

有經驗的算法工程師肯定非常清楚,在一個模型的開發周期中,占工作量大頭的其實是特徵工程和模型評估及上線的過程。在機器學習平台已經非常成熟的現在,模型結構的實現和調整反而僅僅是幾行代碼的事情。所以如果能夠將模型評估和線上AB Test的效率提高,那一定是大大解放算法工程師效率的事情。
今天這篇文章我們就介紹一下流媒體巨頭Netflix的「獨門線上評估秘笈」——Interleaving。
眾所周知,Netflix是美國的流媒體巨頭,其廣為人知的原因不僅是因為其多部知名的原創劇,高昂的市值,在推薦技術領域,Netflix也一直走在業界的最前沿。那麼驅動Netflix實現推薦系統快速迭代創新的重要技術,就是我們今天要介紹的快速線上評估方法——Interleaving。

Netflix推薦系統問題背景
Netflix幾乎所有頁面都是推薦算法驅動的,每種算法針對不同的推薦場景進行優化。
如下圖所示,主頁上的「Top Picks行」根據視頻的個性化排名提供推薦,而「Trending Now行」包含了最近的流行趨勢。這些個性化的行共同構成了Netflix將近1億會員「千人千面「的個性化主頁。

對於強算法驅動的Netflix來說,算法的迭代創新當然是必不可少的。為了通過算法最大化Netflix的商業目標(這些商業指標包括每月用戶訂閱數、觀看總時長等等),需要進行大量的AB Test來驗證新算法能否有效提升這些關鍵的產品指標。
這就帶來一個矛盾,就是算法工程師們日益增長的AB Test需求和線上AB Test資源嚴重不足之間的矛盾。
因為線上AB Test必然要佔用寶貴的線上流量資源,還有可能會對用戶體驗造成損害,但線上流量資源顯然是有限的,而且只有小部分能夠用於AB Test;而算法研發這側,算法驅動的使用場景不斷增加,大量候選算法需要逐一進行AB Test。這二者之間的矛盾必然愈演愈烈。這就迫切需要設計一個快速的線上評估方法。
為此,Netflix設計了一個兩階段的線上測試過程:
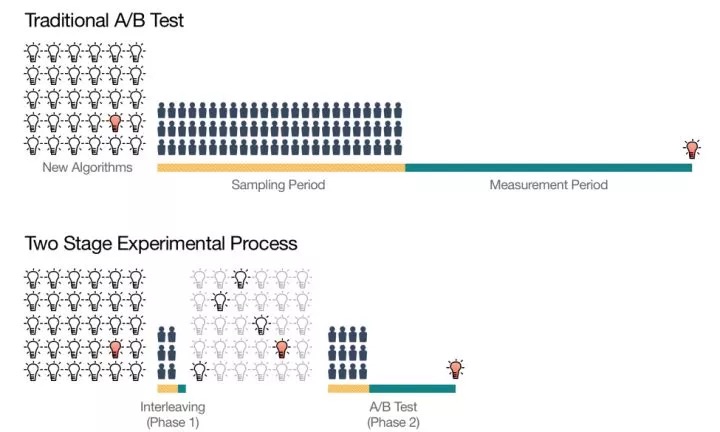
1. 第一階段利用被稱為Interleaving的測試方法進行候選算法的快速篩選,從大量初始想法中篩選出少量「優秀的」Ranking算法。
2. 第二階段是對縮小的算法集合進行傳統的AB Test,以測量它們對用戶行為的長期影響。
大家一定已經對傳統的AB Test方法駕輕就熟,所以這篇文章專註於介紹Netflix是怎樣通過Interleaving方法進行線上快速測試的。
傳統AB Test存在的問題
傳統的AB Test除了存在效率問題,還存在一些統計學上的顯著性差異問題。下面用一個很典型的AB Test問題來進行說明。
這裡設計一個AB Test來驗證用戶群體是否對「可口可樂」和「百事可樂」存在口味傾向。那麼按照傳統的做法,我們會將測試人群隨機分成兩組然後進行「盲測」,即在不告知可樂品牌的情況下進行測試。第一組只提供可口可樂,第二組只提供百事可樂,然後根據大家一定時間內的可樂消耗量來觀察人們是更喜歡「可口可樂」還是「百事可樂」。

