

本文轉載自公眾號 量子位,原文地址
如果你的一大坨數據沒。有。標。簽,怎麼辦?
無監督學習是機器學習算法里非常撲朔迷離的一個類別,負責解決這些「沒有真實值 (no-ground-truth) 」的數據。
本文會講到,無監督學習到底是什麼,和機器學習的其他算法有何本質區別,用的時候有哪些難點,以及推薦閱讀的傳送門。
無監督學習是什麼?
最簡單的理解方式,就是把算法想像成考試。卷子上的每道題對應一個答案,得分高低就要看你的答案和標準答案有多接近。不過,如果沒有答案只有問題,你要怎麼給自己打分?
把這一套東西挪到機器學習上來。傳統的數據集都有標籤 (相當於標答) ,邏輯是「X導致Y」。比如,我們想要知道,推特上粉絲更多的人,是不是收入也更高。那麼,input是粉絲數,output是收入,要試着找出兩組數據之間的關係。
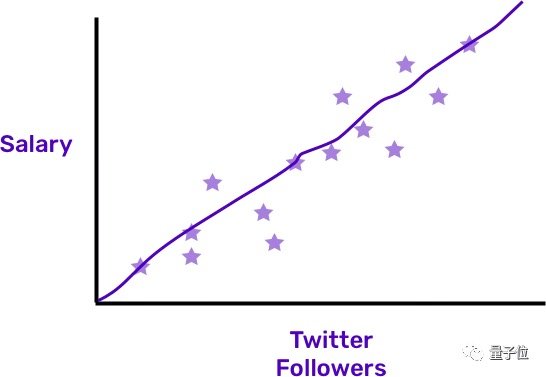
每顆星是一個數據點,機器學習就是要畫出差不多能連起那些點的一條線,以此解釋input和output之間的關係。但在無監督學習里,並沒有output這個東西。
我們要做的是分析input,也就是粉絲數。但沒有收入,或者Y。就像是考試只有題,沒有標答一樣。

其實,也不一定是沒有Y,可能我們只是沒有辦法獲得收入數據。不過這都不要緊,重要的是不需要畫出X和Y之間的那條線了,不需要找它們之間的關係了。
那麼,無監督學習的目標是什麼?如果只有input沒有output,我們到底該怎麼辦?
無監督學習分幾種
聚類(Clustering)
任何行業都需要對用戶的理解:他們是誰?是什麼促使他們做出購買的決定?
通常,用戶可以按照某些標準分為幾組。這些標準可簡單如年齡如性別,也可複雜如用戶畫像、如購買流程。無監督學習可以幫我們自動完成這個任務。

聚類算法會跑過我們的數據,然後找出幾個自然聚類 (Natural Clusters) 。以用戶為例,一組可能是30多歲的藝術家,另一組可能是家裡養狗的千萬富翁。我們可以自己選擇聚類的數量,這樣就能調整各個組別的粒度 (Granularity) 。
有以下幾種聚類方法可以選用:
· K-Means聚類,把所有數據點劃分到K個互斥組別里。複雜之處在於如何選取K的大小。
· 層次聚類 (Hierarchical Clustering) ,把所有數據點劃分到一些組別、和它們的子組別里,形成像族譜一樣的樹狀圖。比如,先把用戶按年齡分組,然後把各個組別按照其他標準再細分。
· 概率聚類 (Probabilistic Clustering) ,把所有數據點按照概率來分組。K-Means其實就是它的一種特殊形式,即概率永遠為0或1的情況。所以這種聚類方式,也被親切地稱為「模糊的K-Means」。
這幾種並無本質區別的方法,寫成代碼可能就長這樣——
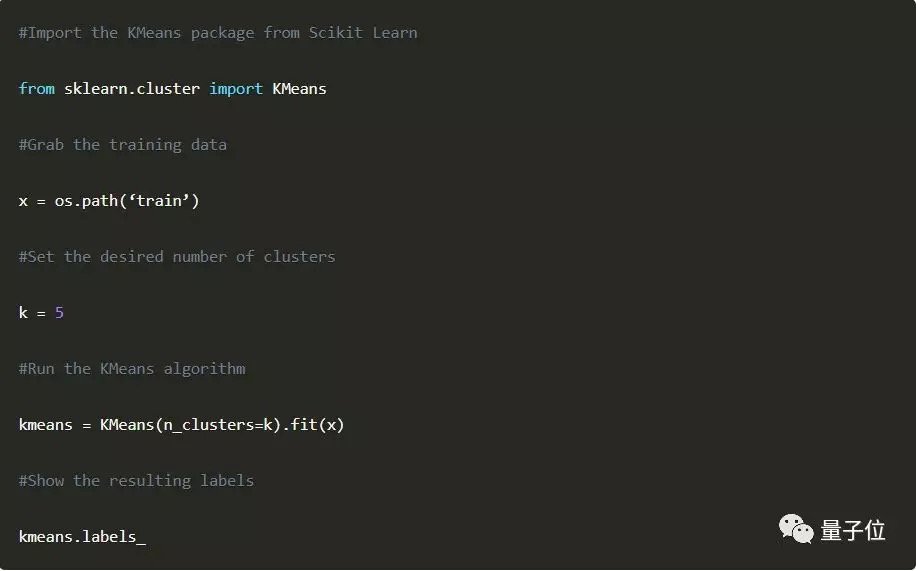
任何聚類算法的output,都會是所有的數據點、以及它們所對應的組別。這就需要我們自己來判斷,output代表怎樣的含義,或是算法到底發現了什麼。數據科學的魅力即在於,output加上人類的解讀,便會產生價值。
數據壓縮 (Data Compression)
在過去的十年間,設備的計算能力和存儲能力都增強了許多。不過,即便在今天我們依然有理由,讓數據集儘可能小、並儘可能高效。這意味着,只要讓算法去跑一些必要的數據,而不要做過多的訓練。

