

識別莫奈的繪畫比繪製莫奈的繪畫更容易。與判別模型(處理數據)相比,生成模型(創建數據)被認為更難。訓練GAN也很難。本文是GAN系列的一部分,我們將研究為什麼培訓如此難以捉摸。通過這項研究,我們了解了一些驅動許多研究人員方向的基本問題。我們將研究一些分歧,以便我們知道研究可能會去哪裡。在研究這些問題之前,讓我們快速回顧一下GAN方程。
GAN
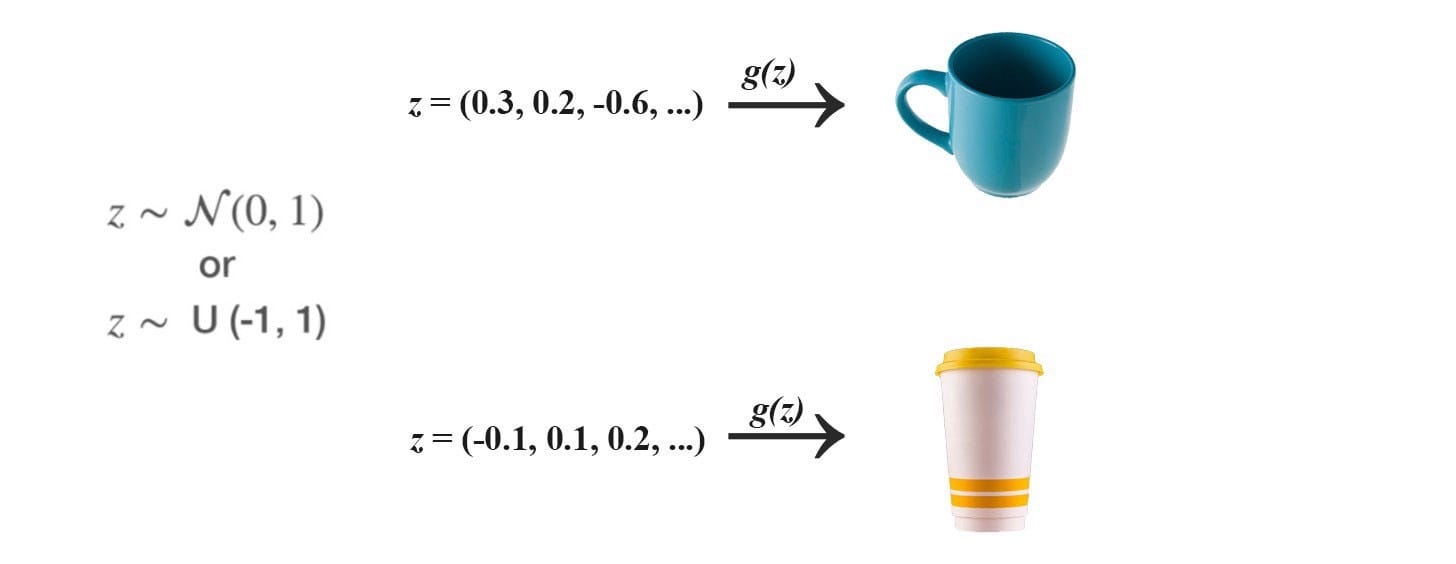
GAN 使用正態或均勻分佈對噪聲z進行採樣,並利用深度網絡生成器G來創建圖像x(x = G(z))。
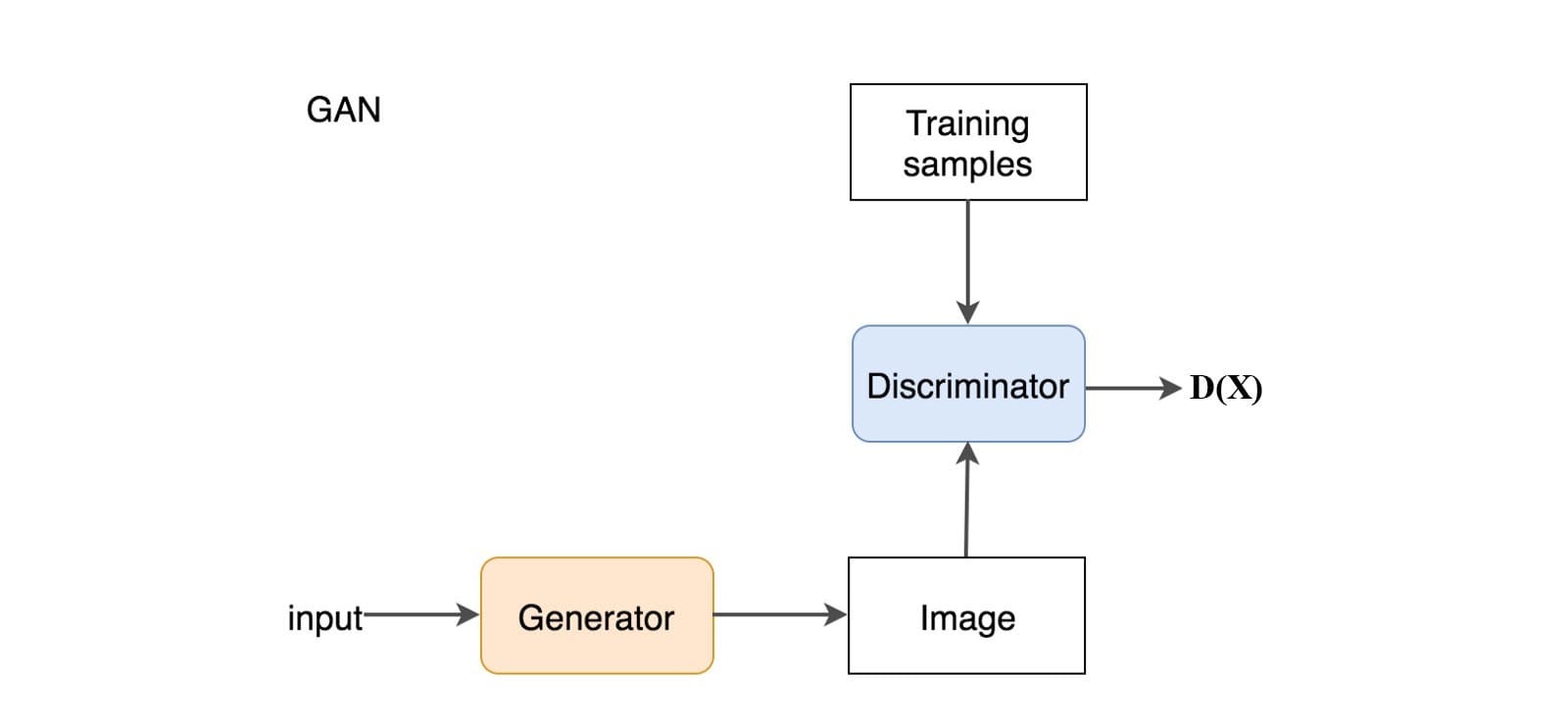
在GAN中,我們添加一個鑒別器來區分鑒別器輸入是真實的還是生成的。它輸出一個值D(x)來估計輸入是真實的機會。
目標函數和漸變
GAN被定義為具有以下目標函數的極小極大遊戲。
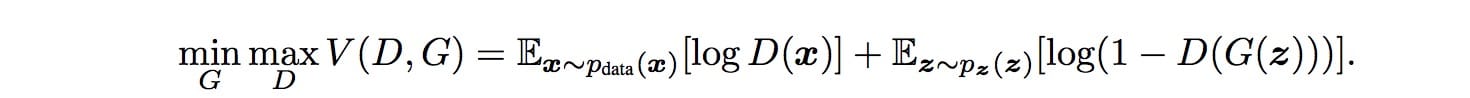
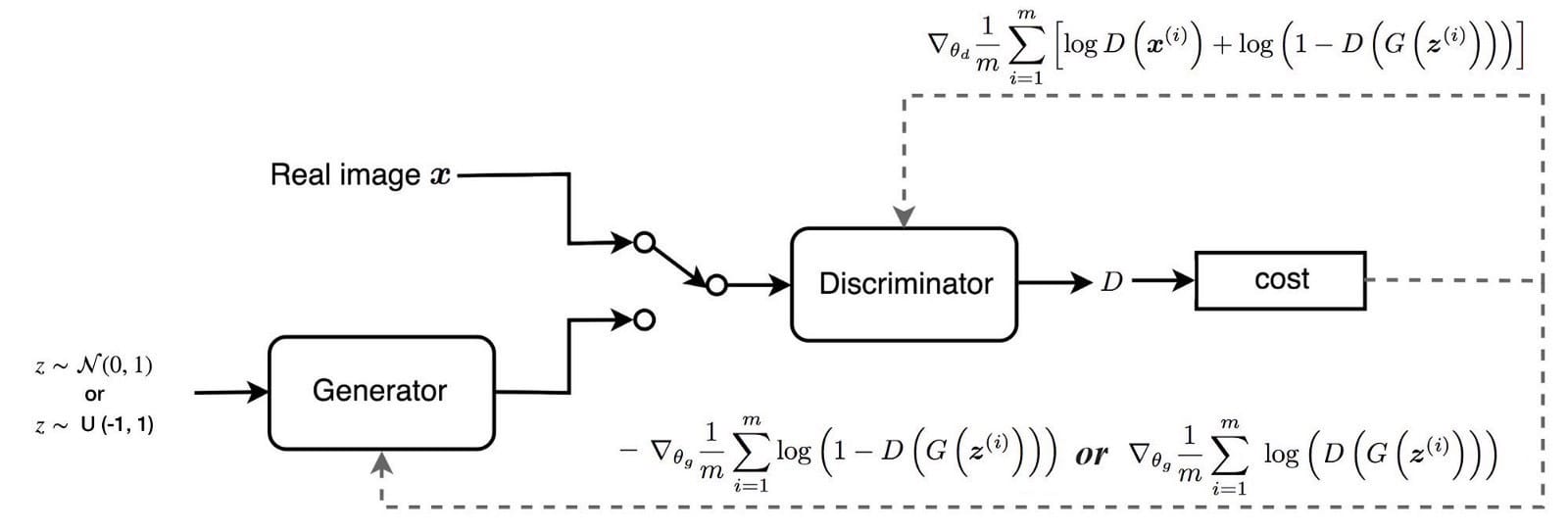
下圖總結了我們如何使用相應的梯度訓練鑒別器和發生器。
GAN問題
許多GAN型號存在以下主要問題:
- 不收斂:模型參數振蕩,不穩定,永不收斂,
- 模式崩潰:發生器坍塌,產生有限的樣品種類,
- 衰減梯度:鑒別器太成功,發電機梯度消失,什麼都不學,
- 發電機和鑒別器之間的不平衡導致過度擬合,和
- 對超參數選擇非常敏感。
模式
實際數據分佈是多模式的。例如,在MNIST中,有10個主要模式,從數字「0」到數字「9」。以下樣本由兩個不同的GAN生成。頂行產生所有10種模式,而第二行僅產生單一模式(數字「6」)。當僅生成幾種數據模式時,此問題稱為模式摺疊。

納什均衡
GAN基於零和非合作遊戲。簡而言之,如果一個人贏了另一個人。零和遊戲也稱為minimax。你的對手希望最大化其行動,你的行動是最小化它們。在博弈論中,當鑒別器和發生器達到納什均衡時,GAN模型收斂。這是下面的minimax方程的最佳點。
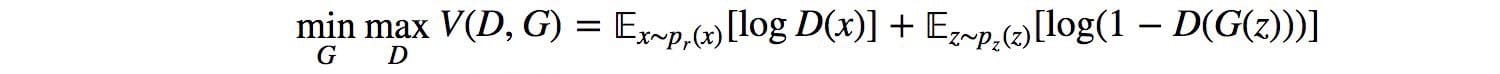
由於雙方都想破壞其他球隊,所以當一名球員無論對手可能做什麼都不會改變其動作時,就會發生納什均衡。考慮兩個播放阿和乙其中控制值X和ÿ分別。玩家A希望最大化xy值,而B想要最小化它。

納什均衡是x = y = 0。這是對手的行動無關緊要的唯一狀態。這是任何對手的行動都不會改變比賽結果的唯一狀態。
