


在大多數NLP研究人員看來,2018年是技術進步的一年,新的預訓練 NLP模型打破了從情緒分析到問答的任務記錄。
但對於其他人來說,2018年是NLP永遠毀掉芝麻街的一年。
首先來到ELMo,然後BERT,現在BigBird坐在頂上GLUE排行榜。我自己的想法已被這種命名慣例所破壞,當我聽到“ 我一直在玩Bert”時,例如,我腦海中浮現的圖像不是我童年時期模糊不均的鳥頭,而是某種東西。像這樣:
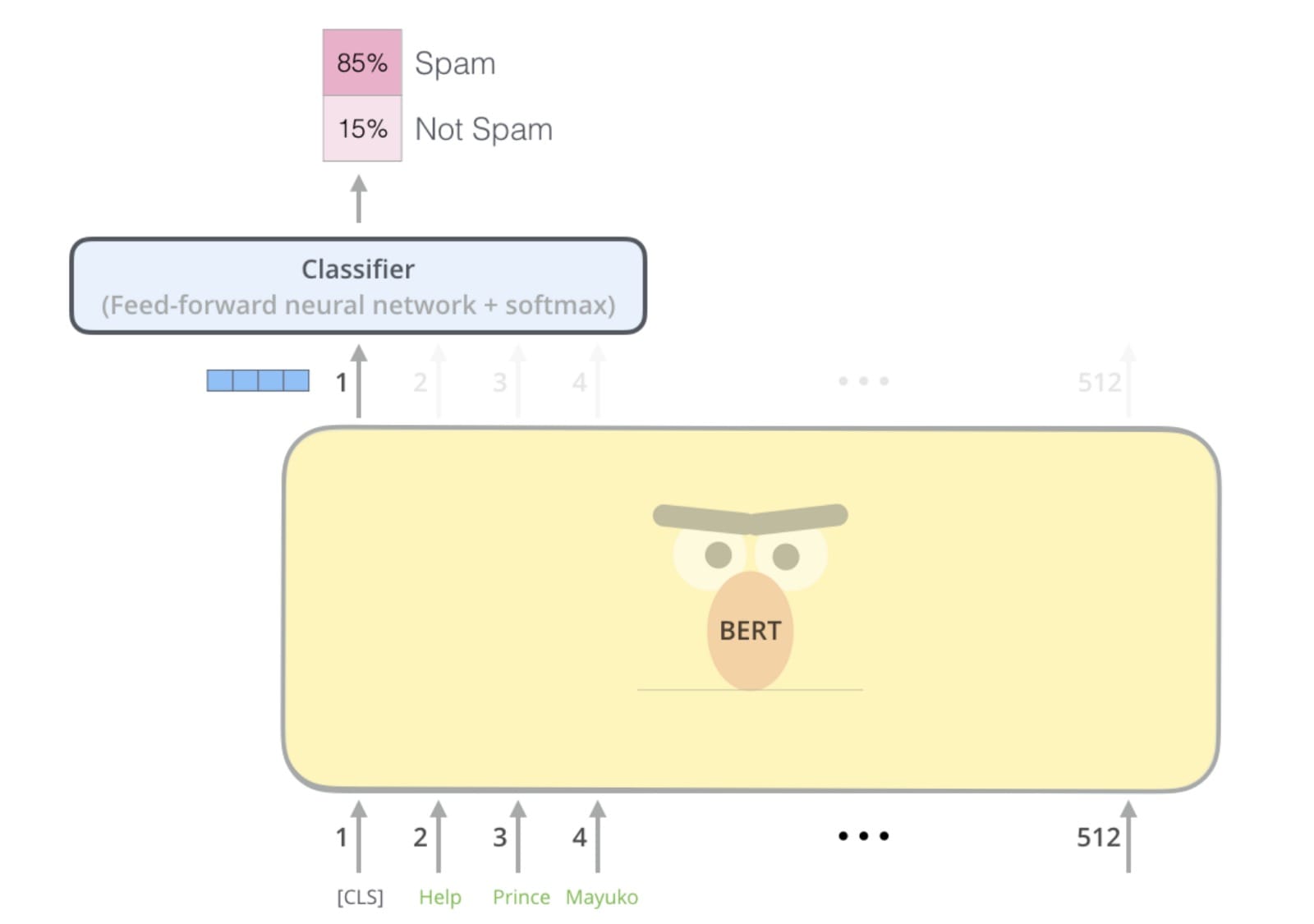
我無法看到那個,插圖BERT!
我問你 – 如果芝麻街對NLP模特品牌不安全,那是什麼?
但有一種模式讓我的童年記憶完好無損,這種算法仍然無名無名,被其作者簡稱為“語言模型”或“我們的方法”。只有當某篇論文的作者需要比較他們的時候這個無名創作的異想天開的模特被認為值得一個綽號。而且它不是搖獎或格羅弗或餅乾怪獸; 這個名字確切地描述了算法是什麼,而不是更多:OpenAI GPT,來自OpenAI的生成預訓練的Transformer。
但與其命名相同,OpenAI GPT被BERT毫不客氣地從GLUE排行榜中淘汰出局。GPT垮台的一個原因是它是使用傳統語言建模預先訓練的,即預測句子中的下一個單詞。相比之下,BERT是預先訓練使用蒙面語言建模,這更是一個填充式的毛坯運動:猜測失蹤(“掩蓋”)字樣因為來之前的話後。這種雙向架構使BERT能夠學習更豐富的表示,並最終在NLP基準測試中表現更好。
因此,在2018年末,似乎OpenAI GPT將永遠為歷史所知,因為它是BERT的通用名稱,古怪單向的前身。
但是2019年卻講了一個不同的故事。事實證明,導致GPT在2018年垮台的單向架構賦予它做BERT從未做過的事情的能力(或者至少不是為此而設計的):寫關於談論獨角獸的故事:

你看,從左到右的語言建模不僅僅是一次預訓練; 它還可以完成一項非常實際的任務:語言生成。如果你可以預測一個句子中的下一個單詞,那麼你可以在那之後預測單詞,然後是下一個單詞,很快就會有很多單詞。如果你的語言建模足夠好,這些單詞將形成有意義的句子,句子將形成連貫的段落,這些段落將形成你想要的任何東西。
而在2019年2月14日,OpenAI的語言模型確實足夠好 – 足以寫出談論獨角獸,生成假新聞和撰寫反回收宣言的故事。它甚至被賦予了一個新名稱:OpenAI GPT-2。
那麼GPT-2的人類寫作能力的秘訣是什麼?沒有基本的算法突破; 這是擴大規模的壯舉。GPT-2擁有驚人的15億個參數(比原來的GPT多15倍),並接受了來自800萬個網站的文本培訓。
如何理解具有15億個參數的模型?讓我們看看可視化是否有幫助。
可視化GPT-2
由於擔心惡意使用,OpenAI沒有發布完整的GPT-2模型,但他們確實發布了與原始GPT(117 M參數)相當的較小版本,並在新的更大的數據集上進行了培訓。雖然沒有大型模型那麼強大,但較小的版本仍然有一些語言生成排序。讓我們看看可視化是否可以幫助我們更好地理解這個模型。
一個說明性的例子
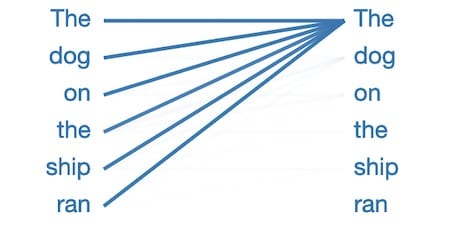
讓我們看看GPT-2小型模型如何完成這句話:船上的狗跑了

這是模型生成的內容:船上的狗跑了,船上
發現了狗。
看起來很合理,對吧?現在讓我們通過將狗更改為電機來略微調整示例,並查看模型生成的內容:船上的馬達跑了
現在完成的句子:船上的電動機
以每小時約100英里的速度運轉。
通過在句子開頭改變那個單詞,我們得到了完全不同的結果。該模型似乎明白,跑狗的類型與電機的類型完全不同。
如何GPT-2知道要這樣的密切關注做 g與電動機,特別是因為這句話早在句子中出現?好吧,GPT-2基於變形金剛,它是一個注意模型 – 它學會將注意力集中在與手頭任務最相關的前幾個詞上:預測句子中的下一個單詞。
讓我們看看GPT-2關注的焦點是“ 船上的狗跑 ”:

從左到右閱讀的線條在猜測句子中的下一個單詞時顯示模型注意的位置(顏色強度代表注意力)。因此,當在跑完後猜測下一個單詞時,模型會密切關注這種情況下的狗。這是有道理的,因為知道誰在做什麼或正在做什麼對於猜測接下來會發生什麼是至關重要的。
在語言學術語中,該模型側重於船上名詞短語“狗”的頭部。有跡象表明,GPT-2捕獲為好,因為上述關注圖案僅僅是許多其他的語言屬性一個所述的144個關注圖案在模型中。GPT-2有12層變壓器,每層都有12個獨立的注意機制,稱為“頭部”; 結果是12 x 12 = 144個不同的注意模式。在這裡,我們可視化所有144個,突出顯示我們剛剛看到的那個:
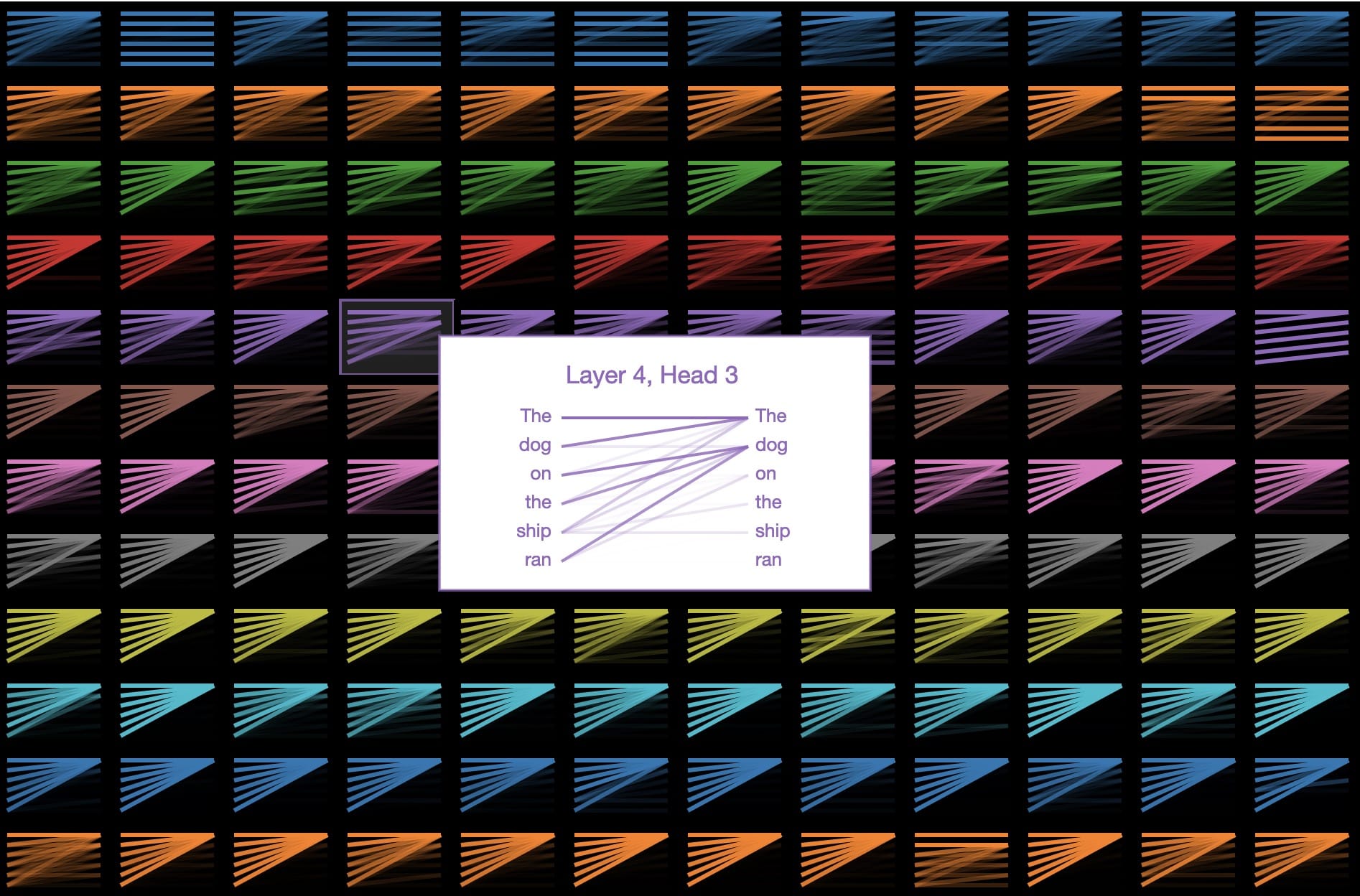
我們可以看到這些模式有許多不同的形式。這是另一個有趣的:

該層/頭將所有注意力集中在句子中的前一個單詞上。這是有道理的,因為相鄰單詞通常與預測下一個單詞最相關。傳統的n -gram語言模型基於同樣的直覺。
但為什麼這麼多注意力模式看起來像這樣呢?
在這種模式中,幾乎所有注意力都集中在句子中的第一個單詞上,而其他單詞則被忽略。這似乎是空模式,表明注意頭沒有找到它正在尋找的任何語言現象。該模型似乎已經將第一個單詞重新定位為當它沒有更好的關注點時可以看的地方。
_____中的貓