無監督學習可以用一種名為數據降維 (Dimentionality Reduction) 的方式做到這一點。
數據降維的「維」,就是指數據集有多少列。這個方法背後的概念和信息論 (Information Theory) 一樣:假設數據集中的許多數據都是冗餘的,所以只要取出一部分,就可以表示整個數據集的情況了。
在實際應用中,我們需要用某種神秘的方式,把數據集里的某些部分結合到一起,來傳達某些意義。這裡有我們比較常用的兩種降維方式——
· 主成分分析算法 (PCA) ,找出能夠把數據集里的大多數變化聯繫起來的線性組合。
· 奇異值分解 (SVD) ,把數據的矩陣分解成三個小矩陣。
這兩種方法,以及另外一些更複雜的降維方式,都用了線性代數的概念,把矩陣分解成容易消化的樣子,便於傳遞信息。
數據降維可以在機器學習算法里,起到非常重要的作用。以圖像為例,在計算機視覺里,一幅圖像就是一個巨大的數據集,訓練起來也很費力。而如果可以縮小訓練用的數據集,模型就可以跑得更快了。這也是為什麼,PCA和SVD都圖像預處理時常見的工具。
無監督深度學習
無監督學習,把領地擴張到了神經網絡和深度學習里,這一點也不奇怪。這個領域還很年輕,不過已經有了自編碼器 (Autoencoder) 這樣的先行者。
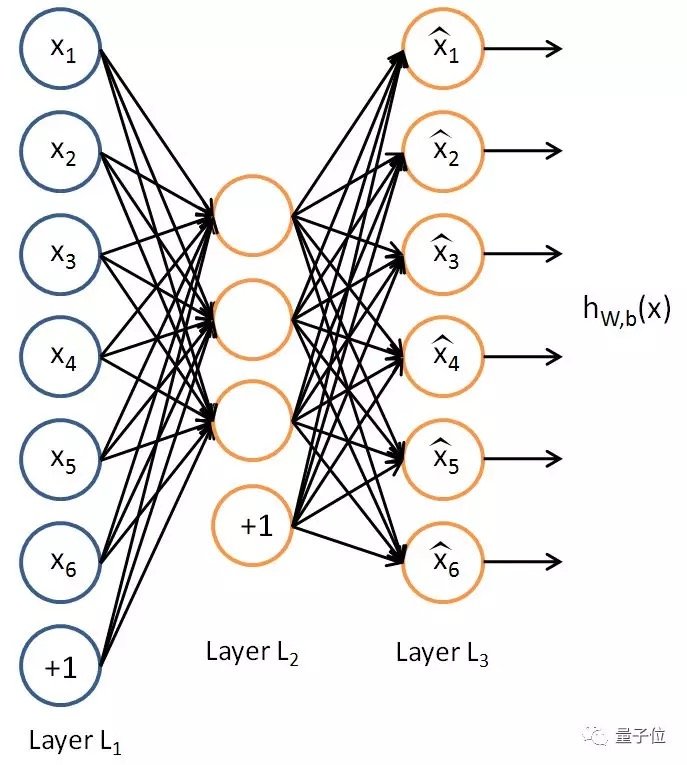
自編碼器和數據壓縮算法背後的邏輯差不多,用一個子集來反映原始數據集的特徵。像神經網絡一樣,自編碼器利用權重把input轉換成理想的output。不過在這裡,output和input並不是兩種不同的東西,output只是input的一種更輕便的表示方式。
在計算機視覺中,自編碼器被用在圖像識別算法里。現在,它也已經把觸角伸向聲音和語音識別等更多的領域。
實戰難點有哪些
除了尋找合適的算法和硬件,這樣常見的問題之外,無監督學習自帶一種神秘的氣質——不知道任務到底完成了沒有。
在監督學習里,我們會定下一套標準,以做出模型調試的決策。精確度 (Precision) 和查全率 (Recall) 這樣的指標會告訴我們,現在的模型有多準確,然後我們可以調整參數來優化模型。分數低,就要繼續調。
可是,無監督學習的數據沒有標籤,我們就很難有理有據地定下那套衡量標準。以聚類為例,怎麼知道K-Means的分類好不好 (比如K值取的合不合適) ?沒有標準了,我們可能就需要有點創造力。
「無監督學習在我這裡管用么?」是人們經常提出的問題。這裡,具體問題要具體分析。還以用戶分組為例,只有當你的用戶真的和自然聚類相匹配的時候,聚類的方法才有效。
雖然有些風險,但最好的測試方法,可能就是把無監督模型放到現實世界里,看看會發生什麼——讓有聚類的和沒有聚類的算法做對比,看聚類能不能得出更有效的信息。
當然,研究人員也在嘗試編寫,自帶 (相對) 客觀評判標準的無監督學習算法。那麼,栗子在哪裡?

1 Comment
但是沒有講清楚twitter粉絲input和output的那個問題嗎?好難受