讓我們看看我們是否可以使用梯度下降輕鬆找到納什均衡。我們根據值函數V的梯度更新參數x和y。

其中α是學習率。當我們針對訓練迭代繪製x,y和xy時,我們意識到我們的解決方案沒有收斂。
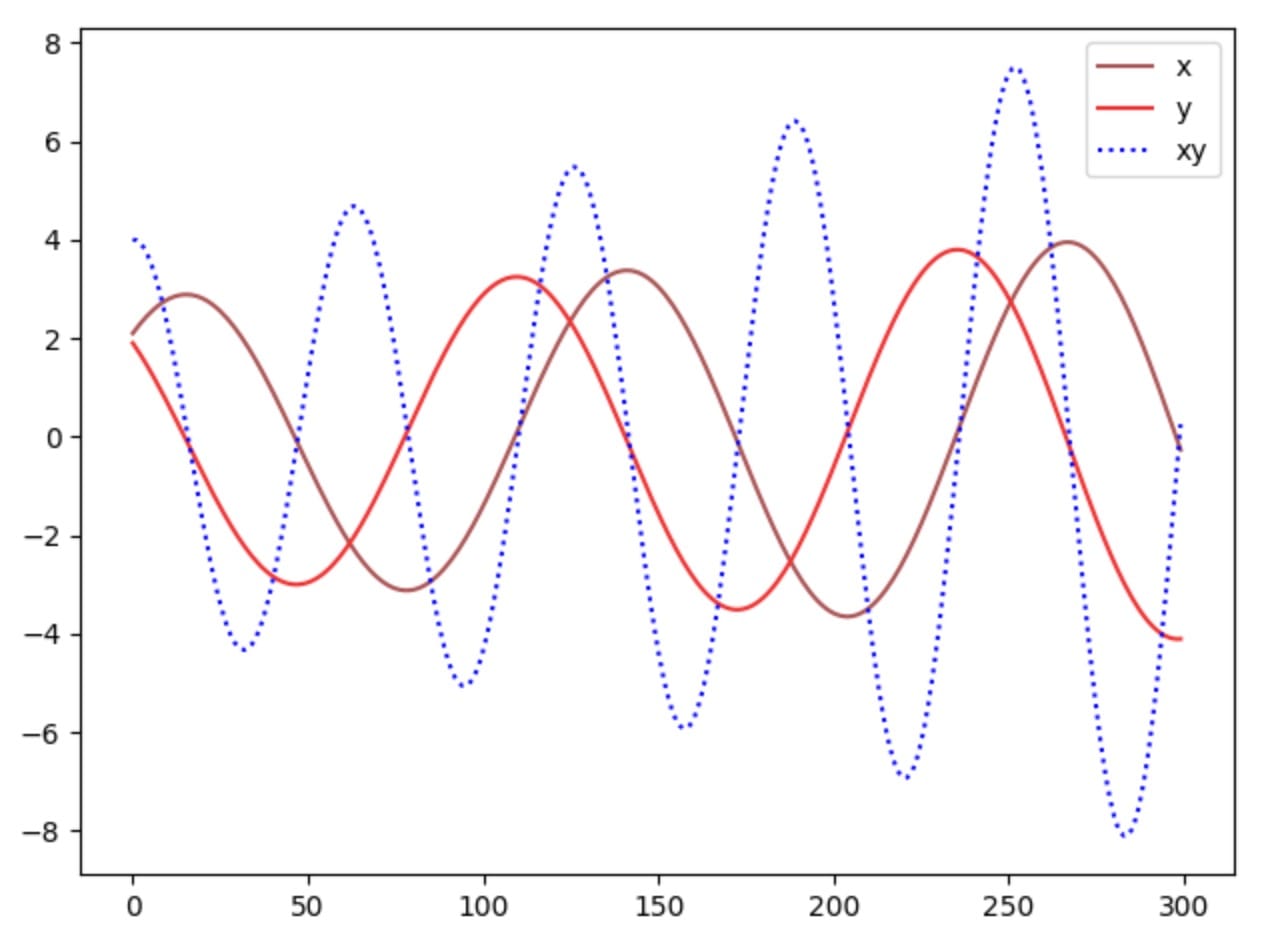
如果我們提高學習率或更長時間訓練模型,我們可以看到參數x,y在大擺動時不穩定。
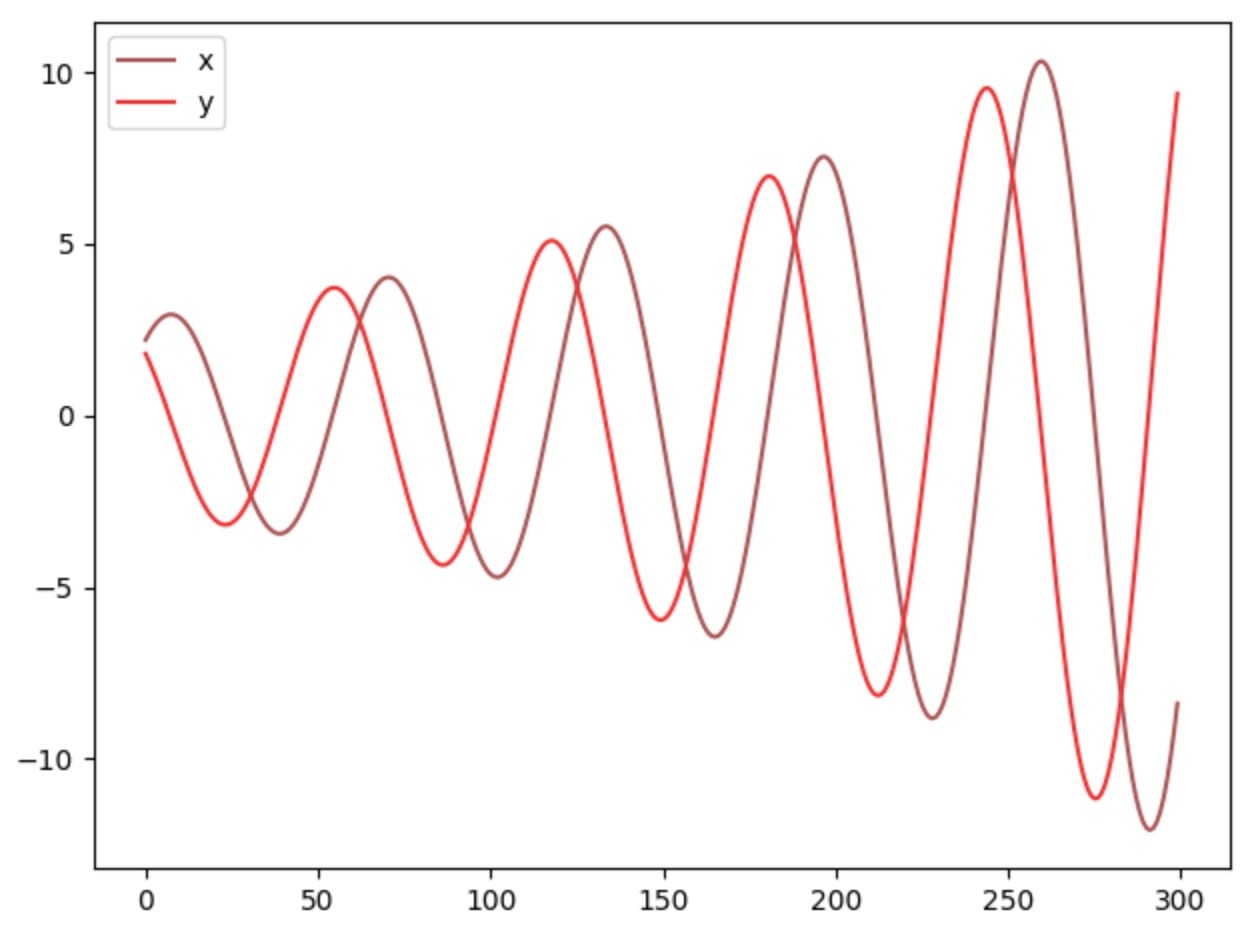
我們的例子是一個很好的展示,一些成本函數不會與梯度下降收斂,特別是對於非凸遊戲。我們也可以直觀地看待這個問題:你的對手總是對你的行為採取對策,這使得模型更難以收斂。
在極小極大遊戲中,使用梯度下降可能無法收斂成本函數。
KL-Divergence的生成模型
為了理解GAN中的收斂問題,我們將首先研究KL-divergence和JS-divergence。在GAN之前,許多生成模型創建了最大化最大似然估計MLE的模型θ 。即找到最適合訓練數據的最佳模型參數。

這與最小化KL-發散KL(p,q)(證明)相同,其測量概率分佈q(估計分佈)如何偏離預期概率分佈p(實際分佈)。

