

本文轉載自公眾號 AI科技評論,原文地址
日前,Josh Gordon 在 TensorFlow 官網上發佈了一篇博客,詳細介紹了符號式 API(symbolic API)和命令式 API(imperative API),並詳細介紹了兩種樣式各自的優點和局限性,以及各自適用於哪些場景。 AI 科技評論編譯如下。
TensorFlow 2.0 中,我最喜歡的一點就是它提供了多個抽象化(abstraction)級別,讓你可以根據自己的項目,挑選出最適合的級別。本文中,我將解讀如何權衡創建神經網絡的兩種樣式:
- 第一種是符號式(symbolic),即你通過操作層次圖來創建模型;
- 第二種是一種命令式(imperative),即你通過擴展類來創建模型。
除了介紹這兩種樣式,我還會分享關於重要設計和適用性方面需要注意的事項,並在文章最後給大家提供一些有助於選擇正確樣式的建議。
符號式(Symbolic)API
符號式 API,也稱作聲明式(Declarative) API。
當我們想到一個神經網絡時,我們通常會將心智模型(mental model)用如下圖所示的「層次圖」來表示:
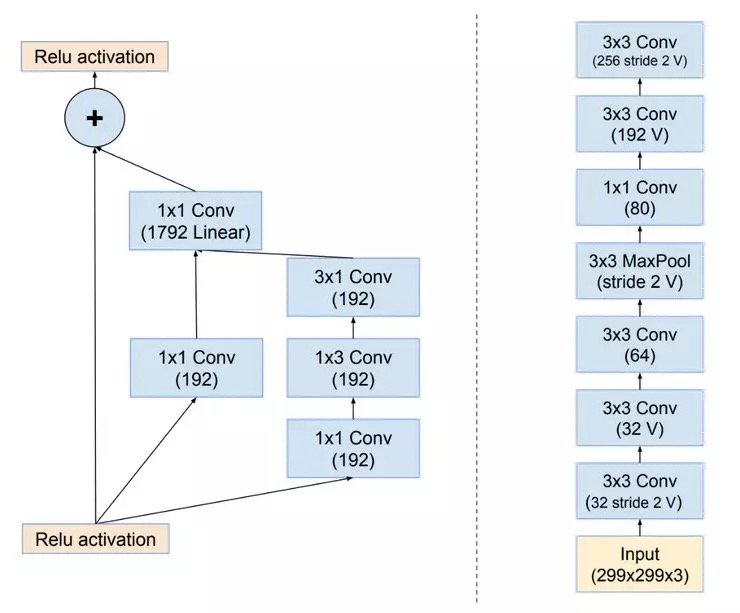
該圖可以是有向無環圖(DAG),如左邊所示;也可以是堆棧圖(stack),如右邊所示。當我們用符號來創建模型,我們通過對該圖的架構進行描述來創建。雖然這個操作聽起來帶有技術性,但是如果你曾經使用過 Keras 的話,就會驚訝地發現你已經擁有了相關的經驗。這裡有一個關於用符號來創建模型的簡單示例,這個示例中使用的是 Keras 的 Sequential API。
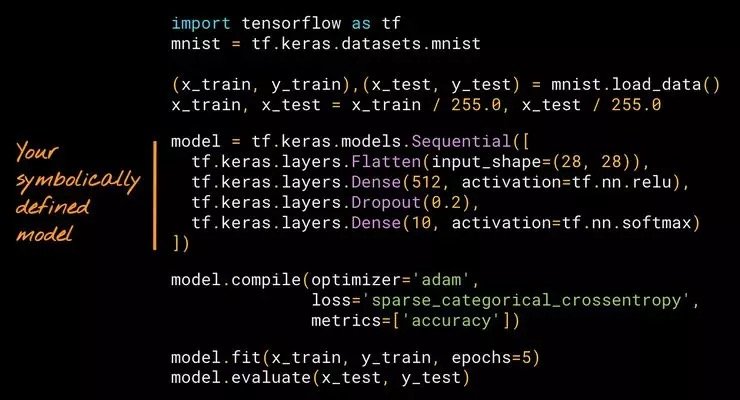
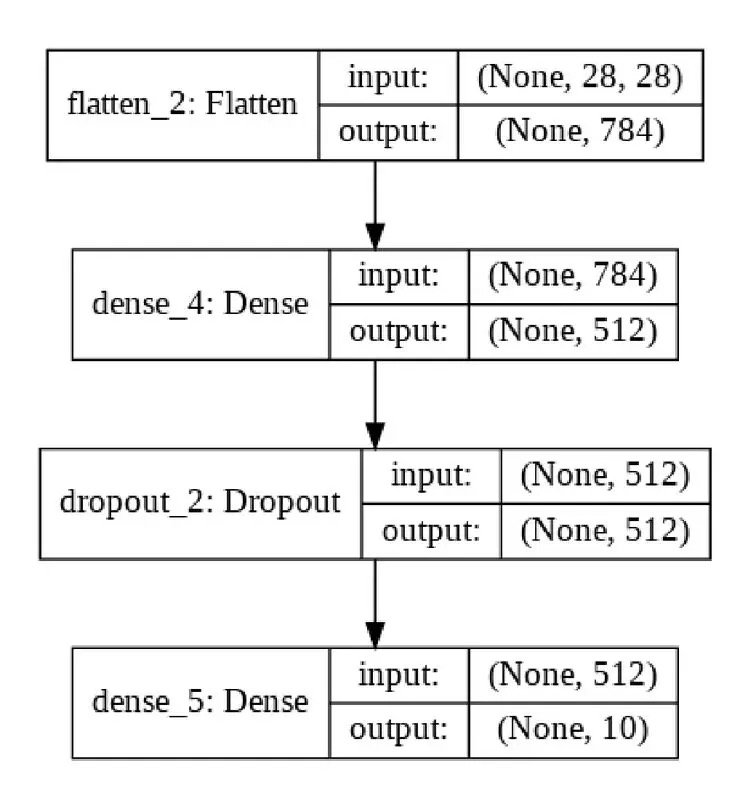
在上面這個示例中,我們定義了一個堆棧(a stack of layers),然後使用內置的訓練循環(training loop)——model.fit 來對它進行訓練。
使用 Keras 創建模型感覺與「把樂高積木拼裝在一起」一樣簡單。為什麼這麼說?除了匹配心智模型,針對後面將介紹到的技術原因,由於框架能夠提供詳細錯誤,使用這種方法來創建模型能夠輕易地排除故障。
TensorFlow 2.0 還提供了另一個符號式 API :Keras Functional。Sequential 是針對堆棧圖的 API;而 Functional,如你所想,是針對 DAG 的 API。
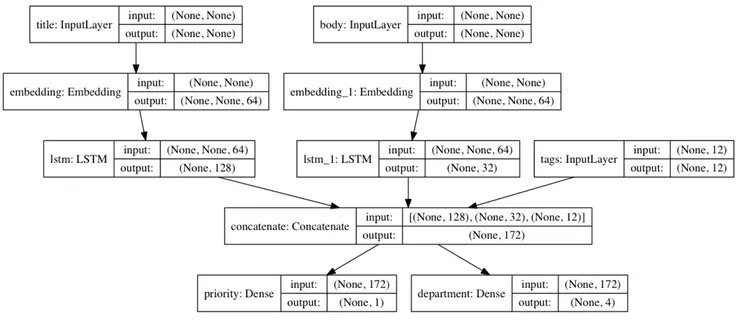
Functional API 是一種創建更靈活的模型的方法,可以操作非線性拓撲、共享層的模型以及有多個輸入或輸出的模型。一般來說,Functional API 是一個用來創建這些層次圖的工具集,我們現在也正在為大家準備一些新教程,來教大家使用這些 API。
