

本文轉載自公眾號 PaperWeekly,原文地址
- 作者丨許志欽、張耀宇
- 學校丨紐約大學阿布扎比分校博士後、紐約大學庫朗研究所訪問學者
- 研究方向丨計算神經科學、深度學習理論
GAN 在圖像生成上取得了巨大的成功,這無疑取決於 GAN 在博弈下不斷提高建模能力,最終實現以假亂真的圖像生成。
GAN 自 2014 年誕生至今也有 4 個多年頭了,大量圍繞 GAN 展開的文章被發表在各大期刊和會議,以改進和分析 GAN 的數學研究、提高 GAN 的生成質量研究、GAN 在圖像生成上的應用(指定圖像合成、文本到圖像,圖像到圖像、視頻)以及 GAN 在 NLP 和其它領域的應用。圖像生成是研究最多的,並且該領域的研究已經證明了在圖像合成中使用 GAN 的巨大潛力。
本文圍繞 An Introduction to Image Synthesis with Generative Adversarial Nets 一文對 GAN 在圖像生成應用做個綜述。

論文引入
著名的物理學家 Richard Feynman 說過:「What I cannot create, I do not understand」(對於我創造不出的事物,我是無法理解它的)。我們現階段接觸到的 AI 產品,都是在嘗試去看懂人類可以看懂的,例如對 ImageNet 的圖像分類、AlphaGo、智能對話機械人等。
然而,我們仍然不能斷定這些算法具有真正的「智能」,因為知道如何做某事並不一定意味着理解某些東西,而且真正智能的機械人理解其任務是至關重要的。
如果機器可以去 create,這也就可以說明機器對它的輸入數據已經可以自主的建模,這是否可以說明機器在朝着更加「智慧」邁進了一步。這種 create 在機器學習的領域下,目前最為可行的方法是生成模型。通過學習的生成模型,機器甚至可以繪製不在訓練集中但遵循相同分佈的樣本。
在生成模型中比較有影響力的有 VAE [1]、PixelCNN [2]、Glow [3]、GAN [4]。其中在 2014 年提出的 GAN 可謂是生成模型中最受歡迎的,即使不能說 GAN 是一騎絕塵但也可謂是鶴立雞群。
GAN 由兩個神經網絡組成,一個生成器和一個判別器組成,其中生成器試圖產生欺騙判別器的真實樣本,而判別器試圖區分真實樣本和生成樣本。這種對抗博弈下使得生成器和判別器不斷提高性能,在達到納什平衡後生成器可以實現以假亂真的輸出。
但是這種納什平衡只存在於理論中,實際 GAN 的訓練伴隨着一些問題的限制。一個是 GAN 訓練不穩定性另一個是模式崩潰,導致問題的理論推導在之前的文章 [41] 有所推證。
GAN 存在的問題並沒有限制 GAN 的發展,不斷改進 GAN 的文章層出不窮,在這幾年的鋪墊下 GAN 已經發展得蠻成熟的。從這幾年關於 GAN 的高質量文章可以看出,18 年以後的文章更多關注的是 GAN 在各個領域的應用,而之前的文章則是集中在 GAN 存在問題的改進。
GAN 在圖像生成應用最為突出,當然在計算機視覺中還有許多其他應用,如圖像繪畫,圖像標註,物體檢測和語義分割。在自然語言處理中應用 GAN 的研究也是一種增長趨勢,如文本建模,對話生成,問答和機器翻譯。然而,在 NLP 任務中訓練 GAN 更加困難並且需要更多技術,這也使其成為具有挑戰性但有趣的研究領域。
An Introduction to Image Synthesis with Generative Adversarial Nets 一文是概述 GAN 圖像生成中使用的方法,並指出已有方法的優缺點。本文則是對這篇論文進行個人的理解和翻譯,並對其中的一些方法結合個人實際應用經驗進行分析。
GAN的基礎
接觸過 GAN 的學者如果對 GAN 的結構已經很熟悉,這一部分可以自行跳過。我們看一下 GAN 的基礎結構:

GAN 可以將任意的分佈作為輸入,這裡的 Z 就是輸入,在實驗中我們多取Z∼N(0,1),也多取 [−1,1] 的均勻分佈作為輸入。生成器 G 的參數為 θ,輸入 Z 在生成器下得到 G(z;θ),輸出可以被視為從分佈中抽取的樣本 G(z;θ)∼Pg。
對於訓練樣本 x 的數據分佈為 Pdata,生成模型 G 的訓練目標是使 Pg 近似Pdata。判別器 D 便是為了區分生成樣本和真實樣本的真假,訓練發生器和判別器通過最小 – 最大遊戲,其中發生器 G 試圖產生逼真的數據以欺騙判別器,而判別器 D 試圖區分真實數據和合成數據。這種博弈可公式化為:

最初的 GAN 使用完全連接的層作為其構建塊。後來,DCGAN [5] 提出使用卷積神經網絡實現了更好的性能,從那以後卷積層成為許多 GAN 模型的核心組件。
然而,當判別器訓練得比發生器好得多時,D 可以有信心地從 G 中拒絕來自 G 的樣本,因此損失項 log(1−D(G(z))) 飽和並且 G 無法從中學到任何東西。
為了防止這種情況,可以訓練 G 來最大化 logD(G(z)),而不是訓練 G 來最小化 log(1−D(G(z)))。雖然 G 的改變後的損失函數給出了與原始梯度不同的梯度,但它仍然提供相同的梯度方向並且不會飽和。
條件GAN
在原始 GAN 中,無法控制要生成的內容,因為輸出僅依賴於隨機噪聲。我們可以將條件輸入 c 添加到隨機噪聲 Z,以便生成的圖像由 G(c,z) 定義。這就是 CGAN [6],通常條件輸入矢量 c 與噪聲矢量 z 直接連接即可,並且將得到的矢量原樣作為發生器的輸入,就像它在原始 GAN 中一樣。條件 c 可以是圖像的類,對象的屬性或嵌入想要生成的圖像的文本描述,甚至是圖片。

輔助分類器GAN (ACGAN)
為了提供更多的輔助信息並允許半監督學習,可以向判別器添加額外的輔助分類器,以便在原始任務以及附加任務上優化模型。這種方法的體系結構如下圖所示,其中 C 是輔助分類器。
添加輔助分類器允許我們使用預先訓練的模型(例如,在 ImageNet 上訓練的圖像分類器),並且在 ACGAN [7] 中的實驗證明這種方法可以幫助生成更清晰的圖像以及減輕模式崩潰問題。使用輔助分類器還可以應用在文本到圖像合成和圖像到圖像的轉換。

GAN與Encoder的結合
儘管 GAN 可以將噪聲向量 z 轉換為合成數據樣本 G(z),但它不允許逆變換。如果將噪聲分佈視為數據樣本的潛在特徵空間,則 GAN 缺乏將數據樣本 x 映射到潛在特徵 z 的能力。
為了允許這樣的映射,兩個並發的工作 BiGAN [8] 和 ALI [9] 在原始 GAN 中添加編碼器 E,如下圖所示。

令 Ωx 為數據空間,Ωz 為潛在特徵空間,編碼器 E 將 x∈Ωx 作為輸入,併產生特徵向量 E(x)∈Ωz 作為輸出。修正判別器 D 以將數據樣本和特徵向量都作為輸入來計算 P(Y|x,z),其中 Y=1 表示樣本是真實的而 Y=0 表示數據由 G 生成。用數學公式表示為:

GAN與VAE的結合
VAE 生成的圖像是模糊的,但是 VAE 生成並沒有像 GAN 的模式崩潰的問題,VAE-GAN [10] 的初衷是結合兩者的優點形成更加魯棒的生成模型。模型結構如下:

但是實際訓練過程中,VAE 和 GAN 的結合訓練過程也是很難把握的。
處理模式崩潰問題
雖然 GAN 在圖像生成方面非常有效,但它的訓練過程非常不穩定,需要很多技巧才能獲得良好的結果。GAN 不僅在訓練中不穩定,還存在模式崩潰問題。判別器不需要考慮生成樣品的種類,而只關注於確定每個樣品是否真實,這使得生成器只需要生成少數高質量的圖像就足以愚弄判別者。
例如在 MNIST 數據集包含從 0 到 9 的數字圖像,但在極端情況下,生成器只需要學會完美地生成十個數字中的一個以完全欺騙判別器,然後生成器停止嘗試生成其他九位數,缺少其他九位數是類間模式崩潰的一個例子。類內模式崩潰的一個例子是,每個數字有很多寫作風格,但是生成器只學習為每個數字生成一個完美的樣本,以成功地欺騙鑒別器。
目前已經提出了許多方法來解決模型崩潰問題。一種技術被稱為小批量(miniBatch)特徵,其思想是使判別器比較真實樣本的小批量以及小批量生成的樣本。通過這種方式,判別器可以通過測量樣本在潛在空間中的距離來學習判斷生成的樣本是否與其他一些生成的樣本過於相似。儘管這種方法運行良好,但性能在很大程度上取決於距離計算中使用的特徵。
MRGAN [11] 建議添加一個編碼器,將數據空間中的樣本轉換回潛在空間,如 BiGAN 它的編碼器和生成器的組合充當自動編碼器,重建損失被添加到對抗性損失中以充當模式正則化器。同時,還訓練判別器以區分重構樣本,其用作另一模式正則化器。
WGAN [12] 使用 Wasserstein 距離來測量真實數據分佈與學習分佈之間的相似性,而不是像原始 GAN 那樣使用 Jensen-Shannon 散度。雖然它在理論上避免了模式崩潰,但模型收斂的時間比以前的 GAN 要長。
為了緩解這個問題,WGAN-GP [13] 建議使用梯度懲罰,而不是 WGAN 中的權重削減。WGAN-GP 通常可以產生良好的圖像並極大地避免模式崩潰,並且很容易將此培訓框架應用於其他 GAN 模型。
SAGAN [14] 將譜歸一化的思想用在判別器,限制判別器的能力。
GAN在圖像生成方法
GAN 在圖像生成中的主要方法為直接方法,迭代方法和分層方法,這三種方法可由下圖展示:

區分圖像生成方法是看它擁有幾個生成器和判別器。
直接法
該類別下的所有方法都遵循在其模型中使用一個生成器和一個判別器的原理,並且生成器和判別器的結構是直接的,沒有分支。許多最早的 GAN 模型屬於這一類,如 GAN [4]、DCGAN [5]、ImprovedGAN [15],InfoGAN [16],f-GAN [17] 和 GANINT-CLS [18]。
其中,DCGAN 是最經典的之一,其結構被許多後來的模型使用,DCGAN 中使用的一般構建塊如下圖所示,其中生成器使用反卷積,批量歸一化和 ReLU 激活,而判別器使用卷積,batchnormalization 和 LeakyReLU 激活,這也是現在很多 GAN 模型網絡設計所借鑒的。

與分層和迭代方法相比,這種方法設計和實現相對更直接,並且通常可以獲得良好的結果。
分層法
與直接法相反,分層方法下的算法在其模型中使用兩個生成器和兩個鑒別器,其中不同的生成器具有不同的目的。這些方法背後的想法是將圖像分成兩部分,如「樣式和結構」和「前景和背景」。兩個生成器之間的關係可以是並聯的或串聯的。
SS-GAN [19] 使用兩個 GAN,一個 Structure-GAN 用於從隨機噪聲 ẑ 作為輸入並輸出圖像,整體結構可由下圖展示:

