

本文转载自公众号 读芯术,原文地址
你听说过“群策群力”吗?不是电视剧,而是一个真实的术语。没有?好吧,想象一下你在茫茫人海中问了一个复杂的问题。现在,来汇总下人们的答案。
你可能会发现,大多数人给出的答案比专家的回答要好。
“群策群力”是指一群人的集体意见,而非某个专家的意见。
——维基百科
回到机器学习领域,我们可以运用同样的思路。例如,如果我们将一组预测器(如分类器和回归器)的预测聚合在一起,所得结果可能会比使用单个最佳预测器更为准确。
一组预测器称为一个集合。因此,这种机器学习技术被称为集成学习。
在自然界中,一群树组成一片森林。假设训练一组树形判定分类器,根据训练数据集的不同子集进行个体预测。后来考虑到大多数人对相同情况的预测,你预测到了预期的观察类。这意味着,你基本上是在使用树形判定分类法的知识集合,它通常被称为随机森林。
本文将介绍最流行的集成方法,包括bagging、boosting、stacking等。在深入讨论之前,请谨记:
当预测器尽可能相互独立时,集成方法的效果最好。获得不同分类器的方法之一是使用完全不同的算法来训练他们。这增加了其产生不同类型误差的机会,从而提高了集成的准确性。
——摘自《使用Scikit-Learn&TensorFlow进行机器学习》第7章
简单集成技术
Hard Voting 分类器
这是该技术最简单的例子,你可能已经熟练掌握。投票分类器通常用于分类问题。假设你已训练并将一些分类器(逻辑回归分类器,SVM分类器,随机森林分类器等)与训练数据集进行了匹配。
创建一个更好的分类器的简单方法是将每个分类器所做的预测集合起来,将选择的多数作为最终预测。基本上,我们可以将其视为检索所有预测器的模式。

平均
上述第一个例子主要用于分类问题。现在,我们来看一种用于回归问题的技术——平均。与Hard Voting类似,我们采用不同的算法进行多次预测,取其平均值进行最终预测。
加权平均
这种方法是指在求平均数时,根据模型对最终预测的重要性,给模型分配不同的权重。
高级集成技术
Stacking
这种技术也被称为堆栈泛化,它基于训练模型的思想,将执行我们之前看到的常规集合。

我们有N个预测器,每个都进行预测并返回一个最终值。之后,元学习者或 Blender 将这些预测作为输入并做出最终预测。
让我们看看它是如何工作的。

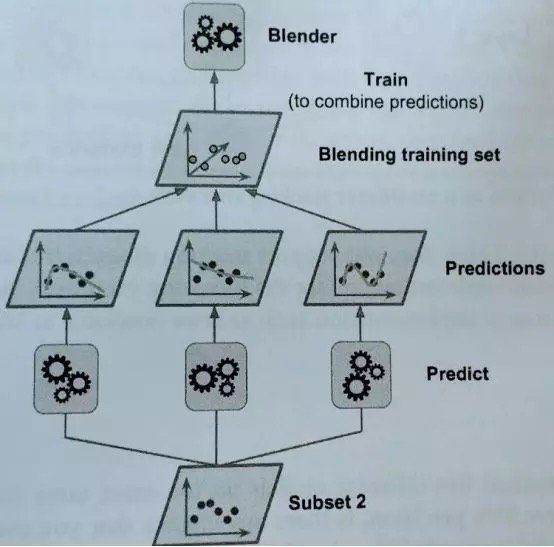
训练元学习者的常用方法是留出集。首先,将训练集分成两个子集。第一个数据子集用来训练预测器。
之后,用训练第一个子集的预测器来对第二个子集(即留出集)进行预测。这样可以确保预测的洁净度,因为这些算法从未进行过数据处理。
通过这些新的预测,我们可以生成一个新的训练集,将其作为输入特征(使新的训练集三维化)并保持目标值。
因此,最后在这个新的数据集上训练元学习者,并在考虑到第一次预测给出的值的情况下预测目标值。
此外,你可以用这种方法训练好几个元学习者(例如,一个使用线性回归,另一个使用随机森林回归,等等)。要使用多个元学习者,必须将训练集分为三个或以上的子集:第一个子集用于训练第一层预测器,第二个用于对未知数据进行预测并创建新的数据集,第三个用于训练元学习者并对目标值进行预测。
Bagging 与 Pasting
另一种方法是对每个预测器(如树形判定分类法)采用相同的算法,然而,训练集的不同随机子集可以得到更全面的结果。
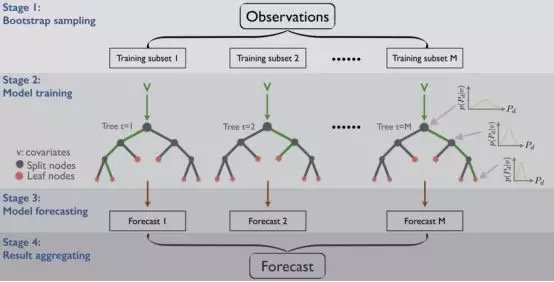
至于子集的创建,可以进行替换 ,也可以不替换。如果假设存在替换,那么有些观测结果可能出现在多个子集中,这就是我们为什么将这个方法称为bagging( bootstrap aggregating的缩写)的原因。而在不进行替换的情况下进行抽样时,我们确保每个子集中的所有观察值都是唯一的,从而保证每个子集中不会出现重复的观察值。
一旦所有的预测器训练完毕,集合就可以通过聚合所有训练过的预测器的预测值来对一个新实例进行预测,就像我们在hard voting分类器中看到的那样。虽然每个个体预测器的偏差都高于在原始数据集上训练的预测器,但是聚合可以减少偏差和方差。
使用pasting则可能使这些模型得到相同的结果,因为它们的输入相同。与pasting相比,bootstraping的每个子集更具多样性,因此用bagging所得到的偏差更大,这意味着预测器之间的相关性更小,从而降低了集成的方差。总之, bagging 模型通常能提供更好的结果,这就解释了为什么一般而言bagging比pasting更常见。
Boosting
如果第一个模型和下一个模型(可能是所有模型)对一个数据点的预测都不正确,那么其结果的组合会提供更好的预测吗?这就是Boosting的作用所在。
Boosting也被称为Hypothesis Boosting,是指任何可以将学习能力弱者组合成学习能力强者的集成方法。这是一个连续的过程,每个模型都试图修正上一个模型的错误。

每个模型不会在整个数据集上都表现良好。然而,在数据集的某些部分它们确实表现得很好。因此,通过Boosting,我们可以期待每个模型都能有助于实际提高整个集成的性能。
基于Bagging和Boosting的算法
最常用的集成学习技术是Bagging和Boosting。下面是这些技术中一些最常见的算法。
Bagging 算法:
· 随机森林(https://medium.com/diogo-menezes-borges/random-forests-8ae226855565)
Boosting 算法:
· AdaBoost(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· Gradient Boosting Machine (GBM)(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· XGBoost(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)
· Light GBM(https://medium.com/diogo-menezes-borges/boosting-with-adaboost-and-gradient-boosting-9cbab2a1af81)

Comments