

本文轉載自公眾號 將門創投,原文地址
人工智慧的能力我們已經耳熟能詳,但它的弱點是什麼、它的局限是什麼才是我們需要關注的重點。例如,無人駕駛汽車在真實路況中會遇到很多在訓練中從未見過的場景,如何處理這種實際與訓練不匹配的特殊情形成為了橫在研究人員面前的一大難題。
近日,MIT和微軟的研究人員開發出一種用於識別智能系統的新模型,特別是自動駕駛系統在訓練中學習到的、但是與實際情形不匹配的知識「盲點」,工程師們可利用這一模型識別並改進自動駕駛系統處理特殊情況的措施,提高整個系統的安全性。

無人駕駛汽車的人工智慧系統在虛擬模擬環境和數據集中接受了廣泛的訓練,以便應對道路上可能發生的每一種狀況。但是有時候汽車在現實世界中會犯下意想不到的錯誤,因為對於有些突發事件,汽車應該但卻沒有做出正確的應對。

如果有一輛未經特殊訓練的無人車,在通常的數據集上進行訓練後可能無法區分白色的箱式小貨車和閃著警報呼嘯而至的救護車。當它在公路上行駛時救護車鳴笛經過,由於它無法識別出救護車這個特殊的訓練集中缺乏的車型(訓練集中一般會標註小貨車),它無法知曉此時需要減速和靠邊禮讓,而這樣的無人車在路上行駛時就帶來一系列無法預知的交通狀況。同樣的情形還會出現在與警車、消防車甚至校車同行的路段中。特備對於外賣快遞飛馳的電動車、忽左忽右的自行車、隨處衝出的行人,無人駕駛系統更是無法處理如此複雜的路況!
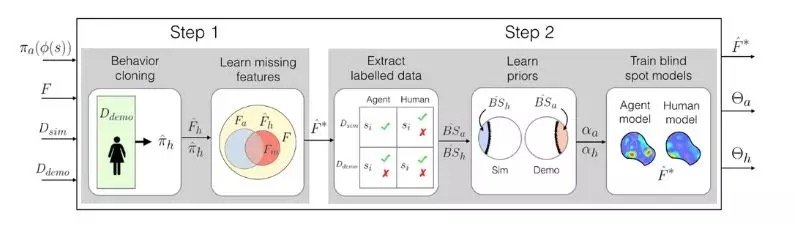
為了解決這一問題,研究人員提出了新的訓練手段來對無人系統進行更深入的訓練和改進。首先研究人員利用先前的方法通過模擬訓練建立了人工智慧系統。但當系統在現實世界中運行時,會有人密切監視該系統的行為,當系統犯下或將要犯下任何錯誤時,人類會及時介入為系統提供人類的反饋意見。隨後研究人員將訓練數據和人類反饋數據結合起來,並使用機器學習技術來生成異常/盲點識別模型,該模型能夠準確地指出該系統在哪些地方需要人類介入以便獲取更多的信息,從而來引導正確行為。
研究人員通過視頻遊戲驗證了這種方法,他們通過模擬讓人類糾正了視頻中人物的學習路徑。下一步是將該模型與傳統的訓練和測試方法結合起來,以便訓練那些需要人類反饋意見的自動學習系統,比如自動駕駛汽車和機器人。這個模型有助於自動系統更好地了解它們不知道的東西,很多時候對系統進行訓練時,它們接受的模擬訓練與現實世界發生的事件並不相符,而且系統可能犯錯,發生意外事故。這個模型可以用安全的方式以人類行為來彌補模擬和現實世界之間的差距。
一些傳統的訓練方法確實在真實世界的測試中提供了人類反饋,但是僅僅是為了更新系統的行為動作。這些方法不能識別人工智慧系統的盲點。 而這種新提出的模型首先將人工智慧系統置於模擬訓練中,人工智慧系統將產生一些「策略」,將每種情況都映射到它在模擬中能採取的最佳行動。然後該系統將被設置到現實世界中,當系統行為錯誤時人類將發出提醒信號。
人類可以通過多種方式提供數據,例如通過「演示」和「修正」。在演示中,人類像在現實世界中那樣行動,系統對其進行觀察,並將人類的行為和在這種情況下系統將採取的行為進行比較。以無人駕駛汽車為例,如果汽車的計劃路線偏離了人類的意願,人類會手動控制汽車,這時系統就會發出信號。通過觀察人類行為相符或不相符的行為,為系統指出了哪些行為是可接受的,哪些行為是不可接受的。
同時人類還可以對系統進行修正,當系統在現實世界中工作時,人類可以對其進行監控。司機可以坐在駕駛座上,而自動駕駛汽車則沿著計劃的路線行駛。如果汽車的行駛是正確的,人類不進行干預。如果汽車的行駛不正確,人類可能會重新控制車輛,這時系統就會發出信號,表明在這種特定情況下汽車採取了不當的行為。
一旦彙集了來自人類的反饋數據,系統就能構建出一個各類情況資料庫。單個情況可以接收許多不同的信號,也就是說每種狀況可能有多個標籤表示該行為是可接受的和不可接受的。例如,一輛自動駕駛汽車可能已經在一輛大車旁邊開過了許多次而且沒有減速和停車,這是被認可的。但是某次對系統來說和大車完全一樣的救護車駛來時,自動駕駛汽車也沒有減速或者做出規避動作,此時它就會收到一個反饋信號:系統的行為不恰當。
此刻,該系統已經從人類那裡得到了多個相互矛盾的信號:有時它從大車旁邊不減速開過去,是可以的;而在相同情況下,只是大車換成了救護車,不減速開過去就不對。這時系統就會注意到它錯了,但是它還不知道為什麼錯,在收集了所有這些看起來相互矛盾的信號後,下一步就是整合信息並提出問題:當收到這些混合信號時,犯下錯誤的可能性有多大。
這一新模型的最終目標是將這些模稜兩可的情況標記為盲點。但這不僅僅是簡單地計算每種情況下出現的可接受行為和不可接受行為的次數。例如如果該系統遇到救護車時十次中有九次採取正確的行動,就會將這種情況標記為非盲點。但由於不恰當行為遠比恰當行為出現的次數少,系統最終會學會預測所有的情況都不是盲點,這對於實際系統來說是極其危險的。
為此研究人員使用一種通常用於眾包數據處理標籤雜訊的Dawid – Skene機器學習方法來解決這一問題。該演算法將各類情況匯總資料庫作為輸入,每個情況都有「可接受」和「不可接受」的一對噪音標籤。然後它聚集所有數據,並使用一些概率計算方法來識別預測盲點標籤模式和預測非盲點標籤模式。使用這些信息它會為每種情況輸出一個整合的「非盲點」或「盲點」標籤以及該標籤的置信度。值得注意的是,即使在90%的情況下做出了可接受行為,該演算法也可以通過學習把罕見的不可接受情況認作盲點。最後該演算法將生成了「熱圖」,系統在原始訓練中經歷的每種訓練情況都被按照從低到高的盲點概率進行排布。
當系統被應用到現實世界中時,它可以利用該學習模型來更加謹慎和智能地行動。如果學習模型預測某種狀態是高概率的盲點,系統就可以諮詢人類應該如何應對,從而更安全的行動。
如果想要了解更詳細的技術細節,請參考研究人員發表在最近AAAI -19的論文:

Comments