

本文轉載於公眾號 科大訊飛,原文地址
如今,科技已經悄無聲息的滲入我們每個人的生活,有時,你甚至毫無察覺。
比如,撥打10086等服務號,會聽到一個優美的女聲為您引導;
比如,啟用導航軟體,會聽到一個流暢的語音播報路況。
再比如,使用時下流行的打車軟體,有清晰語音為師傅播報乘客的位置。
而這些聲音,其實都不是真的。是研究人員通過語音合成技術,讓機器發出的聲音。並且,經過多年的發展,機器合成的聲音不僅能夠達成普通人說話水平,更能賦予聲音以個性、情感。很多時候,甚至能以假亂真。也許,在不久的將來,各種科幻片動畫片中使用的「變聲器」將不再是傳說。
那麼,現在就讓科大訊飛帶領大家一起來看一看這門神奇的技術是前世、今生。感受語音世界的神奇魅力。
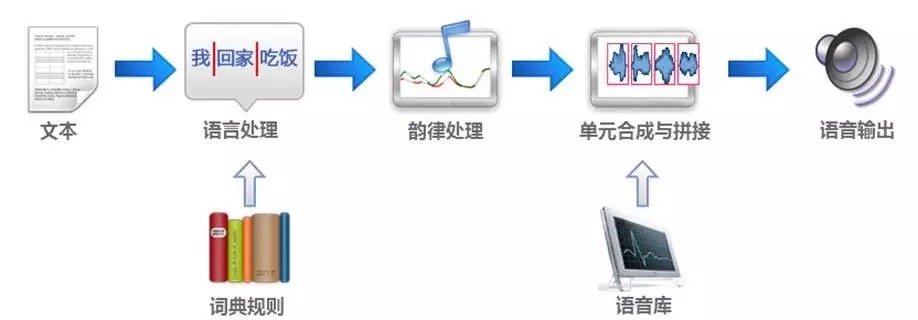
語音合成又稱文語轉換(Text toSpeech,TTS)技術,通過機械的、電子的方法產生人造語音。通俗的講,語音合成技術就是賦予計算機像人一樣可以自如說話的能力。
最早的「語音合成」是利用機械裝置實現的。Kratzenstein在1779年研製出一種機械式語音合成器,用風箱模擬人的肺、簧片模擬聲帶、以皮革製成的共振腔模擬聲道,通過改變共振腔的形狀,可以合成出一些不同的母音。這可謂是人類歷史上最早的合成技術。
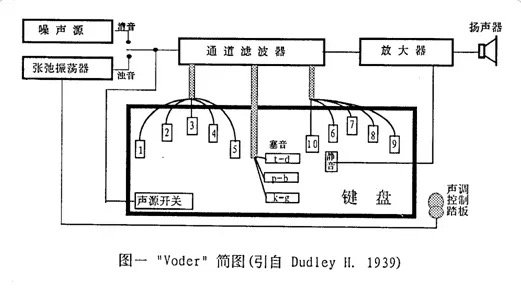
19世紀出現電子器件以來,語音合成技術快速發展。1939年,貝爾實驗室H. Dudley製作出一個電子合成器(Dudley’39)。這是一個利用共振峰原理製作的語音合成器,它以一些白噪音似的激勵產生非濁音信號,以周期性的激勵產生濁音信號。模擬聲道的共振器是通過一個10階的帶通濾波器建模,模型的增益通過人來控制。

此後的一個世紀,語音合成技術不斷取得一個又一個的突破。
1960年,G. Fant系統地闡述了語音產生的理論,極大地推動了語音合成技術的進步。

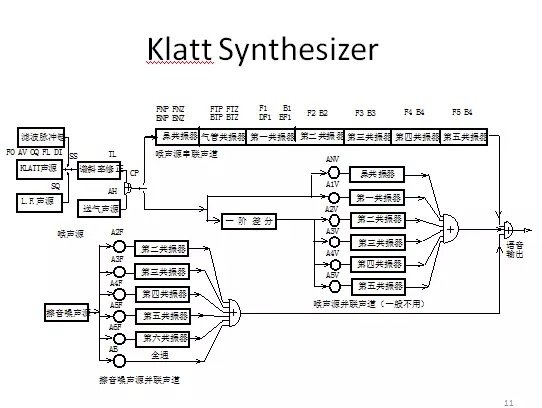
1980年,D. Klatt設計出串/並聯混合型共振峰合成器,可以模擬不同的嗓音。
20世紀80年代末,基音同步疊加的時域波形修改(PSOLA)演算法被提出,較好地解決了語音段之間的拼接問題,有力推動了語音合成技術的發展。
1990年代隨著電子計算機的運算和存儲能力的迅猛發展,基於大語料庫的單元挑選與波形拼接合成方法逐漸成熟並開始商業應用。它的基本思想是從預先錄製和標註好的語音庫中挑選合適的單元,進行少量的調整(或者不進行調整),拼接得到最終的合成語音,其優勢在於保持了高質量的原始聲音。
20世紀末,可訓練的語音合成方法(Trainable TTS)被提出。該方法基於統計建模和機器學習的方法,根據一定的語音數據進行訓練並快速構建合成系統。這種方法可以自動快速的構建合成系統,系統尺寸很小,很適合嵌入式設備上的應用以及多樣化語音合成方面的需求。
21世紀,語音合成技術飛速發展。在聲音合成達到真人說話水平後,學界漸漸把眼光轉向音色合成、情感合成等領域,力求使合成的聲音更加自然,並具備個性化特徵。


1 Comment
哈哈哈,嘿嘿嘿。