這個實驗一般意義上確實是有效的,很多時候我們也是這麼做的。但也確實存在一些潛在的問題:
1. 總的測試人群中,對於可樂的消費習慣肯定各不相同,從幾乎不喝可樂到每天喝大量可樂的人都有。
2. 可樂的重消費人群肯定只佔總測試人群的一小部分,但他們可能佔整體汽水消費的較大比例。
這兩個問題導致——即使AB兩組之間重度可樂消費者的微小不平衡也可能對結論產生不成比例的影響。
在互聯網場景下,這樣的問題同樣存在。比如Netflix場景下,非常活躍用戶的數量是少數,但其貢獻的觀看時長卻占較大的比例,因此Netflix AB Test中活躍用戶被分在A組的多還是被分在B組的多,將對結果產生較大影響,從而掩蓋模型的真實效果。
那麼如何解決這個問題呢?一個方法是不對測試人群進行分組,而是讓所有測試者都可以自由選擇百事可樂和可口可樂(測試過程中仍沒有品牌標籤,但能區分是兩種不同的可樂)。在實驗結束時,統計每個人可口可樂和百事可樂的消費比例,然後進行平均後得到整體的消費比例。
這個測試方案的優點在於:
1. 消除了AB組測試者自身屬性分佈不均的問題;
2. 通過給予每個人相同的權重,降低了重度消費者對結果的過多影響。
這個測試思路應用於Netflix的場景,就是Interleaving。
Netflix的快速線上評估方法——Interleaving
AB Test和Interleaving之間存在如下差異。
- 在傳統的AB Test中,Netflix會選擇兩組訂閱用戶:一組接受Ranking算法A的推薦結果,另一組接受Ranking算法B的推薦結果。
- 在Interleaving測試中,只有一組訂閱用戶,這些訂閱用戶會接受到通過混合算法A和B的排名生成的交替排名。
這就使得用戶同時可以在一行里同時看到算法A和B的推薦結果(用戶無法區分一個item是由算法A推薦的還是算法B推薦的),進而可以通過計算觀看時長等指標來衡量到底是算法A好還是算法B好。

當然,在用Interleaving方法進行測試的時候,必須要考慮位置偏差的存在,避免來自算法A的視頻總排在第一位。因此需要以相等的概率讓算法A和算法B交替領先。這類似於在野球場打球時,兩個隊長先通過扔硬幣的方式決定誰先選人,然後在交替選隊員的過程。

在清楚了Interleaving方法之後,還需要驗證這個評估方法到底能不能替代傳統的AB Test,會不會得出錯誤的結論。Netflix從兩個方面進行了驗證,一是Interleaving的「靈敏度」,二是Interleaving的「正確性」。
Interleaving與傳統AB Test的靈敏度比較
Netflix的這組實驗希望驗證的是Interleaving方法相比傳統AB Test,需要多少樣本就能夠驗證出算法A和算法B的優劣。我們之前一再強調線上測試資源的緊張,因此這裡自然希望Interleaving能夠利用較少的線上資源,較少的測試用戶就解決評估問題。這就是所謂的「靈敏度比較」。
圖5是實驗結果,橫軸是參與實驗的樣本數量,縱軸Netflix沒有給出非常精準的解釋,但我們可以理解為是判定算法A是否比算法B好的「錯誤」概率。可以看出的是interleaving的方法利用10^3個樣本就能夠判定算法A是否比B好,而AB test則需要10^5個樣本才能夠將錯誤率降到5%以下。這就意味着利用一組AB Test的資源,我們可以做100組Interleaving實驗。這無疑大大加強了線上測試的能力。

Interleaving指標與AB Test指標的相關性
除了能夠利用小樣本快速進行算法評估外,Interleaving的判斷結果是否與AB Test一致,也是檢驗Interleaving能否在線上評估第一階段取代AB Test的關鍵。
圖6顯示了Interleaving中的實驗指標與AB Test指標之間的相關性。每個數據點代表一個Ranking算法。我們發現Interleaving指標與AB Test評估指標之間存在非常強的相關性,這就驗證了在Interleaving實驗中勝出的算法也極有可能在之後的AB Test中勝出。

結論
通過實驗我們已經知道Interleaving是一種強大快捷的算法驗證方法,它加速了Netflix各類Ranking算法的迭代創新。
但我們也要清楚的是Interleaving方法也存在一定的局限性,主要是下面兩點:
1. 工程實現的框架較傳統AB Test複雜。由於Interleaving實驗的邏輯和業務邏輯糾纏在一起,因此業務邏輯可能會被干擾。而且為了實現Interleaving,需要將大量輔助性的數據標示添加到整個數據pipeline中,這都是工程實現的難點;
2. Interleaving畢竟只是對用戶對算法推薦結果偏好程度的相對測量,不能得出一個算法完整的表現。比如我們想知道算法A能夠將用戶整體的觀看時長提高多少,使用Interleaving是無法得出這樣的結論的。為此Netflix才設計了Interleaving+AB Test兩級實驗結構,完善整個線上測試的框架。
本文轉自公眾號 將門創投,原文地址

Comments