

生成性对抗网络(GANs)已经接管了公众的想象力 – 通过AI产生的名人来吸引流行文化,并创造出在高级艺术品拍卖中以数千美元销售的艺术品。
在这篇文章中,我们将探讨:
- 关于GAN的简要介绍
- 理解和评估GAN
- 运行自己的GAN
有足够的资源来追赶GAN,因此我们对本文的重点是了解如何评估GAN。我们还将引导您运行自己的GAN以生成MNIST等手写数字。
关于GAN的简要介绍
自2014年Ian Goodfellow的“ Generative Adversarial Networks ”论文成立以来,GAN的进展已经爆发并导致产出越来越现实。

就在三年前,你可以找到Ian Goodfellow对这个Reddit主题的回复给用户询问你是否可以使用GAN作为文本:
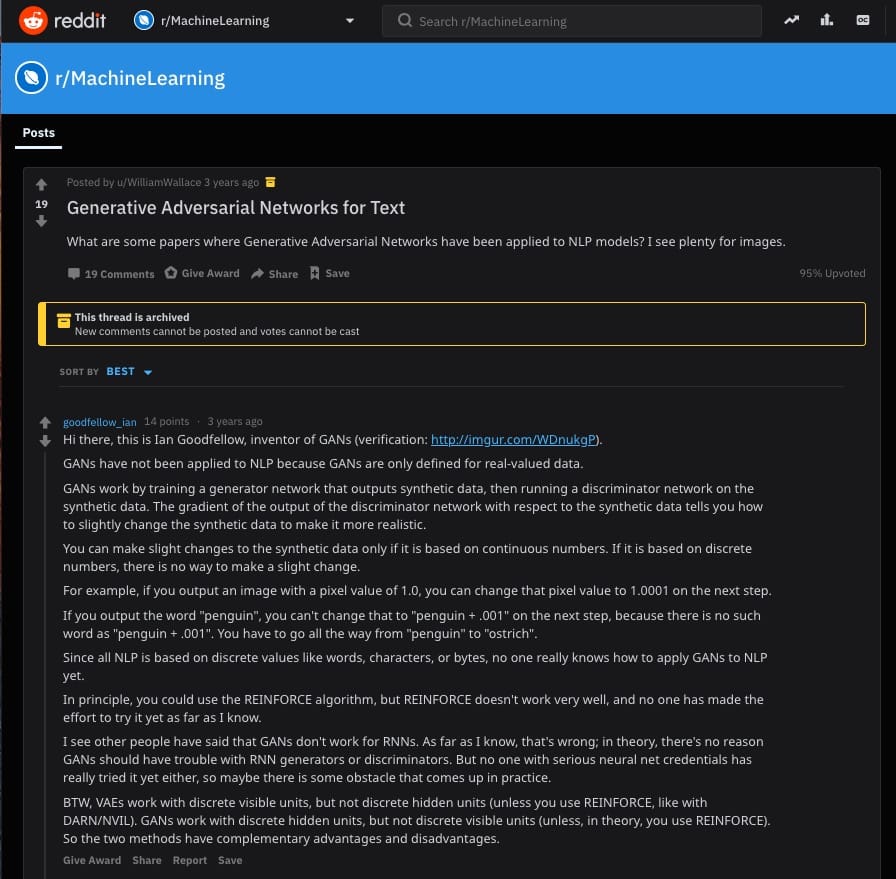
“GAN尚未应用于NLP,因为GAN仅针对实值数据进行了定义。GAN通过训练输出合成数据的发电机网络,然后在合成数据上运行鉴别器网络来工作。鉴别器网络的输出相对于合成数据的梯度告诉您如何稍微改变合成数据以使其更加真实。仅当合成数据基于连续数字时,才能对其进行细微更改。如果它基于离散数字,则无法进行轻微更改。例如,如果输出像素值为1.0的图像,则可以在下一步将该像素值更改为1.0001。如果输出单词“penguin”,则不能在下一步将其更改为“penguin + .001”,因为没有“penguin + .001”这样的单词。你必须从“企鹅”到“鸵鸟”一路走。由于所有NLP都基于离散值,如单词,字符或字节,因此没有人真正知道如何将GAN应用于NLP。“
现在GAN用于创建各种内容,包括图像,视频,音频和(是)文本。这些输出可用作训练其他模型的合成数据,或仅用于产生有趣的侧面项目,例如thispersondoesnotexist.com,thisairbnbdoesnotexist.com/,并且此机器学习媒体帖子不存在。😎
