

本文轉自公眾號 量子位,原文地址
對於大腦的工作原理,我們知之甚少,但是我們知道大腦能通過反覆嘗試來學習知識。我們做出合適選擇時會得到獎勵,做出不切當選擇時會受到懲罰,這也是我們來適應環境的方式。如今,我們可以利用強大的計算能力,在軟體中對這個具體過程進行建模,這就是強化學習。
最近,Algorithmia博客上的一篇文章,從基礎知識、決策過程、實際應用、實踐挑戰和學習資源五個方面,詳細地介紹了強化學習。量子位搬運過來,以下為譯文:
基礎知識
我們可以用電子遊戲來理解強化學習(Reinforcement Learning, RL),這是一種最簡單的心智模型。恰好,電子遊戲也是強化學習演算法中應用最廣泛的一個領域。在經典電子遊戲中,有以下幾類對象:
- 代理(agent,即智能體),可自由移動,對應玩家;
- 動作,由代理做出,包括向上移動和出售物品等;
- 獎勵,由代理獲得,包括金幣和殺死其他玩家等;
- 環境,指代理所處的地圖或房間等;
- 狀態,指代理的當前狀態,如位於地圖中某個特定方塊或房間中某個角落;
- 目標,指代理目標為獲得儘可能多的獎勵;
上面這些對象是強化學習的具體組成部分,當然也可仿照得到機器學習的各部分。在強化學習中,設置好環境後,我們能通過逐個狀態來指導代理,當代理做出正確動作時會得到獎勵。如果你了解馬爾科夫決策過程(https://en.wikipedia.org/wiki/Markov_decision_process),那就能更好理解上述過程。
下圖的迷宮中,有一隻老鼠:

想像下你是那隻老鼠,為了在迷宮中儘可能多地收集獎勵(水滴和乳酪),你會怎麼做?在每個狀態下,即迷宮中的位置,你要計算出為獲得附近獎勵需要採取哪些步驟。當右邊有3個獎勵,左邊有1個獎勵,你會選擇往右走。
這就是強化學習的工作原理。在每個狀態下,代理會對所有可能動作(上下左右)進行計算和評估,並選擇能獲得最多獎勵的動作。進行若干步後,迷宮中的小鼠會熟悉這個迷宮。
但是,該如何確定哪個動作會得到最佳結果?
決策過程
強化學習中的決策(Decision Making),即如何讓代理在強化學習環境中做出正確動作,這裡給了兩個方式。
策略學習
策略學習(Policy Learning),可理解為一組很詳細的指示,它能告訴代理在每一步該做的動作。這個策略可比喻為:當你靠近敵人時,若敵人比你強,就往後退。我們也可以把這個策略看作是函數,它只有一個輸入,即代理當前狀態。但是要事先知道你的策略並不是件容易事,我們要深入理解這個把狀態映射到目標的複雜函數。
用深度學習來探索強化學習場景下的策略問題,這方面有一些有趣研究。Andrej Karpathy構建了一個神經網路來教代理打乒乓球(http://karpathy.github.io/2016/05/31/rl/)。這聽起來並不驚奇,因為神經網路能很好地逼近任意複雜的函數。
Q-Learning演算法
另一個指導代理的方式是給定框架後讓代理根據當前環境獨自做出動作,而不是明確地告訴它在每個狀態下該執行的動作。與策略學習不同,Q-Learning演算法有兩個輸入,分別是狀態和動作,並為每個狀態動作對返回對應值。當你面臨選擇時,這個演算法會計算出該代理採取不同動作(上下左右)時對應的期望值。
Q-Learning的創新點在於,它不僅估計了當前狀態下採取行動的短時價值,還能得到採取指定行動後可能帶來的潛在未來價值。這與企業融資中的貼現現金流分析相似,它在確定一個行動的當前價值時也會考慮到所有潛在未來價值。由於未來獎勵會少於當前獎勵,因此Q-Learning演算法還會使用折扣因子來模擬這個過程。
策略學習和Q-Learning演算法是強化學習中指導代理的兩種主要方法,但是有些研究者嘗試使用深度學習技術結合這兩者,或提出了其他創新解決方案。DeepMind提出了一種神經網路(https://storage.googleapis.com/deepmind-media/dqn/DQNNaturePaper.pdf),叫做深度Q網路(Deep Q Networks, DQN),來逼近Q-Learning函數,並取得了很不錯的效果。後來,他們把Q-Learning方法和策略學習結合在一起,提出了一種叫A3C的方法(https://arxiv.org/abs/1602.01783)。