迭代法
迭代法不同於分層法,首先,不使用兩個執行不同角色的不同生成器,此類別中的模型使用具有相似或甚至相同結構的多個生成器,並且它們生成從粗到細的圖像,每個生成器重新生成結果的詳細信息。當在生成器中使用相同的結構時,迭代方法可以在生成器之間使用權重共享,而分層方法通常不能。
LAPGAN [20] 是第一個使用拉普拉斯金字塔使用迭代方法從粗到細生成圖像的 GAN。LAPGAN 中的多個生成器執行相同的任務:從前一個生成器獲取圖像並將噪聲矢量作為輸入,然後輸出再添加到輸入圖像時使圖像更清晰的細節(殘留圖像)。
這些發生器結構的唯一區別在於輸入/輸出尺寸的大小,而一個例外是最低級別的生成器僅將噪聲向量作為輸入並輸出圖像。LAPGAN 優於原始 GAN 並且表明迭代方法可以生成比直接方法更清晰的圖像。
StackGAN [21] 作為一種迭代方法,只有兩層生成器。第一個生成器接收輸入 (z,c),然後輸出模糊圖像,可以顯示粗略的形狀和對象的模糊細節,而第二個生成器採用 (z,c) 和前一個生成器生成的圖像,然後輸出更大的圖像,可以得到更加真實的照片細節。
迭代法的另一個例子是 SGAN [22],其堆疊生成器,其將較低級別的特徵作為輸入並輸出較高級別的特徵,而底部生成器將噪聲矢量作為輸入並且頂部生成器輸出圖像。
對不同級別的特徵使用單獨的生成器的必要性是 SGAN 關聯編碼器,判別器和 Q 網絡(用於預測 P(zi|hi) 的後驗概率以進行熵最大化,其中 hi 每個生成器的第 i 層的輸出特徵),以約束和改善這些特徵的質量。

其它方法
與前面提到的其他方法不同,PPGN [23] 使用激活最大化來生成圖像,它基於先前使用去噪自動編碼器(DAE)學習的採樣。
為了生成以特定類別標籤 y 為條件的圖像,而不是使用前饋方式(例如:如果通過時間展開,可以將循環方法視為前饋),PPGN 優化過程為生成器找到輸入 z 這使得輸出圖像高度激活另一個預訓練分類器中的某個神經元(輸出層中與其類標籤 y 對應的神經元)。
為了生成更好的更高分辨率的圖像,ProgressiveGAN [24] 建議首先訓練 4×4 像素的生成器和判別器,然後逐漸增加額外的層,使輸出分辨率加倍至 1024×1024。這種方法允許模型首先學習粗糙結構,然後專註於稍後重新定義細節,而不是必須同時處理不同規模的所有細節。

GAN在文本到圖像的應用
GAN 應用於圖像生成時,雖然 CGAN [6] 這樣的標籤條件 GAN 模型可以生成屬於特定類的圖像,但基於文本描述生成圖像仍然是一個巨大的挑戰。文本到圖像合成是計算機視覺的里程碑,因為如果算法能夠從純粹的文本描述中生成真實逼真的圖像,我們可以高度確信算法實際上理解圖像中的內容。
GAN-INT-CLS [18] 是使用 GAN 從文本描述生成圖像的第一次嘗試,這個想法類似於將條件向量與噪聲向量連接起來的條件 GAN,但是使用文本句子的嵌入而不是類標籤或屬性的區別。

