

识别莫奈的绘画比绘制莫奈的绘画更容易。与判别模型(处理数据)相比,生成模型(创建数据)被认为更难。训练GAN也很难。本文是GAN系列的一部分,我们将研究为什么培训如此难以捉摸。通过这项研究,我们了解了一些驱动许多研究人员方向的基本问题。我们将研究一些分歧,以便我们知道研究可能会去哪里。在研究这些问题之前,让我们快速回顾一下GAN方程。
GAN
GAN 使用正态或均匀分布对噪声z进行采样,并利用深度网络生成器G来创建图像x(x = G(z))。
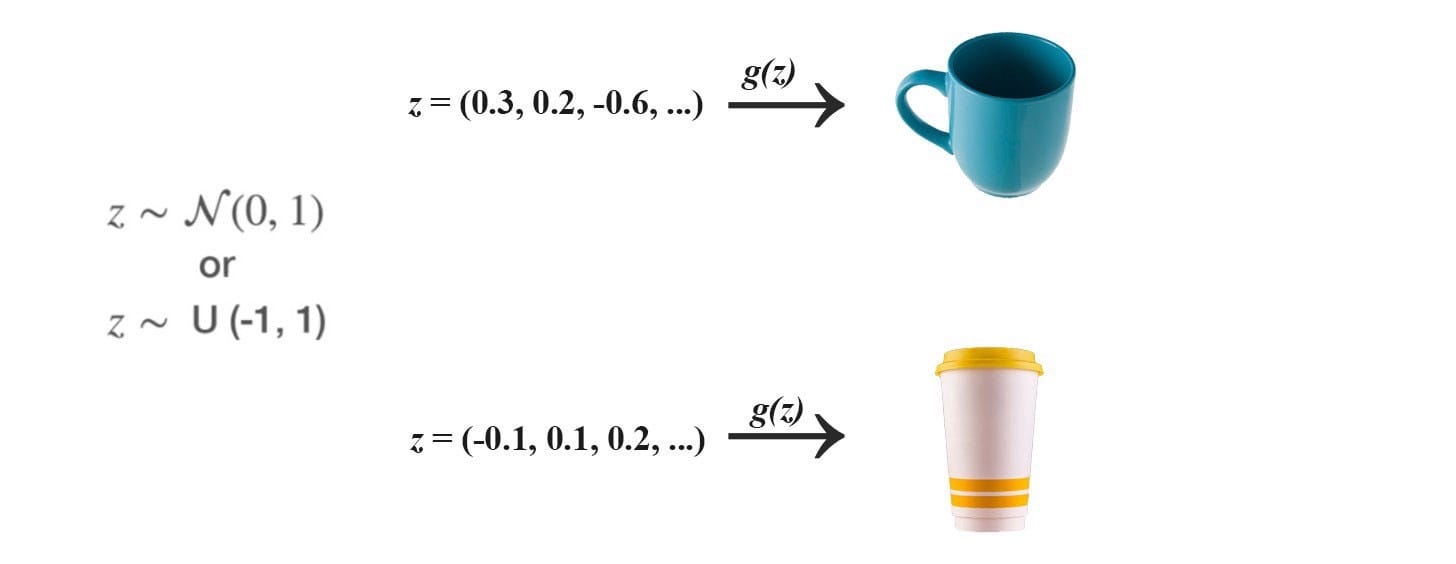
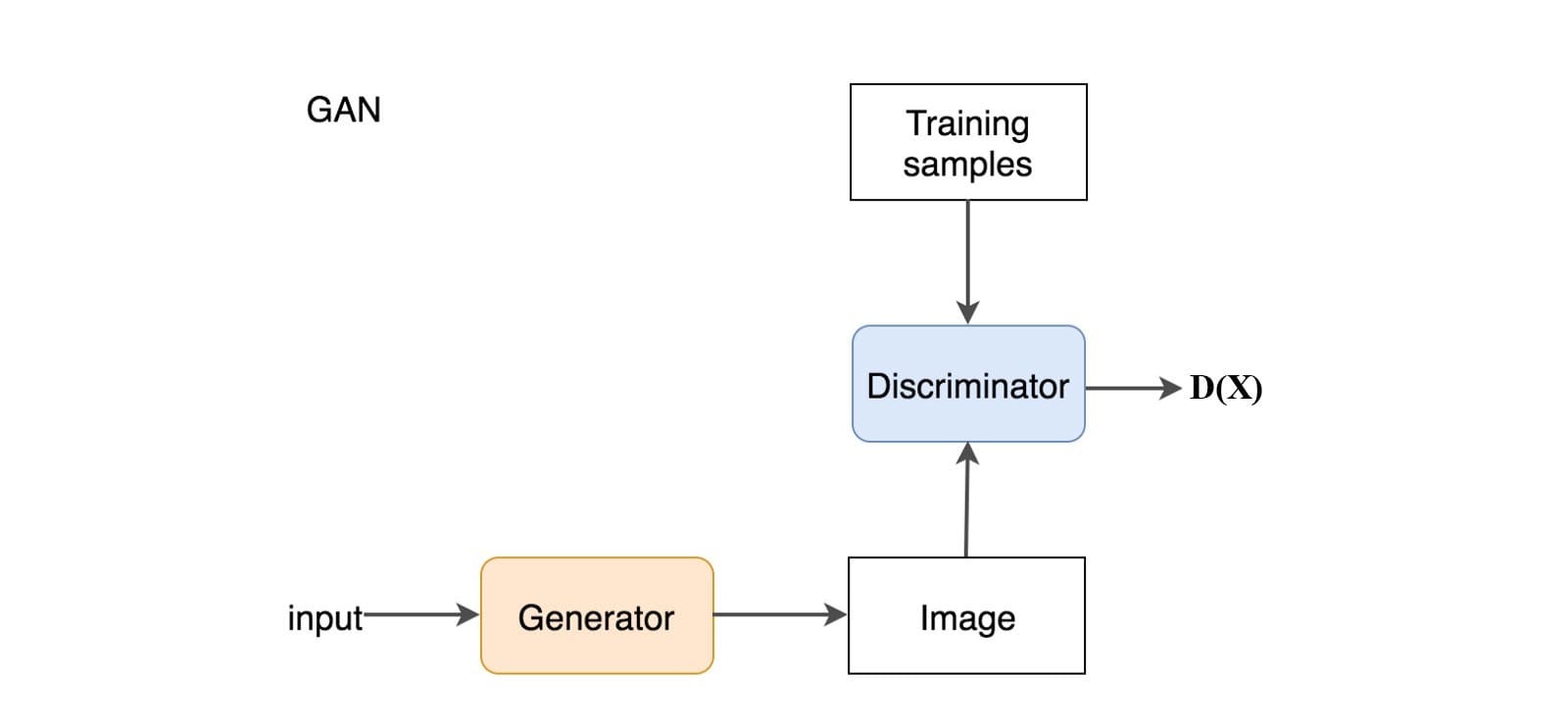
在GAN中,我们添加一个鉴别器来区分鉴别器输入是真实的还是生成的。它输出一个值D(x)来估计输入是真实的机会。
目标函数和渐变
GAN被定义为具有以下目标函数的极小极大游戏。
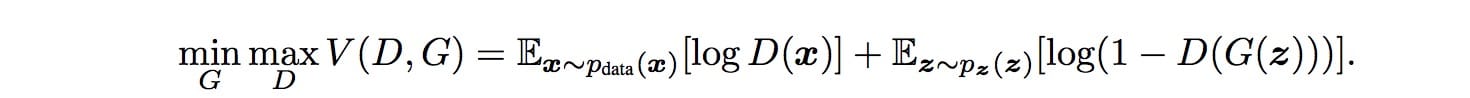
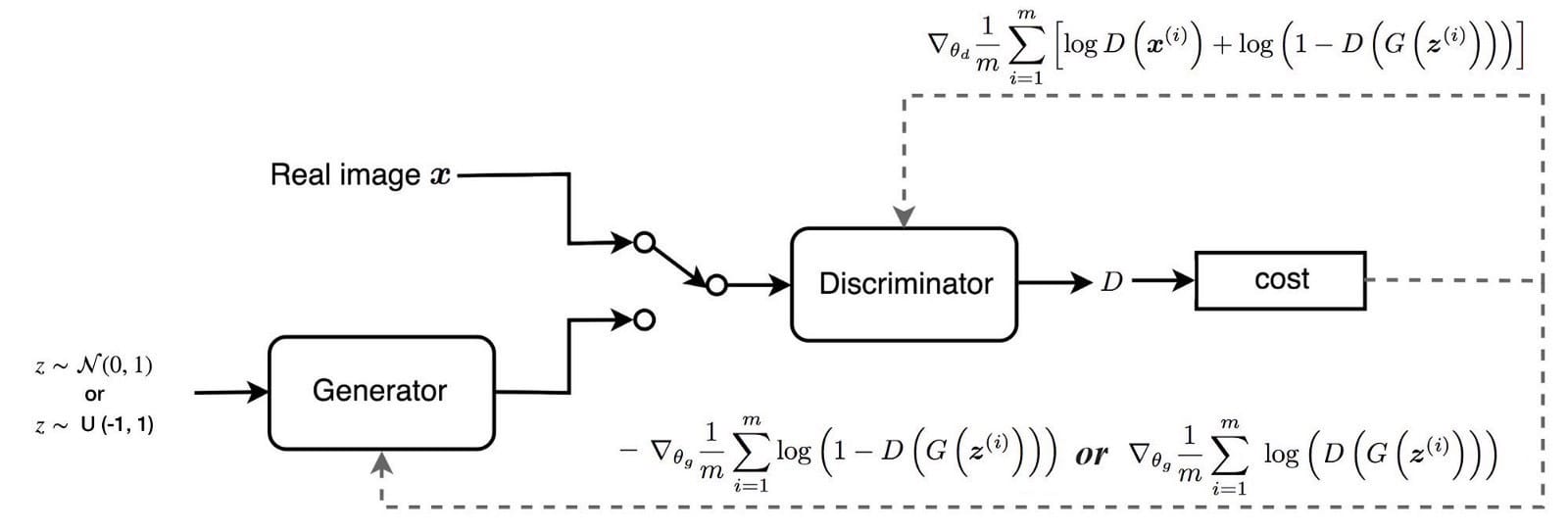
下图总结了我们如何使用相应的梯度训练鉴别器和发生器。
GAN问题
许多GAN型号存在以下主要问题:
- 不收敛:模型参数振荡,不稳定,永不收敛,
- 模式崩溃:发生器坍塌,产生有限的样品种类,
- 衰减梯度:鉴别器太成功,发电机梯度消失,什么都不学,
- 发电机和鉴别器之间的不平衡导致过度拟合,和
- 对超参数选择非常敏感。
模式
实际数据分布是多模式的。例如,在MNIST中,有10个主要模式,从数字“0”到数字“9”。以下样本由两个不同的GAN生成。顶行产生所有10种模式,而第二行仅产生单一模式(数字“6”)。当仅生成几种数据模式时,此问题称为模式折叠。

纳什均衡
GAN基于零和非合作游戏。简而言之,如果一个人赢了另一个人。零和游戏也称为minimax。你的对手希望最大化其行动,你的行动是最小化它们。在博弈论中,当鉴别器和发生器达到纳什均衡时,GAN模型收敛。这是下面的minimax方程的最佳点。
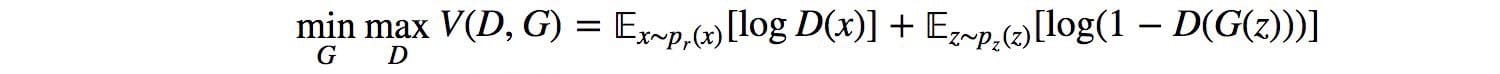
由于双方都想破坏其他球队,所以当一名球员无论对手可能做什么都不会改变其动作时,就会发生纳什均衡。考虑两个播放阿和乙其中控制值X和ÿ分别。玩家A希望最大化xy值,而B想要最小化它。

纳什均衡是x = y = 0。这是对手的行动无关紧要的唯一状态。这是任何对手的行动都不会改变比赛结果的唯一状态。