GAN背后
GAN由两个神经网络组成 – 一个从头开始合成新样本的生成器,以及一个将训练样本与来自生成器的这些生成样本进行比较的鉴别器。鉴别器的目标是区分“真实”和“假”输入(即,如果样本来自模型分布或真实分布,则进行分类)。如我们所述,这些样本可以是图像,视频,音频片段和文本。
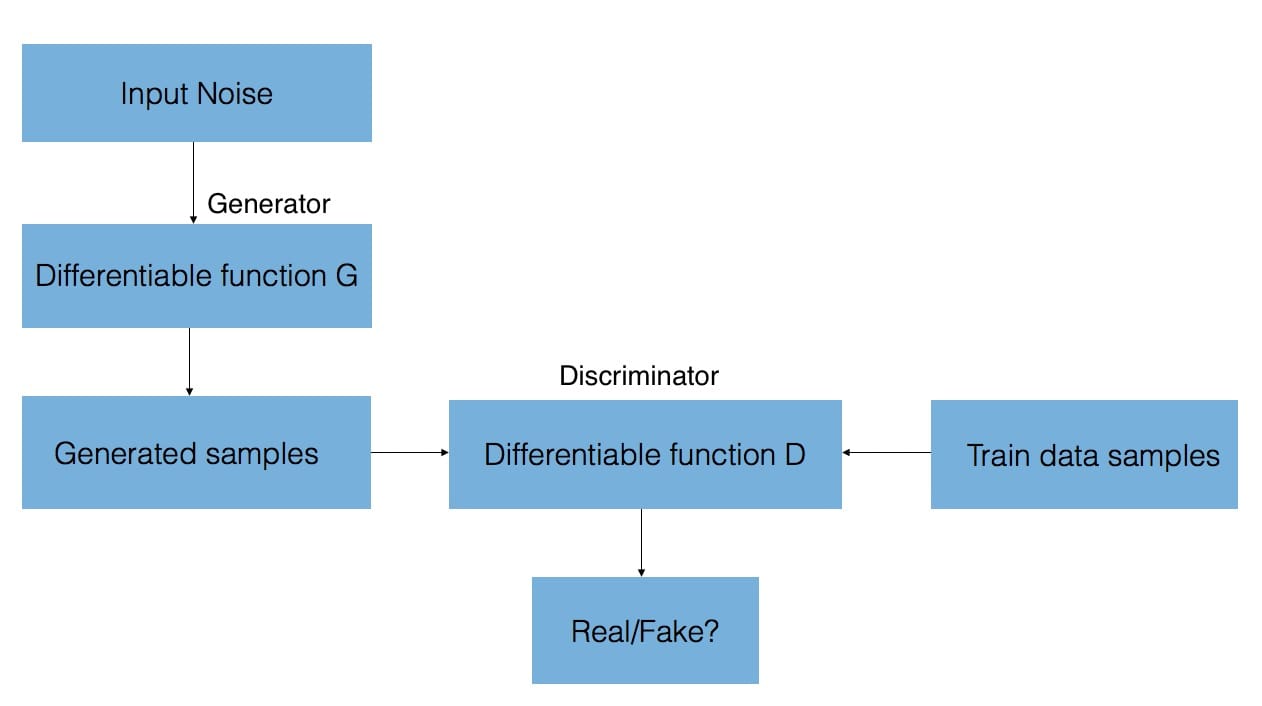
为了合成这些新样本,给予发生器随机噪声并尝试从所学习的训练数据分布生成逼真的图像。
鉴别器网络(卷积神经网络)的输出相对于合成数据的梯度通知如何稍微改变合成数据以使其更加真实。最终,生成器收敛于再现实际数据分布的参数,并且鉴别器无法检测到差异。
您可以通过GAN Lab查看和使用这些融合数据分布:GAN Lab:在您的浏览器中使用生成式对抗网络!
GAN Lab由Minsuk Kahng,Nikhil Thorat,Polo Chau,FernandaViégas和Martin Wattenberg创建,这是…poloclub.github.io
以下是关于GAN的最佳指南:
- 斯坦福CS231第13讲 – 生成模型
- 基于风格的GAN
- 了解生成性对抗网络
- 生成对抗网络简介
- Lillian Weng:从Gan到WGAN
- 首先潜入先进的GAN:探索自我关注和频谱规范
- Guim Perarnau:神奇的GAN以及在哪里找到它们(第一和第二部分)
理解和评估GAN
量化GAN的进度可以感觉非常主观 – “这个生成的面部是否看起来足够逼真?”,“这些生成的图像是否足够多样化?” - 并且GAN可能感觉像黑盒子,其中不清楚模型的哪些组件影响学习或结果质量。