GAN-INT-CLS 開創性地區分兩種錯誤來源:不真實的圖像與任何文本,以及不匹配的文本的真實圖像。
為了訓練判別器以區分這兩種錯誤,在每個訓練步驟中將三種類型的輸入饋送到判別器:{真實圖像,匹配文本},{真實圖像,不匹配文本} 和 {偽圖像,真實文本}。這種訓練技術對於生成高質量圖像非常重要,因為它不僅告訴模型如何生成逼真的圖像,還告訴文本和圖像之間的對應關係。
TAC-GAN [25] 是 GAN-INT-CLS [18] 和 ACGAN [7] 的組合。
位置約束的文本到圖像
儘管 GAN-INT-CLS [18] 和 StackGAN [21] 可以基於文本描述生成圖像,但是它們無法捕獲圖像中對象的定位約束。為了允許編碼空間約束,GAWWN[26] 提出了兩種可能的解決方案。 GAWWN 提出的第一種方法是通過空間變換網絡對空間複製的文本嵌入張量進行學習,從而學習對象的邊界框。
空間變換器網絡的輸出是與輸入具有相同維度的張量,但是邊界外的值都是零。空間變換器的輸出張量經過幾個卷積層,以將其大小減小回一維向量,這不僅保留了文本信息,而且還通過邊界框提供了對象位置的約束。這種方法的一個好處是它是端到端的,不需要額外的輸入。

GAWWN 提出的第二種方法是使用用戶指定的關鍵點來約束圖像中對象的不同部分(例如頭部,腿部,手臂,尾部等)。對於每個關鍵點,生成一個掩碼矩陣,其中關鍵點位置為 1,其他為 0,所有矩陣通過深度級聯組合形成一個形狀 [M×M×K] 的掩碼張量,其中 M 是掩碼的大小,K 是數字關鍵點。
然後將張量放入二進制矩陣中,其中 1 指示存在關鍵點,否則為 0,然後在深度方向上複製以成為要被饋送到剩餘層中的張量。雖然此方法允許對對象進行更詳細的約束,但它需要額外的用戶輸入來指定關鍵點。

