

本文轉自公眾號 鮮棗課堂(xzclasscom),原文地址:https://mp.weixin.qq.com/s/aTmbOiLKbA1NYWGT4CMJhw
這些年,大數據作為一個時髦概念,出現頻率很高,關注度也很高。
對於很多人來說,當他第一次聽到“大數據”這個詞,會自然而然從字面上去理解——認為大數據就是大量的數據,大數據技術就是大量數據的存儲技術。
但是,事實並非如此。
大數據比想象中複雜。它不只是一項數據存儲技術,而是一系列和海量數據相關的抽取、集成、管理、分析、解釋技術,是一個龐大的框架系統。
更進一步來說,大數據是一種全新的思維方式和商業模式。

今天這篇文章,就讓我們花五分鐘的時間,來深入了解一下,到底什麼是大數據。
大數據的定義
首先,還是要重新審視大數據的定義。
行業里對大數據的定義有很多,有廣義的定義,也有狹義的定義。
廣義的定義,有點哲學味道——大數據,是指物理世界到數字世界的映射和提煉。通過發現其中的數據特徵,從而做出提升效率的決策行為。
狹義的定義,是技術工程師給的——大數據,是通過獲取、存儲、分析,從大容量數據中挖掘價值的一種全新的技術架構。
相比較而言,我還是喜歡技術定義,哈哈。
大家注意,關鍵詞我都在上面原句加粗了哈!
要做什麼?——獲取數據、存儲數據、分析數據
對誰做?——大容量數據
目的是什麼?——挖掘價值
獲取數據、存儲數據、分析數據,這一系列的行為,都不算新奇。我們每天都在用電腦,每天都在干這個事。
例如,每月的月初,考勤管理員會獲取每個員工的考勤信息,錄入Excel表格,然後存在電腦里,統計分析有多少人遲到、缺勤,然後扣TA工資。
但是,同樣的行為,放在大數據身上,就行不通了。換言之,傳統個人電腦,傳統常規軟件,無力應對的數據級別,才叫“大數據”。
大數據,到底有多大?
我們傳統的個人電腦,處理的數據,是GB/TB級別。例如,我們的硬盤,現在通常是1TB/2TB/4TB的容量。
TB、GB、MB、KB的關係,大家應該都很熟悉了:
1 KB = 1024 B (KB – kilobyte)
1 MB = 1024 KB (MB – megabyte)
1 GB = 1024 MB (GB – gigabyte)
1 TB = 1024 GB (TB – terabyte)
而大數據是什麼級別呢?PB/EB級別。

大部分人都沒聽過。其實也就是繼續翻1024倍:
1 PB = 1024 TB (PB – petabyte)
1 EB = 1024 PB (EB – exabyte)
只是看這幾個字母的話,貌似不是很直觀。我來舉個例子吧。
1TB,只需要一塊硬盤可以存儲。容量大約是20萬張照片或20萬首MP3音樂,或者是671部《紅樓夢》小說。

1PB,需要大約2個機櫃的存儲設備。容量大約是2億張照片或2億首MP3音樂。如果一個人不停地聽這些音樂,可以聽1900年。。。

1EB,需要大約2000個機櫃的存儲設備。如果並排放這些機櫃,可以連綿1.2公里那麼長。如果擺放在機房裡,需要21個標準籃球場那麼大的機房,才能放得下。
阿里、百度、騰訊這樣的互聯網巨頭,數據量據說已經接近EB級。

EB還不是最大的。目前全人類的數據量,是ZB級。
1 ZB = 1024 EB (ZB – zettabyte)
2011年,全球被創建和複製的數據總量是1.8ZB。
而到2020年,全球電子設備存儲的數據,將達到35ZB。如果建一個機房來存儲這些數據,那麼,這個機房的面積將比42個鳥巢體育場還大。

數據量不僅大,增長還很快——每年增長50%。也就是說,每兩年就會增長一倍。
目前的大數據應用,還沒有達到ZB級,主要集中在PB/EB級別。大數據的級別定位
1 KB = 1024 B (KB – kilobyte)
1 MB = 1024 KB (MB – megabyte)
1 GB = 1024 MB (GB – gigabyte)
1 TB = 1024 GB (TB – terabyte)
1 PB = 1024 TB (PB – petabyte)
1 EB = 1024 PB (EB – exabyte)
1 ZB = 1024 EB (ZB – zettabyte)
數據的來源
數據的增長,為什麼會如此之快?
說到這裡,就要回顧一下人類社會數據產生的幾個重要階段。
大致來說,是三個重要的階段。
第一個階段,就是計算機被發明之後的階段。尤其是數據庫被發明之後,使得數據管理的複雜度大大降低。各行各業開始產生了數據,從而被記錄在數據庫中。這時的數據,以結構化數據為主(待會解釋什麼是“結構化數據”)。數據的產生方式,也是被動的。

第二個階段,是伴隨着互聯網2.0時代出現的。互聯網2.0的最重要標誌,就是用戶原創內容。隨着互聯網和移動通信設備的普及,人們開始使用博客、facebook、youtube這樣的社交網絡,從而主動產生了大量的數據。

