

背景
本文是关于产品经理如何将机器学习融入其产品的更大型独立研究(见下文)中的一部分。它由Ryan Dingler和我自己在加州大学伯克利分校的MBA学习,在Vince Law的帮助下担任我们的指导老师。
该研究旨在了解产品经理如何设计,规划和构建支持ML的产品。为了达到这种理解,我们采访了各个技术公司的15位产品开发专家。在代表的15家公司中,14家公司的市值超过10亿美元,11家公开上市,6家是B2C,9家是B2B。
产品经理指导ML系列:
在开始机器学习之前
在确定机器学习(ML)可能有助于解决的问题之后,在与团队进行模型开发之前采取一些步骤是至关重要的。
根据我们的研究,大多数产品团队都遵循框架和评估ML问题的结构化流程。在这篇文章中,我们分享了这些学习中最重要的四个。
第1步:编写机器学习假设
有时,产品团队只是对他们期望实现的目标有一般意义,就可以开始他们的ML项目。这种非结构化方法的问题在于您将学习更少,并且不会为将来的用例创建框架。
如果没有一个确定的假设,你也会冒险增加风险(特别是对于较小的数据集),找到一个与你的目标变量相关的随机特征。这种相关性可能导致错误地认为随机特征在您的模型中是相关的,这可能导致模型在生产中概括不足。
一个合理的假设将包含以下所有部分:
- 改变你正在测试
- 期望的结果(高级别)
- 成功指标
- 型号输出(数字,标签,簇等)
- 目标
- 预测因子(高级)
例子假设
用ML改善Dropbox中的搜索排名[1。CHANGE]将允许用户找到正确的文件[2。结果]减少15%的时间[3。METRIC]。该模型将对每个可能的文件进行评分[4。MODEL OUTPUT]使用最近与用户共享的文件和最近查看的文件[6。PREDICTORS]预测用户最终选择的文件[5。TARGET]。
注意:如果跳过假设步骤,请务必小心。我们采访了一些没有事先建立实体假设的团队。他们的假设经常是:“X竞争对手已经这样做了。为什么我们不能?“即使您的竞争对手已经这样做了,我们仍然建议使用上述框架创建一个简单的假设。
第2步:我需要什么数据?

