

本文转载自公众号 读芯术,原文地址
为了建立性能良好的机器学习(ML)模型,必须在来自相同目标分布的数据上训练模型并进行测试。然而,有时我们只能从目标分布中收集到有限数量的数据。这些数据可能不足以构建所需的训练/开发/测试集。
与此同时,来自其他数据分布的类似数据可能随时可用。在这种情况下该怎么办?让我们对一些想法进行讨论吧!
一些背景知识
如果你还不熟悉基本的机器学习概念,你可以仔细阅读此版块,以便更好地理解本文内容:
· 训练集,开发集及测试集:注意,dev集也被称为validation或hold-on集。
· 偏差(欠拟合)和方差(过拟合)误差:这是对这些误差的一个非常简单的解释。
· 如何正确地拆分训练/开发/测试集。
场景
假设你正在构建一个狗狗图像分类器应用程序,其可用来确定某图像是否为狗。
该应用程序适用于农村地区的用户,他们可以通过移动设备拍摄动物的照片,以便应用程序为他们分类动物。
通过对目标数据分布的研究,我们发现图像大多是模糊的、低分辨率的,如下图所示:

你只能收集到8000张这样的图像,这还不足以构建训练/开发/测试集。假设你已确定至少需要100000张图像。
你想知道是否可以使用另一个数据集中的图像-以及你收集到的8000张图像-来构建训练/开发/测试集。
你意识到可以很容易地通过网络抓取来建立一个包含100000张或更多图像的数据集,这些图像的频率与我们需要的狗图像和非狗图像的频率类似。
但是,很明显这个web数据集来自不同的分布,其图像清晰且分辨率高,如:

如何构建训练/开发/测试集?
你不能只使用收集的8000张原始图像来构建训练/开发/测试集,因为它们不足以构成一个性能良好的分类器。通常,计算机视觉像其他自然感知问题(语音识别或自然语言处理)一样,需要大量的数据。
此外,你不能只用web数据集。分类器不能很好地处理用户的模糊图像,这与用于训练模型的高清晰度的web图像不同。所以,你需要做些什么?让我们考虑一些可能性。
一个可能的选项-数据洗牌(shufflig)
你可以做的是将两个数据集组合起来并对它们进行随机洗牌。然后,将生成的数据集拆分为训练/开发/测试集。
假设你决定按96:2:2%拆分成训练/开发/测试集,这个过程将类似于:

拆分完毕后,训练/开发/测试集将按要求来自相同的分布,如上图所示。
然而,这里有一个很大的缺点!
如果你查看开发集,在2000张图像中,平均只有148张图像来自目标分布。
这意味着在大多数情况下,你都在优化web图像分布(2000张图像中有1852张)的分类器——这并不是你想要的!
当根据测试集评估分类器的性能时,情况类似。所以,该方法并不太适合用来分割训练/开发/测试集。
一个更好的选择
另一种选择是使开发/测试集来自目标分布数据集,训练集来自web数据集。
假设你仍像以前一样按照96:2:2%拆分成训练/开发/测试集。每个开发/测试集包含2000张图像-来自目标数据集-其余图像将被分到训练集,如下图所示:
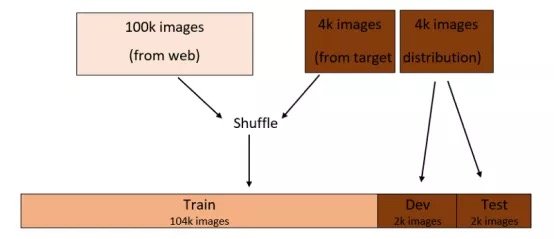
通过此拆分,你将优化分类器,使其在目标分布上表现良好,这正是你所关心的。这是因为开发集的图像仅来自目标分布。
但是,训练分布现在不同于开发/测试分布。这意味着在大多数情况下,你都是在web图像上训练分类器。因此,优化模型将花费越来越多的时间。
更重要的是,相对于训练集上的误差,你将无法轻松地判断开发集上的分类器误差是方差误差,数据不匹配误差,或是两者都有。
让我们更详细地考虑这个问题,看看我们能做些什么。
方差与数据不匹配
考虑上面第二个选项中的训练/开发/测试集的拆分。简单起见,假设人为误差为零。
另外,假设你发现训练误差为2%,开发误差为10%。这两个误差之间8%的误差中有多少是由于两个数据集之间数据不匹配造成的(假定它们来自不同的分布)?而模型的方差(过拟合)是多少?我们不知道。
让我们修改训练/开发/测试的拆分。取出训练集中的一小部分,称之为“桥”集。桥集不会被用于训练分类器,而是一个独立的集合。这种拆分会产生4个集合,这四个集合属于两个数据分布,如下所示:

方差
通过这种拆分,我们假设你发现训练和开发误差分别是2%和10%,发现桥集的误差是9%,如下所示:

现在,训练集误差和开发集误差之间的8%的误差有多少是方差误差?有多少是数据不匹配误差?
很简单!答案是7%的方差误差和1%的数据不匹配误差。但是为什么呢?
这是因为桥集和训练集是来自相同的分布,它们之间的误差差是7%。这意味着分类器在训练集上过拟合。这说明我们现在有一个高方差问题。
数据不匹配误差
现在,我们假设你发现桥集的误差达到了3%,其余的和之前一样,如下所示:

训练集和开发集之间8%的误差中有多少是方差误差?有多少数据不匹配误差?
答案是1%的方差误差,7%的数据不匹配误差。为什么?
这一次,是因为如果分类器来自相同的分布(如桥集),那么它在以前从未见过的数据集上表现良好。如果它来自不同的分布,比如开发集,那么它的性能就很差。因此,我们有一个数据不匹配的问题。
减少方差是机器学习中一项常见的任务。例如,你可以用正则化方法(regularization methods),或者分配一个更大的训练集。
减少数据不匹配误差是一个更有趣的问题,下面我们就来讨论一下。
缓解数据不匹配
为了减少数据不匹配误差,你需要以某种方式将开发/测试数据集(目标分布)并入训练集。
从目标分布中收集更多数据添加到训练集常常是最佳选择。但是,如果这不可行的话(正如我们在讨论开始时假设的那样),你可以尝试以下方法。
误差分析
分析开发集上的误差以及这些误差与训练集上误差的不同之处可以为解决数据不匹配问题提供思路。
例如,如果发现开发集上的许多误差发生在动物图像的背景为岩石的情况下,可以通过在训练集和中添加具有岩石背景的动物图像来减轻这些误差。
人工数据合成
将开发/测试集的特性合并到训练集的另一种方法时合成具有类似特性的数据。
例如,我们之前提到过,我们开发/训练集中的图像大多是模糊的,而我们的训练集大多是由网络上的清晰图像构成的。可以人为地将训练集中的图像模糊化,使其更类似于开发/测试集,如下所示:

然而,这里有一个重要的注意点!
最终可能会因为你所做的人工特征使分类器过拟合。
在我们的示例中,由某些数学函数人为生成的模糊可能只是目标分布图像中存在的模糊的一个子集。
换言之,目标分布中的模糊可能是由多种原因造成的。例如,雾,低分辨率相机,物体的移动都可能是原因。但是合成的模糊可能并不代表所有的这些原因。
一般来说,当为训练集(该训练集可用于解决任何类型的问题,例如计算机视觉或语音识别)进行合成数据时,在建立该合成数据集的模型时,可能会发生过度拟合。
在人眼看来,这个数据集看起来足够代表目标分布。但实际上,它只是目标分布的一小部分。所以,在使用这个强大的工具-数据合成时请记住这一点。
总结
在开发一个机器学习模型时,理想情况下,训练/开发/测试数据集都应该来自同一个数据分布,即当用户使用该模型时将遇到的数据分布。
但是,有时无法从目标分布中收集到足够的数据来构建训练/开发/测试集,而其他分布中的类似数据却很容易得到。
在这种情况下,开发/测试集应该来自目标分布,而来自其他分布的数据可以被用于构建(大多数的)训练集。可以使用数据匹配技术来缓解训练集和开发/测试集之间的数据分布差异。

Comments