

本文轉載自機器之心,原文地址
谷歌大腦最新研究提出通過神經架構搜索尋找更好的 Transformer,以實現更好的性能。該搜索得到了一種名為 Evolved Transformer 的新架構,在四個成熟的語言任務(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十億詞語言模型基準(LM1B))上的表現均優於原版 Transformer。
在過去的幾年裡,神經架構搜索領域取得了極大進展。通過強化學習和進化得到的模型已經被證明可以超越人類設計的模型(Real et al., 2019; Zoph et al., 2018)。這些進展大多聚焦於改善圖像模型,但也有一些研究致力於改善序列模型(Zoph & Le, 2017; Pham et al., 2018)。但在這些研究中,研究者一直致力於改良循環神經網路(RNN),該網路長期以來一直用於解決序列問題(Sutskever et al., 2014; Bahdanau et al., 2015)。
然而,最近的研究表明,RNN 並非解決序列問題的最佳方法。由於卷積網路(如卷積 Seq2Seq)(Gehring et al., 2017)和完全注意力網路(如 Transformer)(Vaswani et al., 2017)的成功,前饋網路已經可以用於解決 seq2seq 任務,它的主要優勢在於訓練速度比 RNN 快,訓練起來也更加容易。
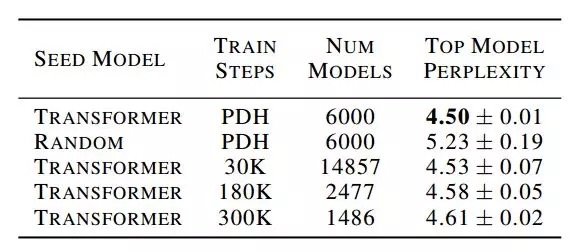
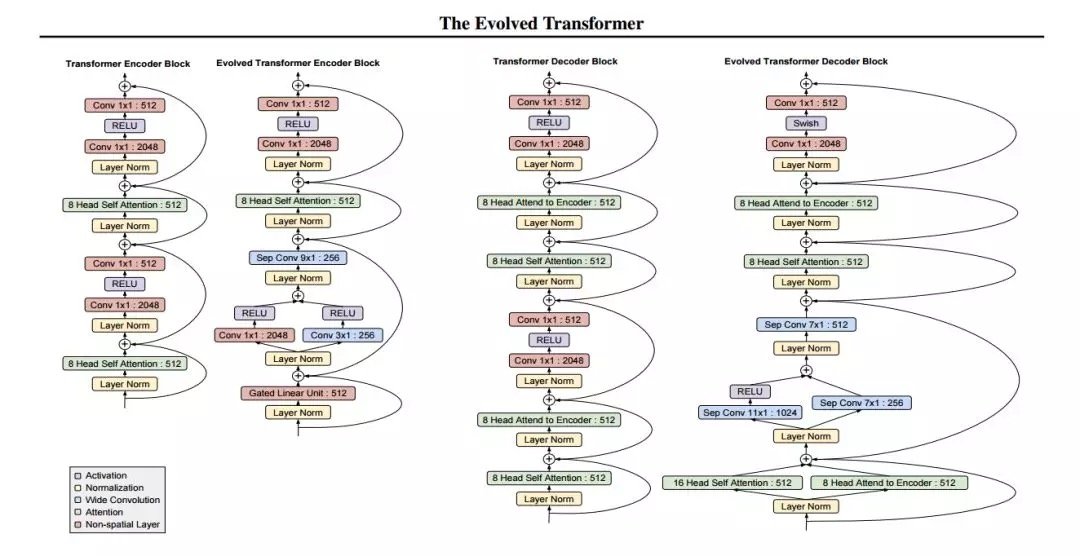
本文旨在檢驗神經架構搜索方法的使用,為 seq2seq 任務設計更好的前饋架構。具體來說,谷歌大腦研究人員使用錦標賽選擇(tournament selection)架構搜索,從 Transformer(被認為是當前最佳、應用最廣的架構)演化出更好、更高效的架構。為了實現這一點,研究者構建了一個反映前饋 seq2seq 模型最新進展的搜索空間,開發了一種名為漸進式動態障礙(progressive dynamic hurdle,PDH)的方法,藉助該方法可以直接在計算要求較高的 WMT 2014 英德翻譯任務上執行搜索。該搜索得到了一種名為 Evolved Transformer 的新架構,在四個成熟的語言任務(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十億詞語言模型基準(LM1B))上的表現均優於原版 Transformer。在用大型模型進行的實驗中,Evolved Transformer 的效率(FLOPS)是 Transformer 的兩倍,而且質量沒有損失。在更適合移動設備的小型模型(參數量為 7M)中,Evolved Transformer 的 BLEU 值高出 Transformer 0.7。
論文:The Evolved Transformer

論文鏈接:https://arxiv.org/abs/1901.11117
摘要:近期研究強調了 Transformer 在解決序列任務中的優勢。同時,神經架構搜索已經發展到可以超越人類設計的模型。本文的目的在於利用架構搜索找到更好的 Transformer 架構。我們首先根據前饋序列模型的最新進展構建了一個大的搜索空間,然後運行進化架構搜索,用 Transformer 為我們的初始種群(initial population)排序。為了在計算成本高昂的 WMT 2014 英德翻譯任務上有效地運行此搜索,我們開發了漸進式動態障礙方法,該方法允許我們將更多的資源動態分配給更有潛力的候選模型。我們在實驗中發現的架構——Evolved Transformer——在四個公認的語言任務(WMT 2014 英德、WMT 2014 英法、WMT 2014 英捷及十億詞語言模型基準(LM1B))上的表現都優於 Transformer。在用大型模型進行的實驗中,Evolved Transformer 的效率(FLOPS)是 Transformer 的兩倍,而且質量沒有損失。在更適合移動設備的小型模型(參數量為 7M)中,Evolved Transformer 在 WMT’14 英德任務中的 BLEU 值高出 Transformer 0.7。
方法
研究者採用了基於進化的架構搜索,因為該方法簡單,而且已經被證明在資源有限的情況下比強化學習更加高效(Real et al., 2019)。他們使用與 Real 等人(2019)所用演算法相同的錦標賽選擇演算法演算法,但省略了老式的正則化。演算法大致描述如下。
錦標賽選擇進化架構搜索首先定義描述神經網路架構的基因編碼;然後,從基因編碼空間中隨機採樣創建一個初始種群來創建個體。基於這些個體在目標任務上描述的神經網路的訓練為它們分配適應度(fitness),再在任務的驗證集上評估它們的表現。然後,研究者對種群進行重複採樣,以產生子種群,從中選擇適應度最高的個體作為親本(parent)。被選中的親本使自身基因編碼發生突變(編碼欄位隨機改變為不同的值)以產生子模型。然後,通過在目標任務上的訓練和評估,像對待初始種群一樣為這些子模型分配適應度。當適應度評估結束時,再次對種群進行抽樣,子種群中適應度最低的個體被移除,也就是從種群中移除。然後,新評估的子模型被添加到種群中,取代被移除的個體。這一過程會重複進行,直到種群中出現具備高度適應度的個體,這在本文中表示性能良好的架構。
結果
在此章節中,我們首先對自己的搜索方法、動態進化障礙以及其他進化搜索方法的表現做了基準測試。我們然後設置了 Evolved Transformer 以及與 Transormer 比對的基準。






Comments