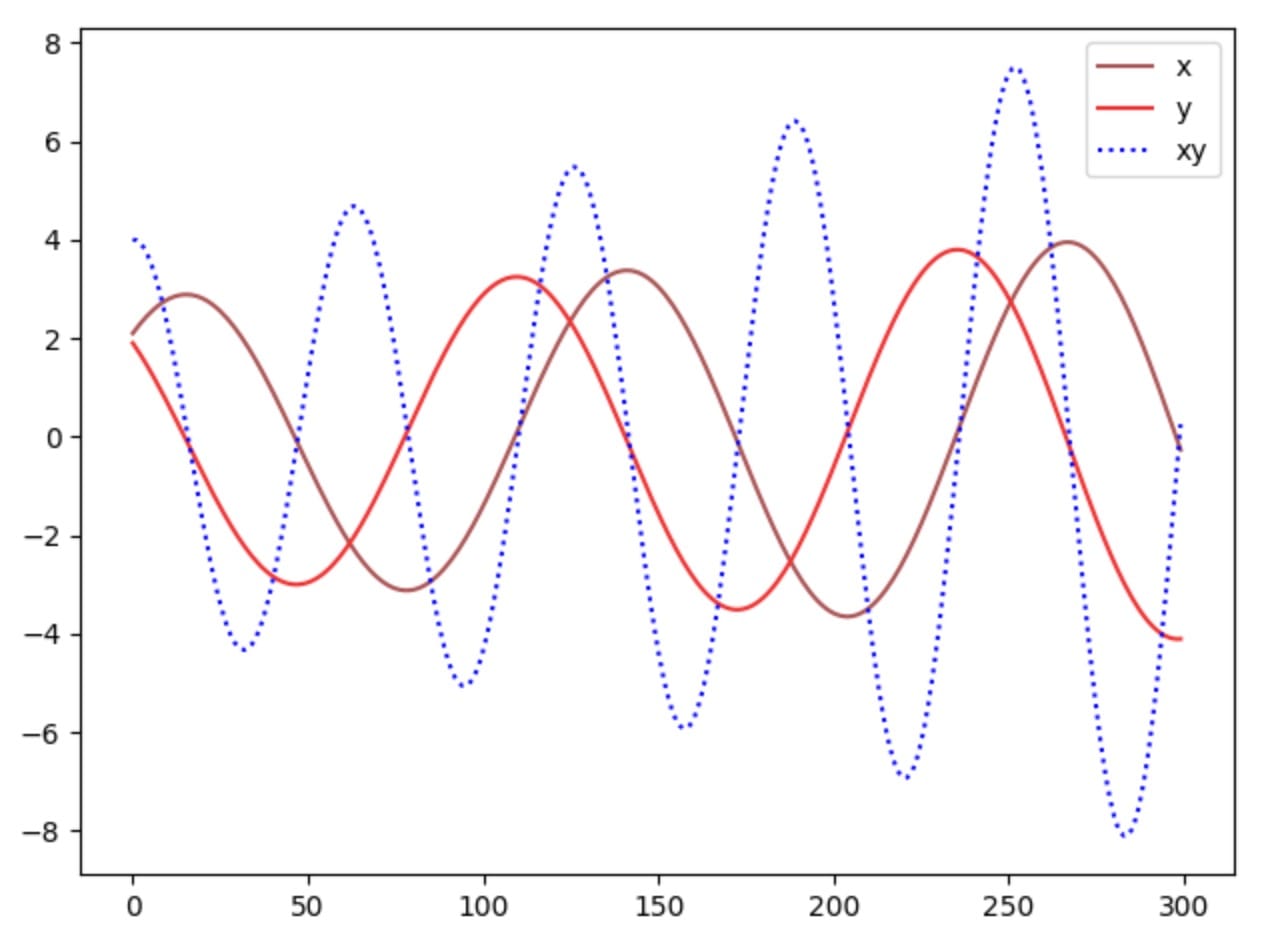
让我们看看我们是否可以使用梯度下降轻松找到纳什均衡。我们根据值函数V的梯度更新参数x和y。

其中α是学习率。当我们针对训练迭代绘制x,y和xy时,我们意识到我们的解决方案没有收敛。
如果我们提高学习率或更长时间训练模型,我们可以看到参数x,y在大摆动时不稳定。
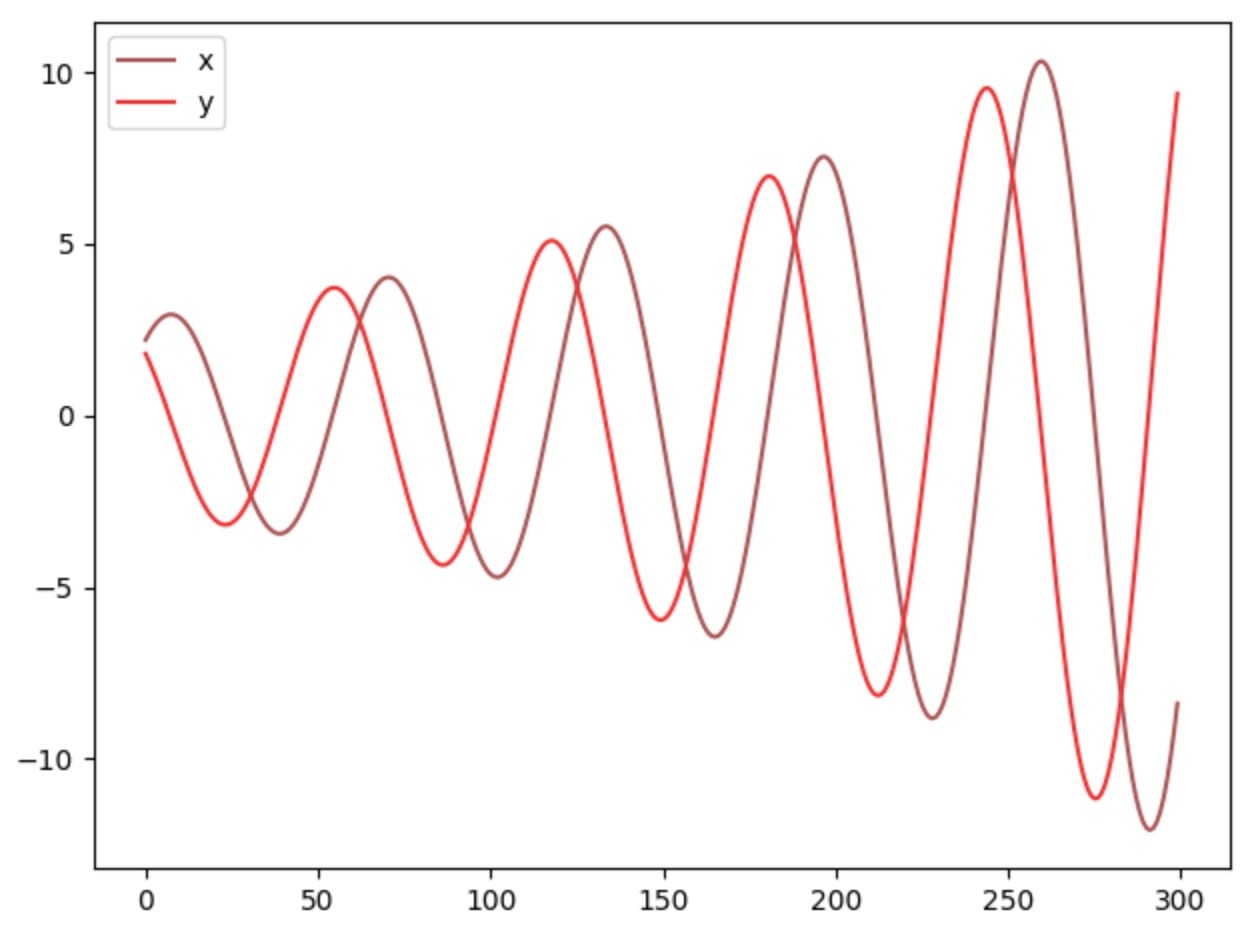
我们的例子是一个很好的展示,一些成本函数不会与梯度下降收敛,特别是对于非凸游戏。我们也可以直观地看待这个问题:你的对手总是对你的行为采取对策,这使得模型更难以收敛。
在极小极大游戏中,使用梯度下降可能无法收敛成本函数。
KL-Divergence的生成模型
为了理解GAN中的收敛问题,我们将首先研究KL-divergence和JS-divergence。在GAN之前,许多生成模型创建了最大化最大似然估计MLE的模型θ 。即找到最适合训练数据的最佳模型参数。

这与最小化KL-发散KL(p,q)(证明)相同,其测量概率分布q(估计分布)如何偏离预期概率分布p(实际分布)。

