

「 Artificial-Intelligently Challenged 」
前言
大家好,我又出來懟人了。
兩年前,寫了一篇文章《為什麼現在的人工智慧助理都像人工智障》,當時主要是懟「智能助理們」。這次呢則是表達 「我不是針對誰,只是現在所有的深度學習都搞不定對話AI」,以及「你看都這樣了,那該怎麼做AI產品」。
– 閱讀門檻 –
- 時間:這篇真的太長了(近3萬字)根據預覽同學們的反饋,通常第一次閱讀到Part 3時,會消耗很多精力,但讀完Part 3才發現是精華(同時也是最燒腦的部分)。請大家酌情安排閱讀時間。
- 可讀性:我會在內容里邀請你一起思考(無需專業知識),所以可能不適合通勤時間閱讀。你的閱讀收益取決於在過程中思考的參與程度。
- 適合人群:對話智能行業從業者、AIPM、關注AI的投資人、對AI有強烈興趣的朋友、關心自己的工作會不會被AI代替的朋友;
- 關於鏈接:閱讀本文時,無需閱讀每個鏈接里的內容,這並不會影響對本文的理解。
– 關於「人工智障」四個字 –
上一片文章發出後,有朋友跟我說,標題里的「人工智障」這個詞貌似有點offensive。作為學語言出身的,我來解釋一下這個原因:
最開始呢,我是在跟一位企業諮詢顧問聊人工智慧這個賽道的現狀。因為對話是用英語展開的,當時為了表達我的看法 「現在的智能助理行業正處在一種難以逾越的困境當中」,我就跟她說「Currently all the digital assistants are Artificial-Intelligently challenged」。
她聽了之後哈哈一笑。「intelligently challenged」同時也是英文中對智障的委婉表達。 假設不了解這個常識,她就可能忽略掉這個梗,儘管能明白核心意思,只是不會覺得有什麼好笑的。那麼信息在傳遞中就有損失。
寫文章時,我把這個信息翻譯成中文,就成了「人工智障」。但是因為中文語法的特性,有些信息就lost in translation了。比如實際表達的是「一種困境的狀態」而不是「一件事」。
(順便說一下,中文的智障,實際上是政治正確的稱呼,詳見特殊奧運會的用詞方法。)
為什麼要寫那麼多字來解釋這個措辭?因為不同的人,看見相同的字,也會得到不同的理解。這也是我們要討論的重點之一。
那麼,我們開始吧。
Part 1:對話智能的表現:智障

2017年10月,上圖這個叫Sophia的機器人,被沙烏地阿拉伯授予了正式的公民身份。公民身份,這個評價比圖靈測試還要牛。何況還是在沙特,他們才剛剛允許女性開車不久(2017年9月頒布的法令)。
Sophia經常參加各種會、「發表演講」、「接受採訪」,比如去聯合國對話,表現出來非常類似人類的言談;去和Will Smith拍MV;接受Good morning Britain之類的主流媒體的採訪;甚至公司創始人參加Jim Fallon的訪談時一本正經的說Sophia是「basically alive」。

Basically alive. 要知道,西方的吃瓜群眾都是看著《終結者》長大的,前段時間還看了《西部世界》。在他們的世界模型里,「機器智能會覺醒」 這個設定是遲早都會發生的。
普通大眾開始嚇得瑟瑟發抖。不僅開始擔心自己的工作是不是會被替代,還有很多人開始擔心AI會不會統治人類,這樣的話題展開。「未來已來」,很多人都以為真正的人工智慧已經近在咫尺了。
只是,有些人可能會注意到有些不合理的地方:「等等,人工智慧都要威脅人類了,為啥我的Siri還那麼蠢?」
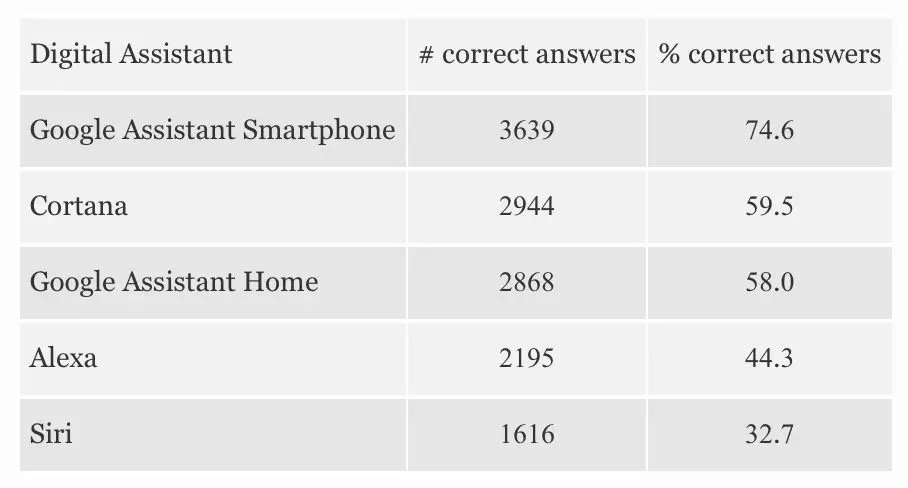
我們來看看到2018年末在對話智能領域,各方面究竟發展的如何了。
「 不要日本菜 」
我在2016年底做過一個測試,對幾個智能助理提一個看似簡單的需求:「推薦餐廳,不要日本菜」。只是各家的AI助理都會給出一堆餐廳推薦,全是日本菜。
2年過去了,在這個問題的處理上有進展么?我們又做了一次測試:

結果是依然沒有解決。「不要」兩個字被所有助理一致忽略了。
為什麼要關注「不要」兩個字?之前我去到一家某非常有名的智能語音創業公司,聊到這個問題時,他家的PM顯出疑惑:「這個邏輯處理有什麼用?我們後台上看到用戶很少提出這類表達啊。」
聽到這樣的評論,基本可以確定:這家公司還沒有深入到專業服務對話領域。
場景方面,一旦深入進服務領域裡的多輪對話,很容易會遇到類似這樣的表達 :「我不要這個,有更便宜的么?」。後台沒有遇到,只能說用戶還沒開始服務就結束了。場景方面與AI公司的domain選擇有關。
但是在技術方面,則是非常重要的。因為這正是真正智能的核心特點。我們將在part 2&3詳細聊聊這個問題。現在先拋個結論:這個問題解決不了,智能助理會一直智障下去的。
「 To C 團隊轉 To B 」
自從2015年幾個重要的深度學習在開發者當中火了起來,大小公司都想做「Her」這樣面對個人消費者的通用型智能助理(To C類產品的終極目標)。一波熱錢投給最有希望的種子隊伍(擁有Fancy背景)之後,全滅。目前為止,在2C這方面的所有商用產品,無論是巨頭還是創業公司,全部達不到用戶預期。
在人們的直覺里,會認為「智能助理」,處理的是一些日常任務,不涉及專業的需求,應該比「智能專家」好做。這是延續「人」的思路。推薦餐廳、安排行程是人人都會做的事情;卻只有少數受過專業訓練的人能夠處理金融、醫療問診這類專業問題。
而對於現在的AI,情況正好相反。現在能造出在圍棋上打敗柯潔的AI,但是卻造不出來能給柯潔管理日常生活的AI。
隨著to C助理賽道的崩盤,To B or not to B已經不再是問題,因為已經沒得選了,只能To B。這不是商業模式上的選擇,而是技術的限制。目前To B,特別是限定領域的產品,相對To C類產品更可行:一個原因是領域比較封閉,用戶從思想到語言,不容易發揮跑題;另一方面則是數據充分。
只是To B的公司都很容易被當成是做「外包」的。因為客戶是一個個談下來的,項目是一個個交付的,這意味著增長慢,靠人堆,沒有複利帶來的指數級增長。大家紛紛表示不開心。
這個「幫人造機器人」的業務有點像「在網頁時代幫人建站」。轉成To B的團隊經常受到資本的質疑: 「你這個屬於做項目,怎麼規模化呢?」
要知道,國內的很多投資機構和裡面的投資經理入行的時間,是在國內的移動互聯起來的那一波。「Scalability」或者「高速增長」是體系里最重要的指標,沒有之一。而做項目這件事,就是Case by case,要增長就要堆人,也就很難出現指數級增長。這就有點尷尬了。
「你放心,我有SaaS!哦不,是AIaaS。我可以打造一個平台,上面有一系列工具,可以讓客戶們自己組裝機器人。」
然而,這些想做技能平台的創業公司,也沒有一個成功的。短期也不可能成功。
主要的邏輯是這樣的:你給客戶提供工具,但他需要的是雕像——這中間還差了一個雕塑家。佐證就是那些各家試圖開放「對話框架」給更小的開發者,甚至是服務提供者,幫助他們「3分鐘開發出自己的AI機器人」,具體就不點名了。自己都開發不出來一個讓人滿意的產品,還想抽象一個範式出來讓別人沿用你的(不work的)框架?
不過,我認為MLaaS在長期的成功是有可能的,但還需要行業發展更為成熟的時候,現在為時尚早。具體分析我們在後面Part 5會談到。
「 音箱的成功和智能的失敗 」
對話這個領域,另一個比較火的賽道是智能音箱。
各大主要科技公司都出了自己的智能音箱,騰訊叮噹、阿里的天貓精靈、小米音箱、國外的Alexa、Google的音箱等等。作為一個硬體品類,這其實是個還不錯的生意,基本屬於製造業。
不僅出貨不差,還被寄予期望,能夠成為一個生態的生意——核心邏輯看上去也是充滿想像力的:
- 超級終端:在後移動時代,每家都想像iphone一樣搶用戶的入口。只要用戶習慣使用語音來獲得諮詢或者服務,甚至可以像Xbox/ps一樣,硬體賠錢賣,軟體來掙錢;
- 用語音做OS:開發者打造各類語音的技能,然後通過大量「離不開的技能」 反哺這個OS的市場佔有;
- 提供開發者平台:像Xcode一樣,給開發者提供應用開發的工具和分發平台、提供使用服務的流量。
可是,這些技能使用的實際情況是這樣的:
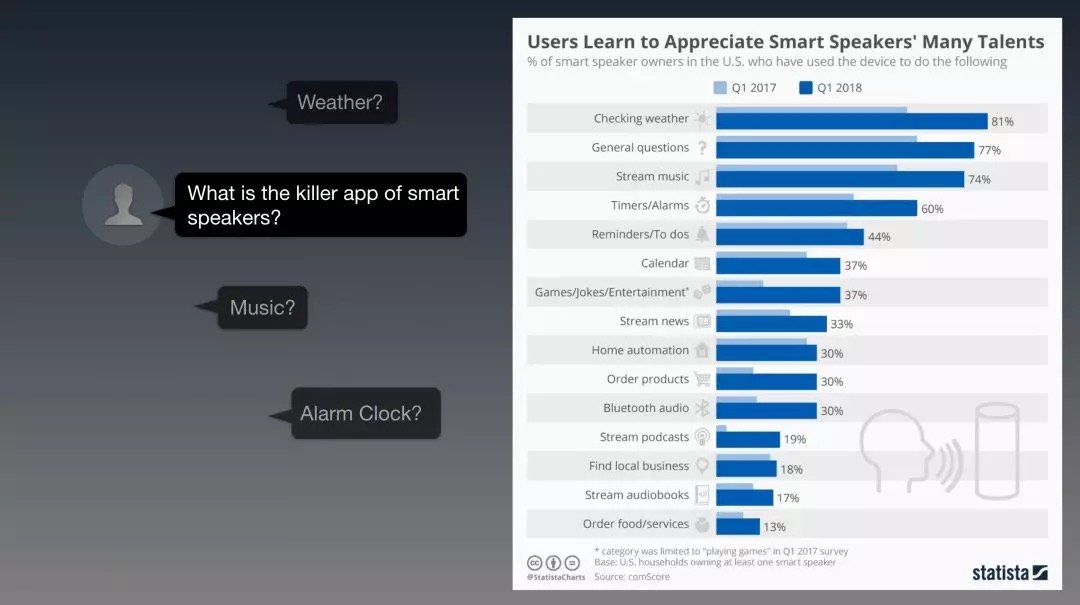
- 萬眾期待的killer app並沒有出現;
- 基本沒有商業服務型的應用;
- 技能開發者都沒賺到錢,也不知道怎麼賺錢;
- 大部分高頻使用的技能都沒有商業價值——用戶用的最多的就是「查天氣」
- 沒有差異性:智能的差異嘛基本都沒有的事兒。
「 皇帝的新人工智慧 」
回過頭來,我們再來看剛剛那位沙烏地阿拉伯的公民,Sophia。既然剛剛提到的那麼多公司投入了那麼多錢和科學家,都搞成這樣,憑什麼這個Sophia能一鳴驚人?
因為Sophia的「智能」 是個騙局。
可以直接引用Yann LeCun對此的評價, 「這完全是鬼扯」。
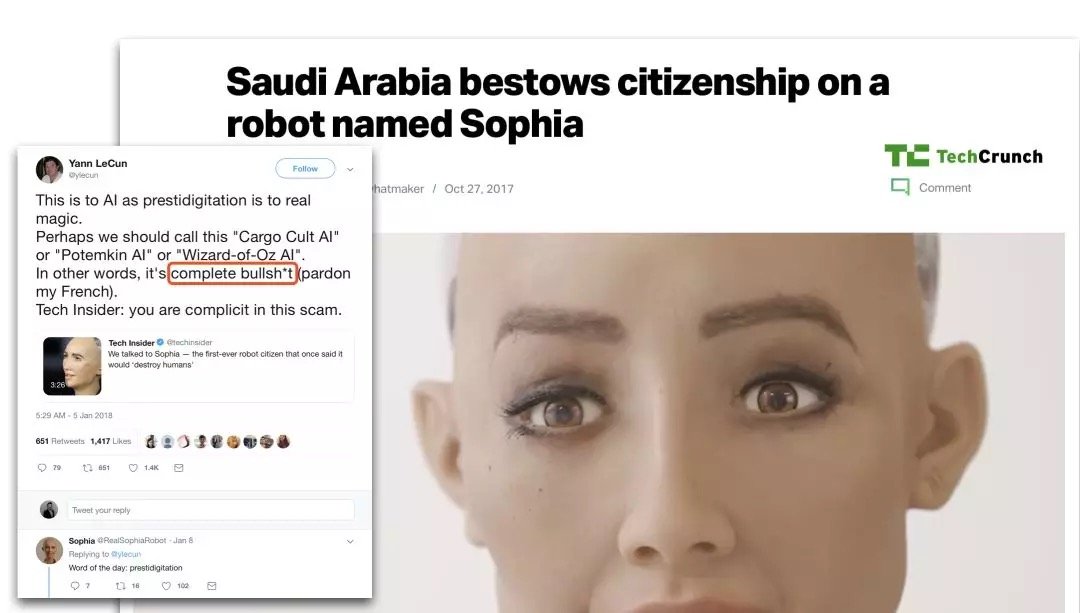
簡單來說,Sophia是一個帶喇叭的木偶——在各種大會上的發言和採訪的內容都是人工撰寫,然後用人人都有的語音合成做輸出。卻被宣傳成為是其「人工智慧」的自主意識言論。
這還能拿「公民身份」,可能是人類公民被黑的最慘的一次。這感覺,好像是我家的橘貓被一所985大學授予了土木工程學士學位。
其實對話系統里,用人工來撰寫內容,或者使用模版回復,這本來就是現在技術的現狀(在後面我們會展開)。
但刻意把「非智能」的產物說成是「智能」的表現,這就不對了。
考慮到大部分吃瓜群眾是通過媒體渠道來了解當前技術發展的,跟著炒作的媒體(比如被點名的Tech Insider)都是這場騙局的共犯。這些不知道是無知還是無良的文科生,真的沒有做好新聞工作者份內的調查工作。
最近這股妖風也吹到了國內的韭菜園裡。

