

本文轉載自公眾號 將門創投,原文地址
當我們在探究人工智能和機器學習背後的概念和算法時會接觸到一系列與這一領域相關的專業術語和核心概念。理解這些術語和概念有助於我們更好的把握這裡領域的發展,並理解數據科學家和AI研究人員們是如何引領時代發展的。
在這篇文章中,我們將幫助你更好的理解監督學習、非監督學習和強化學習的定義的內涵,並從更廣闊的視角中闡述它們與機器學習之間的聯繫。深入理解它們的內涵不僅有助於你在這一領域的文獻中盡情的徜徉,更能引導你敏銳地捕捉到AI領域的發展和技術進步的氣息。
監督學習、非監督學習和強化學習描述了機器處理和利用數據學習的三種不同手段,根據不同的數據和任務人們採用不同的學習方式來從數據中凝練出知識,從而在生產生活中幫助人類。
監督學習
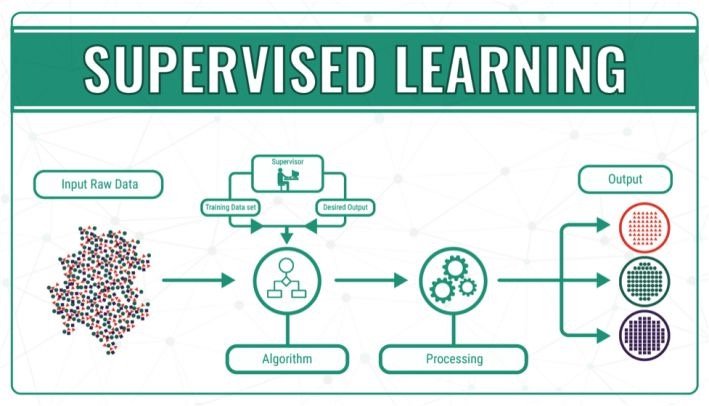
為了讓更多的朋友理解機器學習的核心概念,我們首先給出簡明監督學習簡明扼要的定義:在知道輸入和輸出的情況下訓練出一個模型,將輸入映射到輸出。我們在開始訓練之前就已經知道了輸入和輸入,我們的任務時建立起一個將輸入準確映射到輸出的模型,當給模型輸入新的值時就能預測出對應的輸出了。
在這一過程中機器不斷的通過訓練輸入來指導算法不斷改進。如果輸出的結果不正確,那麼這個錯誤結果與期望正確結果之間的誤差將作為糾正信號傳回到模型,糾正模型的改進。在深度學習中著名的反向傳播算法根本上也是將誤差向後傳播來指導模型改進的。
目前監督學習佔據了機器學習算法的絕大部分,通過算法將輸入變量x和輸出變量y銜接起來創造了很多具有深遠影響的應用。要理解監督學習我們需要把握住以下幾點,在監督學習中所有的算法、輸入、輸出以及場景都是人類提供的。將監督學習問題分為兩類將更好地幫助我們理解監督學習地含義。
分類:分類問題的目標是通過輸入變量預測出這一樣本所屬的類別,例如對於植物品種、客戶年齡和偏好的預測問題都可以被歸結為分類問題。這一領域中使用最多的模型便是支持向量機,用於生成線性分類的決策邊界。隨着深度學習的發展,很多基於圖像信號的分類問題越來越多的使用卷積神經網絡來完成。
回歸:主要用於預測某一變量的實數取值,其輸出的不是分類結果而是一個實際的值。最常見的例子便是市場價格預測,降水量預測等問題。人們主要通過線性回歸、多項式回歸以及核方法等來構建回歸模型。
非監督學習
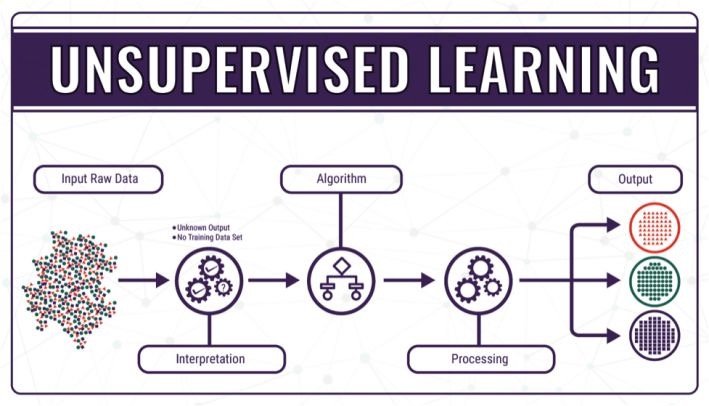
在了解了監督學習後我們再來看看非監督學習法,這種方法的使用不如監督學習廣泛,目前的實際應用也不如監督學習那般普遍。但這種獨特的方法論為機器學習未來的發展方向給出了很多啟發和可能性。也許非監督學習可以讓我們從「教會機器去做什麼」發展到讓機器「自己學會去做什麼」。
與監督學習不同,非監督學習並不需要完整的輸入輸出數據集,並且系統的輸出經常是不確定的。它主要被用於探索數據中隱含的模式和分佈。非監督學習具有解讀數據並從中尋求解決方案的能力,通過將數據和算法輸入到機器中將能發現一些用其他方法無法見到的模式和信息。
讓我們用一個簡單的例子來理解非監督學習。設想我們有一批照片其中包含着不同顏色的幾何形狀。在這裡計算機面對的是沒有任何標記的圖片,它並不知道幾何形狀的顏色和外形,它看到的只是一張張照片而已。但通過將數據輸入到非監督學習的模型中去,算法可以嘗試着理解圖中的內容,通過相關性和特徵將圖中的相似的物體聚為一類。在理想的情況下它可以將不同形狀不同顏色的幾何形狀聚集到不同的類別中去,特徵提取和標籤都是機器自己完成的。
但就像人類學習一樣,機器也會犯錯。而機器的能力可以通過識別錯誤、並從錯誤中學習而不斷提高改善。
強化學習