另外也有一些其他的符號式 API,這些 API 你們可能也使用過。例如,TensorFlow v1 (及 Theano) 提供了一個層級更低得多的 API。當進行編譯並執行時,你可以通過設計一個 ops 圖來創建模型。有時候,使用這種 API 可能會讓你感覺像是在與一個編譯器進行直接的互動。對於很多人(包括作者)來說,該 API 是比較難使用的。
相比之下,使用 Keras 的 Functional API,抽象化級別可以匹配心智模型:像樂高拼圖一樣將層次圖拼接起來。這種 API 使用起來感覺會比較自然,它也是我們在 TensorFlow 2.0 中進行標準化的模型創建方法之一。接下來我將介紹另一種 API 樣式(同時,這種樣式你也可能使用過,或者你可能不久後會嘗試這種 API)。
命令式(Imperative)API
命令式 API,也稱作模型子類化(Model Subclassing) API。
在命令式 API 中,你要像編寫 NumPy 一樣編寫模型。用這種 API 創建模型感覺像是在開發面向對象的 Python。這裡有一個關於子類化模型的簡單示例:

使用命令式 API 為一個有文字說明的圖片創建模型(注意:該示例目前正在更新)。
從一個開發者的角度,它工作的方法就是擴展由框架定義的模型類別,將模型中的層實例化,然後命令式地編寫下模型的正向傳遞(forward pass),而反向傳遞(backward pass)是自動生成的。
TensorFlow 2.0 支持使用現成的 Keras 的子類化 API 來創建模型。與 Sequential API 和 Functional API 一樣,它也是使用 TensorFlow 2.0 創建模型時推薦使用的方法之一。
雖然這種方法在 TensorFlow 來說還比較新,但是你會驚訝地發現早在 2015 年 Chainer 就對它進行了介紹(時光飛逝!)自那以後,許多框架都採用了相似的方法,包括 Gluon、PyTorch 和 TensorFlow (以及 Keras Subclassing)。令人驚訝地是,在不同的框架中使用這種樣式所編寫的代碼看上去非常相似,研究者可能都難以分清哪些代碼是哪個框架的!
這種樣式能給開發人員帶來巨大的靈活性,不過也會帶來一些不明顯的適用性和維護成本。稍後我們會更詳細地討論這一點。
訓練循環(Training Loop)
自定義的模型無論是使用 Sequential API、Functional API 還是使用子類化樣式,都可以用兩種方式進行訓練:
- 一種是使用內建的訓練路徑和損失函數(第一個示例講到的,我們使用的是 model.fit 和 model.compile);
- 另一種是定製更複雜的訓練循環(例如,當你想要自行編寫梯度裁剪代碼時)或損失函數,你可以按照以下方法輕易實現:
