

一、語音合成技術簡介
本文轉載於公眾號 AI科技大本營,原文地址
語音,在人類的發展過程中,起到了巨大的作用。語音是語言的外部形式,是最直接地記錄人的思維活動的符號體系,也是人類賴以生存發展和從事各種社會活動最基本、最重要的交流方式之一。而讓機器開口說話,則是人類千百年來的夢想。語音合成(Text To Speech),是人類不斷探索、實現這一夢想的科學實踐,也是受到這一夢想不斷推動、不斷提升的技術領域。
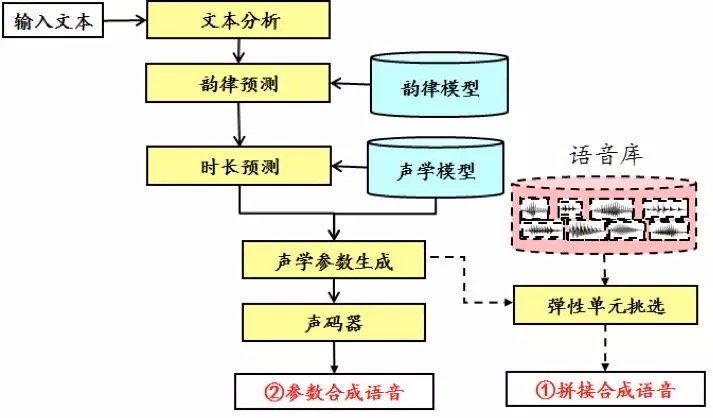
在漫長的探索過程中,真正產生實用意義的合成系統,產生於 20 世紀 70 年代。受益於計算機技術和信號處理技術的發展,第一代參數合成系統–共振峰合成系統誕生了。它利用不同發音的共振峰信息,可以實現可懂的語音合成效果,但整體音質方面,還難以滿足商用的要求。
進入 90 年代,存儲技術得到了長足發展,從而誕生了拼接合成系統。拼接合成系統,利用 PSOLA 演算法,將存儲的原始發音片段進行調整後拼接起來,從而實現了相較於共振峰參數合成效果更好的音質。
之後,語音合成技術不斷向前發展,參數合成、拼接合成兩條主要的技術路線都取得了長足進展,相互競爭、相互促進,使得合成語音的質量大幅提升,語音合成技術在眾多場景中得以應用。整體上看,主要包括如下幾個方面:
從規則驅動轉向數據驅動:在早期的系統中,大多需要大量的專家知識,對發音或者聲學參數進行調整,不但費時費力,而且難以滿足對不同上下文的覆蓋,也在一定程度上影響技術的實施。隨著技術的發展,越來越多的數據得以應用到系統中,以語音合成音庫為例,從最初的幾百句話,發展到後來的幾千、幾萬句規模,使得發音樣本數量大大增加,基於統計模型的技術得以廣泛應用。從最初的樹模型、隱馬爾可夫模型、高斯混合模型,到近幾年的神經網路模型,大大提升了語音合成系統對語音的描述能力。
不斷提升的可懂且舒適的合成效果:語音合成系統的合成效果評價,一般是通過主觀評測實驗,利用多個參試人員對多個語音樣本進行打分。如果語音樣本來自不同的系統,則稱為對比評測。為了提升語音的音質,參數合成系統中先後採用過 LPC 合成器、STRAIGHT 合成器、以 wavenet 為代表的神經網路聲碼器等;拼接合成系統中則採用不斷擴大音庫規模、改善上下文覆蓋的策略,都取得了明顯的效果。在理想情況下,用戶希望語音合成的語音,能夠以假亂真,達到真人發音水平。隨著技術的不斷發展,這一目標已經越來越近。在一種極端情況下,一組樣本來自合成系統,一組樣本來自真人發音,那麼所做的對比評測,即可視為語音合成系統的圖靈測試。如果用戶無法準確分辨哪些語音樣本是機器生成的,哪些是人類產生的,那麼就可以認為這一合成系統通過了圖靈測試。
文本處理能力不斷增強:人類在朗讀文本時,實際上是有一個理解的過程。要想讓機器也能較好地朗讀,這個理解過程必不可少。在語音合成系統中,一般會包括一個文本處理的前端,對輸入文本進行數字、符號的處理,分詞斷句,以及多音字處理等一系列環節。通過利用海量的文本數據和統計模型技術,合成系統中文本處理的水平已經可以滿足大多數場景下的商業應用要求。更進一步地,自然語言理解技術,還可以用於預測句子的焦點、情緒、語氣語調等,但由於這部分受上下文的影響很大,而這類數據又相對較少,所以目前這部分情感相關的技術還不夠成熟。