KL-发散不是对称的。
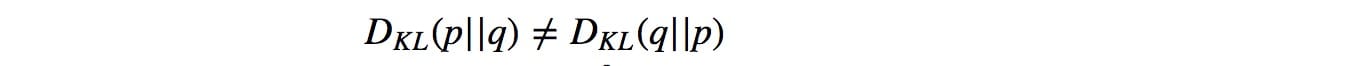
对于 p(x)→0的区域, KL(x)下降到 0。例如,在右下图中,红色曲线对应于 D(p,q)。降至当零 X> 2,其中 p接近0。
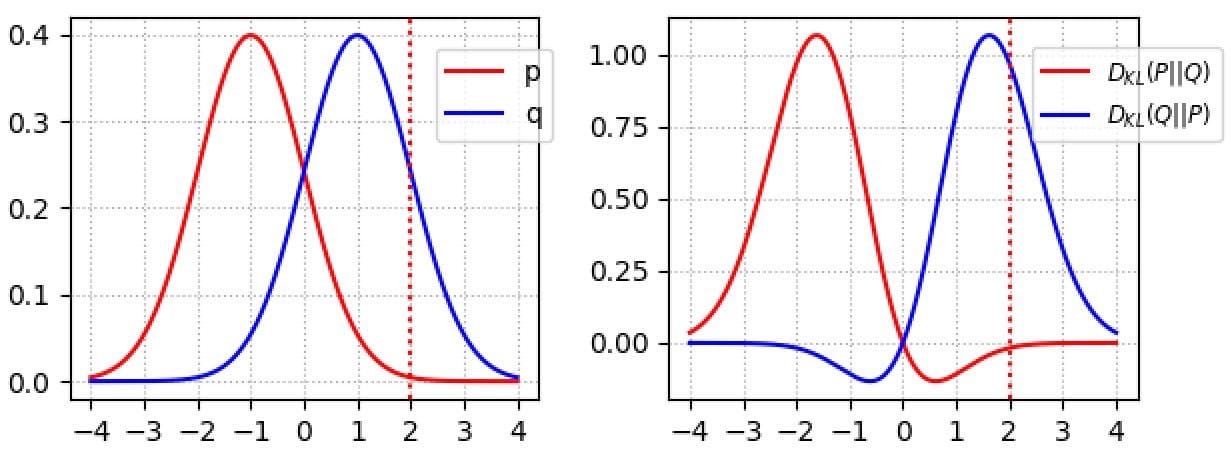
有什么含义?如果发生错过某些图像模式,则KL-发散DL(p,q)惩罚发生器:惩罚高,其中p(x)> 0但q(x)→0。然而,一些图像看起来不真实是可以接受的。当p(x)→0但q(x)> 0时,惩罚很低。(质量较差但样品更多样)
另一方面,如果图像看起来不真实,则反向KL-发散DL(q,p)惩罚发生器:如果p(x)→0但q(x)> 0则高惩罚。但它探讨了较少的变化:如果q(x)→0但p(x)> 0则低惩罚。(质量更好但样品更少样)
一些生成模型(除GAN之外)使用MLE(aka KL-divergence)来创建模型。最初认为KL-发散导致较差的图像质量(模糊图像)。但要注意的是,一些经验实验可能会对这一说法提出异议。
JS-发散
JS-divergence定义为:
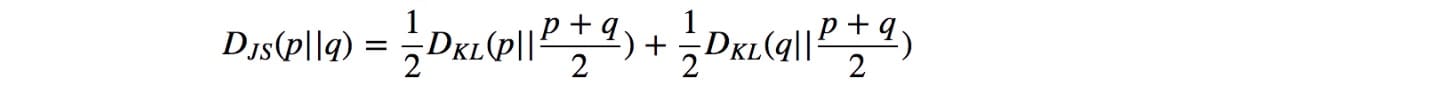