Sophia出現在了王力宏的一首講AI的MV里;然後又2018年11月跑去給大企業站台。
真的,行業內認真做事兒的小夥伴,都應該站出來,讓大家更清晰的知道現在AI——或者說機器學習的邊界在哪兒。不然甲方爸爸們信以為真了,突然指著sophia跟你說,「 別人都能這麼自然,你也給我整一個。」
你怕不得裝個真人進去?
對了,說到這兒,確實現在也有:用人——來偽裝成人工智慧——來模擬人,為用戶服務。
國內的案例典型的就是銀行用的大堂機器人,其實是真人在遠程語音(所謂Tele presence)。美國有X.ai,做基於Email的日程管理的。只是這個AI到了下午5點就要下班。
當然,假如我是這些騙局背後開發者,被質疑的時候,我還可以強行拉回人工智慧上:「這麼做是為了積累真正的對話數據,以後用來做真的AI對話系統識別的訓練。」
這麼說對外行可能是毫無破綻的。但是真正行業內干正經事的人,都應該像傅盛那樣站出來,指明這些做法是騙人:「全世界沒有一家能做出來……做不到,一定做不到」。
人家沙特是把AI當成人,這些套路是把人當成AI。然後大眾就開始分不清楚究竟什麼是AI了。
「 人工智慧究竟(tmd)指的是什麼?」
另一方面,既然AI現在的那麼蠢,為什麼馬一龍 (Elon Musk) 卻說「AI很有可能毀滅人類」;霍金甚至直接說 「AI可能是人類文明裡最糟糕的事件」。
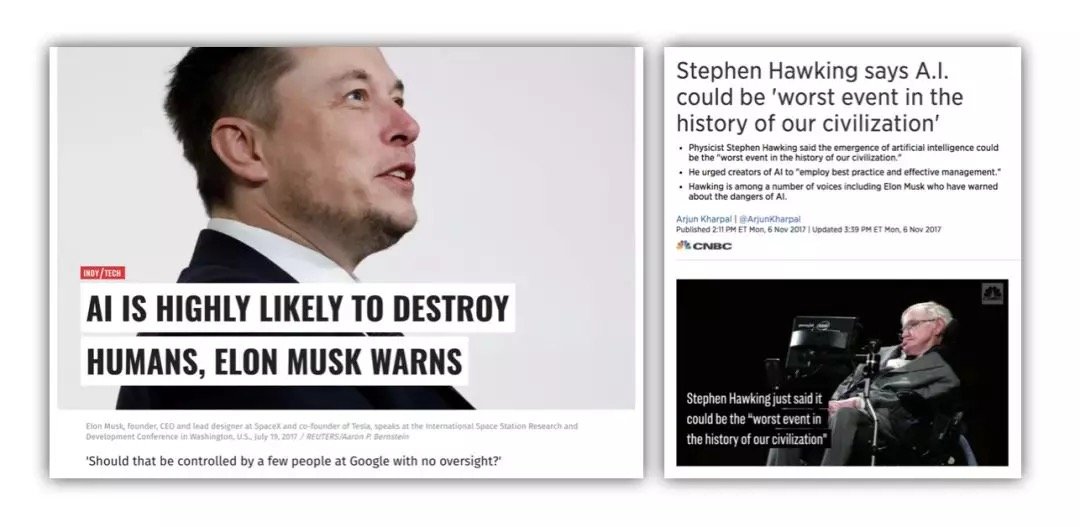
而在另一邊,Facebook和Google的首席科學家卻在說,現在的AI都是渣渣,根本不需要擔心,甚至應該推翻重做。

大家該相信誰的?一邊是要去火星的男人,和說不定已經去了火星的男人;另一邊是當前兩家科技巨頭的領軍人物。
其實他們說的都對,因為這裡說到的「人工智慧」是兩碼事。
馬一龍和霍金擔心的人工智慧,是由人造出來的真正的智能,即通用人工智慧(AGI, Artificial General Intelligence)甚至是超級智能(Super Intelligence)。
而Yann LeCun 和Hinton指的人工智慧則是指的當前用來實現「人工智慧效果」的技術(基於統計的機器學習)。這兩位的觀點是「用這種方式來實現人工智慧是行不通的」。
兩者本質是完全不同的,一個指的是結果,一個指的是(現在的)過程。
那麼當我們在討論人工智慧的時候,究竟在說什麼?

John McCathy在1956年和Marvin Minsky,Nathaniel Rochester 以及Claude Shannon在達特貌似研討會上打造了AI這個詞,但是到目前為止,學界工業界並沒有一個統一的理解。
最根本的問題是目前人類對「智能」的定義還不夠清楚。何況人類本身是否是智能的最佳體現,還不一定呢。想想每天打交道的一些人:)
一方面,在大眾眼中,人工智慧是 「人造出來的,像人的智能」,比如Siri。同時,一個AI的水平高低,則取決於它有多像人。所以當Sophia出現在公眾眼中的時候,普通人會很容易被蒙蔽(甚至能通過圖靈測試)。
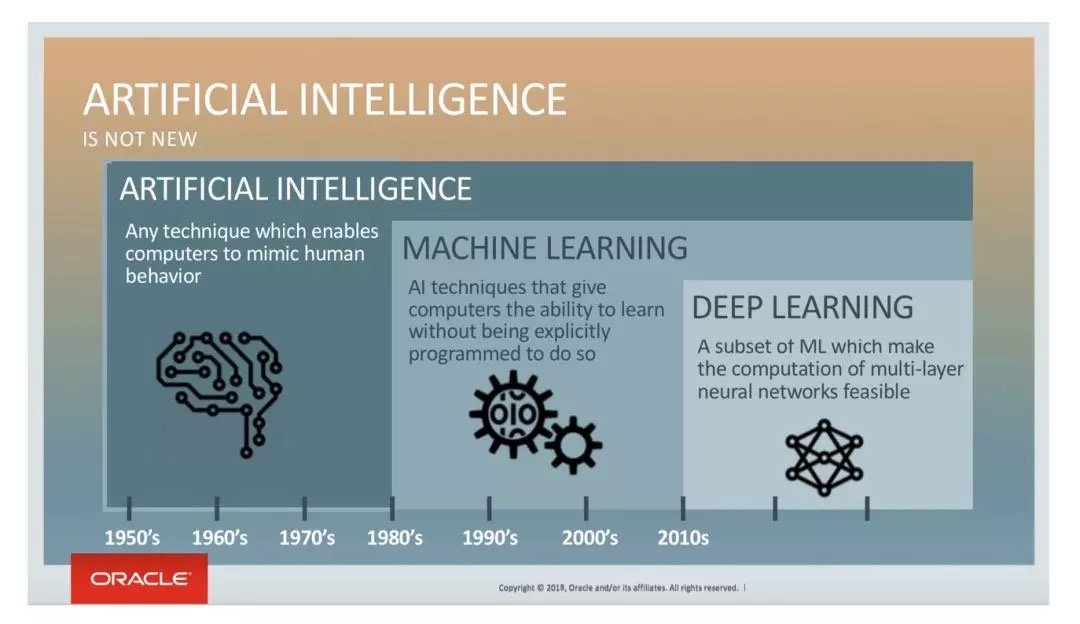
Oracle對AI的定義也是 「只要是能讓計算機可以模擬人類行為的技術,都算!」
而另一方面,從字面上來看「Artificial Intelligence」,只要是人造的智能產品,理論上都算作人工智慧。
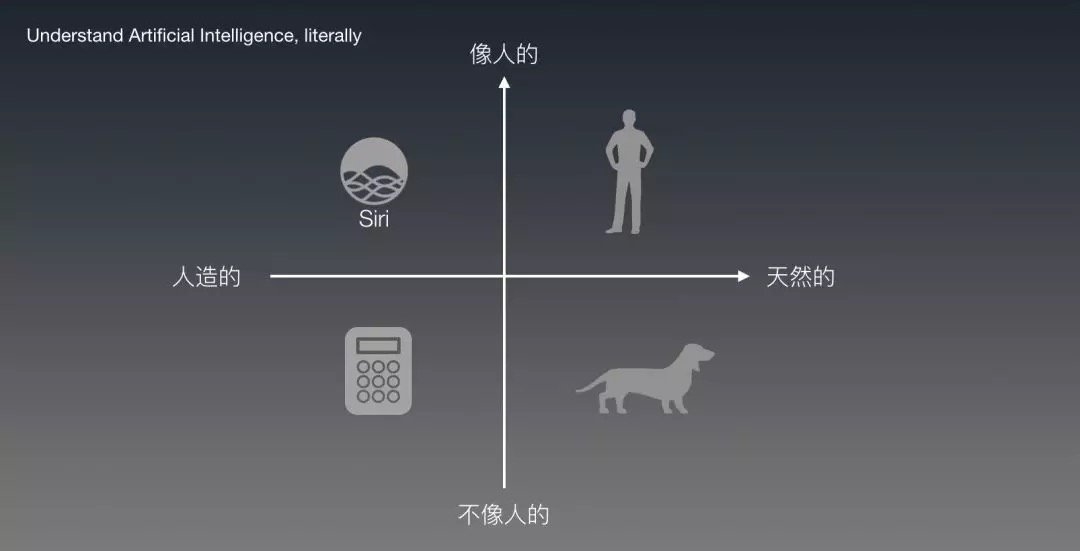
也就是說,一個手持計算器,儘管不像人,也應算是人工智慧產品。但我相信大多數人都不會把計算器當成是他們所理解的人工智慧。
這些在認識上不同的解讀,導致當前大家對AI應用的期望和評估都有很多差異。
再加上還有「深度學習、神經網路、機器學習」 這些概念紛紛跟著人工智慧一起出現。但是各自意味著什麼,之間是什麼關係,普通大眾都不甚了解。
「 沒關係,韭菜不用懂。」 但是想要割韭菜的人,最好能搞清楚吧。連有些投資人自己也分不清,你說怎麼做判斷,如何投項目?當然是投胸大的。
以上,就是到2018年末,在對話領域的人工智慧的現狀:智能助理依然智障;大部分To B的給人造機器人的都無法規模化;對話方面沒有像AlphaZero在圍棋領域那樣的讓人震驚的產品;沒有商業上大規模崛起的跡象;有的是一團渾水,和渾水摸魚的人。
為什麼會這樣?為什麼人工智慧在圖像識別,人臉識別,下圍棋這些方面都那麼快的進展,而在對話智能這個領域卻是如此混亂?
既然你都看到這裡了,我相信你是一個願意探究本質的好同志。那麼我們來了解,對話的本質是什麼;以及現在的對話系統的本質又是什麼。
Part 2:當前對話系統的本質:填表
「 AI thinks, man laughs 」

