
在这篇文章中,我们将帮助你更好的理解监督学习、非监督学习和强化学习的定义的内涵,并从更广阔的视角中阐述它们与机器学习之间的联系。深入理解它们的内涵不仅有助于你在这一领域的文献中尽情的徜徉,更能引导你敏锐地捕捉到AI领域的发展和技术进步的气息。
Author Archive
不平凡的2018 | 机器人十大年度进展全回顾
在过去的2018年,各个领域的技术都有了巨大的进步,机器人领域同样如此。Science近日挑选了10款从实验室的原型研究到推动各领域进步的商业机器人,浓缩了过去一年机器人领域值得回顾的重要进展。
如何构建多快好省的“知识图谱即服务”?
知识图谱作为一种特殊的图数据,不仅人类可以识别且对机器友好。信息检索、问答系统、推荐系统、电子商务、金融风控,这些生活中常见的应用场景都离不开知识图谱的支持。如何构建一个“多快好省”的知识服务系统?微软亚洲研究院机器学习组的研究员们基于自己的经验,给出了他们的建议
文本挖掘 – Text mining

网络上存在大量的数字化文本,通过文本挖掘我们可以获得很多有价值的信息。
本文将告诉大家什么是文本挖掘,以及他的处理步骤和常用的处理方法。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是文本挖掘?
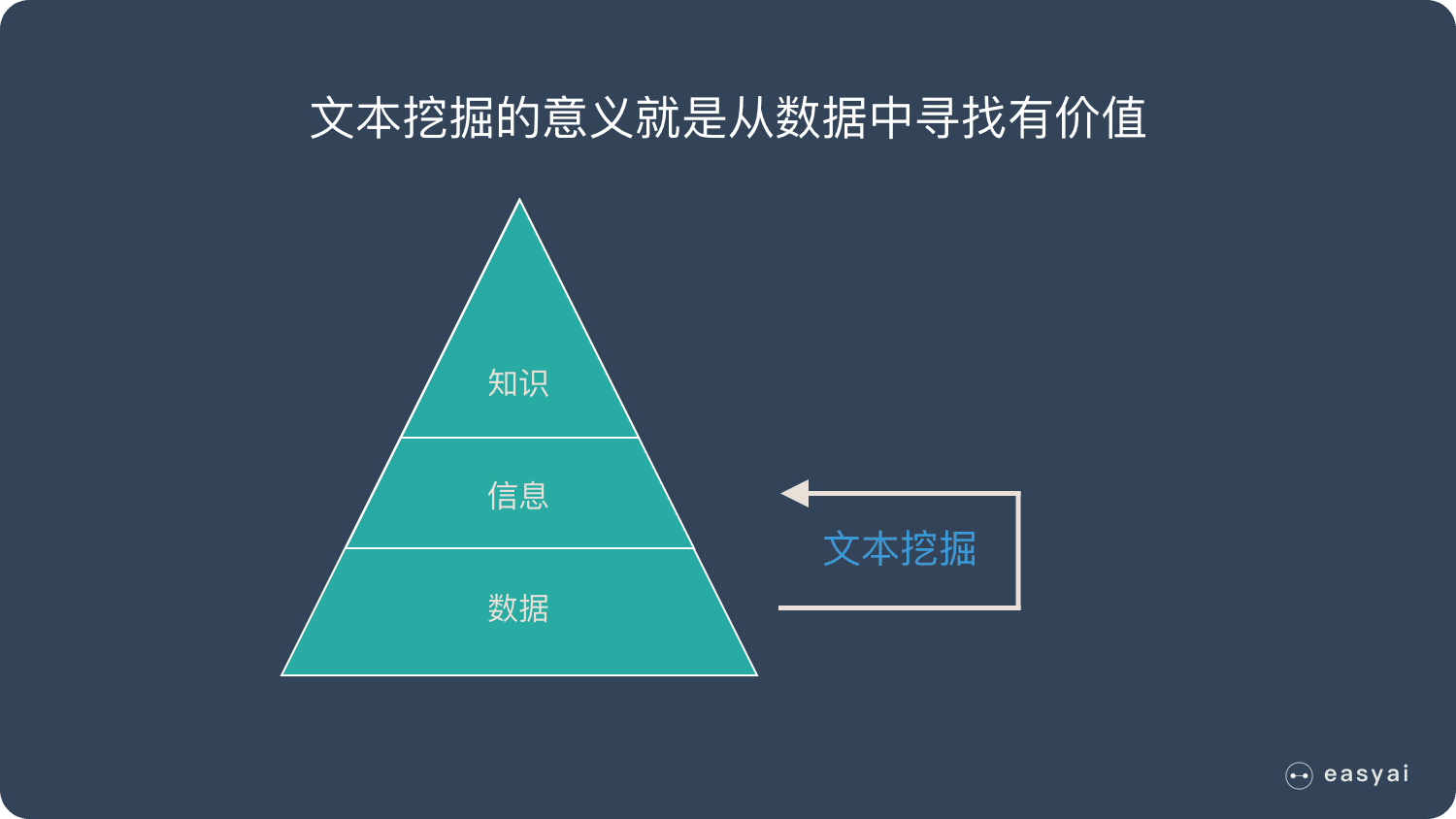
每到春节期间,买火车票和机票离开一线城市的人暴增——这是数据
再匹配这些人的身份证信息,发现这些人都是从一线城市回到自己的老家——这是信息
回老家跟家人团聚,一起过春节是中国的习俗——这是知识
上面的例子是显而易见的,但是在实际业务中,有很多不是那么显而易见的信息,比如:
- 每周末流量会有规律性的上升或者下降,这是为什么?
- 国庆长假,使用 iPad 购物比例比平时要高,这时为什么?
- ……
而文本挖掘的意义就是从数据中寻找有价值的信息,来发现或者解决一些实际问题。
文本挖掘的5个步骤
文本挖掘大致分为以下5个重要的步骤。