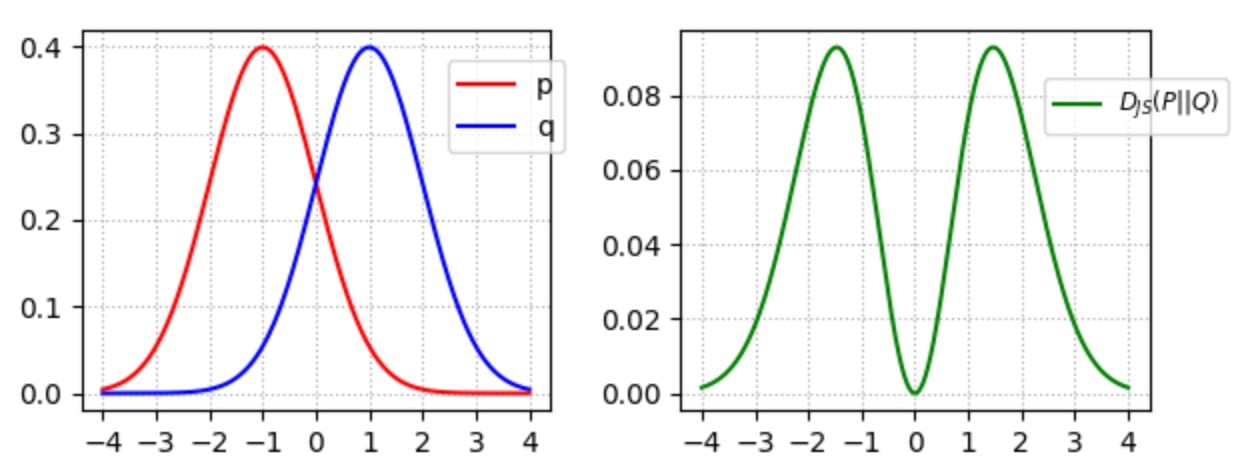
JS-分歧是对称的。与KL-divergence不同,它会严重惩罚糟糕的图像。(当p(x)→0且q(x)> 0时)在GAN中,如果鉴别器是最优的(在区分图像中表现良好),则生成器的目标函数变为(证明):
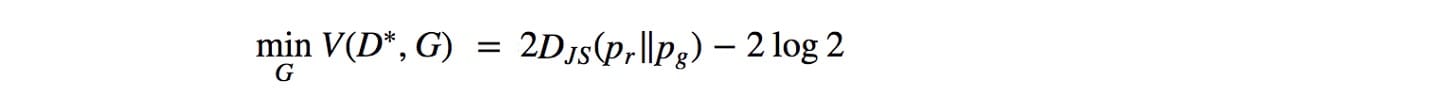
因此优化生成器模型被视为优化JS分歧。在实验中,与使用KL-发散的其他生成模型相比,GAN产生更好的图像。按照上一节中的逻辑,早期的研究推测,优化JS-发散而不是KL-发散,可以创建更好但不太多样化的图像。然而,一些研究人员已经收回了这些说法,因为使用MLE的GAN实验产生的图像质量相似但仍然存在图像多样性问题。但是,在研究GAN训练中JS-Divergence的弱点时,已经做了很多努力。无论辩论如何,这些作品都很重要。因此,接下来我们将深入探讨JS分歧的问题。
JS-Divergence中消失的渐变
回想一下,当鉴别器是最优的时,发生器的目标函数是:
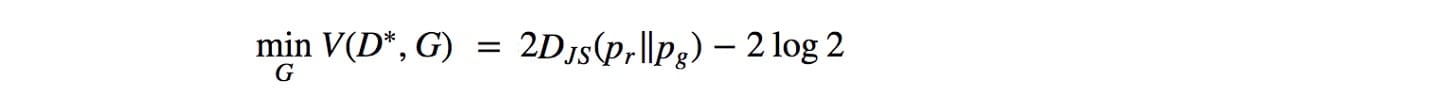
