

本文转载自公众号 读芯术,原文地址
现实世界中的数据可能十分混乱复杂,不论它是相关的SQL数据库、Excel文件或是其它任何数据源。尽管这些数据通常都是表格的结构,即每一行(样本)相对于每一列(特征)都有其对应的值,但是这些数据可能很难理解和处理。为了让机器学习模型能够更轻松地读取数据,我们可以运用特征工程来提升模型的性能。
什么是特征工程?

特征工程是指将给定的数据转换成为更易解析的形式的过程。本文中,我们希望能使机器学习模型更加透明,同时也能够生成一些特征,让没有相关背景知识的人能够更好的理解提供给他们的可视化数据内容。然而,机器学习模型中透明的概念是很复杂的,因为针对不同种类的数据,不同的模型需要使用不同的方法。
示例:坐标
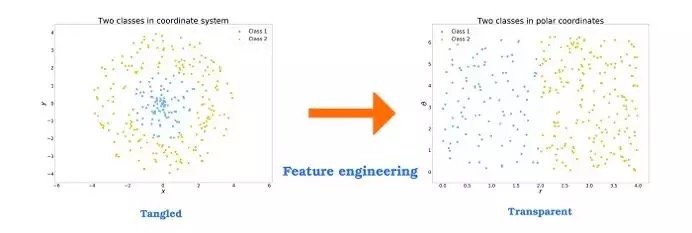
为了理解特征工程的概念,我们可以举一个简单的例子。在下面的图中,我们能够看见两种点。想象一下,现在有一座靠近这些点的仓库,它只能为一些距离有限的客户提供服务。从人类的角度来看,很容易就能理解我们需要考虑距离仓库有限半径内的点。这就需要两种已知特征的组合。
但是这对算法来说并不是显而易见的。例如,基于决策树(decision tree)的算法一次只会考虑一个特征,并将数据集分为两个部分,其中一个的特征值高于任意阈值,另一个低于阈值。如上所述划分空间需要大量地进行这种拆分。
坐标转换
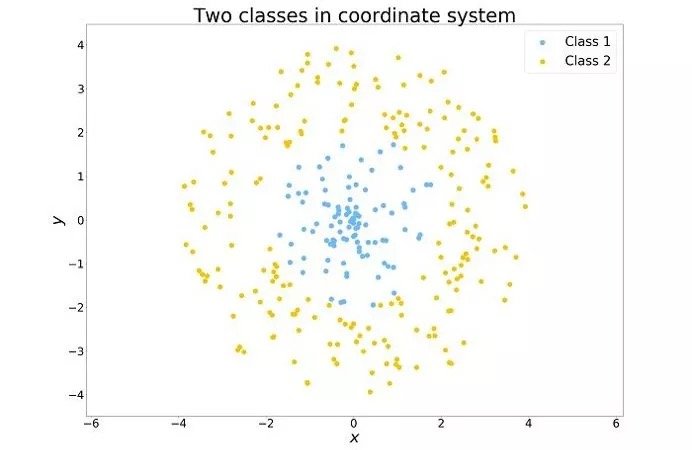
但是,我们可以进行一个高中学过的简单坐标转化。也就是从所谓的笛卡尔坐标系(x,y)转换为极坐标系(r,0)。这里我们使用如下转换:
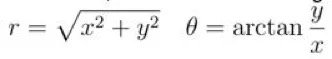
现在,任何算法都更容易对数据进行分析。将数据集按照r轴进行拆分,阈值设为r split=2。显然这个例子并没有什么价值,现实中的数据很少会如此简单,但是它展示了适当的特征工程的潜力。