有一群小雞出生在一個農場,無憂無慮安心地生活。
雞群中出現了一位科學家,它注意到了一個現象:每天早上,食槽里會自動出現糧食。
作為一名優秀的歸納法信徒(Inductivist),這隻科學雞並不急於給出結論。它開始全面觀察並做好記錄,試圖發現這個現象是否在不同的條件下都成立。
「星期一是這樣,星期二是這樣;樹葉變綠時是這樣,樹葉變黃也是這樣;天氣冷是這樣,天氣熱也是這樣;下雨是這樣,出太陽也是這樣!」
每天的觀察,讓它越來越興奮,在心中,它離真相越來越接近。直到有一天,這隻科學雞再也沒有觀察到新的環境變化,而到了當天早上,雞舍的門一打開,它跑到食槽那裡一看,依然有吃的!
科學雞,對他的小夥伴,志在必得地宣布:「我預測,每天早上,槽里會自動出現食物。明天早上也會有!以後都會有!我們不用擔心餓死了!」
經過好幾天,小夥伴們都驗證了這個預言,科學雞驕傲的並興奮的把它歸納成「早起的小雞有食吃定理」。
正好,農場的農夫路過,看到一隻興奮的雞不停的咯咯叫,他笑了:「這隻雞很可愛哦,不如把它做成叫花雞好了」 。
科學雞,卒於午飯時間。
在這個例子里,這隻羅素雞(Bertrand Russell』s chicken)只對現象進行統計和歸納,不對原因進行推理。
而主流的基於統計的機器學習特別是深度學習,也是通過大量的案例,靠對文本的特徵進行歸類,來實現對識別語義的效果。這個做法,就是羅素雞。
目前,這是對話式人工智慧的主流技術基礎。其主要應用方向,就是對話系統,或稱為Agent。之前提到的智能助理Siri,Cortana,Google Assistant以及行業裡面的智能客服這些都算是對話智能的應用。
「 對話智能的黑箱 」
這些產品的交互方式,是人類的自然語言,而不是圖像化界面。
圖形化界面(GUI)的產品,比如網頁或者APP的產品設計,是所見即所得、界面即功能。
對話智能的交互(CUI, Conversational UI)是個黑箱:終端用戶能感知到自己說出的話(輸入)和機器人的回答(輸出)——但是這個處理的過程是感覺不到的。就好像跟人說話,你並不知道他是怎麼想的。
每一個對話系統的黑箱里,都是開發者自由發揮的天地。
雖說每家的黑箱裡面都不同,但是最底層的思路,都萬變不離其宗,核心就是兩點:聽人話(識別)+ 講人話(對話管理)。
如果你是從業人員,那麼請回答一個問題:你們家的對話管理是不是填槽?若是,你可以跳過這一節(主要科普填槽是怎麼回事),請直接到本章的第五節「當前對話系統的局限」 。
「 AI如何聽懂人話 ?」
對話系統這個事情在2015年開始突然火起來了,主要是因為一個技術的普及:機器學習特別是深度學習帶來的語音識別和NLU(自然語言理解)——主要解決的是識別人講的話。
這個技術的普及讓很多團隊都掌握了一組關鍵技能:意圖識別和實體提取。這意味著什麼?我們來看一個例子。
在生活中,如果想要訂機票,人們會有很多種自然的表達:
「訂機票」;
「有去上海的航班么?」;
「看看航班,下周二出發去紐約的」;
「要出差,幫我查下機票」;
等等等等
可以說「自然的表達」 有無窮多的組合(自然語言)都是在代表 「訂機票」 這個意圖的。而聽到這些表達的人,可以準確理解這些表達指的是「訂機票」這件事。
而要理解這麼多種不同的表達,對機器是個挑戰。在過去,機器只能處理「結構化的數據」(比如關鍵詞),也就是說如果要聽懂人在講什麼,必須要用戶輸入精確的指令。
所以,無論你說「我要出差」還是「幫我看看去北京的航班」,只要這些字裡面沒有包含提前設定好的關鍵詞「訂機票」,系統都無法處理。而且,只要出現了關鍵詞,比如「我要退訂機票」里也有這三個字,也會被處理成用戶想要訂機票。
自然語言理解這個技能出現後,可以讓機器從各種自然語言的表達中,區分出來,哪些話歸屬於這個意圖;而那些表達不是歸於這一類的,而不再依賴那麼死板的關鍵詞。比如經過訓練後,機器能夠識別「幫我推薦一家附近的餐廳」,就不屬於「訂機票」這個意圖的表達。
並且,通過訓練,機器還能夠在句子當中自動提取出來「上海」,這兩個字指的是目的地這個概念(即實體);「下周二」指的是出發時間。
這樣一來,看上去「機器就能聽懂人話啦!」。
這個技術為啥會普及?主要是因為機器學習領域的學術氛圍,導致重要的論文基本都是公開的。不同團隊要做的是考慮具體工程實施的成本。
最後的效果,就是在識別自然語言這個領域裡,每家的基礎工具都差不多。在意圖識別和實體提取的準確率,都是百分點的差異。既然這個工具本身不是核心競爭力,甚至你可以用別家的,大把可以選,但是關鍵是你能用它來幹什麼?
「Due to the academic culture that ML comes from, pretty much all of the primary science is published as soon as it』s created – almost everything new is a paper that you can read and build with. But what do you build? 」
——Benedict Evans (A16Z合伙人)
在這方面,最顯而易見的價值,就是解放雙手。語音控制類的產品,只需要聽懂用戶的自然語言,就去執行這個操作:在家裡要開燈,可以直接說 「開燈」,而不用去按開關;在車上,說要「開天窗」,天窗就打開了,而不用去找對應的按鈕在哪裡。
這類系統的重點在於,清楚聽清哪個用戶在講是什麼。所以麥克風陣列、近場遠場的抗噪、聲紋識別講話的人的身份、ASR(語音轉文字),等等硬體軟體的技術就相應出現,向著前面這個目標不斷優化。
「講人話」在這類應用當中,並不那麼重要。通常任務的執行,以結果進行反饋,比如燈應聲就亮了。而語言上的反饋,只是一個輔助作用,可有可無。
但是任務類的對話智能,往往不止是語音控制這樣一輪交互。如果一個用戶說,「看看明天的機票」——這表達正常,但無法直接去執行。因為缺少執行的必要信息:1)從哪裡出發?和 2)去哪裡?
如果我們希望AI Agent來執行這個任務,一定要獲得這兩個信息。對於人來完成這個業務的話,要獲得信息,就得靠問這個用戶問題,來獲得信息。很多時候,這樣的問題,還不止一個,也就意味著,要發起多輪對話。
對於AI而言,也是一樣的。
要知道 「去哪裡」 = Agent 問用戶「你要去哪裡?」
要知道 「從哪裡出發」 = Agent 問用戶「你要從哪裡出發呢?」
這就涉及到了對話語言的生成。
「 AI 如何講人話?」
決定「該說什麼話」,才是對話系統的核心——無論是硅基的還是碳基的智能。但是深度學習在這個版塊,並沒有起到什麼作用。
在當前,處理「該說什麼」這個問題,主流的做法是由所謂「對話管理」系統決定的。
儘管每一個對話系統背後的「對話管理」機制都不同,每家都有各種理解、各種設計,但是萬變不離其宗——目前所有任務類對話系統,無論是前段時間的Google duplex,還是智能客服,或者智能助理,最核心的對話管理方法,有且僅有一個:「填槽」,即Slot filling。
如果你並不懂技術,但是又要迅速知道一家做對話AI的水平如何,到底有沒有黑科技(比如剛剛開始看AI領域的做投資的朋友 ),你只需要問他一個問題:「是不是填槽?」
- 如果他們(誠實地)回答「是」,那你就可以放下心來,黑科技尚未出現。接下來,能討論的範圍,無非都是產品設計、工程實現、如何解決體驗和規模化的困境,這類的問題。基本上該智障的,還是會智障。
- 要是他們回答「不是填槽」,而且產品的效果還很好,那麼就有意思了,值得研究,或者請速速聯繫我:)
那麼這個「填槽」究竟是個什麼鬼?嗯,不搞開發的大家可以簡單的把它理解為「填表」:好比你要去銀行辦個業務,先要填一張表。
如果這張表上的空沒有填完,櫃檯小姐姐就不給你辦。她會紅筆給你圈出來:「必須要填的空是這些,別的你都可以不管。」 你全部填好了,再遞給小姐姐,她就去給你辦理業務了。
還記得剛剛那個機票的例子么?用戶說「看看明天的機票」,要想執行「查機票」,就得做以下的步奏,還要按順序來:
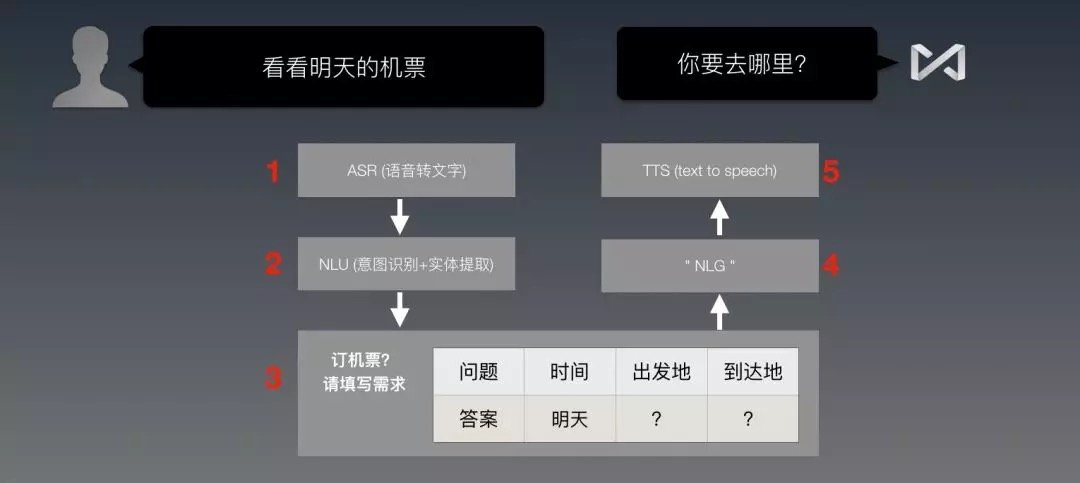
1. ASR:把用戶的語音,轉化成文字。
2. NLU語義識別:識別上面的文字,屬於(之前設定好的)哪一個意圖,在這裡就是「訂機票」;然後,提取文字裡面的實體,「明天」作為訂票日期,被提取出來啦。
3. 填表:這個意圖是訂機票,那麼就選「訂機票」這張表來填;這表裡有三個空,時間那個空里,就放進「明天」。
(這個時候,表裡的3個必填項,還差兩個:「出發地」和「到達地」)
4. 開始跑之前編好的程序:如果差「出發地」,就回「從哪裡走啊?」;如果差「目的地」,就回「你要去哪裡?」(NLG上打引號,是因為並不是真正意義上的自然語言生成,而是套用的對話模版)
5. TTS:把回復文本,合成為語音,播放出去
在上面這個過程當中,1和2步奏都是用深度學習來做識別。如果這個環節出現問題,後面就會連續出錯。
循環1-5這個過程,只要表裡還有空要填,就不斷問用戶,直到所有的必填項都被填完。於是,表就可以提交小姐姐(後端處理)了。
後端看了要查的條件,返回滿足這些條件的機票情況。Agent再把查詢結果用之前設計好的回復模板發回給用戶。
順便說一下,我們經常聽到有些人說「我們的多輪對話可以支持xx輪,最多的時候有用戶能說xx輪」。現在大家知道,在任務類對話系統里,「輪數的產生」是由填表的次數決定的,那麼這種用「輪數多少」來衡量產品水平的方法,在這個任務類對話里里完全無意義。
一定要有意義,也應該是:在達到目的、且不影響體驗的前提下,輪數越少越好。
在當前,只要做任務類的多輪對話,基本跑不掉填表。
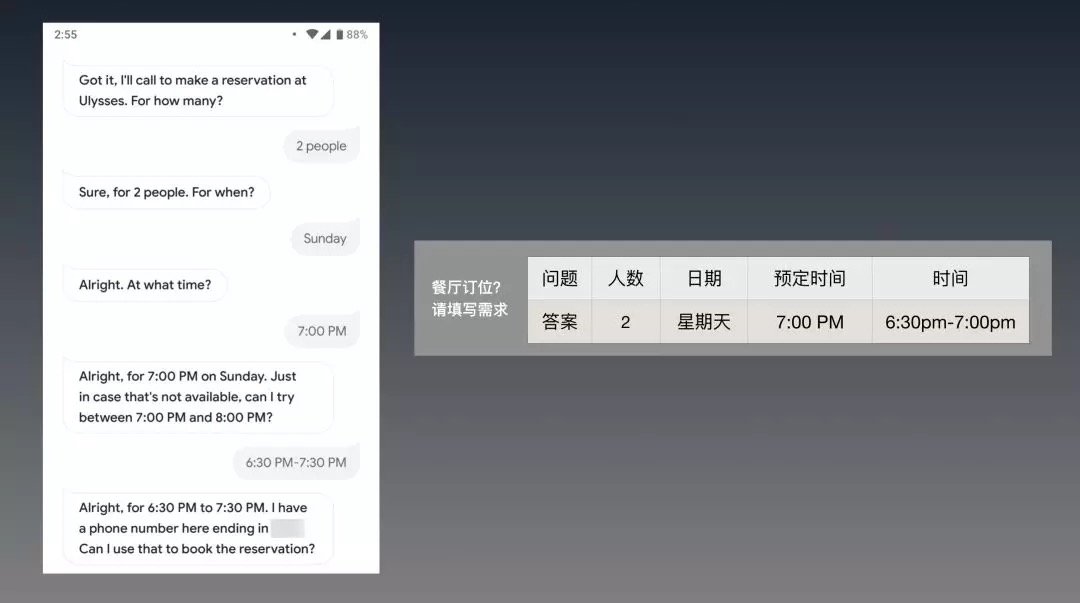
5月的時候,Google I/O發布了Duplex的錄音Demo,場景是Google Assistant代替用戶打電話去訂餐廳,和店員溝通,幫助用戶預定位子。值得注意,這並不是Live demo。
Google’s Assistant. CREDIT:GOOGLE
那Google的智能助理(後稱IPA)又怎麼知道用戶的具體需求呢?跑不掉的是,用戶還得給Google Assistant填一張表,用對話來交代自己的具體需求,比如下面這樣:
「 當前對話系統的局限 」
我剛剛花了兩千來個字來說明對話系統的通用思路。接下來,要指出這個做法的問題
還記得之前提到的 「不要日本菜」測試么?我們把這個測試套用在「訂機票」這個場景上,試試看:「看看明天去北京的航班,東航以外的都可以」,還是按步奏來:
1. ASR語音轉文字,沒啥問題;
2. 語義識別,貌似有點問題
– 意圖:是訂機票,沒錯;
– 實體提取:跟著之前的訓練來;
– 時間:明天
– 目的地:北京
– 出發地:這個用戶沒說,一會得問問他…
等等,他說的這個「東航以外的都可以」,指的是啥?之前沒有訓練過與航空公司相關的表達啊。
沒關係,咱們可以把這個表達的訓練加上去:東航 = 航司。多找些表達,只要用戶說了各個航空公司的名字的,都訓練成航司這個實體好啦。
另外,咱們還可以在填表的框里,添加一個航司選擇,就像這樣(黃色部分):