为此,麻省理工学院计算机科学与人工智能(CSAIL)实验室的一个小组最近发表了一篇论文“ GAN解剖:可视化和理解生成性对抗网络 ”,该论文介绍了一种可视化GAN以及GAN单元如何与对象相关的方法在图像以及对象之间的关系。

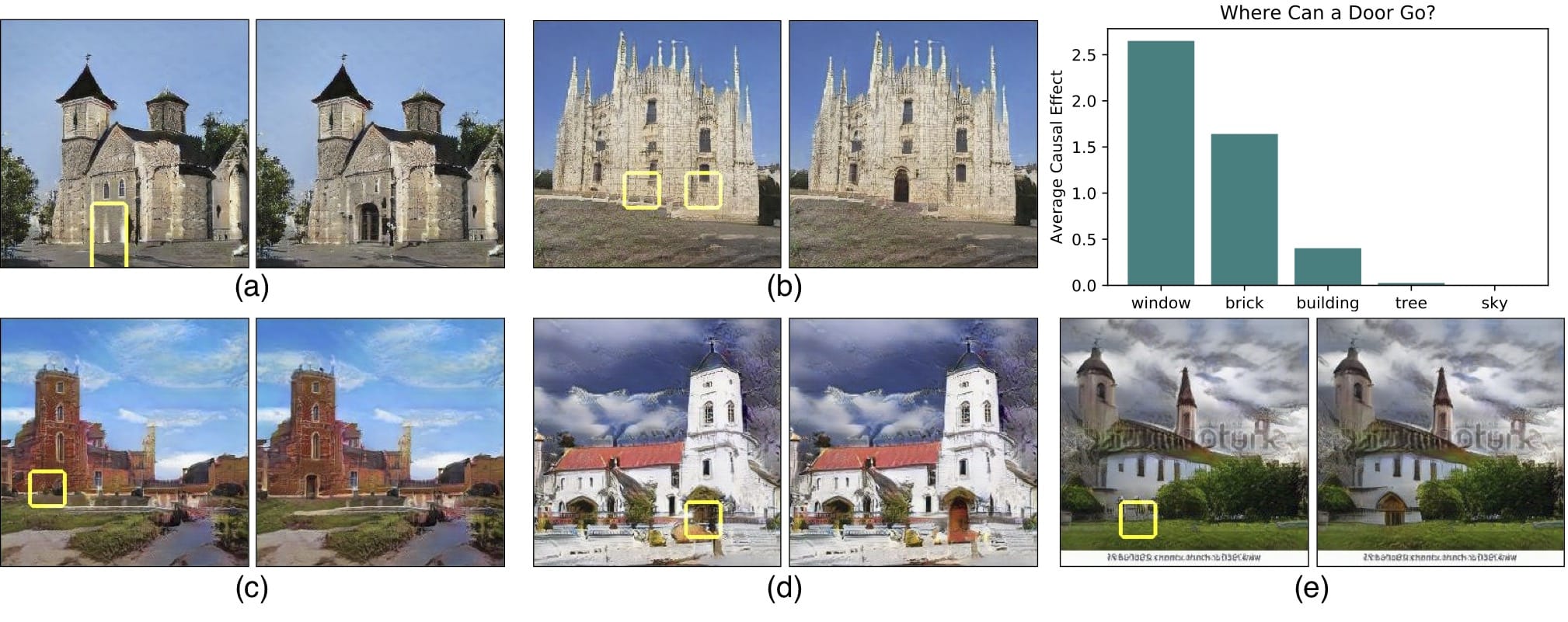
使用基于分割的网络剖析方法,本文的框架允许我们剖析和可视化生成器神经网络的内部工作。这通过寻找一组GAN单元(称为神经元)与输出图像中的概念(例如树,天空,云等)之间的协议来实现。因此,我们能够识别出对某些物体(如建筑物或云)负责的神经元。
将这种粒度级别放入神经元中允许通过强制激活和去激活(消融)这些对象的相应单元来编辑现有图像(例如,添加或移除图像中所示的树)。
但是,目前尚不清楚网络是否能够推断场景中的对象,或者它是否只是记住这些对象。接近这个问题的答案的一种方法是试图以不切实际的方式扭曲图像。也许MIT CSAIL的GAN Paint互动网络演示中最令人印象深刻的部分是该模型似乎能够将这些编辑限制为“真实感”的变化。如果你试图将草坪放在天空上,这就是发生的事情:
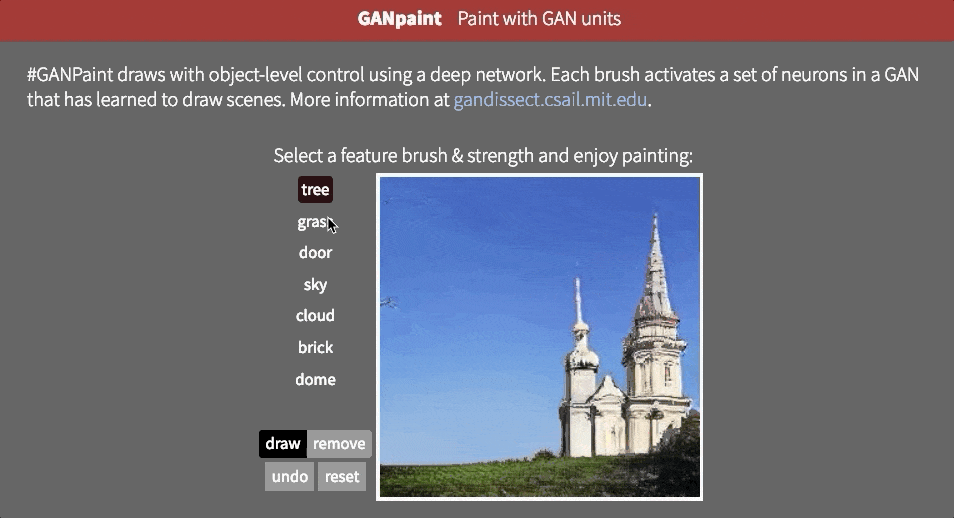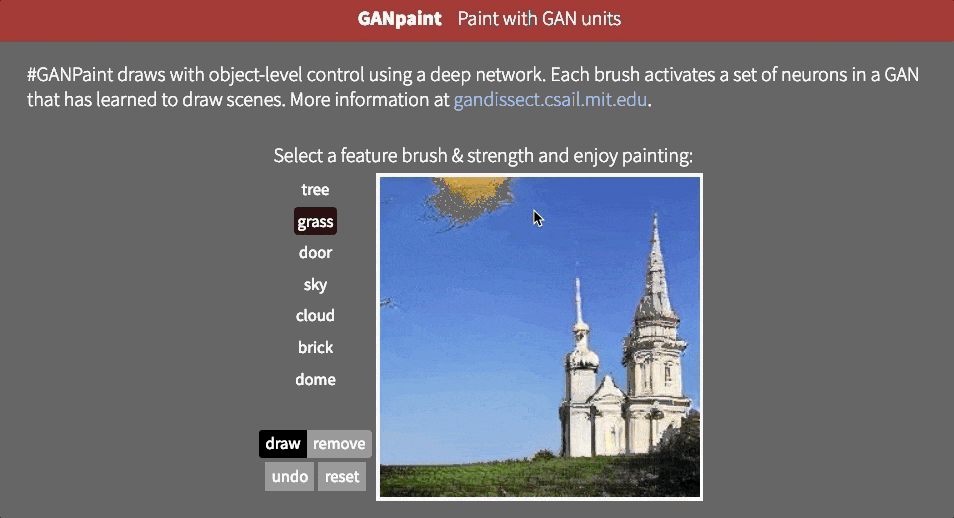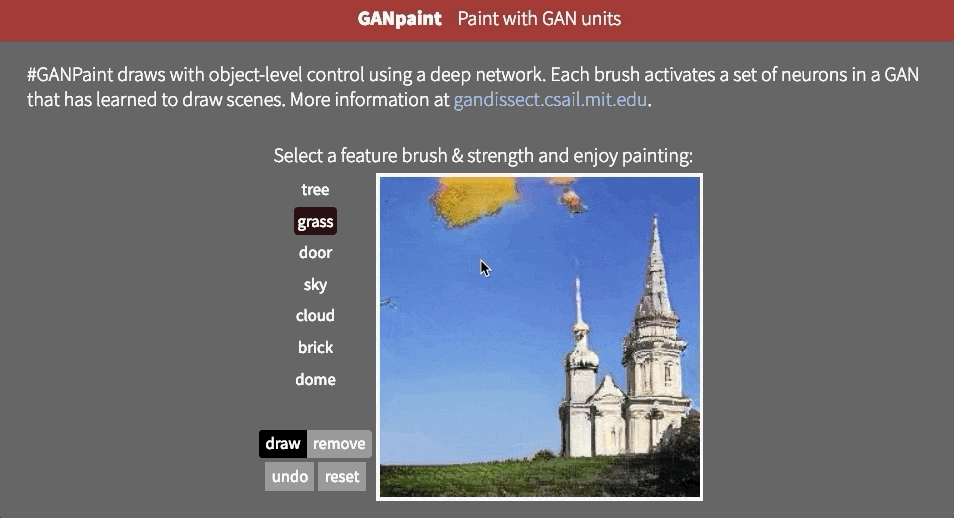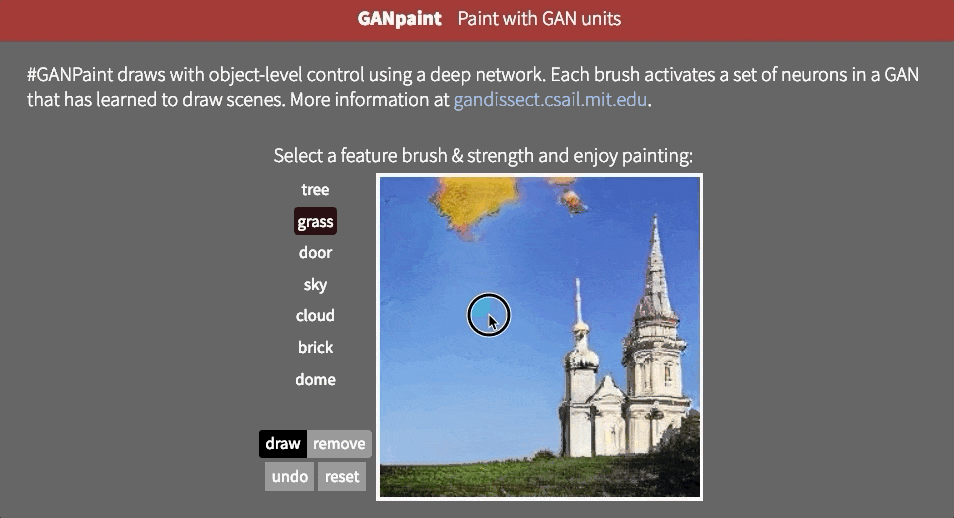
即使我们激活相应的神经元,看起来GAN已经抑制了后续层中的信号。
可视化GAN的另一种有趣方式是进行潜在空间插值(记住,GAN通过从学习的潜在空间中采样来生成新实例)。这可以是查看生成的样本之间的过渡平滑程度的有用方法。

