

有沒有想過我們如何將機器學習算法應用於問題,以便分析,可視化,發現趨勢並找到數據中的相關性?在本文中,我將討論建立機器學習模型的常見步驟以及為數據選擇正確模型的方法。本文的靈感來自於常見的訪談問題,這些問題被問及如何處理數據科學問題以及為什麼選擇上述模型。
作為數據科學家,我們遵循一些準則來創建模型:
- 收集數據(通常為數噸)
- 建立目標,要檢驗的假設和完成此任務的時間表
- 檢查異常或異常值
- 探索丟失的數據
- 根據我們的約束,目標和假設檢驗清理數據
- 執行統計分析和初始可視化
- 縮放,正則化,歸一化,特徵工程師,隨機樣本並驗證我們的數據以進行模型準備
- 訓練和測試我們的數據,並使用我們對數據的驗證部分來扮演未知的角色
- 基於分類/回歸指標構建模型,用於有監督或無監督學習
- 建立基準精度並根據訓練或測試數據檢查我們當前模型的精度
- 仔細檢查我們是否已解決問題並提供結果
- 準備好用於部署和產品交付的模型(AWS,Docker,Buckets,App,網站,軟件,Flask等)
機器學習任務可以分為監督學習,非監督學習,半監督學習和強化學習。在本文中,我們不關注最後兩個,但是,我將對它們的含義有所了解。
半監督學習使用未標記的數據來總體上進一步了解人口結構。換句話說,我們只從一個小的訓練集中學習特徵,因為它被標記了!我們不會利用包含大量有價值信息的測試集,因為這些信息是未標記的。因此,我們應該找到一種從大量未標記數據中學習的方法。
根據GeeksForGeeks的說法,強化學習是關於在特定情況下採取適當的行動以最大化回報的方法。機器或機械人通過嘗試所有可能的路徑,然後選擇能夠以最少的障礙獲得最佳回報的路徑來進行學習。
方法
以下是為機器學習/深度學習任務選擇模型的一些方法:
- 數據不平衡相對普遍。
我們可以通過對數據進行重新採樣來處理不平衡數據,這是一種使用數據樣本來提高準確性並量化總體參數不確定性的方法。記住我們喜歡重新採樣。實際上,重採樣方法利用了嵌套的重採樣技術。
我們將原始數據分為訓練和測試集。在訓練集的幫助下找到適合我們模型的係數之後,我們可以將該模型應用於測試集並找到所述模型的準確性。這是將其應用於未知數據(也稱為我們的驗證集)之前的最終準確性。這種最終的準確性使人們更有希望在未知數據上獲得準確的結果。
但是,如果我們將訓練集進一步劃分為訓練和測試子集,然後計算該子集的最終準確性,那麼對這些子集中的許多子集重複執行此操作,便可以使我們在這些子集中獲得最大的準確性!我們希望該模型可以為我們的最終測試集提供最大的準確性。進行重新採樣以提高模型的準確性。有不同的數據重新採樣方式,例如自舉,交叉驗證,重複交叉驗證等。
2.我們可以通過主成分分析來創建新功能
也稱為PCA,有助於降低尺寸。聚類技術在無監督機器學習技術中非常普遍。
3.通過正則化技術,我們可以防止過度擬合,擬合不足,離群值和噪聲。
4.我們需要解決黑匣子人工智能問題
這使我們考慮了構建可解釋模型的策略。根據KDNuggets的說法,用於自動決策的黑匣子AI系統通常基於對大數據的機器學習,將用戶的特徵映射到一類可以預測個人行為特徵的類中,而沒有揭示其原因。
這不僅是缺乏透明度的問題,而且是算法從人類偏見和訓練數據中隱藏的偽像集合中繼承的可能偏差的問題,這可能導致不公平,錯誤的決定和錯誤的分析。
5.了解對異常值不敏感的算法
我們可以決定我們應該在模型中使用隨機性,還是在隨機森林中克服異常偏斜度。
機器學習模型
我的數據科學家學習指南涵蓋了大多數這些模型。該指南很好地定義了每種模型的用途,用途,使用時間以及簡單的口頭示例。如果您想訪問我的指南,請單擊此處,因為它也是在Medium的「邁向數據科學」上發佈並推薦的。
- 預測連續值的第一種方法:線性回歸通常是首選,也是最常見的選擇,例如房價
- 二元分類方法通常類似於邏輯回歸模型。如果您遇到兩類分類問題,則支持向量機(SVM)非常有助於獲得最佳結果!
