

從 BOW 到 BERT
自 2013 年 Mikolov 等人提出了 Word2Vec 以來,我們在詞嵌入方面已經有了很多發展。如今,幾乎所有機器學習業內人士都能熟背「國王減去男人加上女人等於女王」這類箴言。目前,這些可解釋的詞嵌入已成為許多基於深度學習的 NLP 系統的重要部分。
去年 10 月初,Google AI 提出了 BERT 表徵——Transformer 雙向編碼表征(論文鏈接:https://arxiv.org/abs/1810.04805,項目代碼:https://github.com/google-research/bert)。看上去,Google 又完成了驚人之舉:他們提出了一種新的學習上下文詞表徵的模型,該模型在 11 個 NLP 任務上都優化了當前最好結果,「甚至在最具挑戰性的問答任務上超過了人類的表現」。然而,這中間仍然存在着一個問題:這些上下文詞表示究竟編碼了什麼內容?這些特徵是否能像 Word2Vec 生成的詞嵌入那樣具有可解釋性?
本文就重點討論上述問題:BERT 模型生成的固定詞表徵的可解釋性。我們發現,不用分析得太過深入,我們就能觀察到一些有趣的現象。
分析 BERT 表徵
無上下文方式
我們先來看一個簡單例子——不管任何上下文。這裡,我們先忽略掉 BERT 其實是在一串連續的表徵上訓練的這一事實。在本文講到的所有實驗中,我們都會進行以下兩個操作:
- 提取目標詞的表徵
- 計算詞之間的餘弦距離
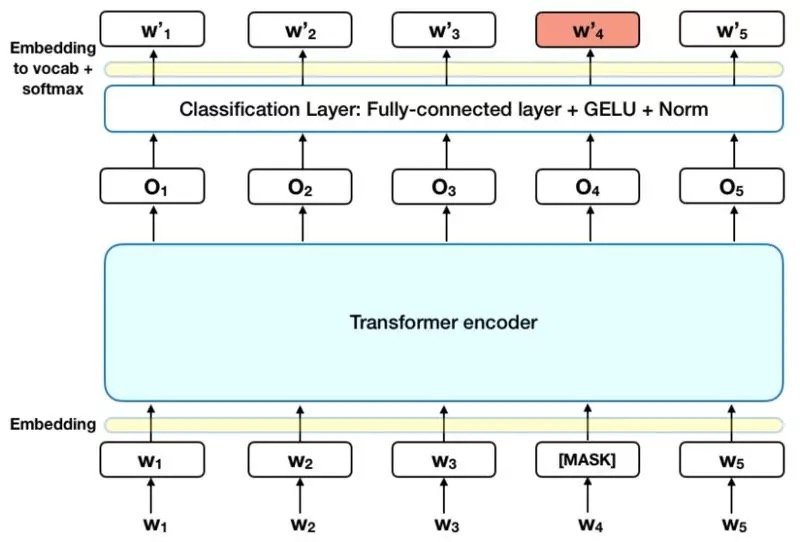
提取「男人」,「女人」,「國王」和「女王」這幾個詞的向量特徵,我們發現,在進行了經典重建操作(即國王減去男人加上女人)後,重建的詞向量實際上距離女王更遠了。
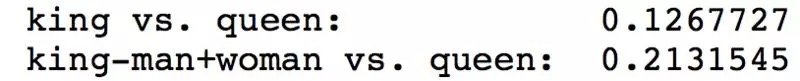
但實際上,也許我們這樣測試 BERT 並不合理。BERT 本來是被訓練用於 Masked-LM 和 Next-Sequence-Prediction 這類序列預測任務的。換句話說,BERT 中的權重是在使用了上下文信息建立詞表徵的條件下獲得的。它不僅僅是一個學習上下文無關表徵的損失函數。
上下文方式
為了消除上一節中的不合理性,我們可以在正確語境中使用我們的詞彙來構建句子,如「國王通過法律」,「女王通過法律」,「冰箱很涼」等等。在這些新的條件下,我們開始研究:
- 特定單詞的表示如何在不同的上下文中使用(例如,作為主語還是賓語,以不同的描述性形容詞為條件,以及與無上下文的單詞本身相對應)。
- 當我們從正確的上下文中提取表徵時,語義向量空間假設是否還會成立。
我們先從一個簡單的實驗開始。使用「冰箱」這一詞彙,我們造了以下 5 個句子:
- 冰箱(在無任何上下文的情況下使用 冰箱 一詞)
- 冰箱在廚房裡(將 冰箱 作為句子的主語)
- 冰箱很涼(仍然是將 冰箱 作為句子的主語)
- 他把食物放在冰箱里(將 冰箱 作為介詞「在……里」的賓語)
- 冰箱通過了法律(把 冰箱 用在不合理的語境里)
在這裡,我們確認了我們之前的假設,並發現使用沒有任何上下文的冰箱會返回一個與在適當的環境中使用冰箱非常不同的表示。另外,將 冰箱 作為主語的句子(句子 2,3)返回的表示比將冰箱作為賓語的句子(句子 4)和不合理上下文(句子 5)所返回的表示更相似。

我們來再看一個例子,這次使用 派 這個詞。我們還是造 5 個句子:
- 派(在無任何上下文的情況下使用 派 一詞)
- 那個人吃了一個派(使用 派 作為賓語)
- 那個人扔掉了一個派(使用 派 作為賓語)
- 那塊派很美味(使用 派 作為主語)
- 那塊派吃了一個人(把 派 用在不合理的語境里)
我們觀察到的趨勢和上一個冰箱實驗很相似。

接下來,我們來看看最早的 國王、女王、男人 和 女人 的例子。我們來造 4 個幾乎一樣的句子,只改變它們的主語。
- 國王通過了法律
- 女王通過了法律
- 男人通過了法律
- 女人通過了法律
從以上句子里,我們提取主語的 BERT 表徵。在這個例子中,我們得到了更好的結果:國王減去男人加上女人和女王之間的餘弦距離縮小了一點點。

最後,我們來看一下當句子結構不變但句子情感不同時,詞表徵有什麼變化。這裡,我們造三個句子。
- 數學是一個困難的學科
- 數學是一個難學的學科
- 數學是一個簡單的學科
使用這些句子,我們可以探討當我們改變情感時主題和形容詞表示會發生什麼變化。有趣的是,我們發現同義(即困難和難學)的形容詞具有相似的表示,但是反義詞(即困難和簡單)的形容詞具有非常不同的表示。
另外,當我們改變情感時,我們發現,主語數學在句子情感相同時相似度更高(如困難和難學),而在情感不同時相似度低(如困難和簡單)。

總之,我們的實驗結果似乎表明,像 Word2Vec 一樣,BERT 也可以學習語義向量表示(儘管不那麼明顯)。BERT 似乎確實非常依賴於上下文信息:沒有任何上下文的單詞與具有某些上下文的相同單詞非常不同,而且不同的上下文(如改變句子情感)也會改變主語的表示。
不過請記住,在證據有限的情況下總是存在過度概括的風險。本文所做的這些實驗並不完整,只能算是一個開始。我們使用的樣本規模非常小(相對於英語單詞的海量詞典來說),同時我們是在非常特定的實驗數據集上評估非常特定的距離度量(餘弦距離)。分析 BERT 表示的未來工作應該在所有這些方面有所擴展。最後,感謝 John Hewitt 和 Zack Lipton 提供了有關該主題的這一很有意義的討論。
本文轉自公眾號 AI前線,原文地址

Comments