以上,是語音合成技術的發展概況。接下來,我們來探討一下最近幾年深度學習技術對合成技術發展的影響。
二、深度學習與語音合成
深度學習技術,對語音合成的影響,主要分為兩個階段:
第一階段:錦上添花。從 2012 年開始,深度學習技術在語音領域逐漸開始受到關注並得以應用。這一階段,深度學習技術的主要作用,是替換原有的統計模型,提升模型的刻畫能力。比如用 DNN 替代時長模型,用 RNN 替代聲學參數模型等。語音的生成部分,仍然是利用拼接合成或者聲碼器合成的方式,與此前的系統沒有本質差異。對比兩種系統發現,在仔細對比的情況下,替代後的系統的效果略好於原系統,但整體感覺差異不大,未能產生質的飛躍。
第二階段:另闢蹊徑。這一階段的很多研究工作,都具有開創性,是對語音合成的重大創新。2016 年,一篇具有標誌性的文章發表,提出了 WaveNet 方案。2017 年初,另一篇標誌性的文章發表,提出了端到端的 Tacotron 方案。2018 年初,Tacotron2 將兩者進行了融合,形成了目前語音合成領域的標杆性系統。在此過程中,也有 DeepVoice,SampleRNN, Char2Wav 等很多有價值的研究文獻陸續發表,大大促進了語音合成技術的發展,吸引了越來越多的研究者參與其中。
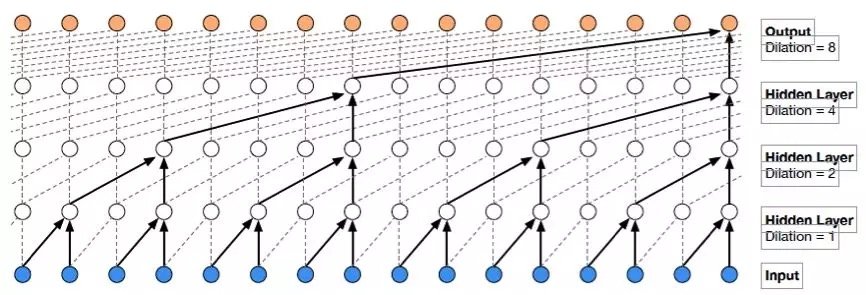
WaveNet 是受到 PixelRNN 的啟發,將自回歸模型應用於時域波形生成的成功嘗試。利用 WaveNet 生成的語音,在音質上大大超越了之前的參數合成效果,甚至合成的某些句子,能夠到達以假亂真的水平,引起了巨大的轟動。其中,所採用的帶洞卷積(dilated convolution)大大提升了感受野,以滿足對高採樣率的音頻時域信號建模的要求。WaveNet 的優點非常明顯,但由於其利用前 N-1 個樣本預測第 N 個樣本,所以效率非常低,這也是 WaveNet 的一個明顯缺點。後來提出的 Parallel WaveNet 和 ClariNet,都是為了解決這個問題,思路是利用神經網路提煉技術,用預先訓練好的 WaveNet 模型(teacher)來訓練可並行計算的 IAF 模型(student),從而實現實時合成,同時保持近乎自然語音的高音質。
Tacotron 是端到端語音合成系統的代表,與以往的合成系統不同,端到端合成系統,可以直接利用錄音文本和對應的語音數據對,進行模型訓練,而無需過多的專家知識和專業處理能力,大大降低了進入語音合成領域的門檻,為語音合成的快速發展提供了新的催化劑。
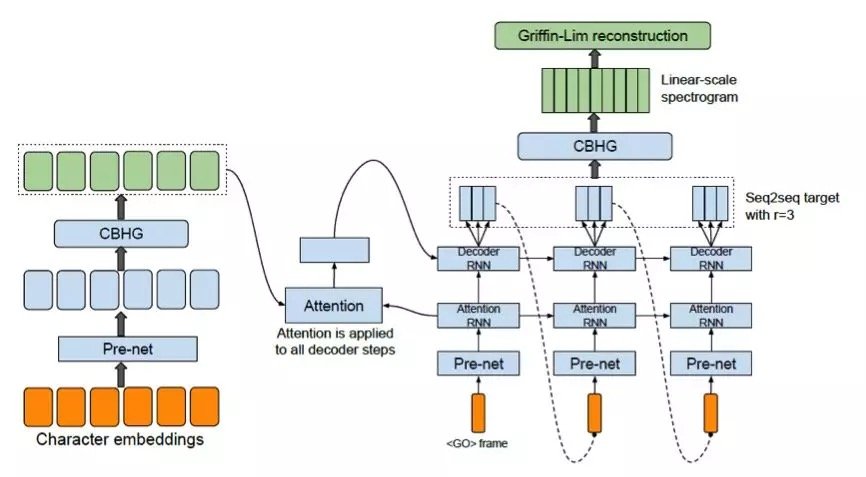
Tacotron 把文本符號作為輸入,把幅度譜作為輸出,然後通過 Griffin-Lim 進行信號重建,輸出高質量的語音。Tacotron 的核心結構是帶有注意力機制的 encoder–decoder 模型,是一種典型的 seq2seq 結構。這種結構,不再需要對語音和文本的局部對應關係進行單獨處理,極大地降低了對訓練數據的處理難度。由於 Tacotron 模型比較複雜,可以充分利用模型的參數和注意力機制,對序列進行更精細地刻畫,以提升合成語音的表現力。相較於 WaveNet 模型的逐採樣點建模,Tacotron 模型是逐幀建模,合成效率得以大幅提升,有一定的產品化潛力,但合成音質比 WaveNet 有所降低。