一般来说,您的数据需要提供信息并且与要解决的问题有关,但对于ML,数据也需要丰富。一个简单的经验法则是为线性模型提供至少数千行数据,为神经网络提供数十万行数据。如果您没有数据,请考虑获取正确数据的方法或坚持基于启发式的方法。
假设有足够的数据,数据仍然必须有一些模式。算法从这些模式中学习。在开始之前你不必知道精确的模式,但是你应该能够定性地表达它或者有一种直觉。
在Dropbox搜索示例中,产品团队可能直觉感觉最近与用户最终选择的文件相关的文件共享。但是,团队在开始项目之前不需要知道确切的关系或模式。
最后,请记住,即使数据量很大,也不是所有问题都可以解决。正如我们采访的一位社交媒体总理所说:“拥有数据并从中获取价值并不是一回事。”
关键点
- 数据需要帮助回答您的假设并具有一些假设模式。
- 即使使用正确的数据,您也可能最终得不到工作模型。
第3步:从启发式开始
ML模型需要大量数据,复杂,并且在准备好生产之前可能需要很长时间才能开发和测试。因此,在尝试ML之前,通常最好从一组简单的启发式开始。启发式规则提供了解决难题的捷径。
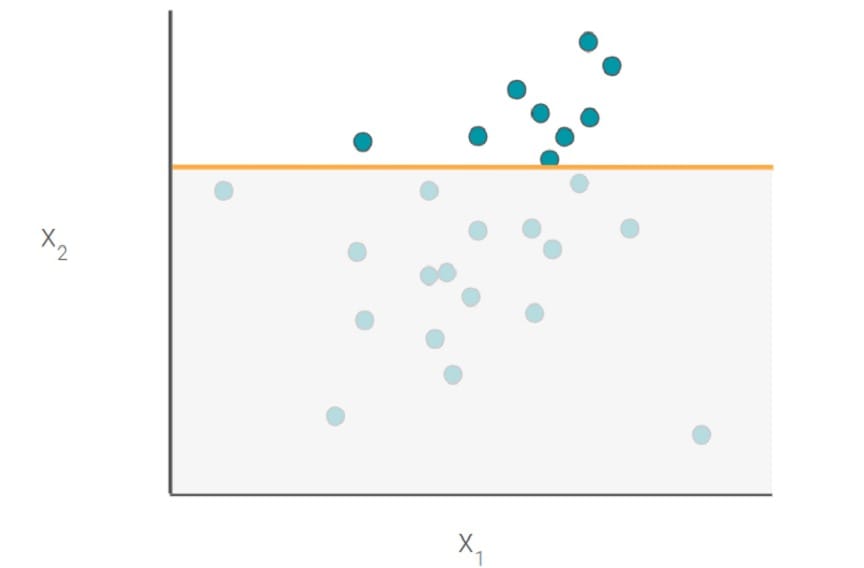
启发式构建速度快,实现起来相对简单,易于理解。这些规则也可以作为测试您的假设的捷径,而无需花费大量时间来完善模型。在某种程度上,启发式算法可以在构建全功能的ML模型之前充当原型工具。
在策划一个简单的新闻源时,如果您的假设的期望结果是增加用户参与度,那么这可以通过启发式来实现,该启发式表达用户的基本内容。例如,任何一小时超过五个的帖子都会出现在新闻源上。当然,这对于病毒式传播不是一个非常准确的代理,因此您可能希望在注释或共享的数量中包含额外的启发式方法。
在许多情况下,项目可能会停止一组简单的启发式(不需要ML)。通常,如果数据不足以满足ML,或者启发式方法简单,性能良好且易于维护,则情况就是如此。我们采访过的许多公司在他们的启发式过于复杂之后才开始考虑ML。当您尝试构建越来越多的相互依赖,重叠和个性化的启发式时,可能会发生并发症。
关键点
- 启发式扫描可以成为测试您的假设的一个很好的捷径。
- 如果您的启发式方法变得太复杂而无法维持或性能滞后,请考虑ML。
第4步:风险管理策略

从图像识别算法标记不恰当的东西到聊天机器人学习变得文化不合适,有很多ML模型出错的例子。我们采访过的许多公司都敏锐地意识到这些问题,并且他们使用风险管理技术来帮助减轻(而不是解决)这些问题。
黑名单
许多公司为可能被视为不良行为者的单词,短语,群组或组织维护黑名单。
如果您开始在Google搜索中输入“What fu”,自动填充结果可能是:“什么是Funk!乐队,“”什么是软糖,“和”未来是什么。“这个ML模型中没有四个字母的单词。Google不会在公司自动填充政策中填写被视为不当的字词或短语。另一个例子是Pinterest通过将搜索中的反疫苗接种相关帖子列入黑名单来制作新闻。
机器学习中的偏见
数据收集和解释的过程通常是有偏见的。许多公司使用内部数据培训他们的初始模型。这种方法很方便,但它存在问题。
例如,在费用报告中,您公司的人员收集的收据可能不代表您的客户在全球范围内收集的收据。这种数据收集偏差会降低您的模型的概括能力,并对类似于您的公司产生偏见。
排除与偏见相关的变量不是答案。许多产品团队都认为最好从模型中排除种族,性别或其他变量。亚马逊通过其自动化的简历筛选ML模型尝试了这一点,导致该算法偏向于女性。在许多数据集中,还有其他种族或性别代理。“有了足够丰富的数据,类成员资格将不可避免地被编码为其他功能。” -
处理这种偏见没有灵丹妙药。首先,在模型中加入类成员(性别,种族等)等功能,以帮助您衡量确实存在的偏见。一旦测量了偏差,您的解决方案可能取决于用例。在重新训练模型时,使用缓解技术,在训练后抵消偏差,甚至改变用户界面可能是有意义的。
关键点
本文转自 medium,原文地址

Comments