(嗯,好多做TO B的團隊,都是掉在這個「在後面可以加上去」的坑裡。)
但是,這麼理所當然的訓練之後,實體提取出來的航司卻是「東航」——而用戶說的是 「東航以外的」,這又指的哪個(些)航司呢?
「要不,咱們做點Trick把『以外』這樣的邏輯單獨拿出來手工處理掉?」——如果這個問題可以這麼容易處理掉,你覺得Siri等一乾貨色還會是現在這個樣子?難度不在於「以外」提取不出來,而是在處理「這個以外,是指哪個實體以外?
當前基於深度學習的NLU在「實體提取」這個技術上,就只能提取「實體」。
而人能夠理解,在這個情況下,用戶是指的「排除掉東航以外的其他選擇」,這是因為人除了做「實體提取」以外,還根據所處語境,做了一個對邏輯的識別:「xx以外」。然後,自動執行了這個邏輯的處理,即推理,去進一步理解,對方真正指的是什麼(即指代)。
而這個邏輯推理的過程,並不存在於之前設計好的步奏(從1到5)里。
更麻煩的是,邏輯的出現,不僅僅影響「實體」,還影響「意圖」:
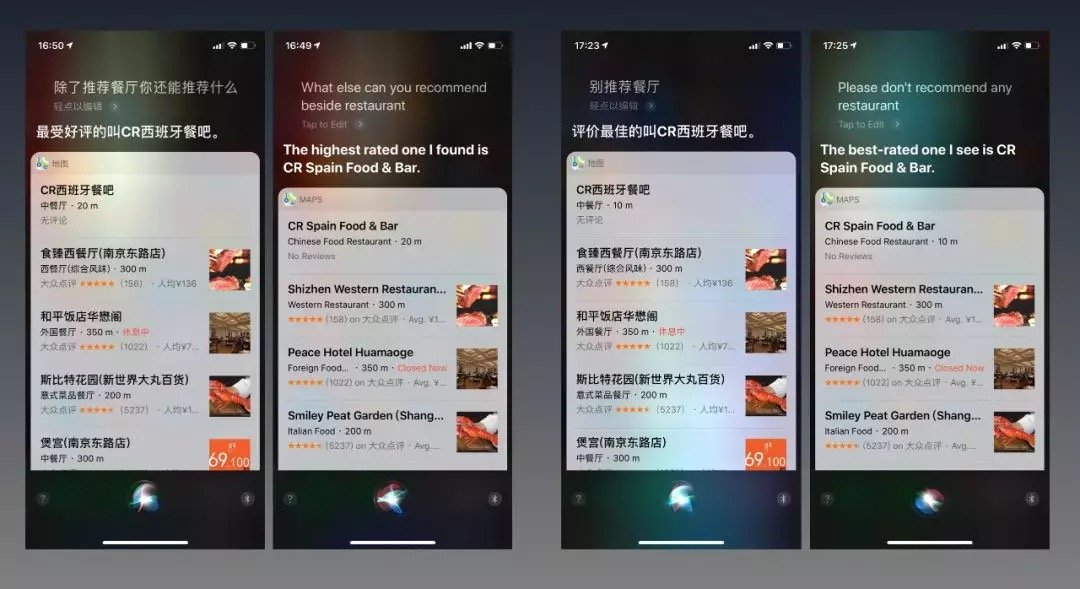
「hi Siri,別推薦餐廳」——它還是會給你推薦餐廳;
「hi Siri,除了推薦餐廳,你還能推薦什麼?」——它還是會給你推薦餐廳。
中文英文都是一樣的;Google assistant也是一樣的。
想要處理這個問題,不僅僅是要識別出「邏輯」;還要正確判斷出,這個邏輯是套用在哪個實體,或者是不是直接套用在某一個意圖上。這個判斷如何做?用什麼做?都不在當前SLU的範圍內。
對這些問題的處理,如果是集中在一些比較封閉的場景下,還可以解決個七七八八。但是,如果想要從根本上、泛化的處理,希望一次處理就解決所有場景的問題,到目前都無解。在這方面,Siri是這樣,Google Assistant也是這樣,任意一家,都是這樣。
為啥說無解?我們來看看測試。
「 用圖靈測試來測對話系統沒用」
一說到對人工智慧進行測試,大部分人的第一反應是圖靈測試。
5月Google I/O大會的那段時間,我們團隊正在服務一家全球100強企業,為他們規劃基於AI Agent的服務。
在發布會的第二天,我收到這家客戶的Tech Office的好心提醒:Google這個像真人一樣的黑科技,會不會顛覆現有的技術方案?我的回答是並不會。
話說Google Duplex在發布會上的demo確實讓人印象深刻,而且大部分看了Demo的人,都分辨不出打電話去做預定的是不是真人。
「這個效果在某種意義上,算是通過了圖靈測試。」
由於圖靈測試的本質是「欺騙」 (A game of deception,詳見Toby Walsh的論文),所以很多人批評它,這隻能用來測試人有多好騙,而不是用來測智能的。在這一點上,我們在後文Part 4對話的本質中會有更多解釋。
人們被這個Demo騙到的主要原因,是因為合成的語音非常像真人。
這確實是Duplex最牛的地方:語音合成。不得不承認,包括語氣、音調等等模擬人聲的效果,確實是讓人嘆為觀止。只是,單就在語音合成方面,就算是做到極致,在本質上就是一隻鸚鵡——最多可以騙騙Alexa(所以你看活體識別有多麼重要)。
只是,Google演示的這個對話系統,一樣處理不了邏輯推理、指代這類的問題。這意味著,就它算能過圖靈測試,也過不了Winograd Schema Challenge測試。
相比圖靈測試,這個測試是直擊深度學習的要害。當人類對句子進行語法分析時,會用真實世界的知識來理解指代的對象。這個測試的目標,就是測試目前深度學習欠缺的常識推理能力。
如果我們用Winograd Schema Challenge的方法,來測試AI在「餐廳推薦」這個場景里的水平,題目會是類似這樣的:
A. 「四川火鍋比日料更好,因為它很辣」
B. 「四川火鍋比日料更好,因為它不辣」
AI需要能準確指出:在A句里,「它」指的是四川火鍋;而在B句里,「它」指的則是日料。
還記得在本文Part 1里提到的那個「不要日本菜測試」么?我真的不是在強調「回字有四種寫法」——這個測試的本質,是測試對話系統能不能使用簡單邏輯來做推理(指代的是什麼)。
而在Winograd Schema Challenge中,則是用世界知識(包括常識)來做推理:
如果系統不知道相應的常識(四川火鍋是辣的;日料是不辣的),就沒有推理的基礎。更不用說推理還需要被準確地執行。
有人說,我們可以通過上下文處理來解決這個問題。不好意思,上面這個常識根本就沒有出現在整個對話當中。不在「上文」裡面,又如何處理?
對於這個部分的詳細解釋,請看下一章 (Part 3 對話的本質)。
儘管指代問題和邏輯問題,看上去,在應用方面已經足夠致命了;但這些也只是深度學習表現出來的諸多局限性中的一部分。
哪怕更進一步,再過一段時間,有一家AI在Winograd Schema Challenge拿了100%的正確率,我們也不能期望它在自然語言處理中的表現如同人一樣,因為還有更嚴重和更本質的問題在後面等著。
「 對話系統更大的挑戰不是NLU 」
我們來看問題表現在什麼地方。
現在我們知道了,當人跟現在的AI對話的時候,AI能識別你說的話,是靠深度學習對你說出的自然語言進行分類,歸於設定好的意圖,並找出來文本中有哪些實體。
而AI什麼時候回答你,什麼時候反問你,基本都取決於背後的「對話管理」系統裡面的各種表上還有啥必填項沒有填完。而問你的話,則是由產品經理和代碼小哥一起手動完成的。
那麼,這張表是誰做的?
或者說,是誰決定,對於「訂機票」這件事,要考慮哪些方面?要獲得哪些信息?需要問哪些問題?機器又是怎麼知道的?
是人。是產品經理,準確點說。
就像剛才的「訂機票」的案例,當用戶問到「航司」的時候,之前的表裡並沒有設計這個概念,AI就無法處理了。
要讓AI能處理這樣的新條件,得在「訂機票」這張表上,新增加「航空公司」一欄(黃色部分)。而這個過程,都得人為手動完成:產品經理設計好後,工程師編程完成這張表的編程。
所以AI並不是真的,通過案例學習就自動理解了「訂機票」這件事情,包含了哪些因素。只要這個表還是由人來設計和編程實現的,在產品層面,一旦用戶稍微談及到表以外的內容,智障的情況就自然出現了。
因此,當Google duplex出現的時候,我並不那麼關心 Google duplex發音和停頓有多像一個人——實際上,當我觀察任意一個對話系統的時候,我都只關心1個問題:
「是誰設計的那張表:人,還是AI?」
只是,深度學習在對話系統裡面,能做的只是識別用戶講出的那句話那部分——嚴格依照被人為訓練的那樣(監督學習)。至於其他方面,比如該講什麼話?該在什麼時候講話?它都無能為力。
但是真正人們在對話時的過程,卻不是上面提到的對話系統這麼設計的,而且相差十萬八千里。人的對話,又是怎麼開展的?這個差異究竟在哪裡?為什麼差異那麼大?所謂深度學習很難搞定的地方,是人怎麼搞定的呢?畢竟在這個星球上,我們自身就是70億個完美的自然語言處理系統呢。
我們需要了解要解決的問題,才可能開展解決問題的工作。在對話領域,我們需要知道人們對話的本質是什麼。下一章比較燒腦,我們將討論「思維」這件事情,是如何主導人們的對話的。
Part 3:人類對話的本質:思維
「 對話的最終目的是為了同步思維 」
你是一位30出頭的職場人士,每天上午9點半,都要過辦公樓的旋轉門,進大堂的,然後刷工牌進電梯,去到28樓,你的辦公室。今天是1月6日,平淡無奇的一天。你剛進電梯,電梯里只有你一個人,正要關門的時候,有一個人匆忙擠進來。
進來的快遞小哥,他進電梯時看到只有你們兩人,就說了一聲「你好」,然後又低頭找樓層按鈕了。
你很自然的回復:「你好」,然後目光轉向一邊。
兩邊都沒什麼話好講——實際上,是對話雙方認為彼此沒有什麼情況需要同步的。
人們用語言來對話,其最終的目的是為了讓雙方對當前場景模型(Situation model)保持同步。(大家先了解到這個概念就夠了。更感興趣的,詳情請見 Toward a neural basis of interactive alignment in conversation)。
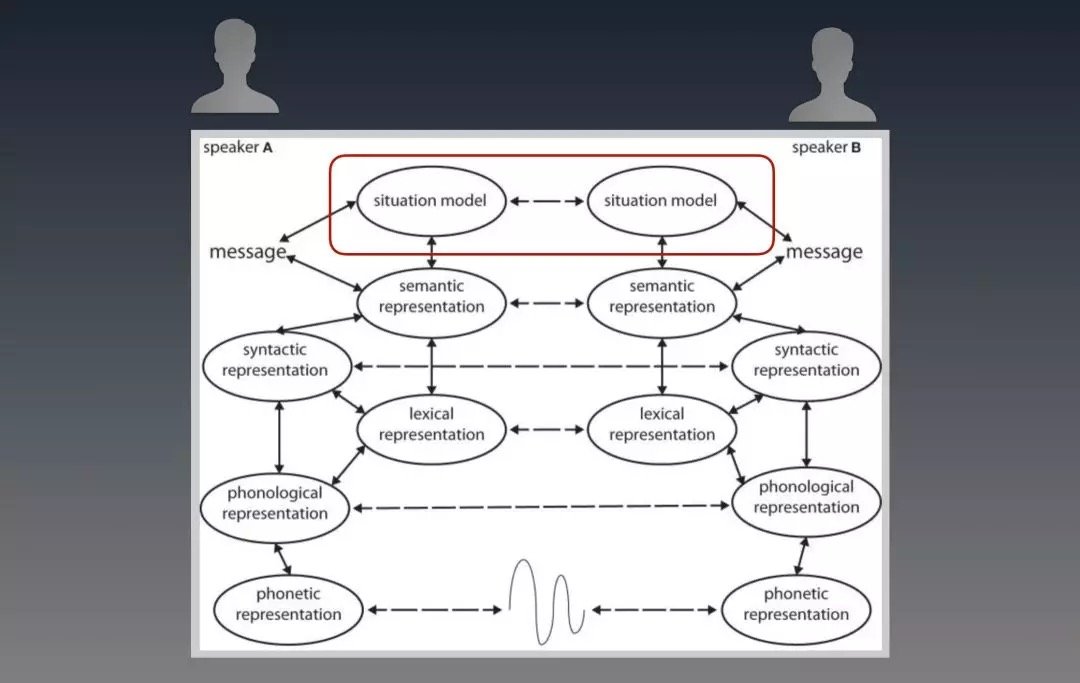
上圖中,A和B兩人之間發展出來所有對話,都是為了讓紅框中的兩個「Situation model」 保持同步。Situation model 在這裡可以簡單理解為對事件的各方面的理解,包括Context。
不少做對話系統的朋友會認為Context是僅指「對話中的上下文」,我想要指出的是,除此以外,Context還應該包含了對話發生時人們所處的場景。這個場景模型涵蓋了對話那一刻,除了明文以外的所有已被感知的信息。 比如對話發生時的天氣情況,只要被人感知到了,也會被放入Context中,並影響對話內容的發展。
A: 「你對這個事情怎麼看?」
B: 「這天看著要下雨了,咱們進去說吧」——儘管本來對話內容並沒有涉及到天氣。
對同一件事情,不同的人在腦海里構建的場景模型是不一樣的。 (想要了解更多,可以看 Situation models in language comprehension and memory. Zwaan, R. A., & Radvansky, G. A. (1998). )
所以,如果匆忙進電梯來的是你的項目老闆,而且假設他和你(多半都是他啦)都很關注最近的新項目進展,那麼你們要開展的對話就很多了。
在電梯里,你跟他打招呼:「張總,早!」, 他會回你 「早啊,對了昨天那個…」
不待他問完,優秀如你就能猜到「張總」 大概後面要聊的內容是關於新項目的,這是因為你認為張總對這個「新項目」的理解和你不同,有同步的必要。甚至,你可以通過昨天他不在辦公室,大概漏掉了這個項目的哪些部分,來推理你這個時候應該回復他關於這個項目的具體什麼方面的問題。
「昨天你不在,別擔心,客戶那邊都處理好了。打款的事情也溝通好了,30天之內搞定。」 ——你看,不待張總問完,你都能很棒的回答上。這多虧了你對他的模型的判斷是正確的。
一旦你對對方的情景模型判斷失誤,那麼可能完全「沒打中點上」。
「我知道,昨天晚上我回了趟公司,小李跟我說過了。我是要說昨天晚上我回來辦公室的時候,你怎麼沒有在加班呀?小王,你這樣下去可不行啊…」
所以,人們在進行對話的過程中,並不是僅靠對方上一句話說了什麼(對話中明文所包含的信息)就來決定回復什麼。而這和當前的對話系統的回復機制非常不同。
「 對話是思想從高維度向低維的投影 」
我們假設,在另一個平行宇宙里,還是你到了辦公樓。
今天還是1月6日,但2年前的今天,你與交往了5年的女友分手了,之後一直對她念念不忘,也沒有交往新人。
你和往日一樣,進電梯的,剛要關門的時候,匆忙進來的一個人,要關的門又打開了。就是你2年前分手的那位前女友。她進門時看到只有你們兩,她抬頭看了一下你,然後又低頭找樓層電梯了,這時她說:「你好」。
請問你這時腦袋裡是不是有很多信息洶湧而過?這時該回答什麼?是不是類似「一時不知道該如何開口」的感覺?
這個感覺來自(你認為)你和她之間的情景模型有太多的不同(分手2年了),甚至你都無法判斷缺少哪些信息。有太多的信息想要同步了,卻被貧瘠的語言困住了。
在信息豐富的程度上,語言是貧瘠的,而思想則要豐富很多 「Language is sketchy, thought is rich」 (New perspectives on language and thought,Lila Gleitman, The Oxford Handbook of Thinking and Reasoning;更多相關討論請看, Fisher & Gleitman, 2002; Papafragou, 2007)
有人做了一個比喻:語言和思維的豐富程度相比,是冰山的一角。我認為遠遠不止如此:對話是思想在低維的投影。
如果是冰山,你還可以從水面上露出來的部分反推水下大概還有多大。屬於維度相同,但是量不同。但是語言的問題在,只用聽到文字信息,來反推講話的人的思想,失真的情況會非常嚴重。

為了方便理解這個維度差異,在這兒用3D和2D來舉例:思維是高維度(立體3D的形狀),對話是低維度(2D的平面上的陰影)。如果咱們要從平面上的陰影的形狀,來反推,上面懸著的是什麼物體,就很困難了。兩個陰影的形狀一模一樣,但是上面的3D物體,可能完全不同。
對於語言而言,陰影就像是兩個 「你好」在字面上是一模一樣的,但是思想里的內容卻完全不同。在見面的那一瞬間,這個差異是非常大的:
你在想(圓柱):一年多不見了,她還好么?
前女友在想(球):這個人好眼熟,好像認識…
「 挑戰:用低維表達高維 」
要用語言來描述思維有多困難?這就好比,當你試圖給另一位不在現場的朋友,解釋一件剛剛發生過的事情的時候,你可以做到哪種程度的還原呢?
試試用語言來描述你今天的早晨是怎麼過的。
當你用文字完整描述後,我一定能找到一個事物或者某個具體的細節,它在你文字描述以外,但是卻確實存在在你今天早晨那個時空里。