KL-發散不是對稱的。
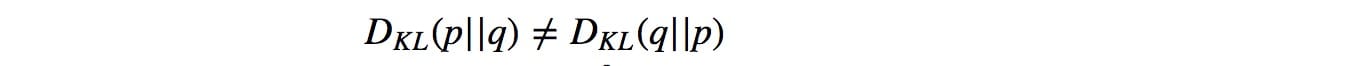
對於 p(x)→0的區域, KL(x)下降到 0。例如,在右下圖中,紅色曲線對應於 D(p,q)。降至當零 X> 2,其中 p接近0。
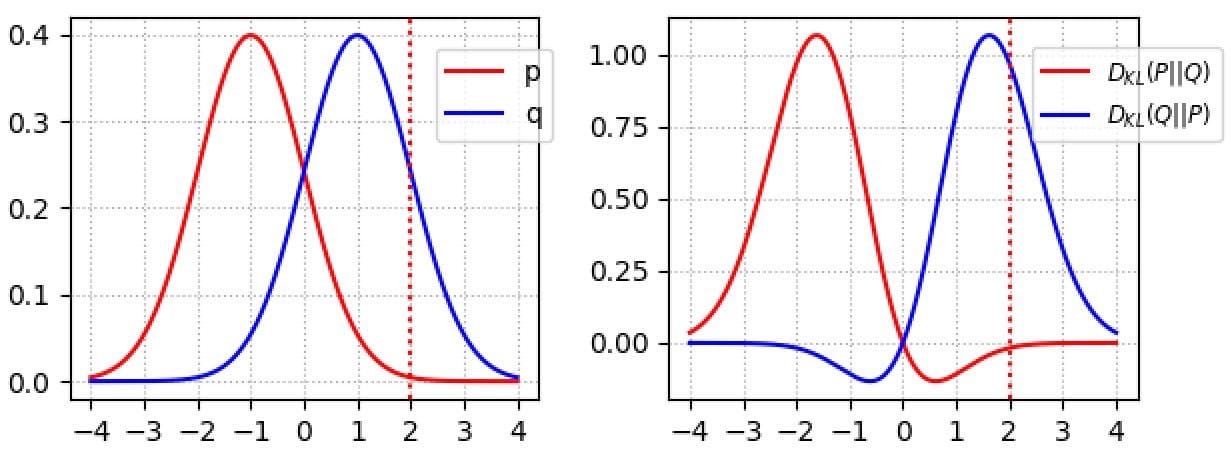
有什麼含義?如果發生錯過某些圖像模式,則KL-發散DL(p,q)懲罰發生器:懲罰高,其中p(x)> 0但q(x)→0。然而,一些圖像看起來不真實是可以接受的。當p(x)→0但q(x)> 0時,懲罰很低。(質量較差但樣品更多樣)
另一方面,如果圖像看起來不真實,則反向KL-發散DL(q,p)懲罰發生器:如果p(x)→0但q(x)> 0則高懲罰。但它探討了較少的變化:如果q(x)→0但p(x)> 0則低懲罰。(質量更好但樣品更少樣)
一些生成模型(除GAN之外)使用MLE(aka KL-divergence)來創建模型。最初認為KL-發散導致較差的圖像質量(模糊圖像)。但要注意的是,一些經驗實驗可能會對這一說法提出異議。
JS-發散
JS-divergence定義為:
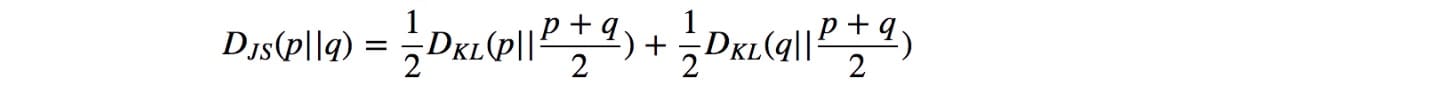