这些可视化可以帮助我们理解GAN的内部表示,但是找到可量化的方法来理解GAN进度和输出质量仍然是一个活跃的研究领域。
图像质量和多样性的两个常用评估指标是:初始分数和Fréchet初始距离(FID)。Shane Barratt和Rishi Sharma 在前者的主要缺点上发表了他们的论文“ 关于初始分数的注释”,大多数从业者已从初始分数转为FID 。
初始分数
在Salimans等人发明。2016年“ 用于训练GAN的改进技术 ”中,初始分数基于一种启发式方法,即当通过预先训练的网络(例如ImageNet上的Inception)传递时,现实样本应该能够被分类。从技术上讲,这意味着样本应具有低熵softmax预测向量。
除了高可预测性(低熵)之外,初始分数还基于所生成的样本的多样性来评估GAN(例如,生成的样本的分布的高方差或熵)。这意味着不应该有任何支配阶级。
如果这两个特征都得到满足,那么应该有一个很大的初始分数。结合这两个标准的方法是评估样本的条件标签分布与所有样本的边际分布之间的Kullback-Leibler(KL)差异。
Fréchet起始距离
由Heusel等人介绍。2017年,FID通过测量生成的图像分布与真实分布之间的距离来估计真实感。FID将一组生成的样本嵌入由特定初始网络层给出的特征空间中。该嵌入层被视为连续的多元高斯,然后估计生成的数据和实际数据的均值和协方差。然后使用这两个高斯之间的Fréchet距离(aka Wasserstein-2距离)来量化生成的样本的质量。较低的FID对应于更相似的实际和生成的样本。
一个重要的注意事项是,FID需要一个合适的样本量才能产生良好的结果(建议的大小= 50k样本)。如果您使用的样本太少,最终会高估您的实际FID,并且估算值会有很大差异。对于成立之初成绩和分数FID如何跨越不同的文件进行比较,看尼尔吉恩的帖子
在这里。
想看更多?