好吧,如果我們要讓NLP玷污我們對芝麻街的記憶,那麼我猜Seuss博士也是公平的遊戲。讓我們來看看GPT-2如何從經典的經典帽子Cat中完成這些系列:在一根風箏線上,我們看到了母親的新禮服!她的禮服有粉紅色,白色和……
以下是GPT-2完成最後一句話的方式:她的禮服有粉紅色,白色和
藍色的點。
還不錯!原文有紅色,所以至少我們知道這不僅僅是記憶。
那麼GPT-2如何知道選擇顏色?也許是由於以下注意模式似乎識別逗號分隔列表:
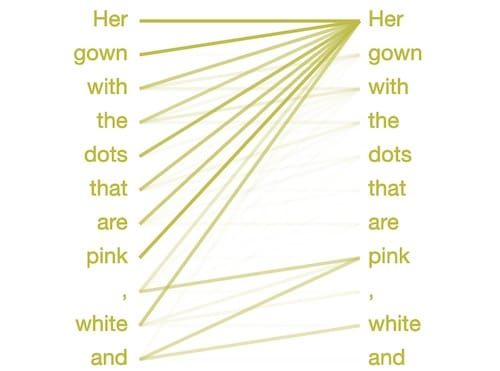
為了決定單詞之後和,模型將注意力集中在列表中的前面的項目 - 粉紅色和白色。它知道選擇一個與之前項目類型匹配的單詞,在這種情況下是一種顏色。
什麼名字?
GPT-2似乎特別擅長僅根據名字撰寫簡短的傳記。

作為一個有趣的練習,嘗試讓GPT-2從提示“誰是<你的名字>?”生成文本。這個特殊的提示通常會觸發模型寫一個簡短的傳記,可能因為它是作者生物的一個共同前言網絡。
這裡有一些為提示“Who is Jesse Vig?”而生成的bios:
“Jesse Vig是一位社交媒體營銷專家和前社交媒體營銷經理。他是VigMedia.com的聯合創始人兼首席執行官,最近是VigMedia.com的創始人兼首席執行官。“
不錯!有點重複,但是以一種意想不到的方式很好地個性化故事。這是另一個:
“傑西維格是福音派傳教士詹姆斯維格的兒子。他於1964年移居美國,並成為密歇根大學的傳教士,在那裡他教了18年,直到2007年10月去世。“
在最後一個例子中,GPT-2非常聰明,知道我的另一個自我的父親有相同的姓氏。讓我們看看GPT-2在選擇這個姓氏時的注意力集中在哪裡:

當決定在詹姆斯之後預測這個詞時,這種模式將注意力集中在我之前提到的姓氏上。(注意,在模型內部,Vig已被分成單詞“ V”和“ ig”,因為它是一個不常見的單詞。)似乎這種注意模式專門用於識別家族名稱之間的關係。為了測試這個,讓我們稍微改變一下文字:
“傑西維格是一位名叫詹姆斯的福音派傳教士的同事 ……”

既然詹姆斯只是一個同事,這種注意模式幾乎完全忽略了我的姓氏。
注意: GPT-2似乎根據與名稱相關的感知種族和性別生成傳記。需要進一步研究以了解模型可能編碼的偏差; 你可以閱讀更多關於這個話題在這裡。
未來是生成性的
就在去年,生成各種圖像,視頻,音頻和文本內容的能力已經提高到我們無法再相信自己的感官和對真實或虛假的判斷的程度。
而這僅僅是個開始; 這些技術將繼續發展並相互融合。很快,當我們盯着thispersondoesnotexist.com上生成的面孔時,他們會滿足我們的目光,他們將與我們談論他們的生活,揭示他們產生的個性的怪癖。
最直接的危險可能是真實與生成的混合。我們已經看過奧巴馬作為AI傀儡和Steve Buscemi-Jennifer Lawrence chimera的視頻。很快,這些深水將成為個人。因此,當你的媽媽打電話說她需要500美元連線到開曼群島時,問問自己:這真的是我的媽媽,還是一個語言生成的AI,從她5年前發布的Facebook視頻中獲得了母親的聲音皮膚?
但就目前而言,讓我們盡情享受談論獨角獸的故事。
資源:
用於創建上述可視化的Colab筆記本
用於可視化工具的GitHub repo,使用這些令人敬畏的工具/框架構建:
本文轉自《Towards Data Science》。原文地址(需要科學上網)

Comments