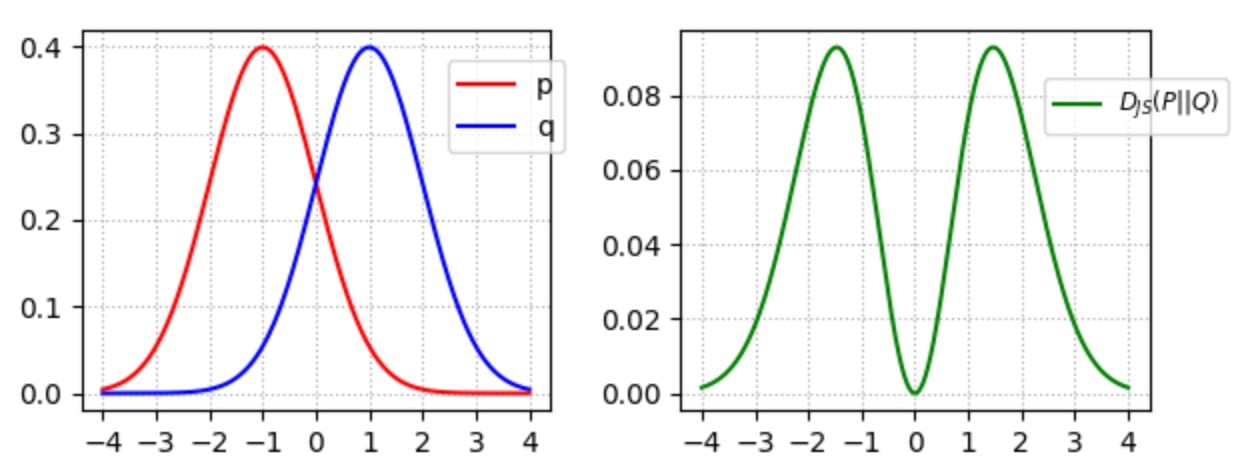
JS-分歧是對稱的。與KL-divergence不同,它會嚴重懲罰糟糕的圖像。(當p(x)→0且q(x)> 0時)在GAN中,如果鑒別器是最優的(在區分圖像中表現良好),則生成器的目標函數變為(證明):
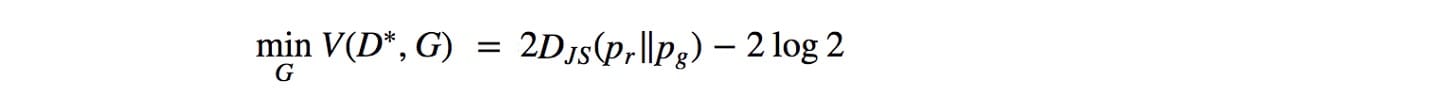
因此優化生成器模型被視為優化JS分歧。在實驗中,與使用KL-發散的其他生成模型相比,GAN產生更好的圖像。按照上一節中的邏輯,早期的研究推測,優化JS-發散而不是KL-發散,可以創建更好但不太多樣化的圖像。然而,一些研究人員已經收回了這些說法,因為使用MLE的GAN實驗產生的圖像質量相似但仍然存在圖像多樣性問題。但是,在研究GAN訓練中JS-Divergence的弱點時,已經做了很多努力。無論辯論如何,這些作品都很重要。因此,接下來我們將深入探討JS分歧的問題。
JS-Divergence中消失的漸變
回想一下,當鑒別器是最優的時,發生器的目標函數是:
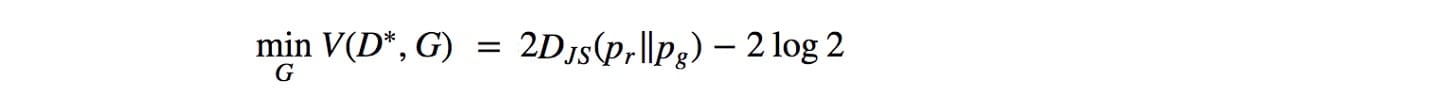