儘管 GAWWN 提供了兩種可以對生成的圖像強制執行位置約束的方法,但它僅適用於具有單個對象的圖像,因為所提出的方法都不能處理圖像中的多個不同對象。
堆疊GAN的文本到圖像
StackGAN [21] 建議使用兩個不同的生成器進行文本到圖像的合成,而不是只使用一個生成器。第一個生成器負責生成包含粗糙形狀和顏色的對象的低分辨率圖像,而第二個生成器獲取第一個生成器的輸出並生成具有更高分辨率和更清晰細節的圖像,每個生成器都與其自己的判別器相關聯。
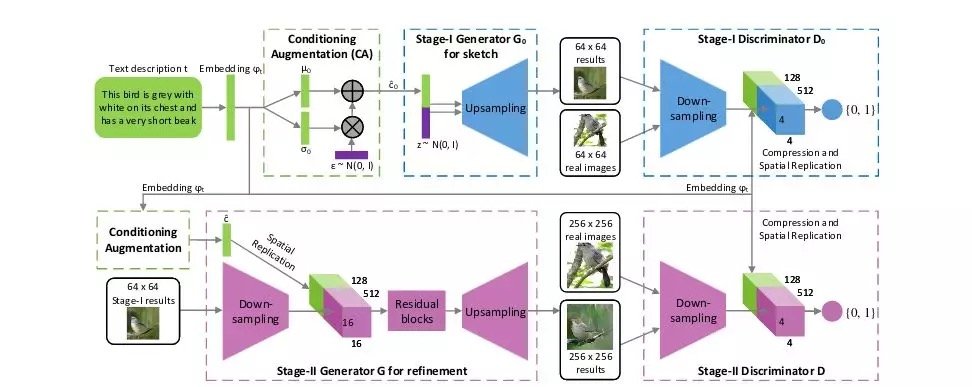
StackGAN ++ [27] 建議使用更多對生成器和判別器而不是僅僅兩個,為判別器增加無條件圖像合成損失,並使用由均值平均損失計算的色彩一致性正則化項和真實和虛假圖像之間的差異。
AttnGAN [28] 通過在圖像和文本特徵上使用注意機制進一步擴展了 StackGAN ++ [27] 的體系結構。在 AttnGAN 中,每個句子都嵌入到全局句子向量中,並且句子的每個單詞也嵌入到單詞向量中。
全局句子向量用於在第一階段生成低分辨率圖像,然後以下階段使用前一階段的輸入圖像特徵和單詞向量作為對關注層的輸入並計算將使用的詞語上下文向量。與圖像特徵組合併形成生成器的輸入,將生成新的圖像特徵。
文本到圖像模型的局限性
目前的文本到圖像模型在每個圖像具有單個對象的數據集上表現良好,例如 CelebA 中的人臉,CUB 中的鳥以及 ImageNet 中的一些對象。此外,他們可以在 LSUN 中為卧室和起居室等場景合成合理的圖像,即使場景中的物體缺乏清晰的細節。然而,在一個圖像中涉及多個複雜對象的情況下,所有現有模型都工作得很糟糕。
當前模型在複雜圖像上不能很好地工作的一個合理的原因是模型只學習圖像的整體特徵,而不是學習其中每種對象的概念。這解釋了為什麼卧室和起居室的合成場景缺乏清晰的細節,因為模型不區分床和桌子,所有它看到的是一些形狀和顏色的圖案應放在合成圖像的某處。換句話說,模型並不真正理解圖像,只記得在哪裡放置一些形狀和顏色。
生成性對抗網絡無疑提供了一種有前途的文本到圖像合成方法,因為它產生的圖像比迄今為止的任何其他生成方法都要清晰。為了在文本到圖像合成中邁出更進一步的步驟,需要找到新的方法實現算法的事物概念。一種可能的方法是訓練可以生成不同種類對象的單獨模型,然後訓練另一個模型,該模型學習如何基於文本描述將不同對象(對象之間的合理關係)組合成一個圖像。
然而,這種方法需要針對不同對象的大型訓練集,以及包含難以獲取的那些不同對象的圖像的另一大型數據集。另一個可能的方向可能是利用 Hinton 等人提出的膠囊理念,因為膠囊被設計用於捕獲物體的概念,但是如何有效地訓練這種基於膠囊的網絡仍然是一個需要解決的問題。
GAN在圖像到圖像的應用
圖像到圖像的轉換被定義為將一個場景的可能表示轉換成另一個場景的問題,例如圖像結構圖映射到 RGB 圖像,或者反過來。該問題與風格遷移有關,其採用內容圖像和樣式圖像並輸出具有內容圖像的內容和樣式圖像的樣式的圖像。
圖像到圖像轉換可以被視為風格遷移的概括,因為它不僅限於轉移圖像的風格,還可以操縱對象的屬性(如在面部編輯的應用中)。
有監督下圖像到圖像轉換
Pix2Pix [29] 提出將 CGAN 的損失與 L1 正則化損失相結合,使得生成器不僅被訓練以欺騙判別器而且還生成儘可能接近真實標註的圖像,使用 L1 而不是 L2 的原因是 L1 產生較少的模糊圖像。

有條件的 GAN 損失定義為:

約束自相似性的 L1 損失定義為:

總的損失為:
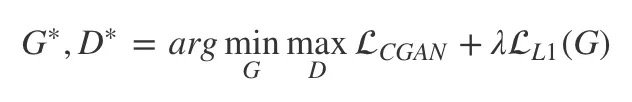
其中 λ 是一個超參數來平衡兩個損失項,Pix2Pix 的生成器結構基於 UNet ,它屬於編碼器 – 解碼器框架,但增加了從編碼器到解碼器的跳過連接,以便繞過共享諸如對象邊緣之類的低級信息的瓶頸。
配對監督下圖像到圖像轉換
PLDT [30] 提出了另一種進行監督圖像到圖像轉換的方法,通過添加另一個判別器 Dpair 來學習判斷來自不同域的一對圖像是否相互關聯。
PLDT 的體系結構如下圖所示,給定來自源域的輸入圖像 Xs,其目標域中的真實圖像 Xt,目標域中的無關圖像 Xt̃ ,以及生成器 G 將 Xs 傳輸到圖像傳輸到圖像Xt中。Dpair 的損失可表示為:


無監督圖像到圖像轉換
兩個並發工作 CycleGAN [31] 和 DualGAN [32] 採用重構損失,試圖在轉換周期後保留輸入圖像。CycleGAN 和 DualGAN 共享相同的框架,如下圖所示。

