

如果你不知道什麼是ML模型,請看一下這篇文章。

學習機器學習的課程和關於它的閱讀文章並不一定告訴你使用哪台機器學習模型。它們只是讓您直觀了解這些模型的工作原理,這可能會讓您無法為問題選擇合適的模型。
在我與ML的旅程開始時,關於解決問題,我會嘗試很多ML模型並使用最有效的模型,我現在仍然這樣做,但我遵循一些最佳實踐 – 關於如何選擇機器學習模型 – 我從經驗,直覺和同事那裡學到,這些最佳實踐使事情變得更容易,這就是我收集的內容。
我會告訴你根據問題的性質使用哪種機器學習模型,我會嘗試解釋一些概念。

分類
首先,如果你有一個分類問題「預測給定輸入的類」。
請記住,您將對輸入進行分類的類數,因為有些分類器不支持多類預測,它們僅支持2類預測。
– 緩慢但準確
– 快
注意:SVM內核使用(來自Andrew NG的課程)
- 當要素數大於觀察數時,請使用線性內核。
- 當觀察數量大於特徵數量時,使用高斯核心。
- 如果觀測數量大於50k,使用高斯核時速度可能是一個問題; 因此,人們可能想要使用線性內核。
回歸
如果你有一個回歸問題「這預測了一個連續的價值,比如預測房子的價格給出了房子的大小,房間的數量等等」。
– 準確但緩慢
– 快
聚類
如果你有一個聚類問題「根據它們的特徵將數據分成k組,使得同一組中的對象具有某種程度的相似性」。
分層聚類(也稱為分層聚類分析或 HCA)是一種聚類分析方法,旨在構建聚類層次結構。層次聚類策略通常分為兩種:
- 凝聚性:這是一種「自下而上」的方法:每個觀察都在它自己的集群中開始,並且當一個集群向上移動時,它們將被合併。
- 分裂:這是一種「自上而下」的方法:所有觀察都在一個集群中開始,並且當一個集體向下移動時,遞歸地執行分割。
非等級聚類:
如果您正在使用分類數據進行聚類
維度降低
PCA可以被認為是對數據擬合n維橢球,其中橢球的每個軸代表主要成分。如果橢圓體的某個軸很小,那麼沿該軸的方差也很小,並且通過從數據集的表示中省略該軸及其相應的主成分,我們僅丟失相應的少量信息。
如果您想進行主題建模(下面的說明),您可以使用奇異值分解(SVD)或潛在Dirichlet分析(LDA),並在概率主題建模的情況下使用LDA。
- 主題建模是一種統計模型,用於發現文檔集合中出現的抽象「主題」。主題建模是一種常用的文本挖掘工具,用於在文本體中發現隱藏的語義結構。
我希望現在對你來說更容易,我會根據你從反饋和實驗中獲得的信息更新文章。
我會給你留下這兩個很棒的摘要。

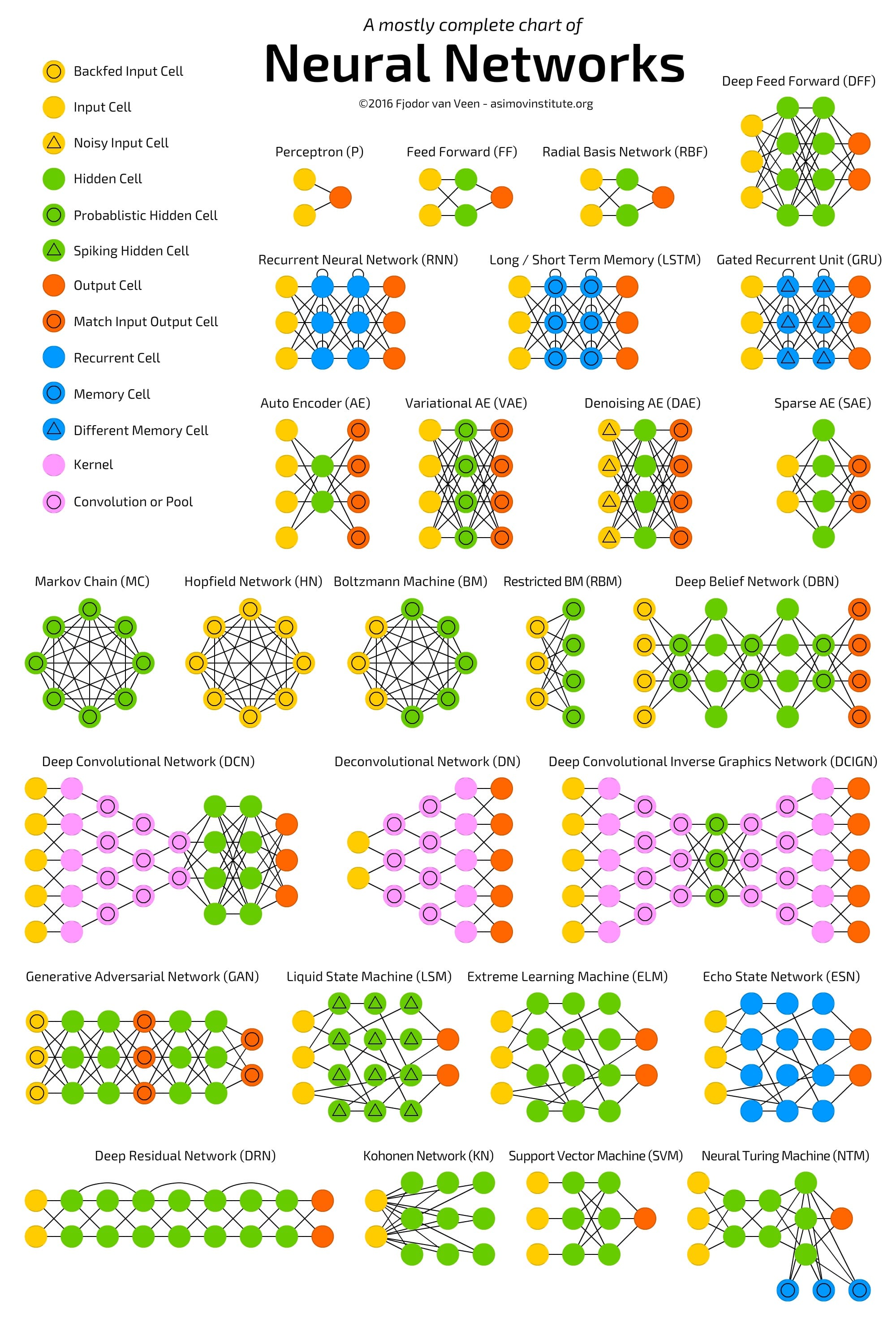
本文轉自towardsdatascience,原文地址

Comments