比如,你可能會跟朋友提到,早飯吃了一碗面;但你一定不會具體去描述面里一共有哪些調料。傳遞信息時,缺少了這些細節(信息),會讓聽眾聽到那碗面時,在腦海里呈現的一定不是你早上吃的「那碗面」的樣子。
這就好比讓你用平面上(2D)陰影的樣子,來反推3D的形狀。你能做的,只是儘可能的增加描述的視角,儘可能給聽眾提供不同的2D的素材,來盡量還原3D的效果。
為了解釋腦中「語言」和「思想」之間的關係(與讀者的情景模型進行同步),我畫了上面那張對比圖,來幫助傳遞信息。如果要直接用文字來精確描述,還要盡量保全信息不丟失,那麼我不得不用多得多的文字來描述細節。(比如上面的描述中,尚未提及陰影的面積的具體大小、顏色等等細節)。
這還只是對客觀事物的描述。當人在試圖描述更情緒化的主觀感受時,則更難用具體的文字來表達。

比如,當你看到Angelina Jordan這樣的小女生,卻能唱出I put a spell on you這樣的歌的時候,請嘗試用語言精確描述你的主觀感受。是不是很難?能講出來話,都是類似「鵝妹子嚶」這類的?這些文字能代表你腦中的感受的多少部分?1%?
希望此時,你能更理解所謂 「語言是貧瘠的,而思維則要豐富很多」。
那麼,既然語言在傳遞信息時丟失了那麼多信息,人們為什麼理解起來,好像沒有遇到太大的問題?
「 為什麼人們的對話是輕鬆的?」
假設有一種方式,可以把此刻你腦中的感受,以完全不失真的效果傳遞給另一個人。這種信息的傳遞和上面用文字進行描述相比,豐富程度會有多大差異?
可惜,我們沒有這種工具。我們最主要的交流工具,就是語言,靠著對話,來試圖讓對方了解自己的處境。
那麼,既然語言這麼不精準,又充滿邏輯上的漏洞,信息量又不夠,那麼人怎麼能理解,還以此為基礎,建立起來了整個文明?
比如,在一個餐廳里,當服務員說 「火腿三明治要買單了」,我們都能知道這和「20號桌要買單了」指代的是同樣的事情 (Nuberg,1978)。是什麼讓字面上那麼大差異的表達,也能有效傳遞信息?
人能通過對話,有效理解語言,靠的是解讀能力——更具體的點,靠的是對話雙方的共識和基於共識的推理能力。
當人接收到低維的語言之後,會結合引用常識、自身的世界模型(後詳),來重新構建一個思維中的模型,對應這個語言所代表的含義。這並不是什麼新觀點,大家熟悉的開復老師,在1991年在蘋果搞語音識別的時候,就在採訪里科普,「人類利用常識來幫助理解語音」。
當對話的雙方認為對一件事情的理解是一樣的,或者非常接近的時候,他們就不用再講。需要溝通的,是那些(彼此認為)不一樣的部分。
當你聽到「蘋果」兩個字的時候,你過去建立過的蘋果這個模型的各個維度,就被引用出來,包括可能是綠或紅色的、味道的甜、大概拳頭大小等等。如果你聽到對方說「藍色的蘋果」時,這和你過去建立的關於蘋果的模型不同(顏色)。思維就會產生一個提醒,促使你想要去同步或者更新這個模型,「蘋果為什麼是藍色的?」
還記得,在Part 2 里我們提到的那個測試指代關係的Winograd Schema Challenge么?這個測試的名字是根據Terry Winograd的一個例子而來的。
「議員們拒絕給抗議者頒發許可證,因為他們 [害怕/提倡] 暴力。」
當 [害怕] 出現在句子當中的時候,「他們」指的應該是議員們;當[提倡]出現在句子當中的時候,「他們」則指的是「抗議者」。
1. 人們能夠根據具體情況,作出判斷,是因為根據常識做出了推理,「議員害怕暴力;抗議者提倡暴力。」
2. 說這句話的人,認為這個常識對於聽眾應該是共識,就直接把它省略掉了。
同理,之前(Part 2)我們舉例時提到的那個常識 (「四川火鍋是辣的;日料不是辣的」),也在表達中被省略掉了。常識(往往也是大多數人的共識)的總量是不計其數,而且總體上還會隨著人類社會發展的演進而不斷新增。
例子1,如果你的世界模型里已經包含了「華農兄弟」 (你看過並了解他們的故事),你會發現我在Part 2最開始的例子,藏了一個梗(做成叫花雞)。但因為「華農兄弟」並不是大多數人都知道的常識,而是我與特定人群的共識,所以你看到這句話時,獲得的信息就比其人多。而不了解這個梗的人,看到那裡時就不會接收到這個額外的信息,反而會覺得這個表達好像有點點奇怪。
例子2,創投圈的朋友應該都有聽說過 Elevator pitch,就是30秒,把你要做什麼事情講清楚。通常的案例諸如:「我們是餐飲界的Uber」,或者說「我們是辦公室版的Airbnb」。這個典型結構是「XX版的YY」,要讓這句話起到效果,前提條件是XX和YY兩個概念在發生對話之前,已經納入到聽眾的模型裡面去了。如果我給別人說,我是「對話智能行業的麥肯錫」,要能讓對方理解,對方就得既了解對話智能是什麼,又了解麥肯錫是什麼。
「 基於世界模型的推理 」
場景模型是基於某一次對話的,對話不同,場景模型也不同;而世界模型則是基於一個人的,相對而言長期不變。
對世界的感知,包括聲音、視覺、嗅覺、觸覺等感官反饋,有助於人們對世界建立起一個物理上的認識。對常識的理解,包括各種現象和規律的感知,在幫助人們生成一個更完整的模型:世界模型。
無論精準、或者對錯,每一個人的世界模型都不完全一樣,有可能是觀察到的信息不同,也有可能是推理能力不一樣。世界模型影響的是人的思維本身,繼而影響思維在低維的投影:對話。
讓我們從一個例子開始:假設現在咱們一起來做一個不那麼智障的助理。我們希望這個助理能夠推薦餐廳酒吧什麼的,來應付下面這樣的需求:

當用戶說:「我想喝點東西」的時候,系統該怎麼回答這句話?經過Part 2,我相信大家都了解,我們可以把它訓練成為一個意圖「找喝東西的店」,然後把周圍的店檢索出來,然後回復這句話給他:「在你附近找到這些選擇」。
恭喜,咱們已經達到Siri的水平啦!
但是,剛剛我們開頭就說了,要做不那麼智障的助理。這個「喝東西的店」是奶茶點還是咖啡店?還是全部都給他?
嗯,這就涉及到了推理。我們來手動模擬一個。假設我們有用戶的Profile數據,把這個用上:如果他的偏好中最愛的飲品是咖啡,就給他推薦咖啡店。
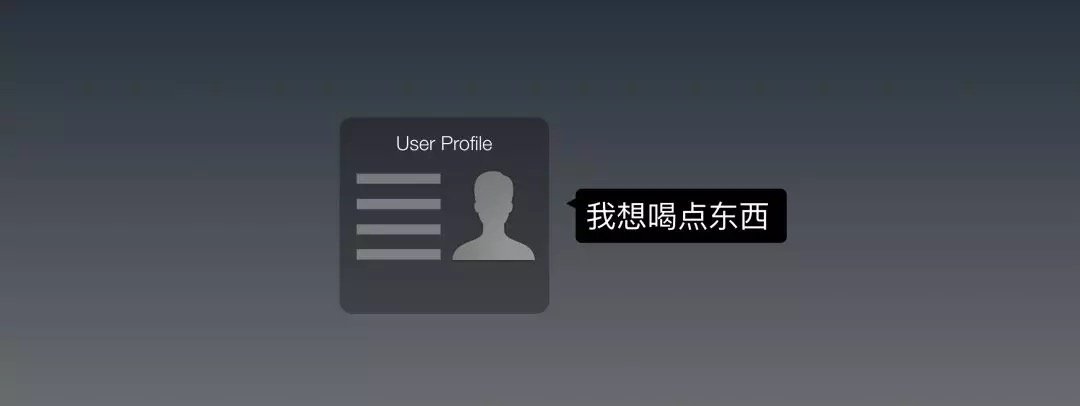
這樣一來,我們就可以更「個性化」的給他回復了:「在你附近找到這些咖啡店」。
這個時候,咱們的AI已經達到了不少「智能系統」最喜歡鼓吹的個性化概念——「千人千面」啦!
然後我們來看這個概念有多蠢。
一個人喜歡喝咖啡,那麼他一輩子的任意時候就都要喝咖啡么?人是怎麼處理這個問題的呢?如果用戶是在下午1點這麼問,這麼回他還好;如果是在晚上11點呢?我們還要給他推薦咖啡店么?還是應該給他推薦一個酒吧?
或者,除此之外,如果今天是他的生日,那麼我們是不是該給他點不同的東西?或者,今天是聖誕節,該不該給他推薦熱巧克力?
你看,時間是一個維度,在這個維度上的不同值都在影響給用戶回復什麼不同的話。
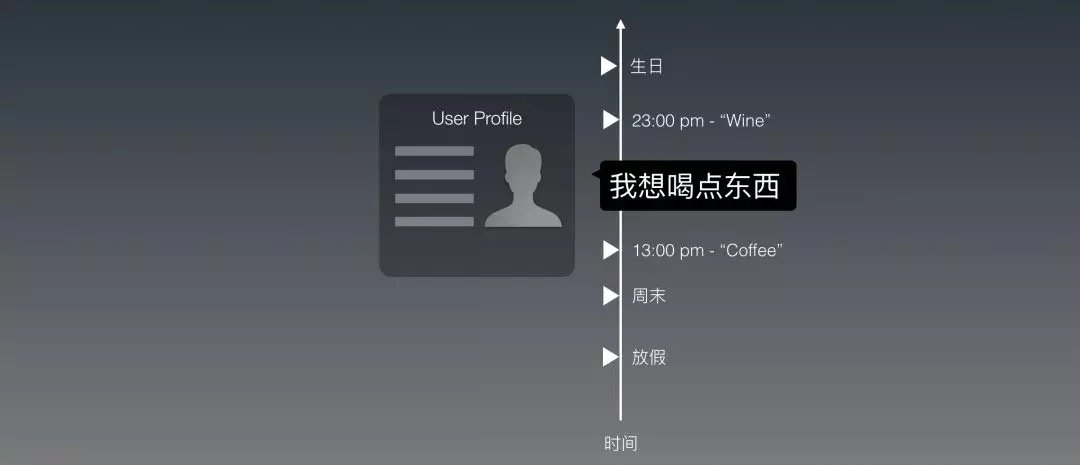
時間和用戶的Profile不同的是:
1. 時間這個維度上的值有無限多;
2. 每個刻度還都不一樣。比如雖然生日是同一個日期,但是過生日的次數卻不重複;
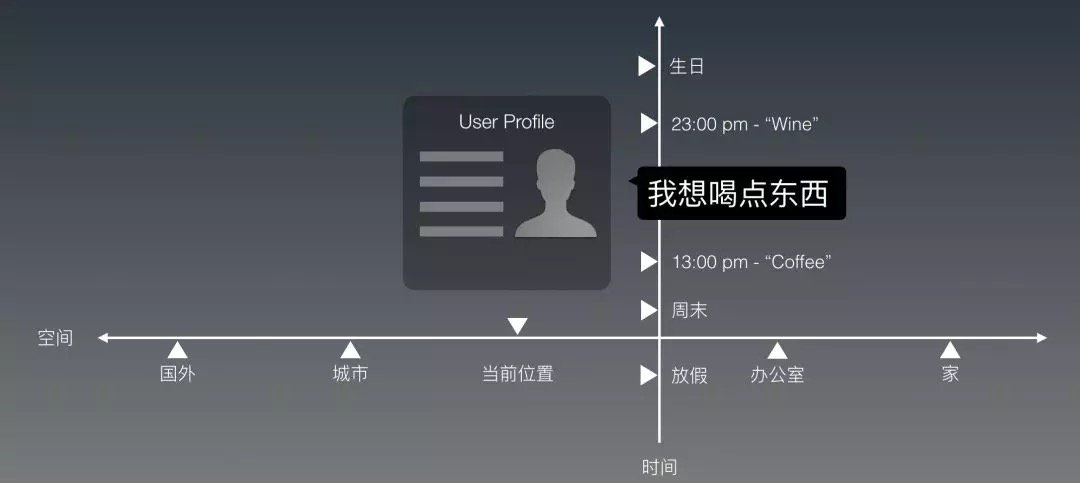
除了時間這個維度以外,還有空間。
於是我們把空間這個維度疊加(到時間)上去。你會發現,如果用戶在周末的家裡問這個問題(可能想叫奶茶外賣到家?),和他在上班時間的辦公室里問這個問題(可能想出去走走換換思路),咱們給他的回復也應該不同。
光是時空這兩個維度,就有無窮多的組合,用”if then”的邏輯也沒法全部手動寫完。我們造機器人的工具,到這個需求,就開始捉襟見肘了。
何況時間和空間,只是世界模型當中最顯而易見的兩個維度。還有更多的,更抽象的維度存在,並且直接影響與用戶的對話。比如,人物之間的關係;人物的經歷;天氣的變化;人和地理位置的關係(是經常來出差、是當地土著、是第一次來旅遊)等等等等。咱們聊到這裡,感覺還在聊對話系統么?是不是感覺有點像在聊推薦系統?
要想效果更好,這些維度的因素都要疊加在一起進行因果推理,然後把結果給用戶。
至此,影響人們對話的,光是信息(還不含推理)至少就有這三部分:明文(含上下文)+ 場景模型(Context)+ 世界模型。
普通人都能毫不費力地完成這個工作。但是深度學習只能處理基於明文的信息。對於場景模型和世界模型的感知、生成、基於模型的推理,深度學習統統無能為力。
這就是為什麼現在炙手可熱的深度學習無法實現真正的智能(AGI)的本質原因:不能進行因果推理。
根據世界模型進行推理的效果,不僅僅體現上在對話上,還能應用在所有現在成為AI的項目上,比如自動駕駛。
經過大量訓練的自動駕駛汽車,在遇到偶髮狀況時,就沒有足夠的訓練素材了。比如,突然出現在路上的嬰兒車和突然滾到路上的垃圾桶,都會被視為障礙物,但是剎不住車的情況下,一定要撞一個的時候,撞哪一個?
又比如,對侯世達(Douglas Hofstardler )而言,「駕駛」意味著當要趕著去一個地方的時候,要選擇超速還是不超速;要從堵車的高速下來,還是在高速上慢慢跟著車流走…這些決策都是駕駛的一部分。他說:「世界上各方面的事情都在影響著「駕駛」這件事的本質 」。
「 人腦有兩套系統:系統1 和系統2 」
關於 「系統1和系統2」的詳情,請閱讀 Thinking, Fast and Slow, by Daniel Kahneman,一本非常好的書,對人的認知工作是如何展開的進行了深入的分析。在這兒,我給還不了解的朋友介紹一下,以輔助本文前後的觀點。
心理學家認為,人思考和認知工作分成了兩個系統來處理:
- 系統1是快思考:無意識、快速、不怎麼費腦力、無需推理
- 系統2是慢思考:需要調動注意力、過程更慢、費腦力、需要推理
- 系統1先上,遇到搞不定的事情,系統2會出面解決。
系統1做的事情包括: 判斷兩個物體的遠近、追溯聲音的來源、完形填空 ( “我愛北京天安 ” )等等。
順帶一提,下象棋的時候,一眼看出這是一步好棋,這個行為也是系統1實現的——前提是你是一位優秀的玩家。
對於中國學生而言,你突然問他:「7乘以7」,他會不假思索的說:「49!」這是系統1在工作,因為我們在小學都會背99乘法表。這個49並非來自計算結果,而是背下來的(反覆重複)。
相應的,如果你問:「3287 x 2234等於多少?」,這個時候人就需要調用世界模型中的乘法規則,加以應用(計算)。這就是系統2的工作。
另外,在系統1所設定的世界裡,貓不會像狗一樣汪汪叫。若事物違反了系統1所設定的世界模型,系統2也會被激活。