Aji Borji的论文“ GAN评估措施的优点和缺点 ”包括一个优秀的表格,更全面地涵盖了GAN评估指标:
有趣的是,其他研究人员通过使用特定领域的评估指标采取不同的方法。对于文本GAN,Guy Tevet和他的团队提出使用传统的基于概率的语言模型度量来评估GAN在他们的论文“ 评估文本GAN作为语言模型 ”中生成的文本的分布。
在’ 我的GAN有多好?‘,Konstantin Shmelkov及其团队使用基于图像分类,GAN-train和GAN-test的两种方法,分别近似于GAN的召回(多样性)和精确度(图像质量)。您可以在Google Brain研究论文“ GANS创建相同 ”中看到这些评估指标,他们使用三角形数据集来衡量不同GAN模型的精确度和召回率。

运行自己的GAN
为了说明GAN,我们将调整Wouter Bulten的这个优秀教程,该教程使用Keras和MNIST数据集来生成书写数字。
在这里查看完整的教程笔记本。
该GAN模型将MNIST训练数据和随机噪声作为输入(具体地,噪声的随机向量)来生成:
- 图像(在这种情况下,手写数字的图像)。最终,这些生成的图像将类似于MNIST数据集的数据分布。
- 鉴别器对生成的图像的预测
所述发电机和鉴别模型一起形成对抗模型-在这个例子中,以及如果对抗模型用作输出所生成的图像分类为实际用于所有输入的发电机将执行。
跟踪模型的进度
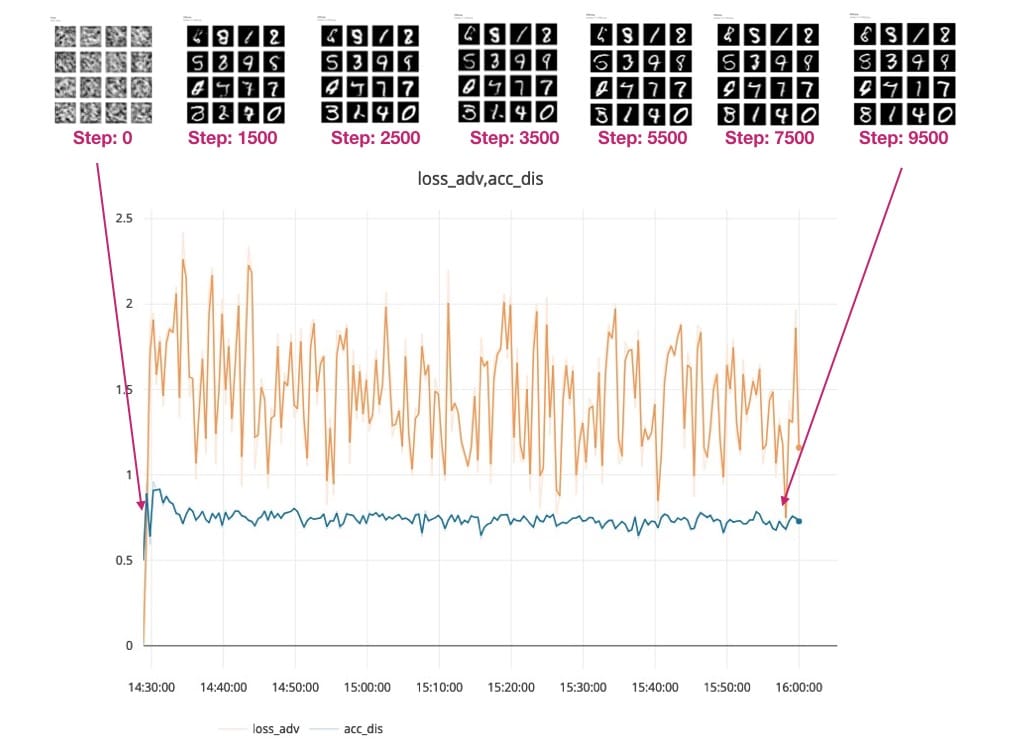