- 多類別分類:隨機森林受到高度青睞,但SVM卻有優勢。隨機森林更適合多類!
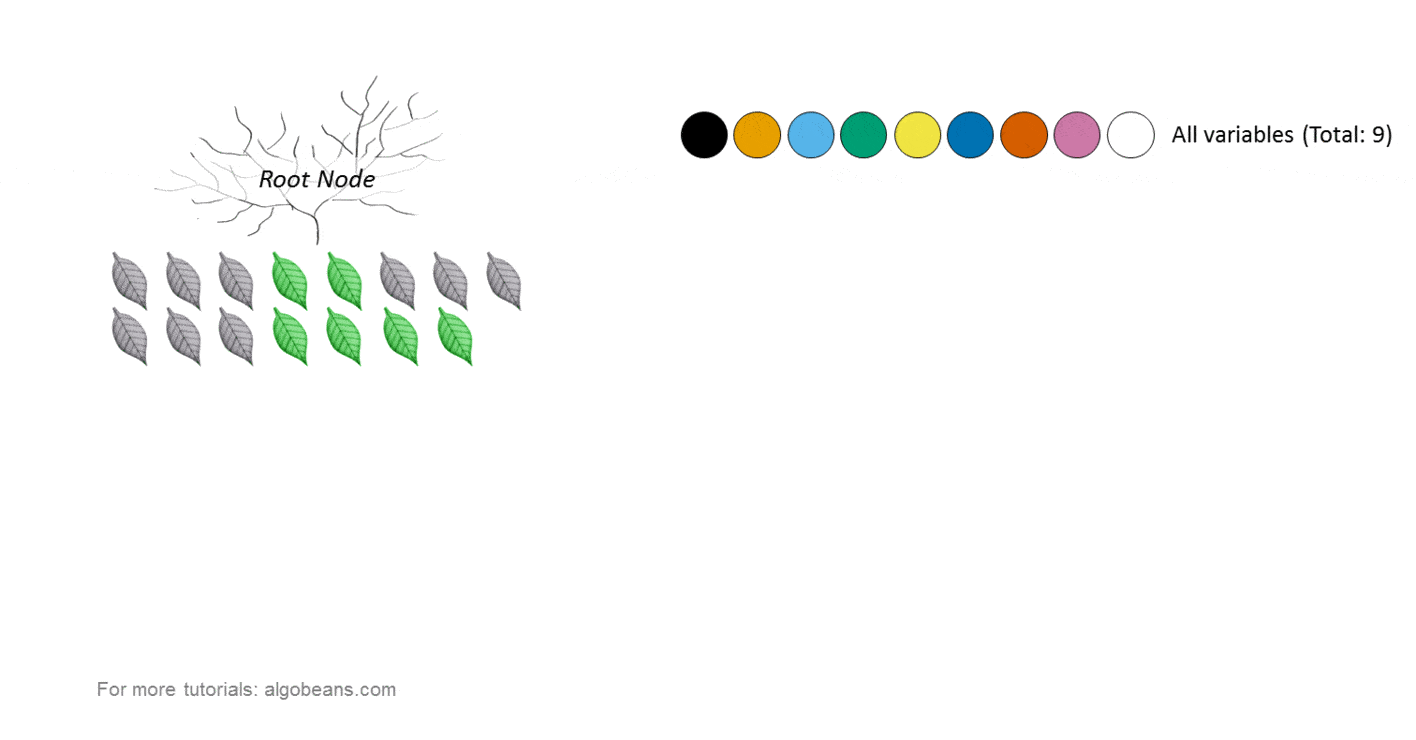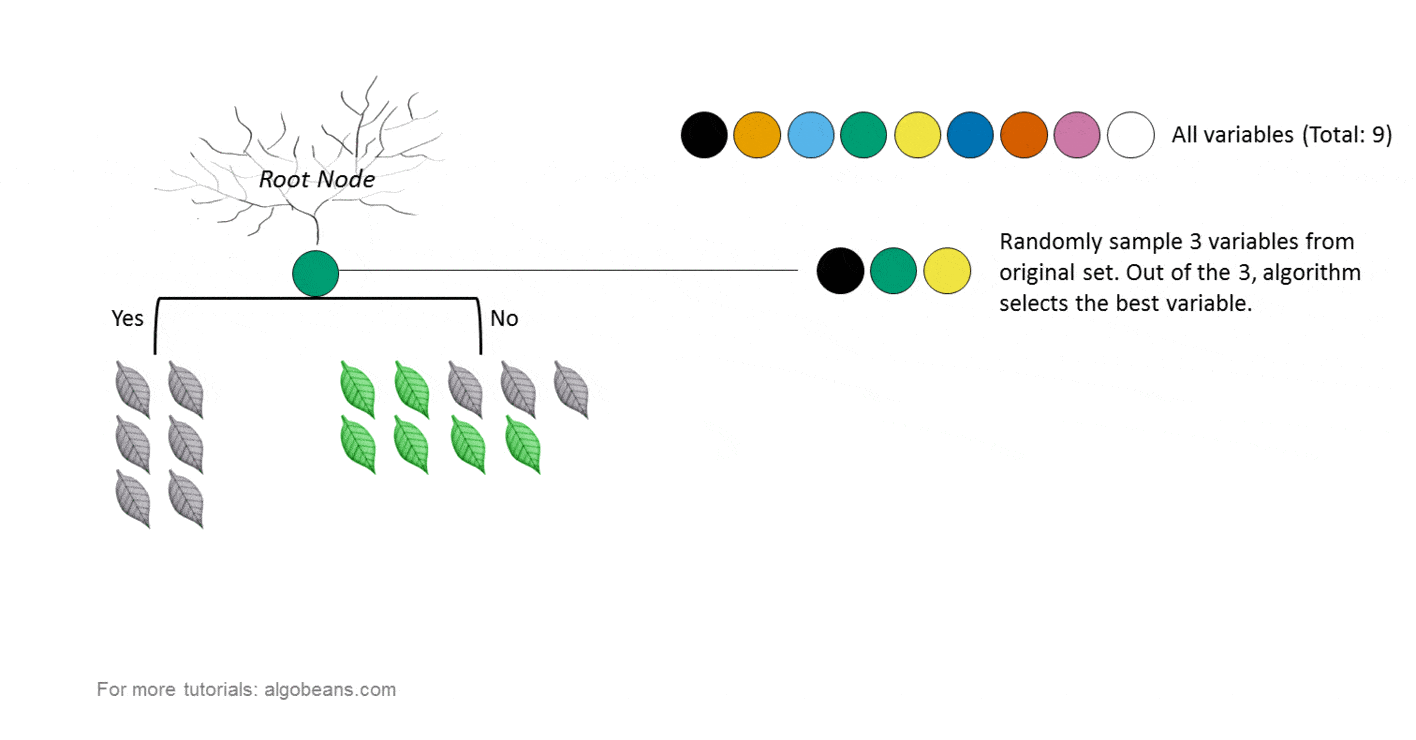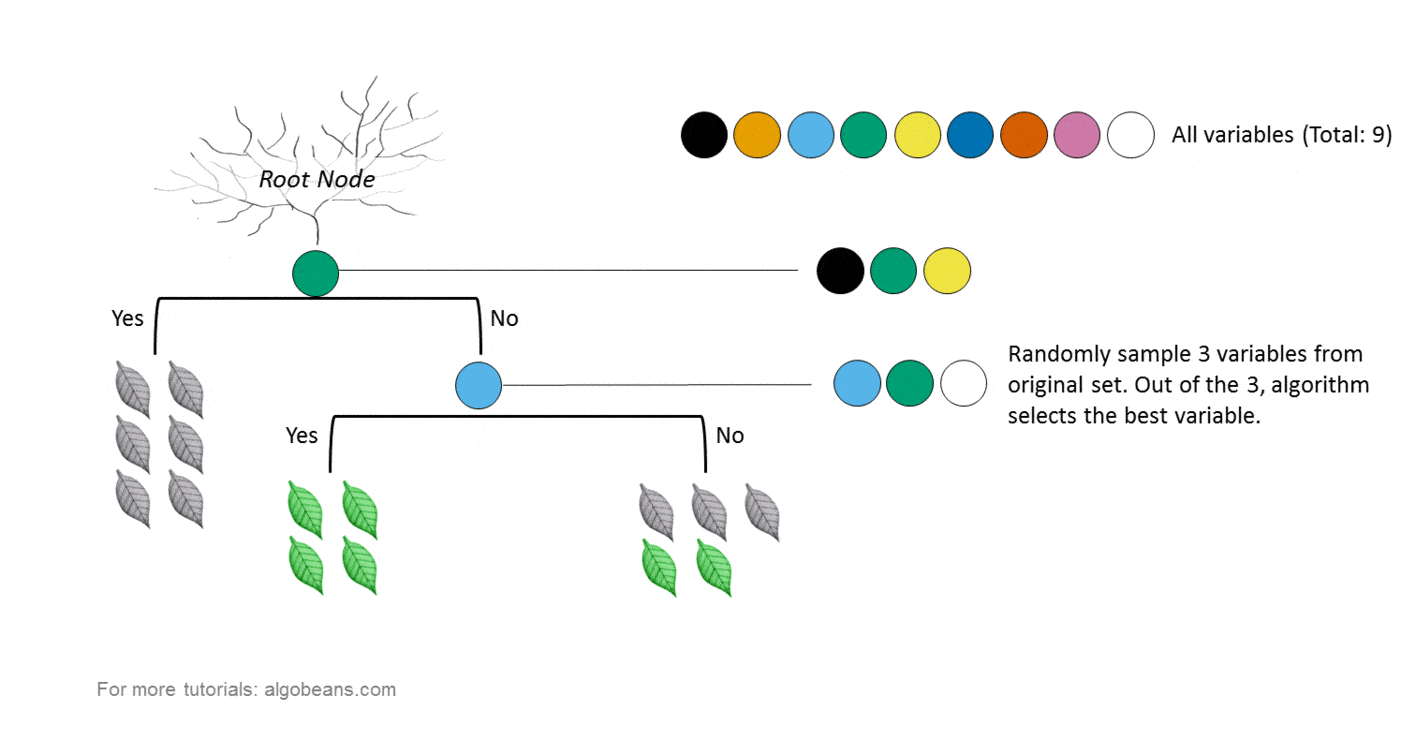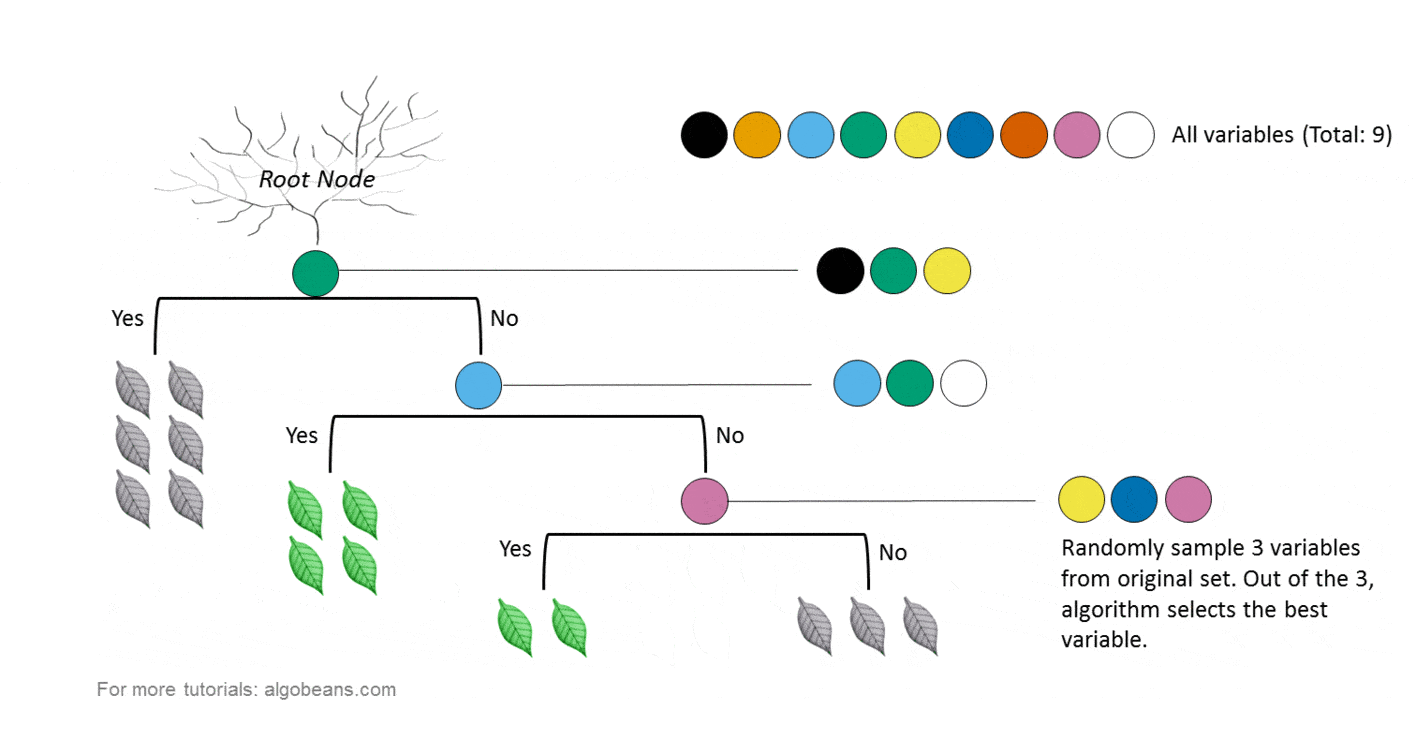