在語言方面,Yoshua Bengio 認為系統1不做與語言有關的工作;系統2才負責語言工作。對於深度學習而言,它更適合去完成系統1的工作,實際上它根本沒有系統2的功能。
關於這兩個系統,值得一提的是,人是可以通過訓練,把部分系統2才能做的事情,變成系統1來完成的。比如中國學生得經過「痛苦的記憶過程」才能熟練掌握99乘法表,而不是隨著出生到長大的自然經驗,慢慢學會的。
但是這裡有2個有意思的特徵:
1. 變成系統1來處理問題的時候,可以節約能量。人們偏向相信自己的經驗,是因為腦力對能量的消耗很大,這是一個節能的做法。
2. 變成系統1的時候,會犧牲辯證能力,因為系統1對於邏輯相關的問題一無所知。「我做這個事情已經幾十年了」這種經驗主義思維就是典型案例。
想想自己長期積累的案例是如何在影響自己做判斷的?
「 單靠深度學習搞不定語言,現在不行,將來也不行 」
在人工智慧行業里,你經常會聽到有人這麼說 「儘管當前技術還實現不了理想中的人工智慧,但是技術是會不斷演進的,隨著數據積累的越來越多,終將會實現讓人滿意的人工智慧。」
如果這個說法,是指寄希望於僅靠深度學習,不斷積累數據量,就能翻盤——那就大錯特錯了。
無論你怎麼優化「馬車」的核心技術(比如更壯、更多的馬),都無法以此造出汽車(下圖右)。

對於大眾而言,技術的可演進性,是以宏觀的視角看人類和技術的關係。但是發動機的演化和馬車的關鍵技術沒有半點關係。
深度學習領域的3大牛,都認為單靠深度學習這條路(不能最終通向AGI)。感興趣的朋友可以沿著這個方向去研究:
- Geoffrey Hinton的懷疑:「我的觀點是都扔掉重來吧」
- Yoshua Bengio的觀點:「如果你對於這個每天都在接觸的世界,有一個好的因果模型,你甚至可以對不熟悉的情況進行抽象。這很關鍵……機器不能,因為機器沒有這些因果模型。我們可以手工製作這些模型,但是這遠不足夠。我們需要能發現因果模型的機器。」
- Yann LeCun的觀點:「A learning predictive world model is what we』re missing today, and in my opinion is the biggest obstacle to significant progress in AI.」
至於深度學習在將來真正的智能上扮演的角色,在這兒我引用Gary Marcus的說法:「I don』t think that deep learning won』t play a role in natural understanding, only that deep learning can』t succeed on its own.」
「 解釋人工智障產品 」
現在,我們了解了人們對話的本質是思維的交換,而遠不只是明文上的識別和基於識別的回復。而當前的人工智慧產品則完全無法實現這個效果。那麼當用戶帶著人類的世界模型和推理能力來跟機器,用自然語言交互時,就很容易看到破綻。
- Sophia是一個技術上的騙局(凡是鼓吹Sophia是真AI的,要麼是不懂,要麼是忽悠);
- 現在的AI,都不會有真正的智能(推理能力什麼的不存在的,包括Alpha go在內);
- 只要是深度學習還是主流,就不用擔心AI統治人類;
- 對話產品感覺用起來智障,都是因為想跳過思維,直接模擬對話(而現在也只能這樣);
- 「用的越多,數據越多,智能會越強,產品就會越好,使用就會越多」——對於任務類對話產品,這是一個看上去很酷,實際上不靠譜的觀點;
- 一個AI agent,能對話多少輪,毫無意義;
- to C的助理產品做不好,是因為解決不了「如何獲得用戶的世界模型數據,並加以利用」這個問題;
- to B的對話智能公司為何很難規模化?(因為場景模型是手動生成的)
- 先有智能,後有語言:要做到真正意義上的自然語言對話,至少要實現基於常識和世界模型的推理能力。而這一點如果能實現,那麼我們作為人類,就可能真的需要開始擔心前文提到的智能了。
- 不要用NLP評價一個對話智能產品:年底了,有些媒體開始出各種AI公司榜單,其中有不少把做對話的公司分在NLP下面。這就好比,不要用觸摸屏來衡量一款智能手機。在這兒我不是說觸摸屏或者NLP不重要(Essential),反而因為太重要了,這個環節成為了每一家的標配,以至於在這方面基本已經做到頭了,差異不過1%。
- 對於一個對話類產品而言,NLU儘管重要,但只應佔個整體配件的5-10%左右。更進一步來說,甚至意圖識別和實體提取的部分用大廠的,產品間差異也遠小於對話管理部分的差距。真正決定產品的是剩下的90%的系統。
到此,是不是有一種絕望的感覺?這些學界和行業的大牛都沒有解決方案,或者說連有把握的思路都沒有。是不是做對話智能這類的產品就沒戲了?上限就是這樣了么?
不是。對於一項技術而言,可能確實觸底了;但是對於應用和產品設計而言,並不是由一個技術決定的,而是很多技術的結合,這裡還有很大的空間。
作為產品經理,讓我來換一個角度。我們來研究一下,既然手中的工具是這些,我們能用他們來做點什麼?
Part 4:AI產品的潛力在於設計
「 AI的歸AI,產品的歸產品 」

有一部我很喜歡的電影,The Prestige,裡面講了一個關於「瞬間移動」的魔術。對於觀眾而言,就是從一個地方消失,然後瞬間又從另一個地方出現。
第一個魔術師,成功的在舞台上實現了這個效果。他打開舞台上的右邊的門,剛一進去的一瞬間,就從舞台左邊的門出來了。對觀眾而言,這完全符合他們的期望。
第二個魔術師在觀眾席里,看到效果後驚呆了,他感覺這根本毫無破綻。但是他是魔術師——作為一個產品經理——他就想研究這個產品是怎麼實現的。但是魔術行業里,最不受人待見的,就是魔術揭秘。
影片最後,他得到了答案(劇透預警):所有的工程機關、升降機、等等,都如他所料的藏在了舞台下面。但真正的核心是,第一個魔術師一直隱藏著自己的另一個雙胞胎兄弟。當他打開一個門,從洞口跳下舞台的那一刻,雙胞胎的另一位就馬上從另一邊升上舞台。
看到這裡,大家可能就恍然大悟:「 原來是這樣,雙胞胎啊!」
這感覺是不是有點似曾相識?在本文Part 2,我們聊到把對話系統的黑箱打開,裡面就是填一張表的時候,是不是有類似的感覺?對話式人工智慧的產品(對話系統)就像魔術,是一個黑箱,用戶是以感知來判斷價值的。
「 我還以為有什麼黑科技呢,我是雙胞胎我也可以啊。」
其實這並不容易。我們先不說魔術的舞台裡面的工程設計,這個魔術最難的地方是如何能在魔術師的生活中,讓另一個雙胞胎在大眾視野里完全消失掉。如果觀眾們都知道魔術師是雙胞胎,就很可能猜到舞台上的魔術是兩個人一起表演的。所以這個雙胞胎,一定不能出現在大眾的「世界模型」里。
為了讓雙胞胎的另一個消失在大眾視野里,這兩兄弟付出了很多代價,身心磨,絕非一般人能接受的,比如共享同一個老婆。
這也是我的建議:技術不夠的時候,設計來補。做AI產品的同學,不要期待給你智能。要是真的有智能了,還需要你幹什麼?人工智慧產品經理需要設計一套龐大的系統,其中包括了填表、也當然包括深度學習帶來的意圖識別和實體提取等等標準做法、也包括了各種可能的對話管理、上下文的處理、邏輯指代等等。
這些部分,都是產品設計和工程力量發揮的空間。
「 設計思路的基礎 」
我需要強調一下,在這裡,咱們講的是AI產品思路,不是AI的實現思路。
對於對話類產品的設計,以現在深度學習的基礎,語義理解應該只佔整個產品的5%-10%;而其他的,都是想盡一切辦法來模擬「傳送」這個效果——畢竟我們都知道,這是個魔術。如果只是識別就佔了你家產品的大量心血,其他的不去拉開差異,基本出來就是智障無疑。
在產品研發方面上,如果研發團隊能提供多種技術混用的工具,肯定會增加開發團隊和設計的發揮空間。這個做法也就是DL(Deep Learning) + GOFAI (Good Old Fashioned AI) 的結合。GOFAI是John Haugeland首先提出的,也就是深度學習火起來之前的symbolic AI,也就是專家系統,也就是大多數在AI領域的人都看不起的 「if then…」
DL+GOFAI 這個前提,是當前一切後續產品設計思路的基礎。
「 Design Principle:存在即為被感知 」
「存在即為被感知」 是18世紀的哲學家George Berkeley的名言。加州大學伯克利分校的命名來源也是為了紀念這位唯心主義大師。這個意思呢,就是如果你不能被感知到,你就是不存在的!
我認為「存在即為被感知」 是對話類AI產品的Design principle。對話產品背後的智能,是被用戶感知到而存在的。直到有一天AI可以代替產品經理,在那之前,所有的設計都應該圍繞著,如何可以讓用戶感覺和自己對話的AI是有價值的,然後才是聰明的。

要非常明確自己的目的,設計的是AI的產品,而不是AGI本身。就像魔術的設計者,給你有限的基礎技術條件,你能組裝出一個產品,體驗是人們難以想到。
同時,也要深刻的認識到產品的局限性。魔術就是魔術,並不是現實。
這意味著,在舞台上的魔術,如果改變一些重要的條件,它就不成立了。比如,如果讓觀眾跑到舞台的頂上,從上往下看這個魔術,就會發現舞台上有洞。或者「瞬間移動」的不是這對雙胞胎中的一個,而是一個觀眾跑上去說,「讓我來瞬間移動試試」,就穿幫了。
Narrow AI的產品,也是一樣的。如果你設計好了一個Domain,無論其中體驗如何,只要用戶跑到Domain的邊界以外了,就崩潰了。先設定好產品邊界,設計好「越界時給用戶的反饋」,然後在領域裡面,儘可能的模擬這個魔術的效果。
假設Domain的邊界已經設定清晰了,哪些方面可以通過設計和工程的力量,來大幅增加效果呢?
其實,在「Part 3 對話的本質」 里談到的與思維相關的部分,在限定Domain的前提下,都可以作為設計的出發點:你可以用GOFAI來模擬世界模型、也可以模擬場景模型、你可以Fake邏輯推理、可以Fake上下文指代——只要他們都限定在Domain里。
「 選擇合適的Domain 」
成本(工程和設計的量)和給用戶的價值並不是永遠成正比,也根據不同的Domain的不同。
比如,我認為現在所有的閑聊機器人都沒有什麼價值。開放Domain,沒有目標、沒有限定和邊界,對用戶而言,會認為什麼都可以聊。但是其自身「場景模型」一片空白,對用戶所知的常識也一無所知。導致用戶稍微試一下,就碰壁了。我把這種用戶體驗稱為 「每次嘗試都容易遇到挫折」。
可能,有些Domain對回復的內容並不那麼看重。也就並不需要那麼強壯的場景模型和推理機制來生成回復內容。
我們假設做一個「樹洞機器人」,可以把產品定義是為,扮演一個好的聽眾,讓用戶把心中的壓力煩惱傾訴出來。

這個產品的邊界,需要非常明確的,在用戶剛剛接觸到的時候,強化到用戶的場景模型中。主要是系統通過一些語言的反饋,鼓勵用戶繼續說。而不要鼓勵用戶來期望對話系統能輸出很多正確且有價值的話。當用戶做出一些陳述之後,可以跟上一些對「場景模型」依賴較小,泛泛的話。
「我從來沒有這麼考慮過這個問題,你為什麼會這麼想呢?」
「關於這個人,你還有哪些了解?」
「你覺得他為什麼會這樣?」
……
這樣一來,產品在需求上,就大幅減輕了對「自然語言生成」的依賴。因為這個產品的價值,不在回復的具體內容是否精準,是否有價值上。這就同時降低了對話背後的「場景模型」、「世界模型」、以及「常識推理」這些高維度模塊的需求。訓練的素材嘛,也就是某個特定分支領域(比如職場、家庭等)的心理諮詢師的對話案例。產品定義上,這得是一個Companion型的產品,不能真正起到理療的作用。
當然,以上並不是真正的產品設計,僅僅是用一個例子來說明,不同的Domain對背後的語言交互的能力要求不同,進而對更後面的「思維能力」要求不同。選擇產品的Domain時,盡量遠離那些嚴重依賴世界模型和常識推理,才能進行對話的場景。
有人可能說,你這不就是Sophia的做法么?不是。這裡需要強調的是Sophia的核心問題是欺騙。產品開發者是想忽悠大眾,他們真的做出了智能。
在這裡,我提倡的是明確告訴用戶,這就是對話系統,而不是真的造出了智能。這也是為什麼,在我自己的產品設計中,如果遇到真人和AI同時為用戶服務的時候(產品上稱為Hybrid Model),我們總是會偏向明確讓用戶知道,什麼時候是真人在服務,什麼時候是機器人在服務。這麼做的好處是,控制用戶的預期,以避免用戶跑到設計的Domain以外去了;不好的地方是,你可能「聽上去」沒有那麼酷。
所以,當我說「存在即為被感知」的時候,強調的是對價值的感知;而不是對「像人一樣」的感知。
「 對話智能的核心價值:在內容,不在交互 」
多年前,還在英國讀書的時候,我曾經在一個非常有名歷史悠久的秘密結社裡工作。我對當時的那位照顧會員需求的大管家印象深刻。你可以想像她好像是「美國運通黑卡服務」的超級禮賓,她有兩個超能力:
1. Resourceful,會員的奇葩需求都能想盡辦法的實現:一個身在法蘭克福的會員半夜裡遇到急事,臨時想儘快回倫敦,半夜沒有航班了,打電話找到大管家求助。最後大管家找到另一個會員的朋友借了私人飛機,送他一程,凌晨回到了倫敦。
2. Mind-reading,會員想要什麼,無需多言:
「Oliver,我想喝點東西…」
「當然沒問題,我待會給你送過來。」 她也不需要問喝什麼,或者送到哪裡。
人人都想要一個這樣的管家。蝙蝠俠需要Alfred;鋼鐵俠需要Javis;西奧多需要Her(儘管這哥們後來走偏了);iPhone 需要Siri;這又回到了我們在Part1里提到的,AI的to C 終極產品是智能助理。
但是,人們需要這個助理的根本原因,是因為人們需要它的對話能力么?這個世界上已經有70億個自然語言對話系統了(就是人),為什麼我們還需要製造更多的對話系統?
我們需要的是對話系統後面的思考能力,解決問題的能力。而對話,只是這個思考能力的交互方式(Conversational User Interface)。如果真能足夠聰明的把問題提前解決了,用戶甚至連話都不想說。
我們來看個例子。