將這些方法對外開放是非常重要的,使用它們來降低代碼複雜性以及維護成本都非常方便。一般而言,如果增加複雜度是有幫助的,那你就增加並將其利用起來;沒必要的話,就直接使用內建的方法,將你的時間更多地花在你的研究或者項目上。
既然我們已經對符號式 API 和命令式 API 都建立起了認知,接下來就讓我們看一下兩者各自的優劣勢。
符號式 API 的優勢和局限性
優勢
使用符號式 API 創建的模型,就是一個類似圖形的數據架構,這就意味着你的模型可以接受監測或者進行匯總。
- 你可以將模型當成圖像來為其繪製圖表(使用 keras.utils.plot_model);或者簡單地使用 model.summary() 來呈現層、權重以及形狀的描述。
同樣地,在將層拼接在一起時,開發庫的設計者可以運行擴展的層兼容性檢查(在創建模型時和執行模型之前)。
- 這類似於在編譯器中進行類型檢查,可以極大地減少開發者的錯誤。
- 大多數的故障排除都會在模型自定義階段而不是執行期間進行。你可以保障所有編譯的模型都能正常運行,這也加速了迭代,並讓故障排除變得更簡單。
符號式模型提供了一個一致的 API,這就使得這些模型的重複使用和共享變得簡單。例如,在遷移學習中,你可以訪問中間層的神經元,從而從現有的神經元中創建新的模型,就像這樣:

符號式模型由可自然地進行複製和克隆的數據架構進行定義。
- 例如,Sequential API 和 Functional API 可以提供 model.get_config(),model.to_json(),model.save(),clone_model(model),同時僅憑藉數據架構就能夠重新創建同樣地模型(而不需要訪問用來定義和訓練模型的原始代碼)。
雖然精心設計的 API 應該跟神經網絡的心智模型匹配,但是跟我們作為一個程序員所有的心智模型進行匹配也同樣重要。對於我們大多數程序員來說,這種心智模型就是命令式的編程樣式。在符號式 API 中,你操作「聲明式的張量」(這些張量是沒有值的)來創建圖表。Keras 的 Sequential API 和 Functional API「感覺像」命令性的,它們是在開發者沒有意識到他們在用符號定義模型的情況下被設計出來的。
局限性
符號式 API 的當前一代,可以很好地適用於有向無環圖的模型創建,這可以滿足絕大多數實際應用的需要,然而現在也有一些特例無法匹配這個簡潔的抽象化,例如,樹形循環神經網絡和遞歸神經網絡等動態網絡。
這也是為什麼 TensorFlow 要同時還提供命令式的模型創建 API 樣式(上文中提到的子類化 API)。無論是使用 Sequential API 還是 Functional API,你都會用到所有熟悉的層、初始化器以及優化器。同時,這兩類 API 是完全互操作的,因此你可以混合併且搭配兩者使用(例如將一種模型嵌套到另一種模型中)。你可以採用一個符號式模型並在子類化模型中將它用作層,反之亦然。
命令式 API 的優勢和局限性
優勢