對於多類,您需要將數據簡化為多個二進制分類問題。即使要素的比例不同,隨機森林也可以很好地結合使用數字和分類要素,這意味着您可以按原樣使用數據。SVM可以最大化餘量,並依賴於不同點之間的距離概念。由距離決定是否真的很重要!
由於這種情況,我們必須對分類特徵進行一次熱編碼(虛擬)。此外,強烈建議使用最小-最大或其他縮放比例作為預處理步驟。對於大多數常見的分類問題,隨機森林提供了屬於該類別的可能性,而SVM提供了您與邊界的距離。如果需要概率,您仍然需要以某種方式將其轉換為概率。對於支持SVM的那些問題,它將勝過隨機森林模型。SVM為您提供支持向量,即每個類中最接近類之間邊界的點。
4.最簡單的分類模型開始於?決策樹被視為最容易使用和理解的樹。它們是通過諸如隨機森林或漸變增強之類的模型實現的。

5.競爭青睞的車型?Kaggle比賽偏愛隨機森林和XGBoost!什麼是梯度增強樹?

深度學習模型
根據Investopedia的說法,深度學習是一種人工智能功能,它模仿人腦在處理數據和創建用於決策的模式方面的工作。

- 我們可以使用多層感知器來專註於複雜的功能,這些功能不容易指定,但是具有大量標記數據!