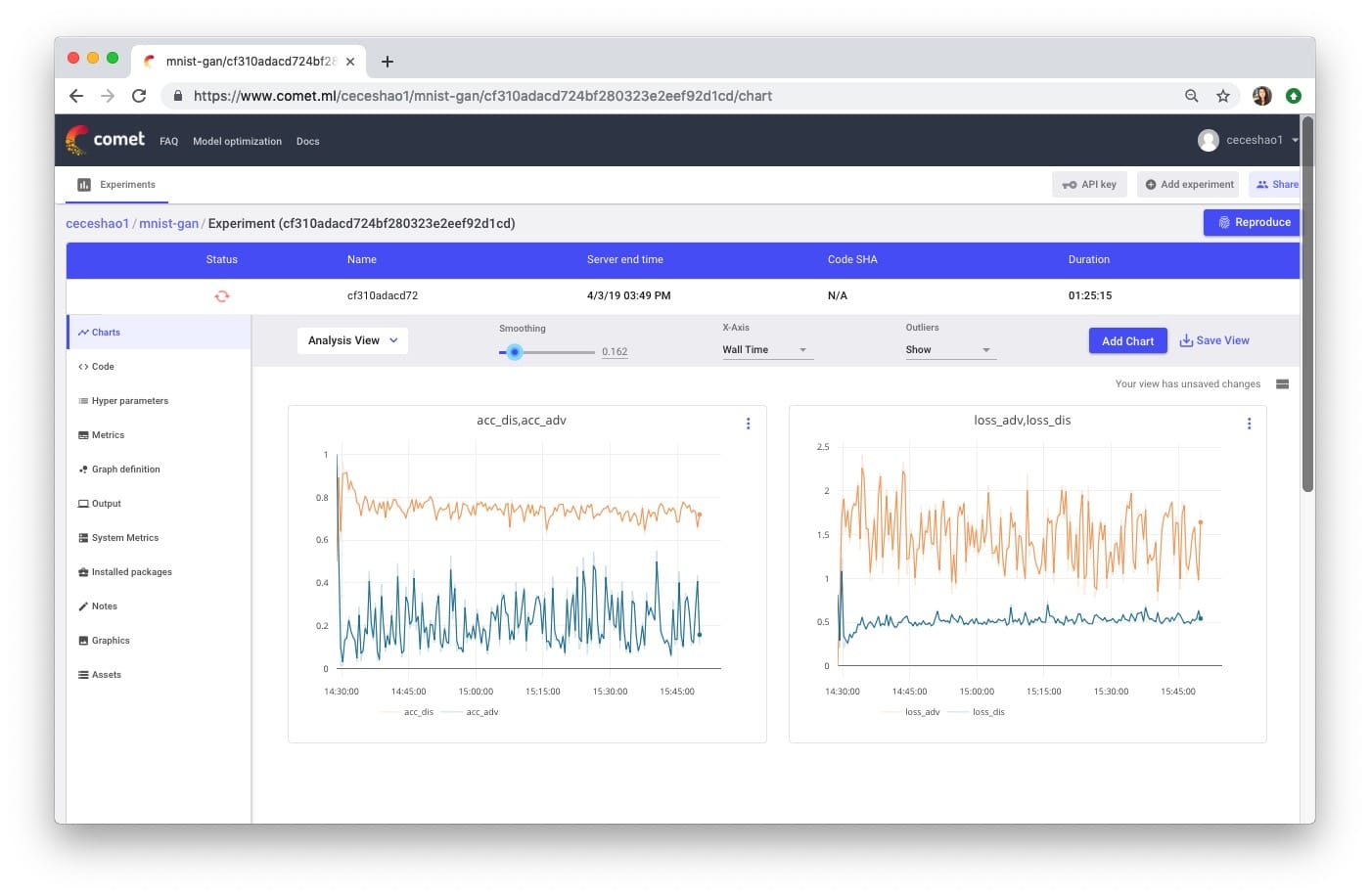
我们可以使用Comet.ml跟踪Generator和Discriminator模型的训练进度。
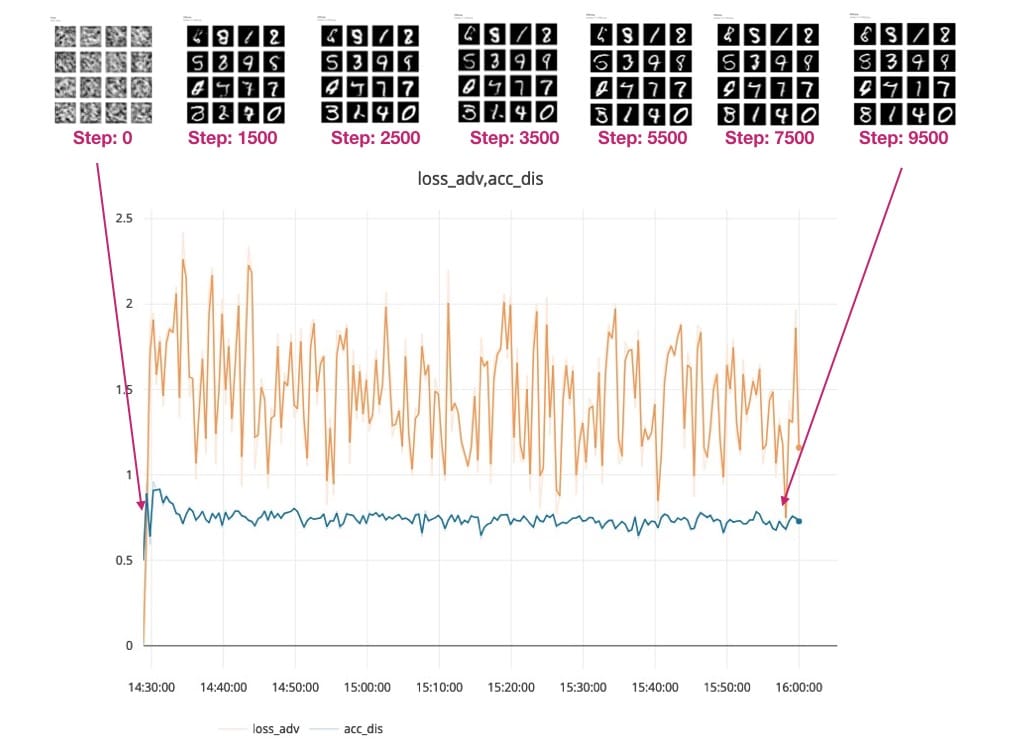
我们正在绘制鉴别器和对抗模型的准确性和损失 – 这里要跟踪的最重要指标是:
- 鉴别者的损失(见右图中的蓝线) – dis_loss
- 对抗模型的准确性(见左图中的蓝线) - acc_adv
请在此处查看此实验的培训进度。
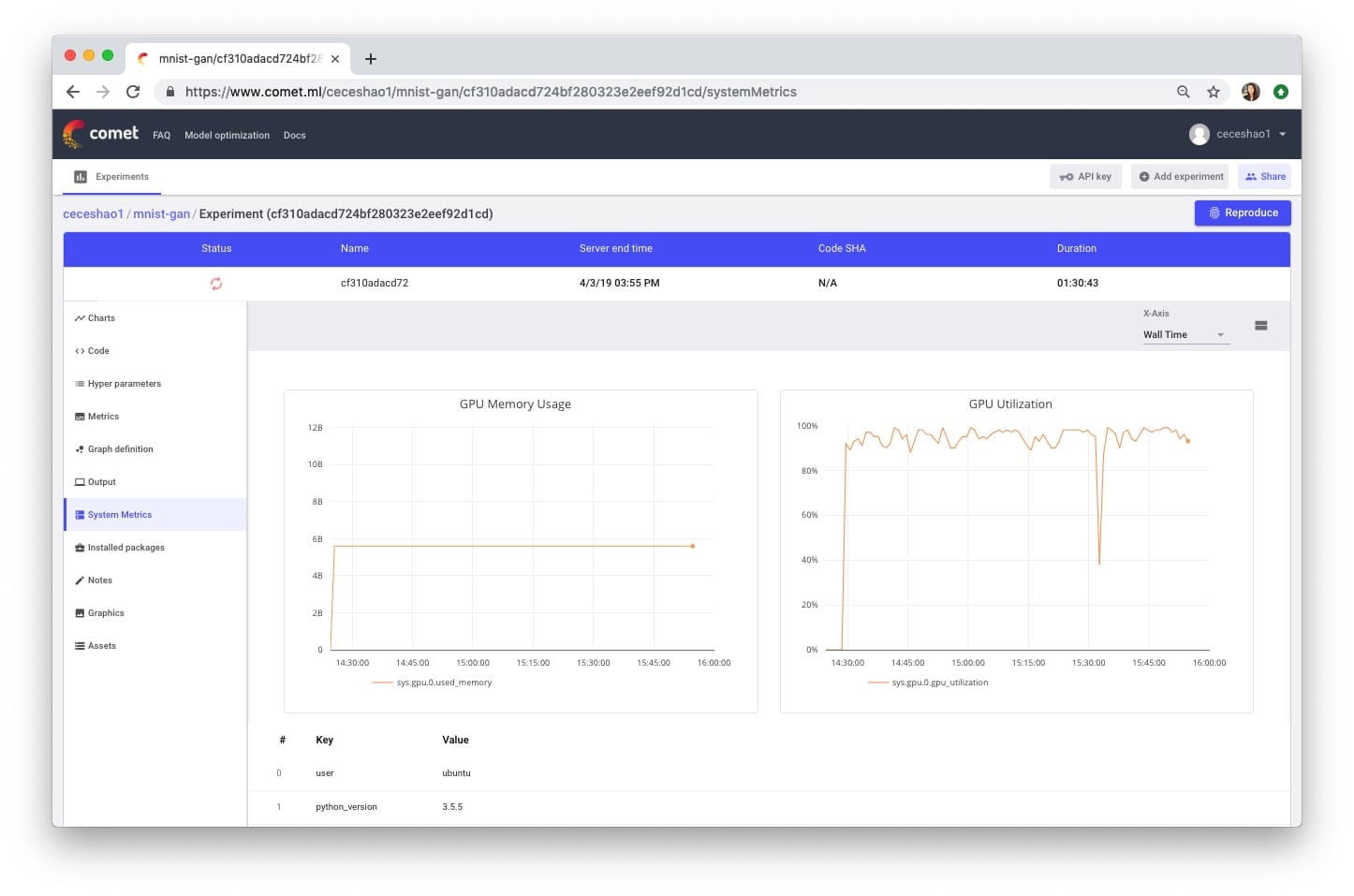
您还需要确认您的培训过程实际上是否正在使用GPU,您可以在Comet System Metrics选项卡中查看。
您注意到我们的for循环训练包括从测试向量报告图像的代码:
if i % 500 == 0:
# Visualize the performance of the generator by producing images from the test vector
images = net_generator.predict(vis_noise)
# Map back to original range
#images = (images + 1 ) * 0.5
plt.figure(figsize=(10,10))
for im in range(images.shape[0]):
plt.subplot(4, 4, im+1)
image = images[im, :, :, :]