连续数据
连续数据是最常见的数据类型。它有可能包含给定范围中的任意值。比如,它可以是产品的价格、工业生产过程中的温度,或是地图中对象的坐标。这里主要通过领域数据来生成特征。例如,你可以用售价减去进价得到利润,或者可以计算地图上两地之间的距离。新的可生成特征只受可用特征和已知的数学运算的限制。
分类特征
第二种最常见的数据类型是分类特征,指能从一组有限的值中获取值的特征。通常该特征只能有一个单一的值。还有另一种情况,但是在这种情况下,这种特征常常被拆分为一组特征。例如依据ISO/IEC 5218标准,性别可被分为下列四种值之一:未知、男性、女性和不适用。
编码和独热(one-hots)
这种数据的问题在于算法并不是设计用来处理文本数据的。处理这个问题的标准变通方法是分类编码。引入一个整数来代表每一个类别。例如,之前提到的性别的标准分类编码分别为0、1、2和9。但是有时候为了可视化或模型效率,可以使用不同的编码。我们可以用数个布尔特征来代替含有多个层级的单一特征,这些布尔特征中只有一个能够取True值。这叫做独热编码(one-hot encoding),尤其流行于神经网络。
缺失值
在现实世界中,有时候无法获取一些数据,或者该数据在处理过程中发生了丢失。因此,数据中经常会含有缺失值。
处理这些值是单独的一门艺术。这部分数据处理被称为数据清洗,且通常被认为是一个单独的步骤。然而在创建一些新的特征时,需要牢记缺失值有可能隐藏在不同的名字和值背后。
一些编程语言和库中含有特殊的对象与缺失值对应。通常它由“NaN”表示-并不是数字,而是用任意的可用值代替。例如,在一列正整数中,缺失值可以被编码为“-1”。但是如果不预先对它的值进行分析,在计算该特征的平均值时就会遭遇不便。其它时候,缺失值可以用“0”代替,这样就能够轻松地进行求和,但是却无法生成一个需要除操作的新特征。
另一种更常见的选择是用当前值的平均值或中位数来填补缺失值。但是同样,再次计算平均值时会得到不同的结果,所以根据真实平均值和错误平均值生成的新特征之间会有明显差异。这些例子都显示出一个不变的事实,理解你的数据!这在进行特征工程时也很重要。
这里有缺失!
一个常见的方法是引入一个布朗特征,指示出给定样本中的给定特征是否含有缺失值。若有缺失则布朗特征会显示为True,若一切正常则显示False。它让机器学习模型能够判断是否应当将给定值视为可信的,或是否应当另行处理。
归一化
另一个常见的特征工程方法是将数据置入一个给定的区间。为什么要这么做呢?第一个原因很简单,即对有限范围内的数字进行运算会避免一些数值误差,同时限制所需的计算性能。第二个原因是一些机器学习算法能够更好的处理归一化的数据。数据归一化的方法有多种。
标准归一化
在自然和人类社会中,许多事物都服从于正太(高斯)分布。这就是为什么会向分布中引入归一特征。它由如下等式表示:

这里X表示新的特征,它等于旧特征的每个样本减去旧特征的平均值后再除以标准偏差。标准偏差表示特征值的离散程度。这样,X的取值范围会在[-1,1]的区间内。
特征缩放
另一种归一化是用特征值减去最小值Xmin,再除以它的取值范围Xmax – Xmin,得到入下表达式:
这种归一化会将给定的特征归入[0,1]的区间内。
正确的模型归一化
正如之前提到的,不同的模型需要不同的归一化来实现高效运行。举个例子,在k-近邻的案例中,特定的特征范围表示权重。值越大特征就越重要。在神经网络的案例中,归一化对于最终运行结果本身来说并不重要,但是它能够加快训练速度。另一方面,基于决策树的算法并不会从归一化中获益,也不会受到归一化的不良影响。
问题的正确归一化
有时正确的归一化并不源自一般的数据或计算考量,而是来自领域知识。例如,在根据温度对一些物理系统进行建模时,引入开氏温标无疑是大有裨益的,它能够使数据间的关系简单化。在数据科学中,领域知识总是十分有用的。
日期与时间
下一种常见的数据类型集合是所有不同格式的日期和时间。
这里的问题在于日期时间的格式多种多样。例如,数据可能是带格式的字符串,或是存在于给定的语言或库中的标准化日期类别。在世界上不同的组织和地区之间,其标准与格式可能存在差异。
举个例子,每个欧洲人在处理美国格式的日期时都会炸毛,即10.27.2018。如果DD/MM/YYYY和MM/DD/YYYY格式的日期被作为简单字符串导入同一个数据集,可能很容易导致一些误会或是模型运行不佳。该问题在于数据并不是简单的数值数据。它并不能直接导入机器学习模型。最简单的方法是将该数据拆分为3个整数特征,分别代表日、月和年。但这并不是全部。我们还可以构建一些文化相关的特征。例如,这一天是不是周末或是节假日。其它选项还有特定大事件开始的时间或日期,或者连续活动之间的间隔。此外,时间也一样。它可以用时、分、秒来表示。但是也可以只按秒计时,或是从一个特定的大事件开始计算。例如,实际上大多数软件都以标准时间1970年1月1日00:00:00作为时间的开始,这也可以很好地应用于特征工程中。
示例:修补时间
我们可以拿一个日期起到重要作用的数据集举例。这是一个来自the Blue Book for Bulldozers competition的数据集。
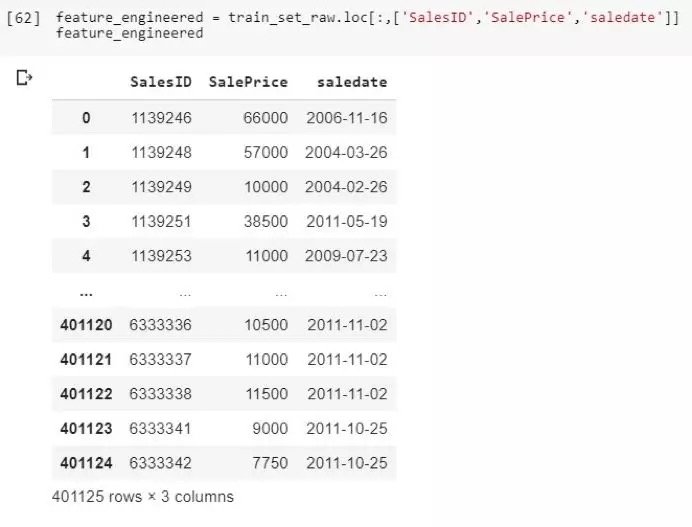
在这里,我们借助Python中的Pandas库载入这个数据集。为了便于说明,我们只取三个特征。SalesID表示交易编号,需要预测的是SalePrice。另外,在该数据集中能够找到售出机器的更多信息和售出日期。我们可以稍稍利用日期。
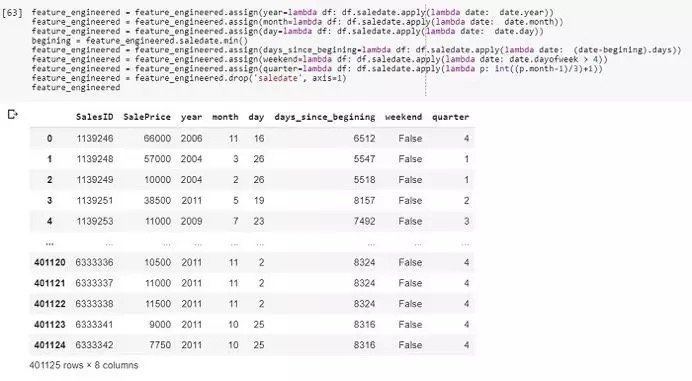
通过几行简单的代码,日期列转换成了6个可被模型读取的特征,可以利用它们来提取更多销售信息。
文本
在计算机中,文本是以数字表示的ASCII代码进行编码的。这听起来可能是个很好处理的东西,但是大错特错!从文本中提取信息需要借助语言结构,也就是单词中字母之间的关系和句子中的单词本身。这跨越了一整个交叉学科领域的分支,叫做自然语言处理(NLP)。许多开发都是为了更轻松地提取这些信息。因为这至少需要另一篇文章或一整本书来阐释,所以在这里不再赘述。
从文本中分类
除了处理整个文本,还可以将其拆分成为单个单词,并尝试查找出现率最高的那一个。举个例子,我们可能有权进入一些人力资源部门的数据库。其中一个字段可能是学术头衔。在这之中可能查找出许多类似于工科学士、理学硕士、哲学博士的字段。但是字段的数量会很庞大。可以从中提取的是例如学士、硕士、博士之类的词语,省略特定的领域。这里包含了一个含有4级(包括不含头衔的)教育水平的分类特征。一个相似的例子是带称谓的全名。在这个字段中会出现像Mr. Alan Turing、Mrs. Ada Lovelace、Miss Skłodowska之类的词组。我们可以提取Mr.、Mrs.、Miss.等表示性别和婚姻状况的称谓。如你所见,利用文本数据的方法很多,并且无需使用NLP昂贵的全部计算性能。
图表
如果不重新撰写一整本专刊,可视化数据是第二种至少需要一篇单独的文章进行讨论的数据。分析这种数据的问题困扰了科学家们数十年之久。一整个计算机视觉领域应运而生。但值得一提的是,由于数年前深度学习革命,一种简单的图像分析方法随之出现。卷积神经网络(CNNs)可以通过使用其中一个通用的框架和显卡强劲的计算性能,为没有太多的计算机视觉(CV)或是特定科目领域知识的用户提供一个合理的解决方案。
如你所见,在创建新的特征方面存在许多可能性。其真实的目的是设计能够促进数据科学过程的特征。但是除了之前提及的方法,还有更多。例如,通过混合连续特征和分类特征来生成新的特征。NLP和CV赋予了我们更多的特征,但这并不是全部。全部掌握它们的唯一方法就是不断地练习与实验。因其巨大的多元性,特征工程常常被称为一门艺术。

Comments