把神經網路和其他方法相結合,這樣聽起來可能很複雜。請記住,這些訓練演算法都只有一個簡單目標,就是在整個環境中有效指導代理來獲得最大回報。
實際應用
雖然強化學習研究已經開展了數十年,但是據報告指出,它在當前商業環境中的落地還十分有限(https://www.oreilly.com/ideas/practical-applications-of-reinforcement-learning-in-industry)。這裡面有很多方面原因,但都面臨一個共同問題:強化學習在一些任務上的表現與當前應用演算法仍有一定差距。
過去十年中,強化學習的大部分應用都在電子遊戲方面。最新的強化學習演算法在經典和現代遊戲中取得了很不錯的效果,在有些遊戲中還以較大優勢擊敗了人類玩家。
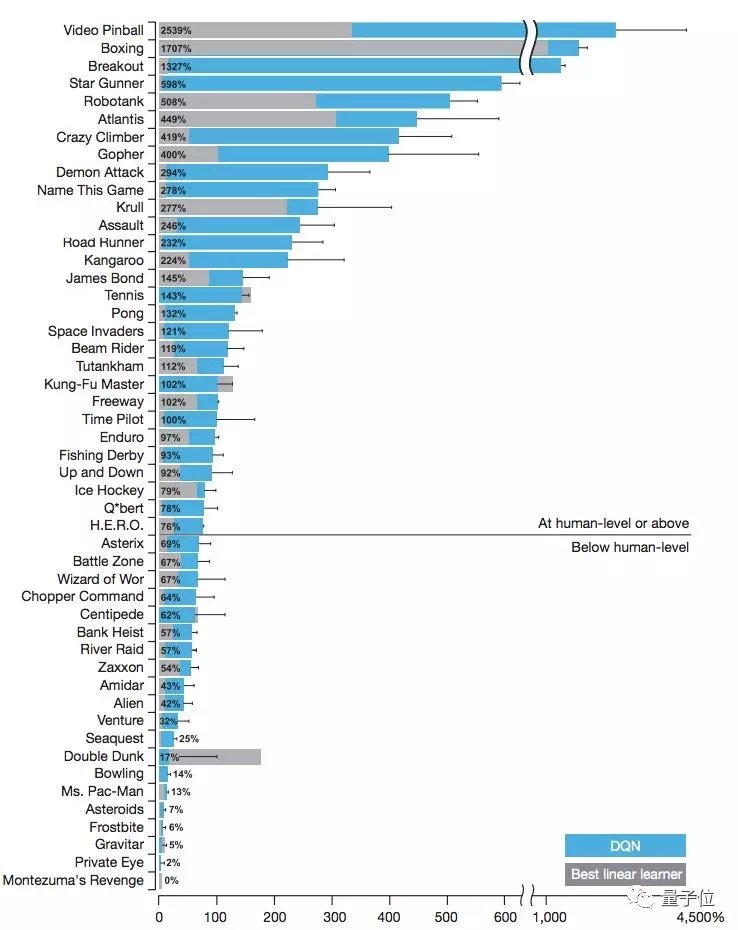
上圖源自DeepMind的DQN論文。在超過一半的測試遊戲中,論文中的代理能夠優於人類測試基準,通常為人類水平的兩倍。但在一些遊戲中,這個演算法的表現差於人類水平。
強化學習在機器人和工業自動化方面也有一些成功的實際應用。我們可以把機器人理解成環境中的代理,而強化學習已被證明是一種可行的指導方案。值得一提的是,Google還使用強化學習來降低數據中心的運營成本。
強化學習在醫療和教育方面也有望得到應用,但目前的大多數研究還處於實驗室階段。
實踐挑戰
強化學習的應用前景十分光明,但是實踐道路會很曲折。

第一是數據問題。強化學習通常需要大量訓練數據才能達到其他演算法能高效率達到的性能水平。DeepMind最近提出一個新演算法,叫做RainbowDQN,它需要1800萬幀Atari遊戲界面,或大約83小時遊戲視頻來訓練模型,而人類學會遊戲的時間遠遠少於演算法。這個問題也出現在步態學習的任務中。
強化學習在實踐中的另一個挑戰是領域特殊性(domain-specificity)。強化學習是一種通用演算法,理論上應該適用於各種不同類型的問題。但是,這其中的大多數問題都有一個具有領域特殊性的解決方案,往往效果優於強化學習方法,如MuJuCo機器人的在線軌跡優化。因此,我們要在權衡範圍和強度之間的關係。
最後,在強化學習中,目前最迫切的問題是設計獎勵函數。在設計獎勵時,演算法設計者通常會帶有一些主觀理解。即使不存在這方面問題,強化學習在訓練時也可能陷入局部最優值。
上面提到了不少強化學習實踐中的挑戰問題,希望後續研究能不斷解決這些問題。
學習資源
函數庫
1、RL-Glue:提供了一個能將強化學習代理、環境和實驗程序連接起來的標準界面,且可進行跨語言編程。
http://glue.rl-community.org/wiki/Main_Page
2、Gym:由OpenAI開發,是一個用於開發強化學習演算法和性能對比的工具包,它可以訓練代理學習很多任務,包括步行和玩乒乓球遊戲等。
3、RL4J:是集成在deeplearning4j庫下的一個強化學習框架,已獲得Apache 2.0開源許可。
https://github.com/deeplearning4j/rl4j
4、TensorForce:一個用於強化學習的TensorFlow庫。
https://github.com/reinforceio/tensorforce
論文集
1、用通用強化學習演算法自我對弈來掌握國際象棋和將棋
題目:Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
https://arxiv.org/abs/1712.01815
這篇文章有13位作者,提出了AlphaZero方法。在這篇論文中,作者將先前的AlphaGo Zero方法推廣到一個單一的AlphaZero演算法,它可以在多個具有挑戰性的領域實現超越人類的性能,同樣利用的是「白板」強化學習(「白板」指的是所有知識均由感官和經驗得來,即從零開始的學習)。從隨機下棋開始,除了遊戲規則外,沒有輸入任何領域知識,AlphaZero在24小時內實現了在國際象棋、將棋和圍棋上超越人類水平的表現,並且在這三種棋上都以令人信服的成績擊敗了當前的世界冠軍程序。