我知道很多產品經理已經把這個iPhone初代發布的東西講爛了。但是,在這兒確實是一個非常好的例子:我們來探討一下iPhone用虛擬鍵盤代替實體鍵盤的原因。
普通用戶,從最直觀的視角,能得出結論:這樣屏幕更大!需要鍵盤的時候就出現,不需要的時候就消失。而且還把看上去挺複雜的產品設計給簡化了,更好看了。甚至很多產品經理也是這麼想的。實際上,這根本不是硬體設計的問題。原因見下圖。

其實喬布斯在當時也講的很清楚:物理鍵盤的核心問題是,(作為交互UI)你不能改變它。物理交互方式(鍵盤)不會根據不同的軟體發生改變。
如果要在手機上載入各種各樣的內容,如果要創造各種各樣的軟體生態,這些不同的軟體都會有自己不同的UI,但是交互方式都得依賴同一種(物理鍵盤無法改變),這就行不通了。
所以,實際代替這些物理鍵盤的,不是虛擬鍵盤,而是整個觸摸屏。因為iPhone(當時的)將來會搭載豐富的生態軟體內容,就必須要有能與這些還沒出現的想法兼容的交互方式。
在我看來,上述一切都是為了豐富的內容服務。再一次的,交互本身不是核心,它背後搭載的內容才是。
但是在當初看這個發布會的時候,我是真的沒有get到這個點。那個時候真的難以想像,整個移動互聯時代會誕生的那麼多APP,都有各自不同的UI,來搭載各式各樣的服務。
你想想,如果以上面這些實體鍵盤,讓你來操作大眾點評、打開地圖、Instagram或者其他你熟悉的APP,是一種怎樣的體驗?更有可能的是,只要是這樣的交互方式,根本設計不出剛才提到的那些APP。
與之同時,這也引申出一個問題:如果設備上,並沒有多樣的軟體和內容生態,那還應該把實體鍵設計成觸摸和虛擬的方式么?比如,一個挖掘機的交互方式,應該使用觸屏么?甚至對話界面?
「 對話智能解決重複思考 」
同樣的,對話智能的產品的核心價值,應該在解決問題的能力上,而不是停留在交互這個表面。這個「內容」 或者 「解決問題的能力」 是怎麼體現的呢?

工業革命給人類帶來的巨大價值在於解決「重複體力勞動」這件事。
經濟學家Tyler Cowen 認為,「 什麼行業的就業人越多,顛覆這個工種就會創造更大的商業價值。」 他在Average Is Over這本書里描述到:
「 20世紀初,美國就業人口最多的是農民;二戰後的工業化、第三產業的發展,再加上婦女解放運動,就業人工最多的工種變成輔助商業的文字工作者比如秘書助理呼叫中心(文員,信息輸入)。1980/90年代的個人計算機,以及Office 的普及,大量秘書,助理類工作消失。」
這裡提及的工作,都是需要大量重複的工作。而且不停的演變,從重複的體力,逐步到重複的腦力。
從這個角度出發,對一個場景背後的「思考能力」沒有把控的AI產品,會很快被代替掉。首當其衝的,就是典型意義上的智能客服。
在市場上,有很多這樣的智能客服的團隊,他們能夠做對話系統(詳見Part 2),但是對這各領域的專業思考,卻不甚了解。
我把「智能客服」 稱為「前台小姐姐」——無意冒犯,但是前台小姐姐的主要工作和專業技能並沒有關係。他們最重要的技能就是對話,準確點說是用對話來「路由」——了解用戶什麼需求,把不合適的需求過濾掉,再把需求轉給專家去解決。
但是對於一個企業而言,客服是只嘴和耳,而專家才是腦,才是內容,才是價值。客服有多不核心?想想大量被外包出去的呼叫中心,就知道了。
與這類客服機器人產品對應的,就是專家機器人。一個專家,必定有識別用戶需求的能力,反之不亦然。你可以想像一個企業支付給一個客服多少薪資,又支付給一個專家多少薪資?一個專家需要多少時間培訓和準備才能上崗,客服小姐姐呢?於此同時,專業能力是這個機構的核心,而客服不是。
正因為如此,很多人認為,人工的呼叫中心,以後會被AI呼叫中心代替掉;而我認為,用AI做呼叫中心的工作,是一個非常短暫的過渡型方案。很快代替人工呼叫中心的,甚至代替AI呼叫中心,是具備交互能力的專家AI中心。在這兒,「專家」的意義大於「呼叫」。
在經歷過工具化帶來的產能爬坡和規模效應之後,他們成本差不多,但是卻專業很多。比如他直接鏈接後端的供給系統的同時,還具備專業領域的推理能力,也能與用戶直接交互。
NLP在對話系統里解決的是交互的問題。
在人工智慧產品領域裡,給與一定時間,掌握專業技能的團隊一定能對話系統;而掌握對話系統的團隊則很難掌握專業技能。試想一下在幾年前,移動互聯剛剛出現的時候,會做app的開發者,去幫銀行做app;而幾年之後銀行都會自己開發app,而開發者幹不了銀行的事。
在這個例子里,做AI產品定義的朋友,你的產品最好是要代替(或者輔助)某個領域專家;而不要瞄準那些過渡性崗位,比如客服。
從這個角度出發,對話智能類的產品最核心的價值,是進一步的代替用戶的重複思考。Work on the mind not the mouth. 哪怕已經是在解決腦袋的問題,也盡量去代替用戶系統2的工作,而不只是系統1的工作。
在你的產品中,加入專業級的推理;幫助用戶進行抽象概念與具象細節之間的轉化;幫助用戶去判斷那些出現在他的模型中,但是他口頭還沒有提及的問題;考慮他當前的環境模型、發起對話時所處的物理時空、過去的經歷;推測他的心態,他的世界模型。
先解決思考的問題,再儘可能的轉化成語言。
Part 5:AIPM
「 缺了什麼?」
2018年10月底,我在慕尼黑為企業客戶做on site support。期間與客戶的各個BU、市場老闆們以及自身的研發團隊交流對話AI的應用。作為全球最頂尖的汽車品牌之一,他們也在積極尋求AI在自身產品和服務上的應用。
- 不缺技術人才。儘管作為傳統行業的大象,可能會被外界視為不擅長AI,其實他們自身並不缺少NLP的研發。當我跟他們的NLP團隊交流時,發現基本都有世界名校的PHD。而且,在閉門的供應商大會上,基本全球所有的科技大廠和諮詢公司都在場了。就算實在搞不了,也大有人排著隊的想幫他們搞。
- 創新的意願強烈。在我接觸過的大企業當中,特別是傳統世界100強當中中,這個巨頭企業是非常重視創新的。經過移動互聯時代,丟掉的陣地,他們是真心想一點點搶回來,並試圖領導所在的行業,而不是follow別人的做法。不僅僅是像「傳統的大企業創新」那樣做一些不痛不癢的POC,來完成創新部門的KPI。他們則真的很積極地推進AI的商業化,而且勇於嘗試改變過去和Tech provider之間的關係。這點讓我印象深刻,限於保密條款,在此略過細節。(關於國際巨型企業借新技術的初創團隊之手來做顛覆式創新,也是一個很有意思的話題,以後新開一個Topic。)
- 數據更多。那麼傳統巨頭的優勢就在於,真正擁有業務場景和實際的數據。賣出去的每一台產品都是他們的終端,而且開始全面聯網和智能化。再加上,各種線下的渠道、海量的客服,其實他們有能力和空間來搜集更完整的用戶生命周期數據。
當然,作為硬幣的另一面,百年品牌也自然會有嚴重的歷史牽絆。機構內部的合規、採購流程、數據的管控、BU之間的數據和行政壁壘也是跑不掉的。這些環節的Trade off確實大大的影響了對上述優勢的利用。
但是最缺少的還是產品定義能力。
如果對話智能的產品定義失敗,後面的執行就算是完美的,出來的效果也是智障。有些銀行的AI機器人就是例子:立項用半年,競標用半年,開發用一年,然後上線跑一個月就因為太蠢下線了。
但這其實並不是傳統行業的特點,而是目前所有玩家的問題——互聯網或科技公司的對話AI產品也逃不掉。可能互聯網企業還自我感覺良好,在這產品設計部分,人才最不缺了——畢竟「人人都是產品經理」 嘛。但在目前,咱們看到的互聯網公司出來的產品也都是差不多的效果,具體情況咱們在Part 2里已經介紹足夠多了。
我們來看看難點在哪裡。
AI產品該怎麼做定義呢?也就是,需要怎樣的產品才能實現商業需求。技術部門往往主要關注技術實現,而不背商業結果KPI;而業務部門的同事對AI的理解又很有限,也就容易提出不合適的需求。
關鍵是,在做產品定義時,你想要描述 「我想要一個這樣的AI,它可以說…」 的時候你會發現,因為是對話界面,你根本無法窮盡這個產品的可能性。其中一個具體細節就是,產品文檔該怎麼寫,這就足夠挑戰了。
「 對話AI產品的管理方法 」
先給結論:如果還想沿用管理GUI產品的方法論來管理對話智能產品,這是不可能的。
從行業角度來看,沒有大量成功案例,就不會有流水線;沒有流水線,就沒有基於流水線的項目管理。

也就是說,從1886年開始第一輛現代汽車出現,到1913年才出現第一條流水線——中間有27年的跨度。再到後來豐田提出The Toyota Way,以精益管理(Lean Management)來快速迭代(類似敏捷開發)以盡量避免浪費,即Kaizen(改善),這已經是2001年的事情了。
這兩天和其他也在給大企業做對話的同行交流的時候,聽到很多不太成功的產品案例,歸結起來幾乎都是因為 「產品Scope定義不明」,導致項目開展到後面根本收不了尾。而且因為功能之間的耦合緊密,連線都上不了(遇到上下文對話依賴的任務時,中間環節一但有缺失,根本走不通流程)。這些都是行業早期不成熟的標誌。
「 對話AI產品的Design Principle 尚未出現 」
對話智能領域相對視覺類的產品,有幾個特性上的差異:
1)是產品化遠不如視覺類AI成熟;
2)深度學習在整個系統里扮演的角色雖然重要,但是還是很少,遠不夠撐起來有價值的對話系統;
3)產品都是黑箱,目前在行業中尚無比較共同認可的設計標準。
APP發展到後面,隨著用戶的使用習慣的形成,和業界內成功案例的「互相交流」,逐步形成了一些設計上的共識,比如下面這一排,最右邊紅圈裡的 「我」:
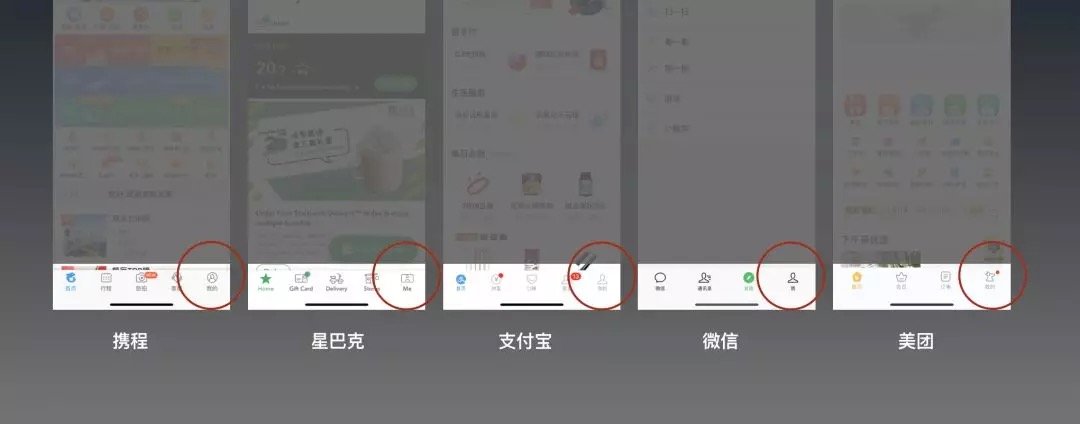
但是,從2007年iPhone發布,到這些移動產品的設計規範逐步形成, 也花了近6、7年時間,且不提這是圖形化界面。
到如今,這類移動設備上的產品設計標準已經成熟到,如果在設計師不遵循一些設計思路,反而會引起用戶的不習慣。只是對話系統的設計規範,現在談還為時尚早。
到這裡,結合上述兩個點(對話AI產品的管理方法、設計規範都不成熟),也就可以解釋為什麼智能音箱都不智能。因為智能音箱的背後都是一套「技能打造框架」,給開發者,希望開發者能用這套框架來製作各種「技能」。
而「對話技能類平台」 在目前根本走不通。任何場景一旦涉及到明文識別以外的,需要對特定的任務和功能進行建模,然後再融合進多輪對話管理里的場景,以現在的產品成熟程度,都無法抽象成有效的設計規範。現在能抽象出來的,都是非常簡單的上下文管理(還記得Part 2里的「填表」么?)。
我就舉一個例子,絕大部分的技能平台,根本就沒有「用戶生命周期管理」的概念。這和服務流程是兩碼事,也是很多機器人智障的諸多原因之一。因為涉及到太細節和專業的部分,咱們暫且不展開。
也有例外的情況:技能全部是語音控制型,比如「關燈開燈」 「開空調25度」。這類主要依賴明文識別的技能,也確實能用框架實現比較好的效果。但這樣的問題在於,開放給開發者沒有意義:這類技能既不需要多樣的產品化;開發者從這類開發中也根本賺不到錢——幾乎沒有商業價值。
另一個例外是大廠做MLaaS類平台,這還是很有價值的。能解決開發者對深度學習的需求,比如意圖識別、分詞、實體提取等最底層的需求。但整個識別部分,就如我在Part 3&4里提到的,只應佔到任務對話系統的10%,也僅此而已。剩下的90%的工作,也是真正決定產品價值的工作,都得開發者自己搞。
他們會經歷些什麼?我隨便舉幾個最簡單的例子(行業外的朋友可以忽略):
- 如果你需要訓練一個意圖,要生成1000句話來做素材,那麼「找100個人,每人寫10句」 的訓練效果要遠好於 「找10個人,每人寫100句」;
- 是用場景來分意圖、用語義來分意圖和用謂語來拆分意圖,怎麼選?這不僅影響機器人是否能高效支持「任務」之間的跳轉,還影響訓練效率、開發成本;
- 有時候意圖的訓練出錯,是訓練者把自己腦補的內容放進去了;
- 話術的重要性,不僅影響用戶看著舒不舒服,更決定了他的回復的可能性——以及回復的回復的可能性——畢竟他說的每一句後面的話,都需要被識別後,再回復;
- 如果你要給一個電影院做產品,最好用圖形化界面,而不要用語言來選座位:「現在空著的座位有,第一排的1,2,3,4….」
這些方面的經驗和技巧數都數不完,而且還是最淺顯、最皮毛的部分。你可以想像,對話智能的設計規範還有多少路要走——記得,每個產品還是黑箱,就算出了好效果,也看不到裡面是怎麼設計的。
「 一個合適的AIPM 」
當真正的人工智慧實現之後,所有產品經理所需要做的思考,都會被AI代替。所以,真正的人工智慧也許是人類最後的一個發明。在那一天之前,對話智能產品經理的工作,是使用各種力量來創造智能給人的感覺。
AIPM一定要在心中非常明確 「AI的歸AI,產品的歸產品」。做工具的和用工具的,出發點是完全不同。應該是帶著做產品的目的,來使用AI;千萬不要出現「AIPM是來實現AI的」這樣的幻覺。