根據Techopedia的說法,多層感知器(MLP)是一種前饋人工神經網絡,可以從一組輸入生成一組輸出。MLP的特點是輸入節點和輸出層之間有向連接的幾層輸入節點,作為有向圖。
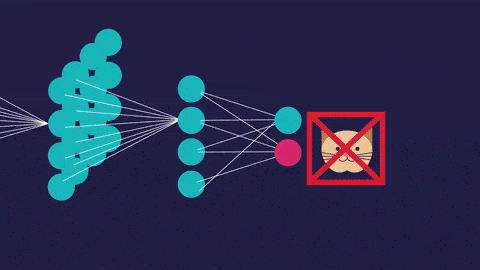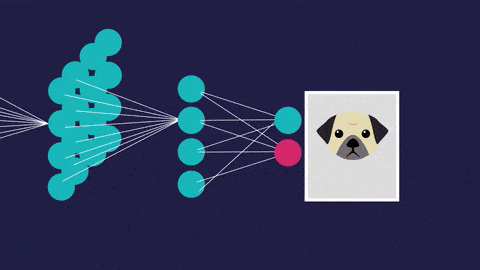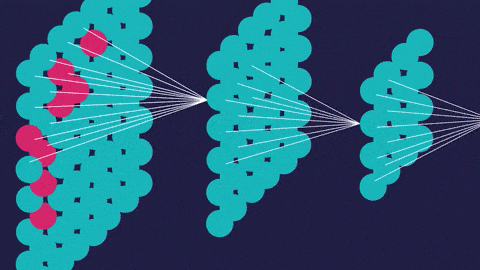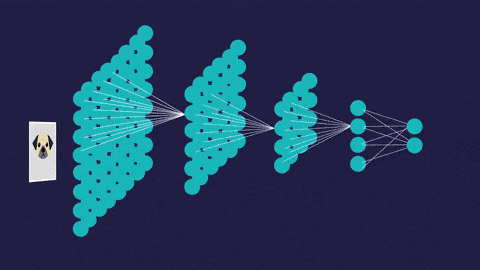
2.對於基於視覺的機器學習,例如圖像分類,目標檢測,圖像分割或圖像識別,我們將使用卷積神經網絡。CNN用於專門用於處理像素數據的圖像識別和處理。

3.對於諸如語言翻譯或文本分類之類的序列建模任務,經常使用遞歸神經網絡。
當任何模型需要上下文以能夠基於輸入提供輸出時,RNN就會出現。有時,上下文是模型預測最適當輸出的最重要的事情。在其他神經網絡中,所有輸入都是彼此獨立的。
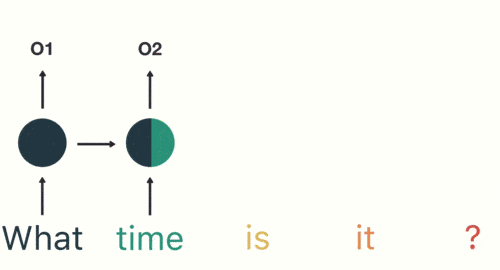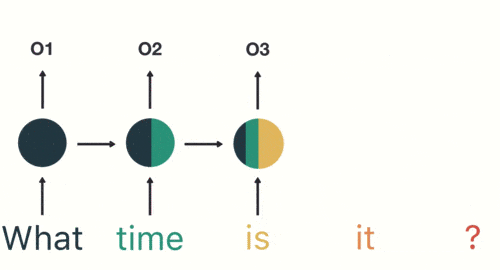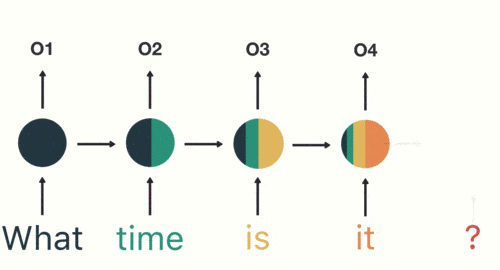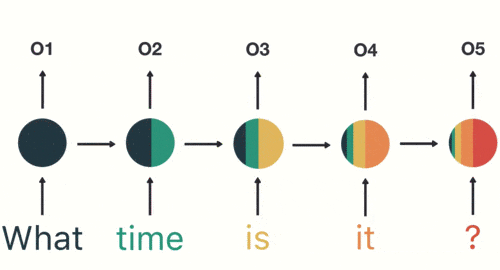
感謝您抽出寶貴的時間閱讀我的文章。在我的面試過程中,我一直在質疑解決數據科學問題和選擇正確的機器學習模型的方法。不是說錯了,而是為什麼我選擇了這個特定的方向。實際上,對於您的方法,確實沒有正確的答案,但是選擇正確的模型具有某種正確性。最終,這取決於您正在分析的數據以及您要解決的目標!
本文轉自 medium,原文地址

Comments