發生了JS-發散梯度什麼當數據分佈q發電機的圖像並不與地面真相匹配p為實像。讓我們考慮一個例子,其中p和q是高斯分佈的,p的平均值是零。讓我們用不同的方法考慮q來研究JS(p,q)的梯度。
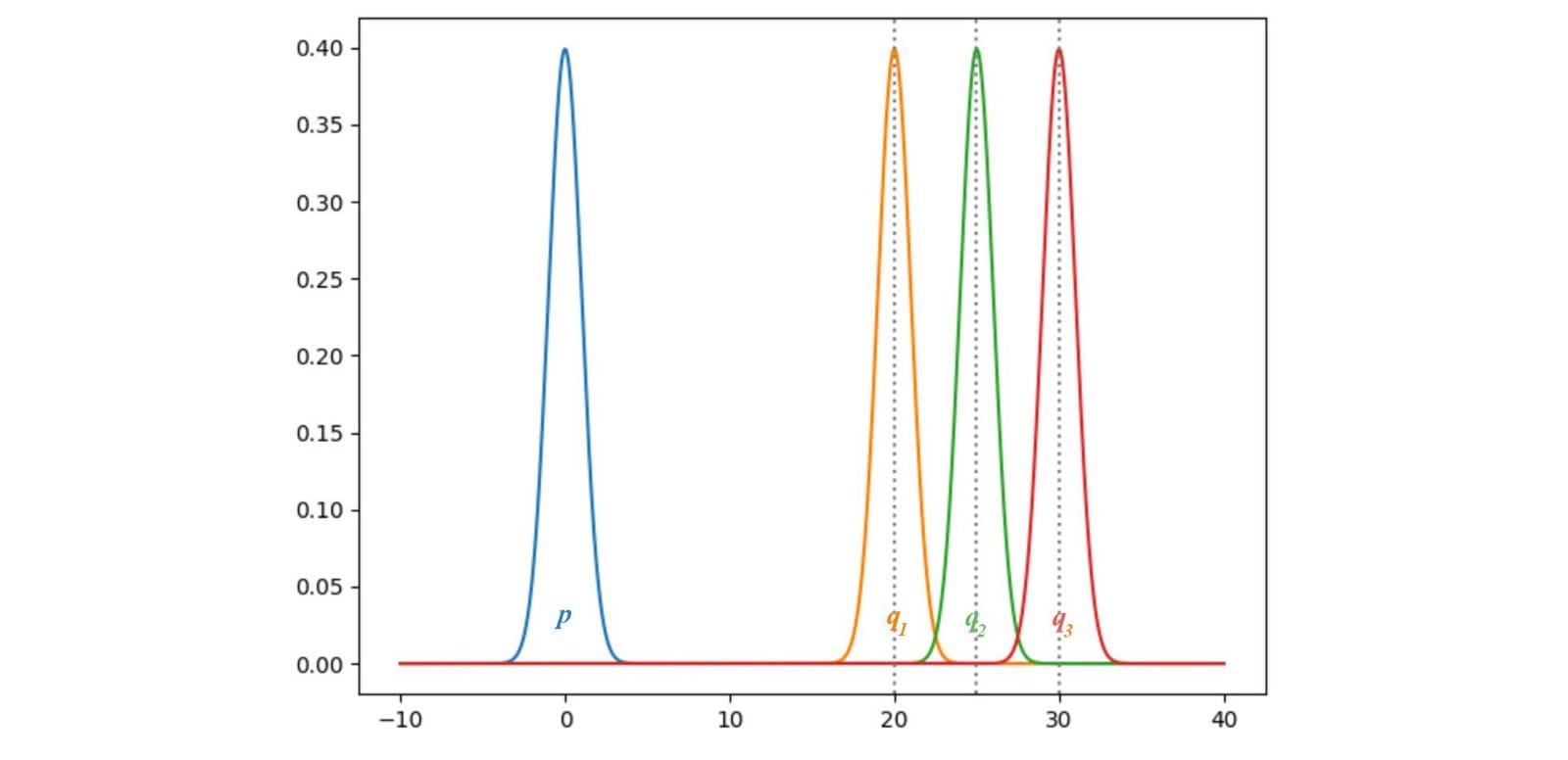
這裡,我們繪製p和q之間的JS-發散JS(p,q),其中q的範圍從0到30.如下所示,JS-發散的梯度從q1消失到q3。當這些地區的成本飽和時,GAN發電機將學會極其緩慢。特別是在早期訓練中,p和q是非常不同的,並且發生器學習非常慢。
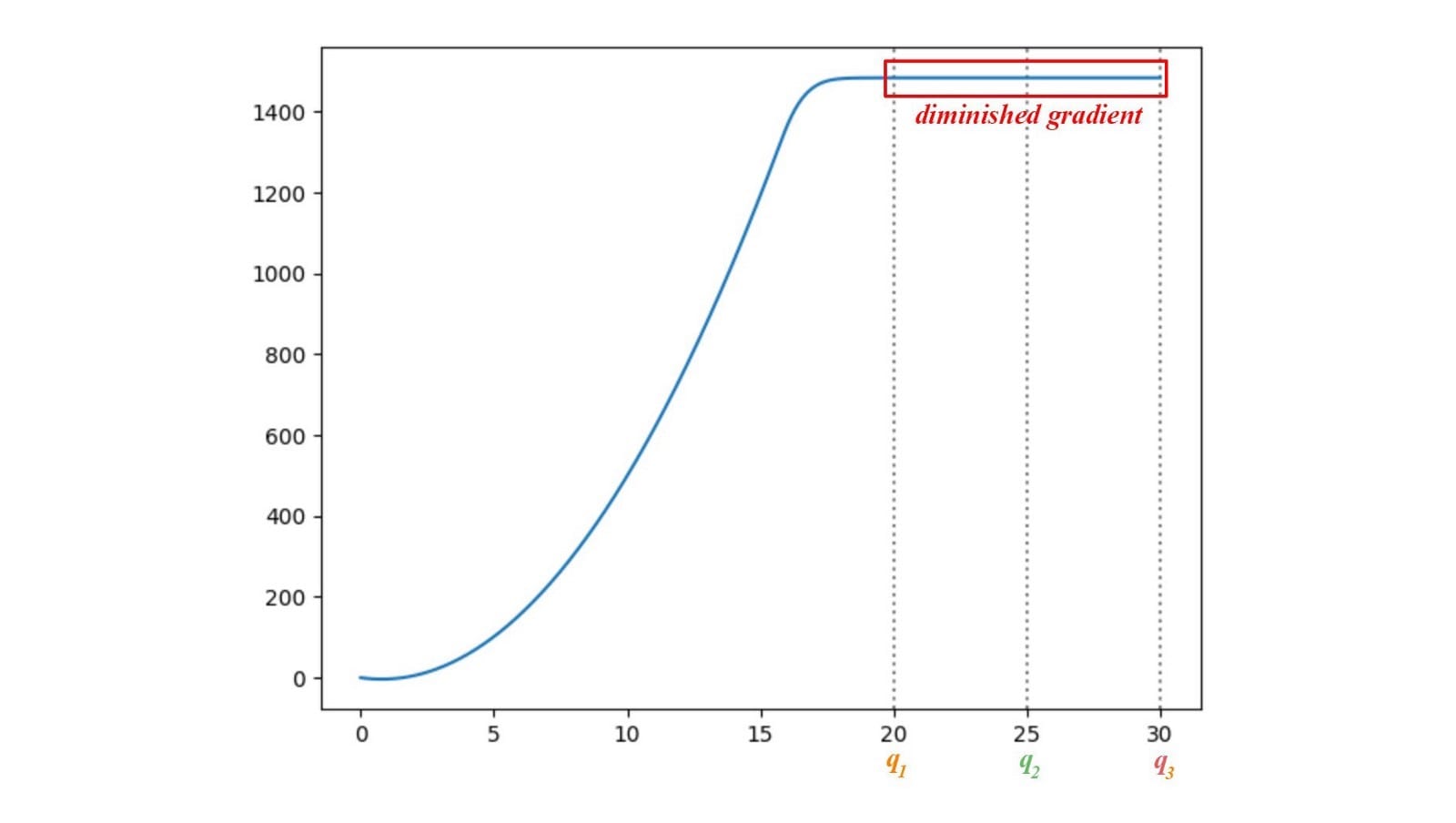
不穩定的漸變
由於梯度消失,原始GAN論文提出了另一種成本函數來解決梯度消失問題。

根據Arjovsky的另一篇研究論文,相應的梯度是:
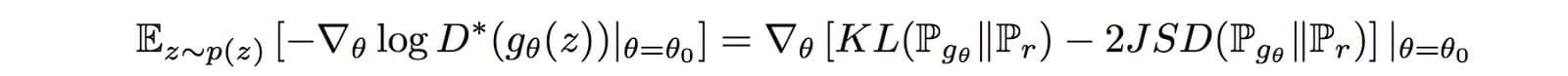
它包括一個反向 KL-發散項,Arjovsky使用它來解釋為什麼GAN與基於KL-發散的生成模型相比具有更高的質量但更少的圖像。但同樣的分析聲稱梯度波動並導致模型不穩定。為了說明這一點,Arjovsky凍結髮電機並持續訓練判別器。隨着更大的變體,發電機的梯度開始增加。