第三個階段,是感知式系統階段。隨着物聯網的發展,各種各樣的感知層節點開始自動產生大量的數據,例如遍布世界各個角落的傳感器、攝像頭。

經過了“被動-主動-自動”這三個階段的發展,最終導致了人類數據總量的極速膨脹。
大數據的4Vs
行業里對大數據的特點,概括為4個V。前面所說的龐大數據體量,就是Volume(海量化)。除了Volume之外,剩下三個,分別是Variety、Velocity、Value。
我們一個一個來介紹。
- Variety(多樣化)
數據的形式是多種多樣的,包括數字(價格、交易數據、體重、人數等)、文本(郵件、網頁等)、圖像、音頻、視頻、位置信息(經緯度、海拔等),等等,都是數據。
數據又分為結構化數據和非結構化數據。
從名字可以看出,結構化數據,是指可以用預先定義的數據模型表述,或者,可以存入關係型數據庫的數據。

例如,一個班級所有人的年齡、一個超市所有商品的價格,這些都是結構化數據。
而網頁文章、郵件內容、圖像、音頻、視頻等,都屬於非結構話數據。
在互聯網領域裡,非結構化數據的佔比已經超過整個數據量的80%。
大數據,就符合這樣的特點:數據形式多樣化,且非結構化數據佔比高。
- Velocity(時效性)
大數據還有一個特點,那就是時效性。從數據的生成到消耗,時間窗口非常小。數據的變化速率,還有處理過程,越來越快。例如變化速率,從以前的按天變化,變成現在的按秒甚至毫秒變化。
我們還是用數字來說話:
就在剛剛過去的這一分鐘,數據世界裡發生了什麼?
Email:2.04億封被發出
Google:200萬次搜索請求被提交
Youtube:2880分鐘的視頻被上傳
Facebook:69.5萬條狀態被更新
Twitter:98000條推送被發出
12306:1840張車票被賣出
……
怎麼樣?是不是瞬息萬變?
- Value(價值密度)
最後一個特點,就是價值密度。
大數據的數據量很大,但隨之帶來的,就是價值密度很低,數據中真正有價值的,只是其中的很少一部分。
例如通過監控視頻尋找犯罪分子的相貌,也許幾TB的視頻文件,真正有價值的,只有幾秒鐘。

2014年美國波士頓爆炸案,現場調取了10TB的監控數據(包括移動基站的通訊記錄,附近商店、加油站、報攤的監控錄像以及志願者提供的影像資料),最終找到了嫌疑犯的一張照片。
大數據的價值
剛才說到價值密度,也就說到了大數據的核心本質,那就是價值。
人類提出大數據、研究大數據的主要目的,就是為了挖掘大數據裡面的價值。
大數據,究竟有什麼價值?
早在1980年,著名未來學家阿爾文·托夫勒在他的著作《第三次浪潮》中,就明確提出:“數據就是財富”,並且,將大數據稱為“第三次浪潮的華彩樂章”。

- 第一次浪潮:農業階段,約1萬年前開始
- 第二次浪潮:工業階段,17世紀末開始
- 第三次浪潮:信息化階段,20世紀50年代後期開始
進入21世紀之後,隨着前面所說的第二第三階段的發展,移動互聯網崛起,存儲能力和雲計算能力飛躍,大數據開始落地,也引起了越來越多的重視。
2012年的世界經濟論壇指出:“數據已經成為一種新的經濟資產類別,就像貨幣和黃金一樣”。這無疑將大數據的價值推到了前所未有的高度層面上。
如今,大數據應用開始走進我們的生活,影響我們的衣食住行。

之所以大數據會有這麼快的發展,就是因為越來越多的行業和企業,開始認識到大數據的價值,開始試圖參與挖掘大數據的價值。
歸納來說,大數據的價值主要來自於兩個方面:
1 幫助企業了解用戶
大數據通過相關性分析,將客戶和產品、服務進行關係串聯,對用戶的偏好進行定位,從而提供更精準、更有導向性的產品和服務,提升銷售業績。
典型的例子就是電商。
像阿里淘寶這樣的電子商務平台,積累了大量的用戶購買數據。在早期的時候,這些數據都是累贅和負擔,存儲它們需要大量的硬件成本。但是,現在這些數據都是阿里最寶貴的財富。
通過這些數據,可以分析用戶行為,精準定位目標客群的消費特點、品牌偏好、地域分布,從而引導商家的運營管理、品牌定位、推廣營銷等。

大數據可以對業績產生直接影響。它的效率和準確性,遠遠超過傳統的用戶調研。
除了電商,包括能源、影視、證券、金融、農業、工業、交通運輸、公共事業等,都是大數據的用武之地。