我們都熟悉,PM需要站在「人文和技術的十字路口」來設計產品。那麼對話智能的AIPM可能在這方面可能人格分裂的情況更極端,以至於甚至需要2個人來做配合成緊密的產品小組——我認為一個優秀的對話智能產品經理,需要在這三個表現優秀:
1. 懂商業:就是理解價值。
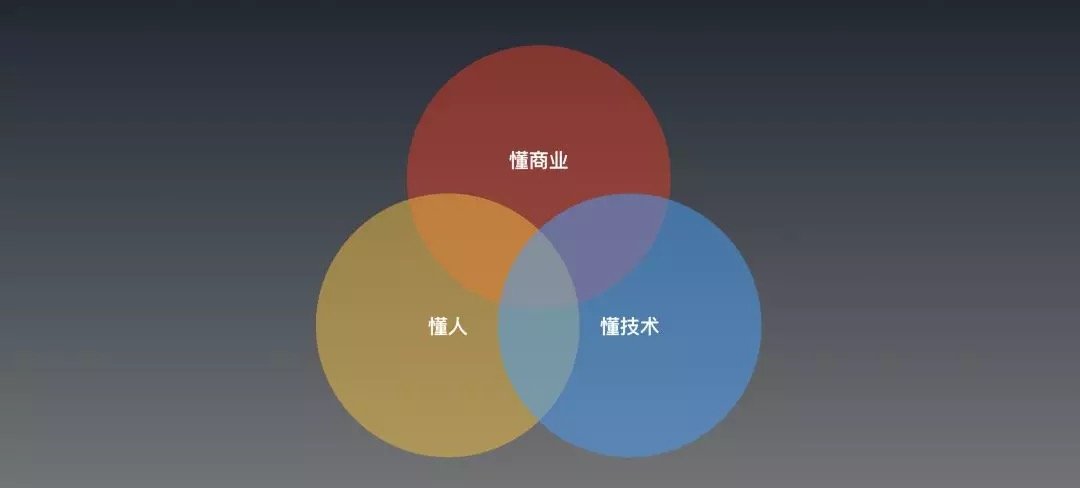
對話產品的價值一定不在對話上,而是通過對話這種交互方式(CUI)來完成背後的任務或者解決具體問題。一個本來就很強的APP,就不要想著去用對話重新做一遍。反而是一些APP/WEB還沒有能很好解決的問題,可以多花點時間研究看看。
這方面在Part 4 里的對話智能的核心價值部分,當中有詳細闡述,在這裡就不重複了。
2. 懂技術:理解手中的工具(深度學習 + GOFAI)
一個大廚,應該熟悉食材的特性;一個音樂家,應該熟悉樂器的特徵;一個雕塑家,應該熟悉手中的鑿子。大家工具都差不多,成果如何,完全取決於藝術家。
現在,AIPM手中有深度學習,那麼就應該了解它擅長什麼和不擅長什麼。以避免提出太過於荒謬的需求,導致開發的同學向你發起攻擊。了解深度學習的特性,會直接幫助我們判斷哪些產品方向更容易出效果。比如,做一個推薦餐廳的AI,就比做一個下圍棋的AI難太多了。
下圍棋的產品成功,並不需要人類理解這個過程,接受這個結果就行。而推薦一個餐廳給用戶,則必須要去模擬人的思維後,再投其所好。
人們在想要推薦餐廳的時候,通過對話,了解他的需求(絕對不能問太多,特別是顯而易見的問題,比如他在5點的時候,你問他要定幾點的餐廳)
對於圍棋而言,每次(單次)輸入的可能性只有不超過棋盤上19×19=361種可能性;一局棋的過程儘管千變萬化,我們可以交給深度學習的黑箱;最後決定輸贏所需要的信息,全部呈現在棋盤上的落子上,儘管量大,但與落子以外的信息毫無關係,全在黑箱里,只是這個黑箱很大。最後,輸出的結果的可能性只有兩種:輸或者贏。
對於推薦餐廳。每次輸入的信息,實際並不包含決策所需要的全部信息(無法用語言表達所有相關的影響因素,參考Part 3 里世界模型部分);而且輸出的結果是開放的,因為推薦的餐廳,既不可被量化,更不存在絕對的對錯。
了解CUI的特性後,不該用對話的就不要強上對話交互;有些使用對話成本非常高,又很不Robust的環節,同時用戶價值和使用頻次又很低的,就要考慮規避——咱們是做產品的,不是實現真正的AI的,要分清楚。
3. 懂人:心理和語言
這可能是當前對話類產品最重要的地方,也是拉開和其他產品設計的核心部分。也可能是中年人做產品的第二春。
對心理的理解,指的是當用戶在說話的時候,對他腦中的模型的理解。英文中「Read the room」就是指講話之前,先觀察一下了解周圍聽眾的情況,揣摩一下他們的心理,再恰當的說話。
比如,講話的時候,是否聽眾開始反覆的看錶?這會讓直接影響對話的進程。你有遇到過和某人對話起來感覺很舒服的么?這個人,不僅僅是語言組織能力強,更重要的則是他對你腦中的對話進程的把握,以及場景模型,甚至對你的世界模型有把握。他還知道怎麼措辭,會更容易讓你接受,甚至引導(Manipulate)你對一些話題的放棄,或者是加強。
對話系統的設計也是一樣的。哪些要點在上文中說過?哪些類型的指代可以去模擬?如果是文字界面,用戶會不會拉回去看之前的內容?如果是語音界面,用戶腦中還記不記得住?如果記得住,還強調,會感覺重複;如果記不住,又不重複,會感覺困惑。
對語言的理解,則是指對口語特性的理解。我知道Frederick Jelinek說的「每當我開除一個語言學家,Speech識別的準確率就會增高」。只是,現在根本沒有真正意義上的自然語言生成(NLG),因為沒有真正的思維生成。
所以,任務類的對話的內容,系統不會自然產生,也無法用深度學習生成。對於AIPM而言,要考慮的還是有很多語言上的具體問題。一個回復里,內容會不會太長?要點該有幾個?謂語是否明確,用戶是否清晰被告知要做什麼?條件又是什麼?這樣的回復,能引發多少種可能的問詢?內容措辭是否容易引起誤解(比如因為聽眾的背景不同,可能會有不同的解讀)?
從這個角度而言,一個好的對話系統,必定出自一個很能溝通的人或者團隊之手。能為他人考慮,心思細膩,使用語言的能力高效,深諳人們的心理變化。對業務熟悉,能洞察到用戶的Context的變化,而其格調又幫助用戶控制對話的節奏,以最終解決具體問題。
Part 6:可見的未來是現狀的延續
「 過渡技術」
在幾周前,我與行業里另一家做對話的CEO討論行業的將來。當我聊到「深度學習做對話還遠達不到效果」的態度時,他問我:「如果是悲觀的,那麼怎麼給團隊希望繼續往前進呢?」
其實我並不是悲觀的,可能只是更客觀一點。
既然深度學習在本質上搞不定對話,那麼現在做對話AI的實現方式,是不是個過渡技術?這是一個好問題。
我認為,用現在的技術用來製作AI的產品,還會持續很長時間,直到真正智能的到來。
如果是個即將被替代或者顛覆的技術,那就不應該加碼投入。如果可以預見未來,沒人想在數碼相機崛起的前期,加入柯達;或者在LED電視普及之前,重金投入在背投電視的研發上。而且難以預測的不僅僅是技術,還有市場的發展趨勢。比如在中國,作為無現金支付方式,信用卡還沒來得及覆蓋足夠多的支付場景,就被移動支付斷了後路。
而現在的對話智能所使用的技術,還遠沒到這個階段。
Clayton M. Christensen在《創新者的窘境》里描述了每個技術的三個階段:
- 第一個階段,緩步爬坡;
- 第二個階段開始迅猛發展,但是到接近發展的高地(進步減速)的時候,另一個顛覆式技術可能已經悄悄萌芽,並重複著第一個技術的發展歷程;
- 第三個階段,則進入發展瓶頸,並最終被新技術顛覆
下圖黑色部分,為書中原圖:

而當前對話AI的技術,還在第一階段(藍色旗幟位置)稱不上是高速發展,還處於探索的早期。黑箱的情況,會使得這個周期(第一階段)可能比移動時代更長。
以當前的技術發展方向,結合學術界與工業界的進展來看,第二個技術還沒有出現的影子。
但是同樣因為深度學習在對話系統中,只扮演的一小部分角色,所以大部分的空間,也是留給大家探索和成長的空間。換句話來講,還有很多發展的潛力。
前提是,我們在討論對話類的產品,而不是實現AI本身。只是,這個階段的對話AI,還不會達到人們在電影里看到的那樣,能自如的用人類語言溝通。
2) 服務提供者崛起的機會
因為上述的技術發展特點,在短期的將來,數據和設計是對話智能類產品的壁壘,技術不是。
只是這裡說的數據,不是指的用來訓練的數據。而是供給端能完成服務的數據;能夠照顧用戶整個生命周期的數據;是當對話發生的時候,用戶的明文以外的數據這些數據;影響用戶腦中的環境模型、影響對任務執行相關的常識推理數據,等等。
而隨著IOT的發展,服務提供者,作為與用戶在線下直接打交道的一方,是最有可能掌握這些數據。他們能在各個Touch point去部署這些IOT設備,來搜集環境數據。並且,由他們決定要不要提供這些數據給平台方。
但是,往往這些行業里的玩家都是歷史悠久、行動緩慢。其組織機構龐大,而且是組織結構並不是為了創新而設計,而是圍繞著如何能讓龐大的軀幹不用思考,高速執行。而這也正是互聯網企業和創業企業的機會。
3)超級終端與入口之爭
對話智能類的產品必須搭載在硬體終端上。很多相關的硬體嘗試,都是在賭哪個設備能夠成為繼手機之後的下一個超級終端。就好像智能手機作為計算設備,代替了PC的地位一樣。
畢竟,在移動時代,搶到了超級終端,就搶到了用戶獲取服務的入口。在入口的基礎之上,才是各個應用。
如果對話智能發展到足夠好的體驗,並能覆蓋更多的服務領域時,哪一個終端更有可能成為下一個超級終端呢?智能音箱、帶屏幕的音箱、車載設備甚至車機、穿戴設備等等都可以搭載對話智能。在5G的時代,更多的計算交給雲端,在本地設備上留下能耗較低的OS和基礎設施,I/O交給麥克風和音頻播放就完成了。

因此任意一個聯網設備,都可能具備交互和傳遞服務的能力,進一步削弱超級終端的存在。也就是說,作為個人用戶,在任意一個聯網設備上,只要具備語音交互和聯網能力,都可能獲得服務。特別是一些場景依賴的商業服務,如酒店、醫院、辦公室等等。
隨著這些入口的出現,在移動時代的以流量為中心的商業模式,可能將不再成立。而新的模式可能誕生,想像一下,每一個企業,每一個品牌都會有自己的AI。一個或是多個,根據不同的業務而產生;對內部員工服務或者協助其工作,同時也接待外部的客服,管理整個生命周期從註冊成這家企業的用戶開始,到最後(不幸地)中斷服務為止。
只是這個發展順序是,先有服務,再有對話系統——就好像人,是有腦袋裡的想法,再用對話來表達。
結語
在本文中,所有與技術和產品相關的討論,都是在強調一個觀點:一個產品是由很多技術組合而成。我不希望傳達錯誤的想法,類似「深度學習不重要」之類的;相反,我是希望每一類技術都得到正確的認識,畢竟我們離真正的人工智慧還有距離,能用上的都有價值。
作為AI從業者,心中也會留有非理性的希望,能早日見證到人造的智能的到來。畢竟,如果真正的智能出現了,可能產品經理(以及其他很多崗位)就徹底解放了(或者被摧毀了)。
這或許就是人類的最後一個發明。
本文開始於慕尼黑,最終成稿於北京,斷斷續續耗時接近3個月。期間與很多大企業,行業內的創業者,還有一些資本的同學溝通交流。在此表示感謝,就不一一點名啦。
本文轉自公眾號 S先生,原文地址

7 Comments
感謝作者的輸出
感謝讀者的肯定
講的很好,十分感謝作者的輸出
感謝您的肯定
寫的很好,文筆幽默,內容翔實。有一點小小的建議:標題以人工智慧整體作為出發點,而文章主要集中在NLP相關產品上,這可能會對讀者產生一定的誤導。
這是一篇轉載文章,博主的內容還達不到這麼高的高度~
如今GPT出現了,又出現什麼變化了呢?