发生了JS-发散梯度什么当数据分布q发电机的图像并不与地面真相匹配p为实像。让我们考虑一个例子,其中p和q是高斯分布的,p的平均值是零。让我们用不同的方法考虑q来研究JS(p,q)的梯度。
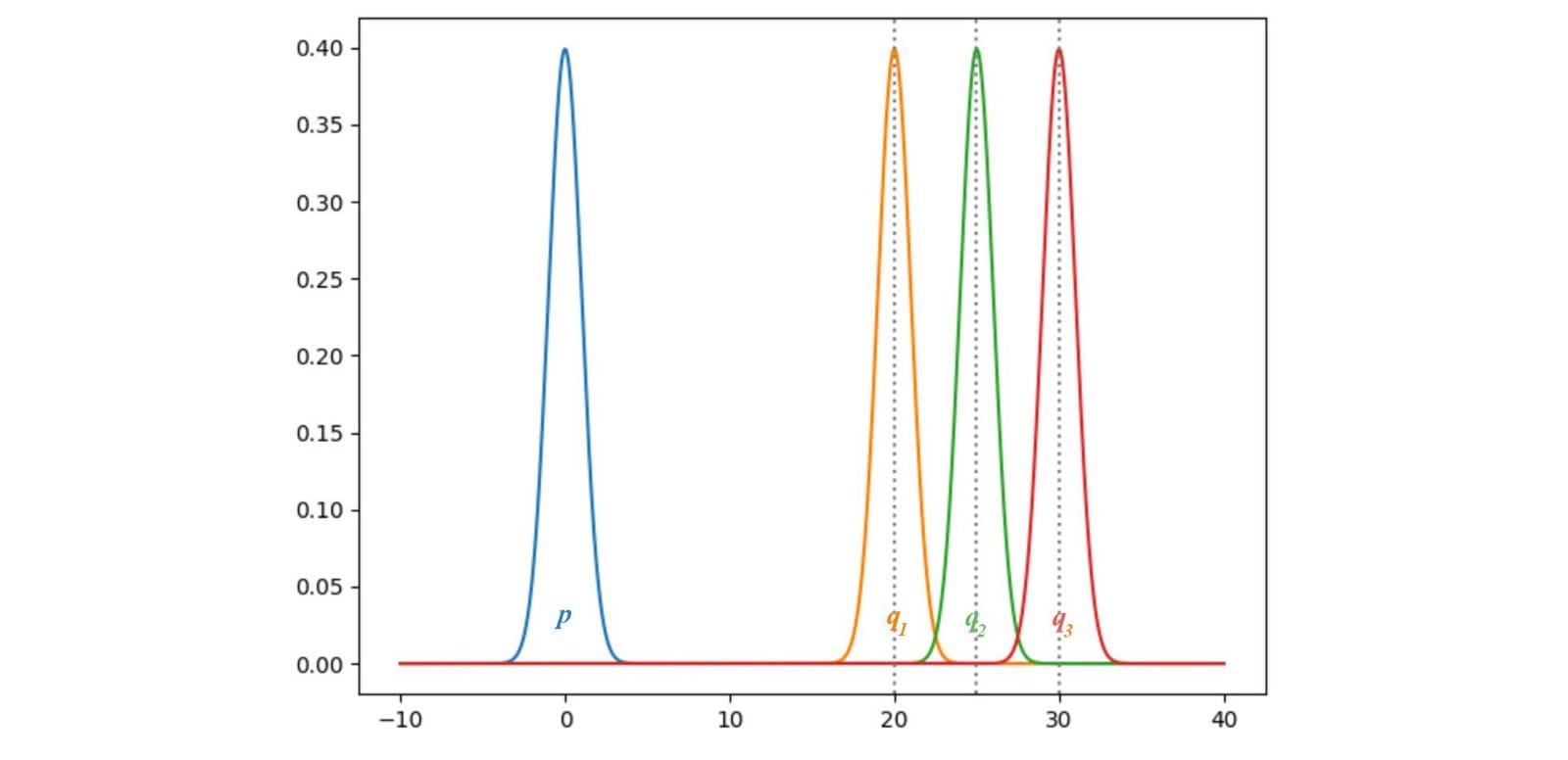
这里,我们绘制p和q之间的JS-发散JS(p,q),其中q的范围从0到30.如下所示,JS-发散的梯度从q1消失到q3。当这些地区的成本饱和时,GAN发电机将学会极其缓慢。特别是在早期训练中,p和q是非常不同的,并且发生器学习非常慢。
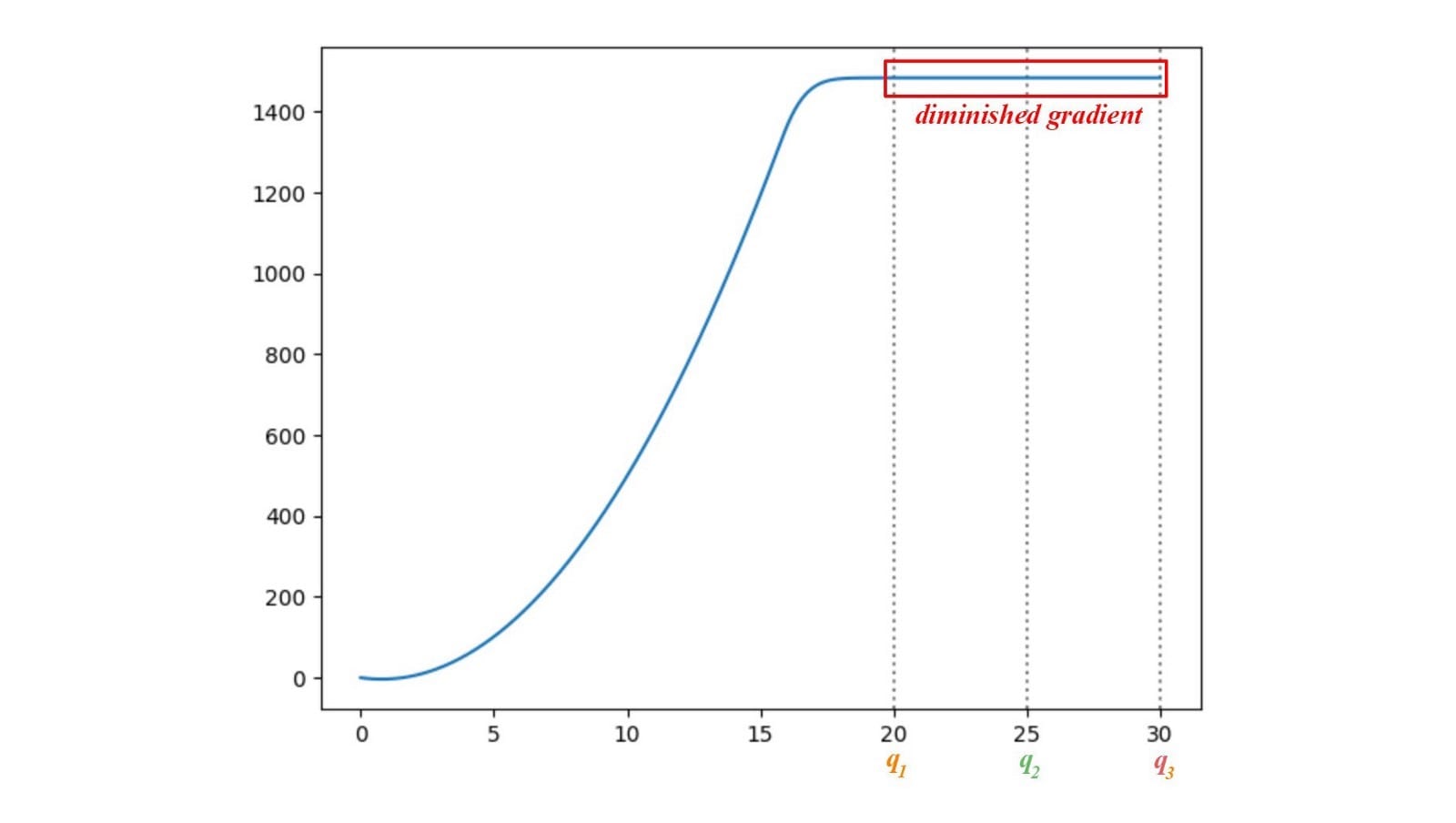
不稳定的渐变
由于梯度消失,原始GAN论文提出了另一种成本函数来解决梯度消失问题。

根据Arjovsky的另一篇研究论文,相应的梯度是:
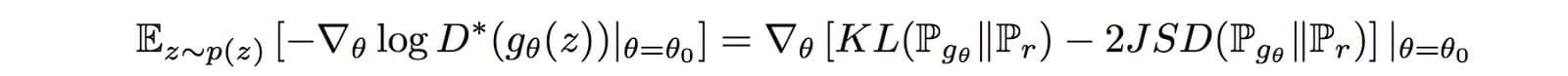
它包括一个反向 KL-发散项,Arjovsky使用它来解释为什么GAN与基于KL-发散的生成模型相比具有更高的质量但更少的图像。但同样的分析声称梯度波动并导致模型不稳定。为了说明这一点,Arjovsky冻结发电机并持续训练判别器。随着更大的变体,发电机的梯度开始增加。