大數據甚至能夠幫助競選總統
2 幫助企業了解自己
除了幫助了解用戶之外,大數據還能幫助了解自己。
企業生產經營需要大量的資源,大數據可以分析和鎖定資源的具體情況,例如儲量分布和需求趨勢。這些資源的可視化,可以幫助企業管理者更直觀地了解企業的運作狀態,更快地發現問題,及時調整運營策略,降低經營風險。
總而言之,“知己知彼,百戰百勝”。大數據,就是為決策服務的。
大數據和雲計算
說到這裡,我們要回答一個很多人心裡都存在的疑惑——大數據和雲計算之間,到底有什麼關係?
可以這麼解釋:數據本身是一種資產,而雲計算,則是為挖掘資產價值提供合適的工具。
從技術上,大數據是依賴於雲計算的。雲計算裡面的海量數據存儲技術、海量數據管理技術、分布式計算模型等,都是大數據技術的基礎。
雲計算就像是挖掘機,大數據就是礦山。如果沒有雲計算,大數據的價值就發揮不出來。
相反的,大數據的處理需求,也刺激了雲計算相關技術的發展和落地。
也就是說,如果沒有大數據這座礦山,雲計算這個挖掘機,很多強悍的功能都發展不起來。
套用一句老話——雲計算和大數據,兩者是相輔相成的。
大數據和物聯網(5G)
第二個問題,大數據和物聯網有什麼關係?
這個問題我覺得大家應該能夠很快想明白,前面其實也提到了。
物聯網就是“物與物互相連接的互聯網”。物聯網的感知層,產生了海量的數據,將會極大地促進大數據的發展。
同樣,大數據應用也發揮了物聯網的價值,反向刺激了物聯網的使用需求。越來越多的企業,發覺能夠通過物聯網大數據獲得價值,就會願意投資建設物聯網。
其實這個問題也可以進一步延伸為“大數據和5G之間的關係”。
即將到來的5G,通過提升連接速率,提升了“人聯網”的感知,也促進了人類主動創造數據。
另一方面,它更多是為“物聯網”服務的。包括低延時、海量終端連接等,都是物聯網場景的需求。
5G刺激物聯網的發展,而物聯網刺激大數據的發展。所有通信基礎設施的強大,都是為大數據崛起鋪平道路。
大數據的產業鏈
接下來再說說大數據的產業鏈。
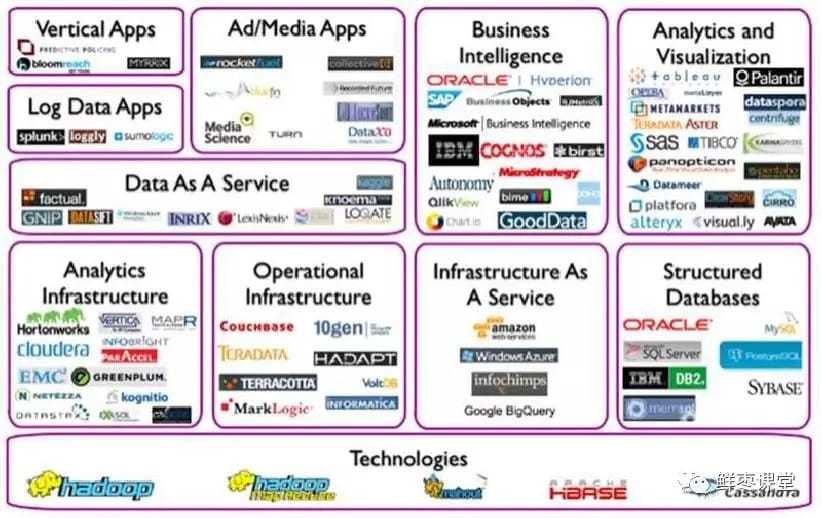
大數據的產業鏈,和大數據的處理流程是緊密相關的。簡單來說,就是生產數據、聚合數據、分析數據、消費數據。
每個環節,都有相應的角色玩家。如下圖:

從目前的情況來看,國外廠商在大數據產業佔據了較大的份額,尤其是上游領域,基本上都是國外企業。國內IT企業相比而言,存在較大的差距。
大數據的挑戰
說了那麼多大數據的好話,並不代表大數據是完美的。
大數據也面臨著很多挑戰。
除了數據管理技術難度之外,大數據的最大挑戰,就是安全。
數據是資產,也是隱私。沒有人願意自己的隱私被暴露,所以,人們對自己的隱私保護越來越重視。政府也在不斷加強對公民隱私權的保護,出台了很多法律。

歐盟在2018年出台了有史以來最嚴厲的GDPR(《一般數據保護法案》),把網絡數據保護上升到前所未有的高度
在這種情況下,企業獲取用戶數據,就需要慎重考慮,是否符合倫理和法律。一旦違法,將付出極為沉重的代價。
此外,即使企業合法獲取數據,也要擔心是否會被惡意攻擊和竊取。這裡面的風險也是不容忽視的。
除了安全之外,大數據還要面臨能耗等方面的問題。
換言之,如果不能很好地保護和利用手裡的大數據,那麼它就是一個燙手的山芋,有還不如沒有。


Comments