強化學習是機器學習的重要部分,在為機器學習開拓新方向上做出了巨大的貢獻。強化學習突破了非監督學習,為機器和軟件如何獲取最優化的結果給出了一種全新的思路。它將如何最優化主體的表現和如何優化這一能力之間建立起了強有力的鏈接。通過獎勵函數的反饋來幫助機器改進自身的行為和算法。
但強化學習在實踐中並不簡單,人們利用很多種算法來實現強化學習。簡單來說,強化學習需要指導機器做出在當前狀態下能獲取最好結果的行為。
強化學習中主體通過行為與環境相互作用,而環境通過獎勵函數來幫助算法調整做出行為決策的策略函數。從而在不斷的循環中得到表現優異的行為策略。它十分適合用於訓練控制算法和遊戲AI等場景。
最後在了解和這三者的概念後讓我們來討論監督學習、非監督學習和強化學習的異同點:
1. 監督學習 v.s 強化學習
在監督學習中對應的輸入輸出數據扮演了監督的角色,將其中蘊含的知識通過訓練賦予模型,模型通過數據的糾正信號不斷學習最終形成能較好理解數據並準確預測的算法。而在強化學習中監督數據並不是必須的,主體可以通過與環境相互作用嘗試很多方法和表現並調節。我們可以想像圍棋的例子,在最終勝負揭曉之前我們需要執行很多次操作,每一次操作都有很多種可能,為這一任務建立監督學習的知識是十分複雜的工作。而電腦則可以根據與環境相互作用後收到的反饋建立起自己對於棋局的理解。
當機器開始學習後她便可以不斷地充實自己的經驗並改善表現。這也許是與監督學習最大的不同了。雖然兩種模型都建立了某種輸入到輸出的映射關係,但強化學習卻是通過獎勵函數來幫助系統不斷改進模型的。
2.強化學習 v.s 非監督學習
強化學習根本上來說是通過映射結構來對輸入和輸入進行銜接,但非監督學習則在輸入和輸出之間沒有任何的鏈接。在非監督學習中,機器的主要任務是對數據種的模式進行識別而不是建立映射關係。如果我們想要建立一個用戶新聞推薦系統,強化學習可以通過用戶的使用反饋不斷改進,並建立起用戶喜歡的新聞類型圖譜實現更精準的推薦。而對於非監督學習來說,則能從用戶讀過的文章種總結出用戶的喜好,並為用戶推薦合適的主題。

2 Comments
懂了
nice