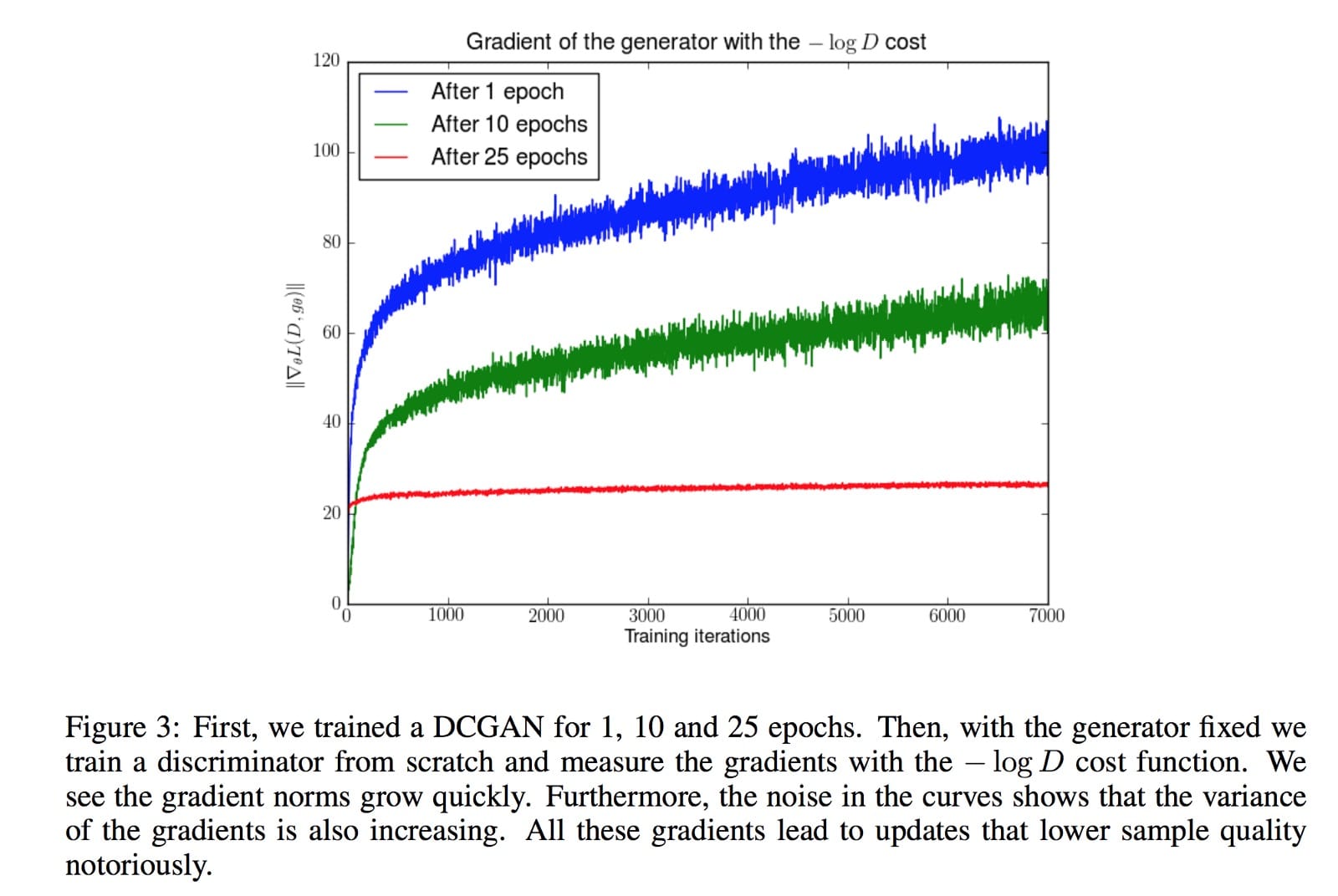
上面的實驗不是我們訓練GAN的方式。然而,在數學上,Arjovsky顯示第一個GAN發生器的目標函數具有消失的梯度,而替代成本函數具有波動的梯度,導致模型的不穩定性。自最初的GAN論文以來,尋找新的成本函數,如LSGAN,WGAN,WGAN-GP,BEGAN等都有淘金熱……有些方法基於新的數學模型,其他方法基於直覺通過實驗備份。目標是找到具有更平滑和非消失梯度的成本函數。
然而,2017年谷歌腦論文「GAN創建平等?」聲稱最後,我們沒有發現任何經過測試的算法始終優於原始算法的證據。
如果任何新提出的成本函數在提高圖像質量方面取得了巨大成功,我們就不會有這種爭論。關於Arjovsky數學模型中原始成本函數的世界末日圖片也沒有完全實現。但我會謹慎地提醒讀者過早宣布成本函數並不重要。我可以在這裡找到我對Google Brain論文的看法。我的看法是什麼?訓練GAN很容易失敗。而不是在開始時嘗試許多成本函數,首先調試您的設計和代碼。接下來嘗試調整超參數,因為GAN模型對它們很敏感。在隨機嘗試成本函數之前這樣做。
為什麼模式在GAN崩潰?