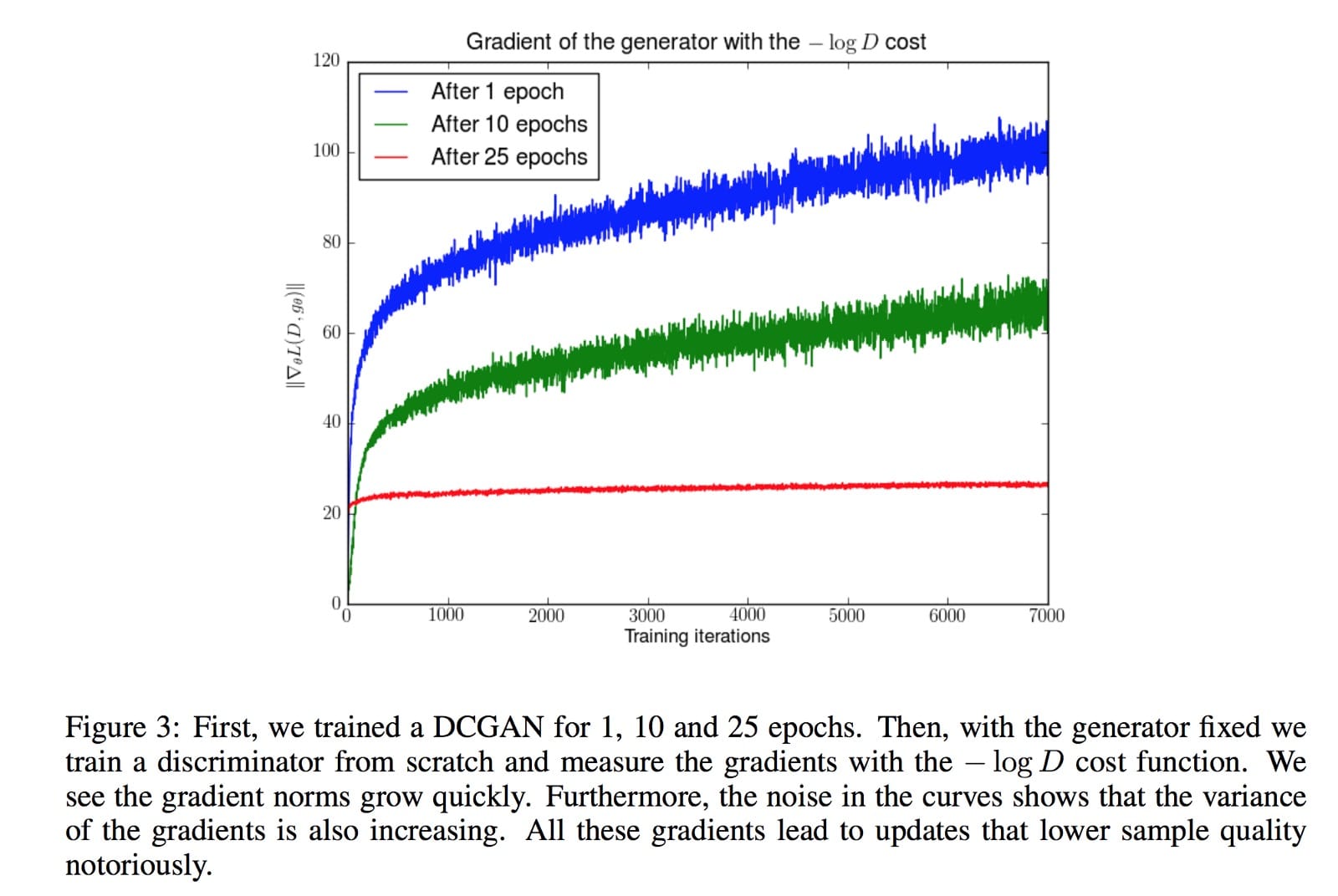
上面的实验不是我们训练GAN的方式。然而,在数学上,Arjovsky显示第一个GAN发生器的目标函数具有消失的梯度,而替代成本函数具有波动的梯度,导致模型的不稳定性。自最初的GAN论文以来,寻找新的成本函数,如LSGAN,WGAN,WGAN-GP,BEGAN等都有淘金热……有些方法基于新的数学模型,其他方法基于直觉通过实验备份。目标是找到具有更平滑和非消失梯度的成本函数。
然而,2017年谷歌脑论文“GAN创建平等?”声称最后,我们没有发现任何经过测试的算法始终优于原始算法的证据。
如果任何新提出的成本函数在提高图像质量方面取得了巨大成功,我们就不会有这种争论。关于Arjovsky数学模型中原始成本函数的世界末日图片也没有完全实现。但我会谨慎地提醒读者过早宣布成本函数并不重要。我可以在这里找到我对Google Brain论文的看法。我的看法是什么?训练GAN很容易失败。而不是在开始时尝试许多成本函数,首先调试您的设计和代码。接下来尝试调整超参数,因为GAN模型对它们很敏感。在随机尝试成本函数之前这样做。
为什么模式在GAN崩溃?