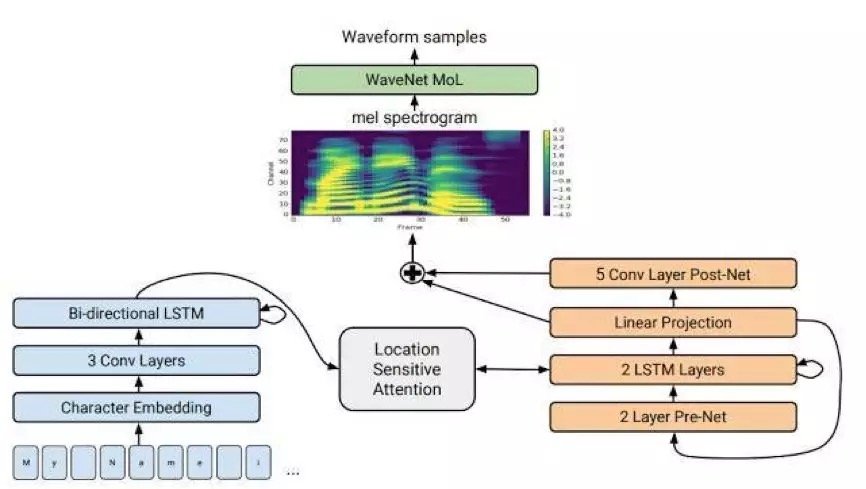
Tacotron2 是基於 Tacotron 和 WaveNet 進行融合的自然結果,既充分利用了端到端的合成框架,又利用了高音質的語音生成演算法。在這一框架中,採用與 Tacotron 類似的結構,用於生成 Mel 譜,作為 WaveNet 的輸入,而 WaveNet 則退化成神經網路聲碼器,兩者共同組成了一個端到端的高音質系統。
三、語音合成的應用
語音合成技術,已經成功應用在很多領域,包括語音導航、信息播報等。對於語音合成的應用前景,標貝科技有著自己的看法。因為標貝科技既是語音數據服務商,同時也是語音合成整體解決方案提供商,所以對於語音合成的應用前景,也做過很多思考。目前語音合成的聲音,從合成效果上,已經可以滿足大多數用戶的需求,但是從音色選擇上,還不夠豐富;從發音方式上,還是偏單調。針對這種情況,標貝科技推出了「聲音超市」,為合作夥伴提供了一個可供選擇的,所聽即所得的聲音平台。我們認為,語音合成會以更貼近場景需求的合成效果,在如下的三大場景中得以廣泛應用:語音交互、閱讀&教育、泛娛樂。
語音交互
近年來,隨著人工智慧概念的推廣,語音交互成為了一個熱點,智能助手、智能客服等應用層出不窮。語音交互中,主要有三個關鍵技術,語音識別、語音合成和語義理解,語音合成在其中的作用顯而易見。受限於語義理解的技術發展水平,目前的應用主要是聚焦於不同的垂直領域,用於解決某些特定領域的問題,還存在一定的局限性。
閱讀&教育
閱讀是一個長期且廣泛的需求,我們每天都需要通過閱讀獲取大量的信息,既有碎片化的信息獲取,也有深度閱讀;既包括新聞、朋友圈、博文,也包括小說、名著;有的是為了與社會同步,有的是消磨時光,有的是為了提升自我修養。在這種多維度的信息需求當中,語音合成技術提供了一種「簡單」的方式,一種可以「並行」輸入的方式,同時也是一種「廉價」的方式。相較於傳統的閱讀,自有其優勢。在開車時、散步時、鍛煉時,都可以輕鬆獲取信息。
在教育方面,尤其是語言教育方面,模仿與交互是必不可少的鍛煉方式。目前的教育方式中,想學到標準的發音,是需要大量的成本的,比如各種課外班,甚至一對一教育。隨著語音合成技術的不斷進步,以假亂真的合成效果,一方面可以大大增加有聲教育素材,另一方面,甚至可以部分取代真人對話的教育內容。
泛娛樂
泛娛樂是之前與語音合成交叉較少的場景,但我們認為這恰恰是一個巨大的有待開發的市場。我們已經擁有豐富的聲音 IP 資源,並且可以通過聲音超市進行展示,供大家選購自己喜歡的聲音。這些都是為了將語音合成技術廣泛應用到泛娛樂領域所做的準備。以配音領域為例,利用語音合成技術,可以大大降低配音的成本和周期;以目前火爆的短視頻為例,利用語音合成技術可以非常容易地為自己的視頻配上有趣的聲音來展現內容;以虛擬主持人為例,利用語音合成技術,可以提升信息的時效性,同時大大緩解主持人的工作壓力,降低其工作強度。
總之,隨著語音合成技術的快速發展,所生成的語音會越來越自然生動,也會越來越有情感表現力。我們堅信,技術的進步,會不斷衝破原有的障礙,滿足越來越多的用戶需求,使得更好的應用不斷湧現,實現用聲音改變生活的美好願景!


Comments