2、深化強化學習綜述
題目:Deep Reinforcement Learning: An Overview
https://arxiv.org/abs/1701.07274
這篇論文概述了深度強化學習中一些最新精彩工作,主要說明了六個核心要素、六個重要機制和十二個有關應用。文章中先介紹了機器學習、深度學習和強化學習的背景,接著討論了強化學習的核心要素,包括DQN網路、策略、獎勵、模型、規劃和搜索。
3、用深度強化學習玩Atari遊戲
題目:Playing Atari with Deep Reinforcement Learning
https://arxiv.org/abs/1312.5602
這是DeepMind公司2014年的NIPS論文。這篇論文提出了一種深度學習方法,利用強化學習的方法,直接從高維的感知輸入中學習控制策略。該模型是一個卷積神經網路,利用Q-learning的變體來進行訓練,輸入是原始像素,輸出是預測未來獎勵的價值函數。此方法被應用到Atari 2600遊戲中,不需要調整結構和學習演算法,在測試的七個遊戲中6個超過了以往方法並且有3個超過人類水平。
4、用深度強化學習實現人類水平的控制
題目:Human-Level Control Through Deep Reinforcement Learning
https://web.stanford.edu/class/psych209/Readings/MnihEtAlHassibis15NatureControlDeepRL.pdf
這是DeepMind公司2015年的Nature論文。強化學習理論根植於關於動物行為的心理學和神經科學,它可以很好地解釋代理如何優化他們對環境的控制。為了在真實複雜的物理世界中成功地使用強化學習演算法,代理必須面對這個困難任務:利用高維的感測器輸入數據,推導出環境的有效表徵,並把先前經驗泛化到新的未知環境中。
講座教程
1、強化學習(Georgia Tech, CS 8803)
https://www.udacity.com/course/reinforcement-learning—ud600
官網介紹:如果你對機器學習感興趣並且希望從理論角度來學習,你應該選擇這門課程。本課程通過介紹經典論文和最新工作,帶大家從計算機科學角度去探索自動決策的魅力。本課程會針對單代理和多代理規劃以及從經驗中學習近乎最佳決策這兩個問題,來研究相應的高效演算法。課程結束後,你將具備復現強化學習中已發表論文的能力。
2、強化學習(Stanford, CS234)
http://web.stanford.edu/class/cs234/index.html
官網介紹:要實現真正的人工智慧,系統要能自主學習並做出正確的決定。強化學習是一種這樣的強大範式,它可應用到很多任務中,包括機器人學、遊戲博弈、消費者建模和醫療服務。本課程詳細地介紹了強化學習的有關知識,你通過學習能了解當前面臨問題和主要方法,也包括如何進行泛化和搜索。
3、深度強化學習(Berkeley, CS 294, Fall 2017)
http://rll.berkeley.edu/deeprlcourse/
官網介紹:本課程需要一定的基礎知識,包括強化學習、數值優化和機器學習。我們鼓勵對以下概念不熟悉的學習提前閱讀下方提供的參考資料。課堂上開始前會簡單回顧下這些內容。
4、用Python玩轉深度強化學習(Udemy高級教程)
https://www.udemy.com/deep-reinforcement-learning-in-python/
官網介紹:本課程主要介紹有關深度學習和神經網路在強化學習中的應用。本課程需要一定的基礎知識(包括強化學習基礎、馬爾可夫決策、動態編程、蒙特卡洛搜索和時序差分學習),以及深度學習基礎編程。

Comments