模式崩溃是GAN中最难解决的问题之一。彻底崩溃并不常见,但经常发生部分崩溃。下面带有相同下划线颜色的图像看起来相似,模式开始折叠。

让我们看看它是如何发生的。GAN生成器的目标是创建可以最大程度地欺骗鉴别器D的图像。

但是让我们考虑一个极端情况,即G在没有更新D的情况下进行广泛训练。生成的图像将收敛以找到最佳图像x *,该图像最愚弄D,从鉴别器角度来看最逼真的图像。在这个极端情况下,x *将独立于z。
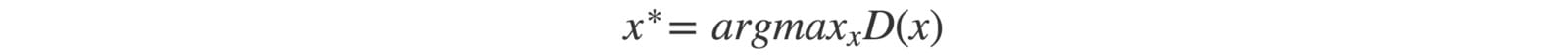
这是坏消息。模式折叠为单点。与z相关的梯度接近零。
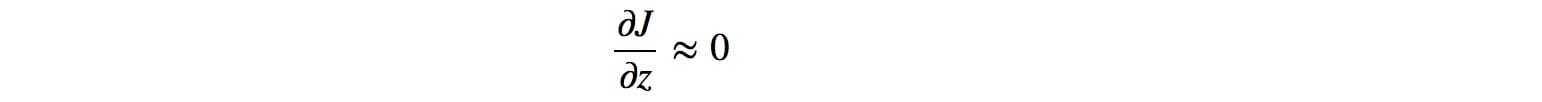
当我们在鉴别器中重新开始训练时,检测生成图像的最有效方法是检测这种单一模式。由于发生器已经对z的影响不敏感,因此来自鉴别器的梯度可能会将单点推到下一个最脆弱的模式。这不难发现。发电机在训练中产生这种不平衡的模式,这会降低其检测其他模式的能力。现在,两个网络都过度装配,以利用短期对手的弱点。这变成了猫捉老鼠的游戏,模型不会收敛。
在下图中,Unroll GAN设法生成所有8种预期的数据模式。第二行显示另一个GAN,当鉴别器赶上时,模式折叠并旋转到另一个模式。
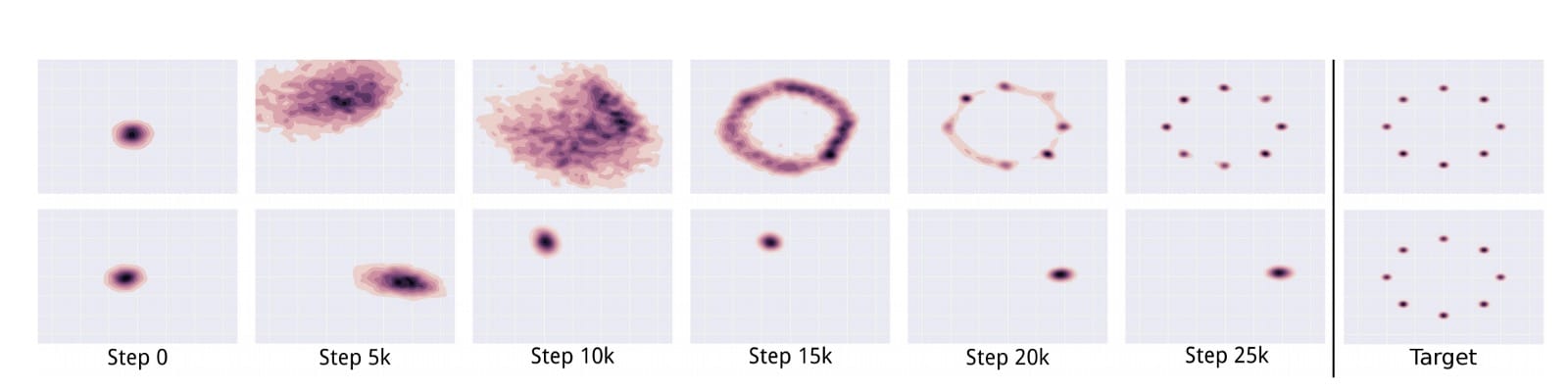
在训练期间,不断更新鉴别器以检测对手。因此,发电机不太可能过度装配。在实践中,我们对模式崩溃的理解仍然有限。我们上面的直观解释可能过于简单了。通过经验实验开发并验证了缓解方法。然而,GAN训练仍然是一个启发式过程。部分崩溃仍然很常见。
但模式崩溃并非都是坏消息。在使用GAN的样式传输中,我们很乐意将一个图像转换为一个好的图像,而不是找到所有变体。实际上,局部模式崩溃的专业化有时会产生更高质量的图像。但模式崩溃仍然是GAN要解决的最重要问题之一。
超参数和培训
如果没有好的超参数,没有成本函数可以工作,调整它们需要时间和耐心。新的成本函数可能会引入具有敏感性能的超参数。超参数调整需要耐心。如果不花时间在超参数调整上,任何成本函数都无法工作。
鉴别器和发生器之间的平衡
非收敛和模式崩溃通常被解释为鉴别器和发生器之间的不平衡。显而易见的解决方案是平衡他们的训练以避免过度拟合。然而,很少取得进展,但并非因为缺乏尝试。一些研究人员认为,这不是一个可行或理想的目标,因为良好的鉴别器可以提供良好的反馈。因此,一些注意力转移到具有非消失梯度的成本函数。
成本与图像质量
在判别模型中,损失测量预测的准确性,并使用它来监控培训的进度。但是,与对手相比,GAN的损失衡量了我们的表现。通常,发电机成本增加但图像质量实际上正在提高。我们回过头来手动检查生成的图像以验证进度。这使得模型比较更难以导致在单次运行中挑选最佳模型的困难。它还使调整过程复杂化。
进一步阅读
现在您听到了问题,您可能希望听到解决方案。我们提供两种不同的文章。第一个提供解决方案的关键摘要。GAN – 对GAN歹徒的综合评论(第二部分)
本文研究了GAN研究在改进GAN方面的动机和方向。通过在…media.com中查看它们
如果你想要更深入,第二个将有更深入的讨论:GAN – 改善GAN性能的方法与
其他深度网络相比,GAN模型在以下方面可能会受到严重影响。medium.com
如果你想进一步研究梯度和稳定性问题的数学模型,下面的文章将详细阐述它。但要注意,方程式可能看起来势不可挡。但是,如果你不害怕方程式,那么就可以对它们的一些主张提供很好的推理。GAN – GAN成本函数有什么问题?
我们努力为深度学习提供数学模型。但通常情况下,我们并没有成功,而是回到了…medium.com

Comments