正向傳遞(forward pass)以命令式的方法編寫,這就使得用自己的實現來替換掉通過開發庫實現的部分(例如一層、一個神經元後者一個損失函數)變得很容易。這種方式的編程也非常自然,並且是深入了解深度學習的基本要點的不錯的方法。
- 這也讓你快速地嘗試新想法變得很容易(深度學習開發工作流會變得與面向對象的 Python 一樣),同時對於研究人員來說尤其有幫助。
- 也可以很輕易地使用 Python 指定模型正向傳遞中的任意控制流。
命令式 API 給予了你最大的靈活性,但同時也要付出代價。我喜歡用這種樣式來寫代碼,但還是想花點時間來強調一下它的局限性(意識到要對這種方法的優勢和局限性進行權衡是很不錯的)。
局限性
當使用命令式 API 時,模型是由某個類別方法來進行定義的。這樣的話,模型就不再是一個清晰的數據架構,而是一個不透明的位元組碼。這種 API 樣式所獲得的靈活性是以可用性和可重用性換來的。
故障排除發生在執行期間,而不是在定義模型之時。
- 使用這一 API 樣式時,由於幾乎不會對輸入或者層間兼容性進行檢查,因此大量的故障排除壓力就從框架上轉移到了開發者身上。
命令式模型很難進行重複利用。例如你無法使用一個一致的 API 去訪問中間層或神經元。
- 相反地,提取神經元的方法就是採用一種新的調用(或者前進)方法來編寫一個新的類別。最開始的時候可能會覺得這個操作有趣又簡單,但是如果沒有標準的話就會積累成技術債(tech debt)。
命令式模型也很難進行檢測、複製和克隆。
- 例如,model.save(), model.get_config(),以及 clone_model 對於子類化的模型是不起作用的,而 model.summary() 也只能給你層的列表(並且不會提供任何關於它們怎樣進行連接的信息,因為這些信息是訪問不了的)。
機器學習系統中的技術債(Technical debt)
記住:模型創建僅僅是機器學習實際應用中的一個小小的部分。關於這個主題,有一個我非常喜歡的描述:模型本身(指定層、訓練循環等的代碼部分)就是機器學習中央的一個小盒子。
符號式定義的模型在可重用性、故障排除以及測試方面具有優勢,例如,在教授期間,如果學生使用的是 Sequential API,我立刻就能排除故障;如果他們使用的是子類化的模型(不管框架),排除故障需要花費的時間就更長(故障會更不易察覺,類型也更多)。
總結
TensorFlow 2.0 直接支持符號式 API 和命令式 API 兩種樣式,因此大家可以選擇最適合自己項目的抽象化(複雜性)層級。
如果你的目標是易用、低預算,同時你傾向於將模型考慮為層次圖,那就使用 Keras 的 Sequential API 或者 Functional API (就像拼裝樂高積木一樣) 和內建的訓練循環。這種方法適用於大多數問題。
如果你是偏好於將模型考慮成面向對象的 Python/Numpy 開發者,同時有限考慮模型的靈活性和可破解性,Keras 的 Subclassing 這樣的 API 會比較適合你。

Comments