image = np.reshape(image, [28, 28])
plt.imshow(image, cmap='gray')
plt.axis('off')
plt.tight_layout()
# plt.savefig('/home/ubuntu/cecelia/deeplearning-resources/output/mnist-normal/{}.png'.format(i))
plt.savefig(r'output/mnist-normal/{}.png'.format(i))
experiment.log_image(r'output/mnist-normal/{}.png'.format(i))
plt.close('all')我们想要每隔几步报告生成的输出的部分原因是,我们可以直观地分析我们的生成器和鉴别器模型在生成逼真的手写数字方面的表现,并正确地将生成的数字分类为“真实”或“假”,分别。
我们来看看这些生成的输出!在此Comet实验中查看您自己生成的输出
您可以看到Generator模型如何从这个模糊的灰色输出(参见下面的0.png)开始,它看起来并不像我们期望的手写数字。

随着培训的进行和我们模型的损失下降,生成的数字变得更加清晰。查看生成的输出:
步骤500:

步骤1000:

步骤1500:

最后在步骤10,000 - 您可以在下面的红色框中看到GAN生成数字的一些样本

一旦我们的GAN模型完成训练,我们甚至可以在Comet的图形选项卡中查看我们报告的输出作为电影(只需按下播放按钮!)。

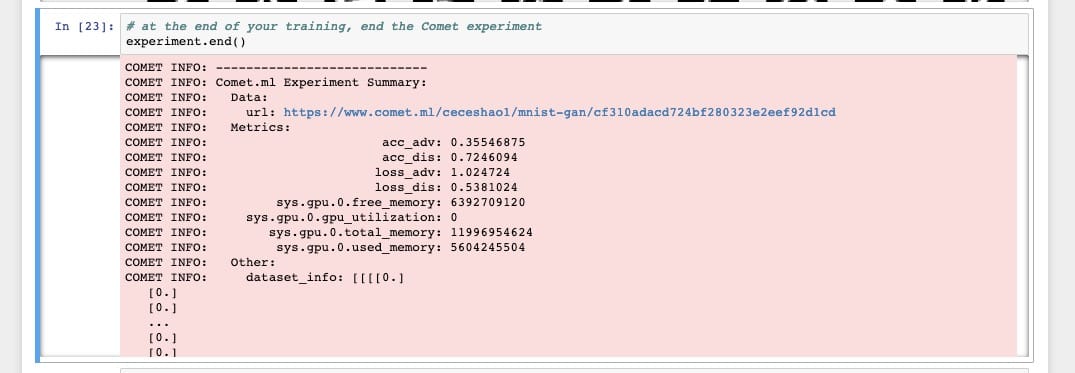
要完成实验,请确保运行experiment.end()以查看有关模型和GPU使用情况的一些摘要统计信息。
迭代您的模型
我们可以更长时间地训练模型以查看它如何影响性能,但让我们尝试使用几个不同的参数进行迭代。
我们使用的一些参数是:
- 鉴别器的优化器
- 学习率
- 辍学概率
- 批量大小
从Wouter的原始博客文章中,他提到了自己在测试参数方面的努力:
我已经测试了两者
SGD,RMSprop并且Adam对于鉴别器的优化器但是RMSprop表现最好。RMSprop使用低学习率并且我将值限制在-1和1之间。学习率的小衰减可以帮助稳定
我们将尝试将鉴别器的丢失概率从0.4增加到0.5,并增加鉴别器的学习率(从0.008到0.0009)和生成器的学习率(从0.0004到0.0006)。很容易看出这些变化如何失控并难以追踪……🤯
要创建不同的实验,只需再次运行实验定义单元格,Comet会为您的新实验发给您一个新的网址!跟踪您的实验很好,因此您可以比较差异:
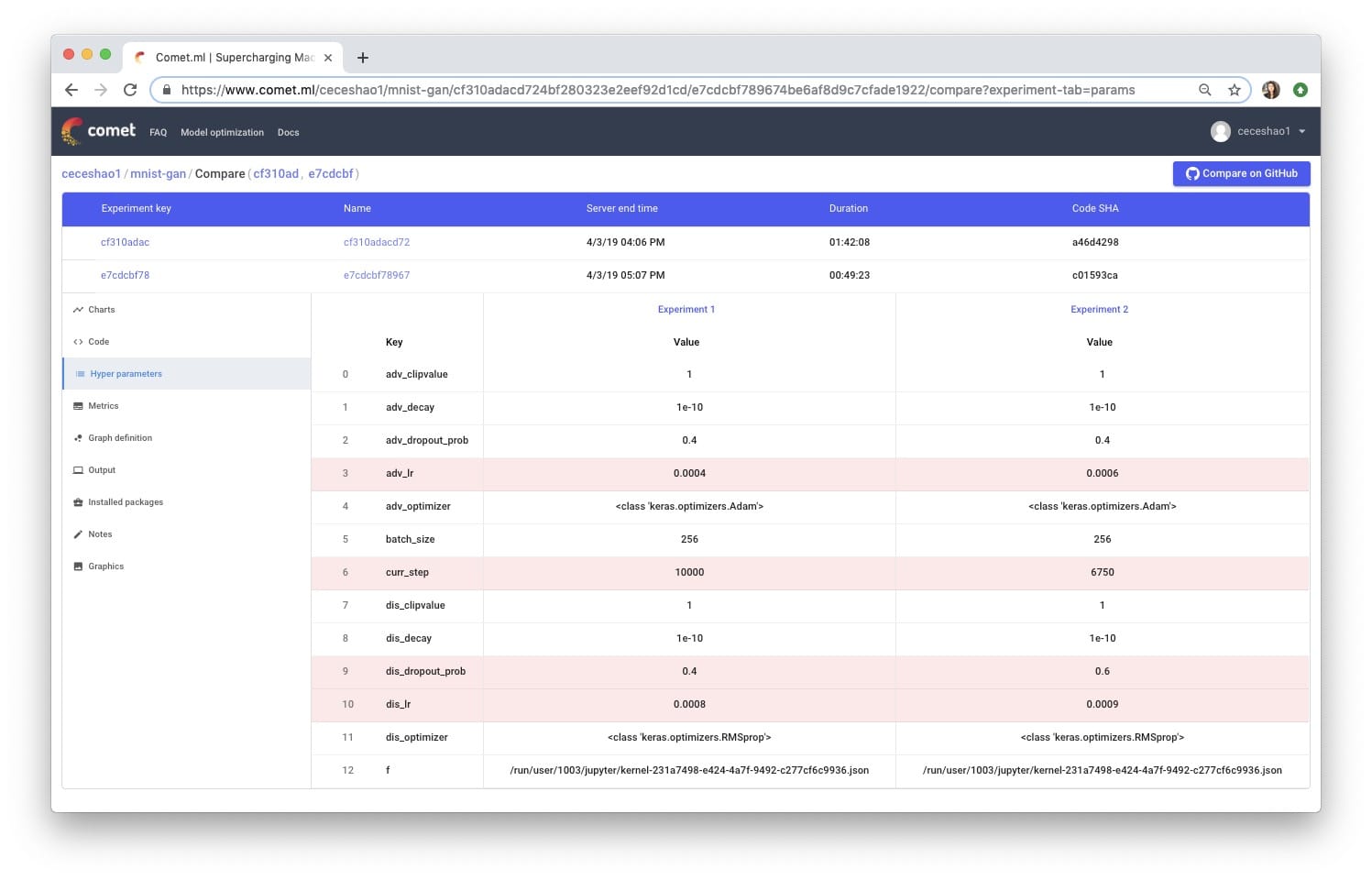
不幸的是,我们的调整没有改善模型的性能!事实上,它产生了一些时髦的输出:

这就是本教程的内容!如果您喜欢这篇文章,请随时与可能觉得有用的朋友分享😎
本文转自towardsdatascience,原文地址

Comments