可以看到,兩個生成器G(ab)和G(ba)正在進行相反的轉換,這可以看作是一種雙重學習。此外,DiscoGAN [33] 是另一種利用與下圖相同的循環框架的模型。
以 CycleGAN 為例,在 CycleGAN 中,有兩個生成器,G(ab)用於將圖像從域 A 傳輸到 B,G(ba)用於執行相反的轉換。此外,還有兩個判別器 DA 和 DB 可預測圖像是否屬於該域。
儘管 CycleGAN 和 DualGAN 具有相同的模型結構,但它們對生成器使用不同的實現。CycleGAN 使用卷積架構的生成器結構,而 DualGAN 遵循 U-Net 結構。
距離約束下無監督圖像到圖像轉換

特徵穩定下無監督圖像到圖像轉換
除了最小化原始像素級別的重建誤差外,還可以在更高的特徵級別進行此操作,這在 DTN[35] 中進行了探討。DTN 的體系結構如下圖所示,其中發生器 G 由兩個神經網絡組成,一個卷積網絡 f 和一個反卷積網絡 g,使得 G=f∘g。

這裡 f 充當特徵提取器,並且 DTN 嘗試在將輸入圖像傳輸到目標域之後保留輸入圖像的高級特徵。給定輸入圖像 x∈xs 生成器的輸出為 G(x)=g(f(x)),然後可以使用距離度量 d(DTN 使用均方誤差 (MSE))定義特徵重建錯誤。這篇論文之前我們進行過詳細解讀,可參看這篇文章[42]。
藉助VAE和權重分享下無監督圖像到圖像轉換
UNIT [36] 建議將 VAE 添加到 CoGAN [37] 用於無監督的圖像到圖像轉換,如下圖所示。

此外,UNIT 假設兩個編碼器共享相同的潛在空間,這意味着 xA,xB 是不同域中的相同圖像,然後共享潛在空間意味着。基於共享潛在空間假設,UNIT 強制在編碼器的最後幾層之間以及發生器的前幾層之間進行權重共享。
UNIT 的目標函數是 GAN 和 VAE 目標的組合,不同之處在於使用兩組 GAN / VAE 並添加超參數 λs 來平衡不同的損耗項。
無監督的多域圖像到圖像轉換
以前的模型只能在兩個域之間轉換圖像,但如果想在幾個域之間轉換圖像,需要為每對域訓練一個單獨的生成器,這是昂貴的。
為了解決這個問題,StarGAN [38] 建議使用一個可以生成所有域圖像的生成器。StarGAN 不是僅將圖像作為條件輸入,而是將目標域的標籤作為輸入,並且生成器用於將輸入圖像轉換為輸入標籤指示的目標域。
與 ACGAN 類似,StarGAN 使用輔助域分類器,將圖像分類到其所屬的域中。此外,循環一致性損失用於保持輸入和輸出圖像之間的內容相似性。
為了允許 StarGAN 在可能具有不同標籤集的多個數據集上進行訓練,StarGAN 使用額外的單一向量來指示數據集並將所有標籤向量連接成一個向量,將每個數據集的未指定標籤設置為零。

圖像到圖像轉換總結
之前討論的圖像到圖像轉換方法,它們使用的不同損失總結在下表中:

最簡單的損失是像素方式的 L1 重建損失,這需要成對的訓練樣本。單側和雙向重建損失都可以被視為像素方式 L1 重建損失的無監督版本,因為它們強制執行循環一致性並且不需要成對的訓練樣本。
額外的 VAE 損失基於源域和目標域的共享潛在空間的假設,並且還意味着雙向循環一致性損失。然而,等效損失不會嘗試重建圖像,而是保留源和目標域之間圖像之間的差異。
在所有提到的模型中,Pix2Pix [29] 產生最清晰的圖像,即使 L1 損失只是原始 GAN 模型的簡單附加組件。將 L1 損失與 PLDT 中的成對判別器結合起來可以改善模型在涉及圖像幾何變化的圖像到圖像轉換上的性能。
此外,Pix2Pix 可能有利於保留源域和目標域中圖像之間的相似性信息,如在一些無監督方法如 CycleGAN [31] 和 DistanceGAN [34] 中所做的那樣。
至於無監督方法,雖然它們的結果不如 Pix2Pix 等監督方法生成效果,但它們是一個很有前途的研究方向,因為它們不需要配對數據,並且在現實世界中收集標記數據是非常昂貴的。
圖像到圖像轉換的應用
圖像到圖像轉換已經應用在很多領域,比如在人臉面部編輯、圖像超分辨率、視頻預測以及醫學圖像轉換,這一部分就不具體展開,因為這方面的工作實在過於龐大。
GAN生成圖像的評價指標
生成圖像的質量很難去量化,並且像 RMSE 這樣的度量並不合適,因為合成圖像和真實圖像之間沒有絕對的一對一對應關係。一個常用的主觀指標是使用 Amazon Mechanical Turk (AMT),它僱用人類根據他們認為圖像的真實程度對合成和真實圖像進行評分。然而,人們通常對好的或壞的看法不同,因此我們還需要客觀的指標來評估圖像的質量。
Inception score (IS) [15] 在將類別放入預先訓練的圖像分類器時,基於類概率分佈中的熵來評估圖像。初始得分背後的一個直覺是圖像 x 越好,條件分佈 p(y|x) 的熵就越低,這意味着分類器對圖像的高度信任。此外,為了鼓勵模型生成各種類型的圖像,邊際分佈 p(y)=∫p(y|x=G(z))dz 應具有高熵。
結合這兩個討論,初始分數由計算。Inception score 既不對標籤的先前分佈敏感,也不對適當的距離測量敏感。此外,Inception score 受到類內模式崩潰的影響,因為模型只需要為每個類生成一個完美樣本以獲得完美的 Inception score,所以 Inception score 不能反應生成模型到底有沒有模式崩潰。
與初始得分相似,FCN-score [29] 採用的理念是,如果生成圖像是真實的,那麼在真實圖像上訓練的分類者將能夠正確地對合成圖像進行分類。然而,圖像分類器不需要輸入圖像非常清晰以給出正確的分類,這意味着基於圖像分類的度量可能無法在分辨兩個圖像之間細節上很小的差異。更糟糕的是,分類器的決定不一定取決於圖像的視覺內容,但可能受到人類不可見的噪聲的高度影響,FCN-score 的度量也是存在問題。
Fréchet Inception Distance (FID) [39] 提供了一種不同的方法。首先,生成的圖像嵌入到初始網絡的所選層的潛在特徵空間中。其次,將生成的和真實的圖像的嵌入視為來自兩個連續多元高斯的樣本,以便可以計算它們的均值和協方差。然後,生成的圖像的質量可以通過兩個高斯之間的 Fréchet 距離來確定:
上式 (μx,μg) 和 (∑x,∑g) 分別是來自真實數據分佈和生成樣本的均值和協方差。FID 與人類判斷一致,並且 FID 與生成圖像的質量之間存在強烈的負相關。此外,FID 對噪聲的敏感度低於 IS,並且可以檢測到類內模式崩潰。
總結
本文在論文 An Introduction to Image Synthesis with Generative Adversarial Nets 的基礎上回顧了 GAN 的基礎知識、圖像生成方法的三種主要方法,即直接方法,分層方法和迭代方法和其它生成方法,如迭代採樣。也討論了圖像合成的兩種主要形式,即文本到圖像合成和圖像到圖像的轉換。
希望本文可以幫助讀者理清 GAN 在圖像生成方向的指導,當然限於原論文(本文多數內容為翻譯原文),還有很多篇精彩的 GAN 在圖像生成方向的論文沒有涉及,讀者可以自行閱讀。

Comments