文本挖掘的5个步骤:
- 数据收集
- 文本预处理
- 数据挖掘和可视化
- 搭建模型
- 模型评估
7种文本挖掘的方法

关键词提取:对长文本的内容进行分析,输出能够反映文本关键信息的关键词。
文本摘要:许多文本挖掘应用程序需要总结文本文档,以便对大型文档或某一主题的文档集合做出简要概述。
聚类:聚类是未标注文本中获取隐藏数据结构的技术,常见的有 K均值聚类和层次聚类。更多见 无监督学习
文本分类:文本分类使用监督学习的方法,以对未知数据的分类进行预测的机器学习方法。
文本主题模型 LDA:LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。
观点抽取:对文本(主要针对评论)进行分析,抽取出核心观点,并判断极性(正负面),主要用于电商、美食、酒店、汽车等评论进行分析。
情感分析:对文本进行情感倾向判断,将文本情感分为正向、负向、中性。用于口碑分析、话题监控、舆情分析。
维基百科版本
文本挖掘,也称为文本数据挖掘,大致相当于文本分析,是从文本中获取高质量信息的过程。高质量信息通常是通过统计模式学习等手段设计模式和趋势而得出的。文本挖掘通常涉及构造输入文本的过程(通常解析,添加一些派生的语言特征和删除其他特征,然后插入到数据库中),在结构化数据中导出模式,最后评估和解释输出。文本挖掘中的“高质量”通常是指相关性,新颖性和兴趣的某种组合。典型的文本挖掘任务包括文本分类,文本聚类,概念/实体提取,粒度分类法的生成,情感分析,文档摘要和实体关系建模(即,命名实体之间的学习关系)。
文本分析涉及信息检索,词汇分析以研究词频分布,模式识别,标记 / 注释,信息提取,数据挖掘技术,包括链接和关联分析,可视化和预测分析。最重要的目标是通过应用自然语言处理(NLP)和分析方法将文本转换为数据进行分析。 典型的应用是扫描以自然语言编写的一组文档,并为文档集建模以用于预测分类目的,或者用提取的信息填充数据库或搜索索引。
扩展阅读
2018年10大机器学习开源项目
本期将为大家推荐 10 个机器学习开源项目,统计了过去一个月中 250 个机器学习开源项目,并从中选取了本期的 Top10。平均 1483 Stars。
BERT | Bidirectional Encoder Representation from Transformers
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 BERT?
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
从现在的大趋势来看,使用某种模型预训练一个语言模型看起来是一种比较靠谱的方法。从之前AI2的 ELMo,到 OpenAI的fine-tune transformer,再到Google的这个BERT,全都是对预训练的语言模型的应用。BERT这个模型与其它两个不同的是
- 它在训练双向语言模型时以减小的概率把少量的词替成了Mask或者另一个随机的词。我个人感觉这个目的在于使模型被迫增加对上下文的记忆。至于这个概率,我猜是Jacob拍脑袋随便设的。
- 增加了一个预测下一句的loss。这个看起来就比较新奇了。
BERT模型具有以下两个特点:
- 是这个模型非常的深,12层,并不宽(wide),中间层只有1024,而之前的Transformer模型中间层有2048。这似乎又印证了计算机图像处理的一个观点——深而窄 比 浅而宽 的模型更好。
- MLM(Masked Language Model),同时利用左侧和右侧的词语,这个在ELMo上已经出现了,绝对不是原创。其次,对于Mask(遮挡)在语言模型上的应用,已经被Ziang Xie提出了(我很有幸的也参与到了这篇论文中):[1703.02573] Data Noising as Smoothing in Neural Network Language Models。这也是篇巨星云集的论文:Sida Wang,Jiwei Li(香侬科技的创始人兼CEO兼史上发文最多的NLP学者),Andrew Ng,Dan Jurafsky都是Coauthor。但很可惜的是他们没有关注到这篇论文。用这篇论文的方法去做Masking,相信BRET的能力说不定还会有提升。
内容来自:【NLP】Google BERT详解 | [NLP自然语言处理]谷歌BERT模型深度解析
扩展阅读
当训练数据和测试数据不同时怎么办?
为了建立性能良好的机器学习(ML)模型,必须在来自相同目标分布的数据上训练模型并进行测试。然而,有时我们只能从目标分布中收集到有限数量的数据。这些数据可能不足以构建所需的训练/开发/测试集。
2种简单的方式缓解RNN的优化问题
在上一节(如何理解RNN?(理论篇))的课程我们介绍了循环神经网络的基本结构,同时这样的循环结构也会给优化带来一定的困难,本文主要介绍两种较为简单的方式来缓解RNN的优化问题
如何理解RNN?(理论篇)
带有循环结构的网络都可以被叫做循环神经网络(recurrent neural network),RNN可以非常有效的解决这个问题,从简单的理论上来说,它可以处理任意长度的序列,并且不需要提前将N固定住,灵活性更高。