模式崩潰是GAN中最難解決的問題之一。徹底崩潰並不常見,但經常發生部分崩潰。下面帶有相同下劃線顏色的圖像看起來相似,模式開始摺疊。

讓我們看看它是如何發生的。GAN生成器的目標是創建可以最大程度地欺騙鑒別器D的圖像。

但是讓我們考慮一個極端情況,即G在沒有更新D的情況下進行廣泛訓練。生成的圖像將收斂以找到最佳圖像x *,該圖像最愚弄D,從鑒別器角度來看最逼真的圖像。在這個極端情況下,x *將獨立於z。
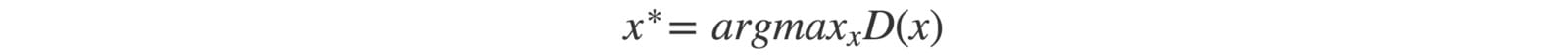
這是壞消息。模式摺疊為單點。與z相關的梯度接近零。
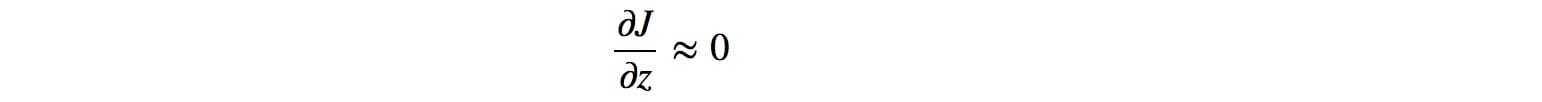
當我們在鑒別器中重新開始訓練時,檢測生成圖像的最有效方法是檢測這種單一模式。由於發生器已經對z的影響不敏感,因此來自鑒別器的梯度可能會將單點推到下一個最脆弱的模式。這不難發現。發電機在訓練中產生這種不平衡的模式,這會降低其檢測其他模式的能力。現在,兩個網絡都過度裝配,以利用短期對手的弱點。這變成了貓捉老鼠的遊戲,模型不會收斂。
在下圖中,Unroll GAN設法生成所有8種預期的數據模式。第二行顯示另一個GAN,當鑒別器趕上時,模式摺疊並旋轉到另一個模式。
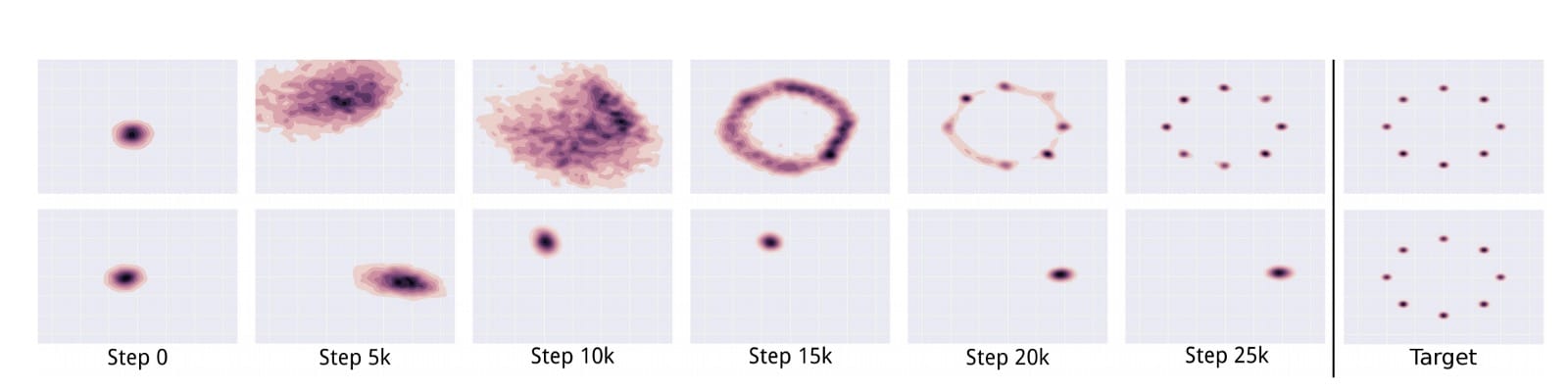
在訓練期間,不斷更新鑒別器以檢測對手。因此,發電機不太可能過度裝配。在實踐中,我們對模式崩潰的理解仍然有限。我們上面的直觀解釋可能過於簡單了。通過經驗實驗開發並驗證了緩解方法。然而,GAN訓練仍然是一個啟發式過程。部分崩潰仍然很常見。
但模式崩潰並非都是壞消息。在使用GAN的樣式傳輸中,我們很樂意將一個圖像轉換為一個好的圖像,而不是找到所有變體。實際上,局部模式崩潰的專業化有時會產生更高質量的圖像。但模式崩潰仍然是GAN要解決的最重要問題之一。
超參數和培訓
如果沒有好的超參數,沒有成本函數可以工作,調整它們需要時間和耐心。新的成本函數可能會引入具有敏感性能的超參數。超參數調整需要耐心。如果不花時間在超參數調整上,任何成本函數都無法工作。
鑒別器和發生器之間的平衡
非收斂和模式崩潰通常被解釋為鑒別器和發生器之間的不平衡。顯而易見的解決方案是平衡他們的訓練以避免過度擬合。然而,很少取得進展,但並非因為缺乏嘗試。一些研究人員認為,這不是一個可行或理想的目標,因為良好的鑒別器可以提供良好的反饋。因此,一些注意力轉移到具有非消失梯度的成本函數。
成本與圖像質量
在判別模型中,損失測量預測的準確性,並使用它來監控培訓的進度。但是,與對手相比,GAN的損失衡量了我們的表現。通常,發電機成本增加但圖像質量實際上正在提高。我們回過頭來手動檢查生成的圖像以驗證進度。這使得模型比較更難以導致在單次運行中挑選最佳模型的困難。它還使調整過程複雜化。
進一步閱讀
現在您聽到了問題,您可能希望聽到解決方案。我們提供兩種不同的文章。第一個提供解決方案的關鍵摘要。GAN – 對GAN歹徒的綜合評論(第二部分)
本文研究了GAN研究在改進GAN方面的動機和方向。通過在…media.com中查看它們
如果你想要更深入,第二個將有更深入的討論:GAN – 改善GAN性能的方法與
其他深度網絡相比,GAN模型在以下方面可能會受到嚴重影響。medium.com
如果你想進一步研究梯度和穩定性問題的數學模型,下面的文章將詳細闡述它。但要注意,方程式可能看起來勢不可擋。但是,如果你不害怕方程式,那麼就可以對它們的一些主張提供很好的推理。GAN – GAN成本函數有什麼問題?
我們努力為深度學習提供數學模型。但通常情況下,我們並沒有成功,而是回到了…medium.com

Comments