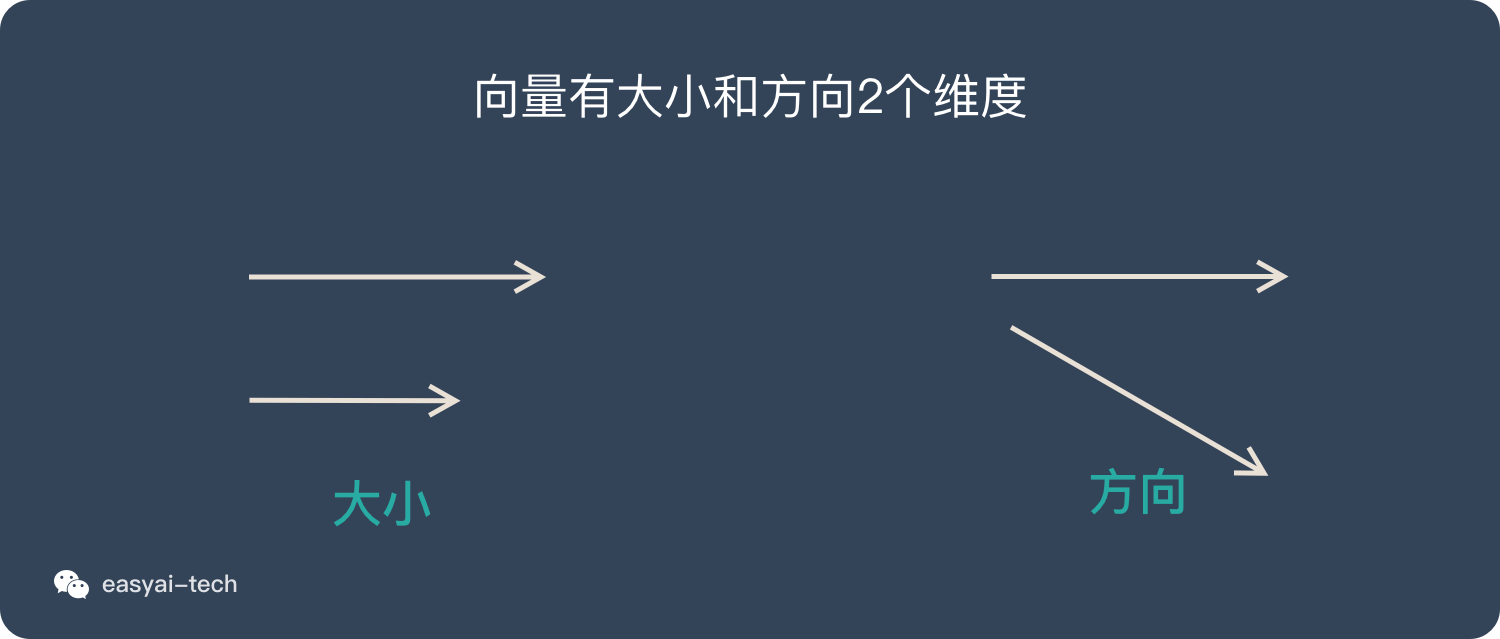
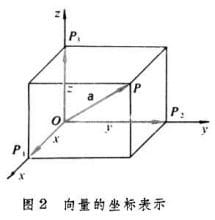
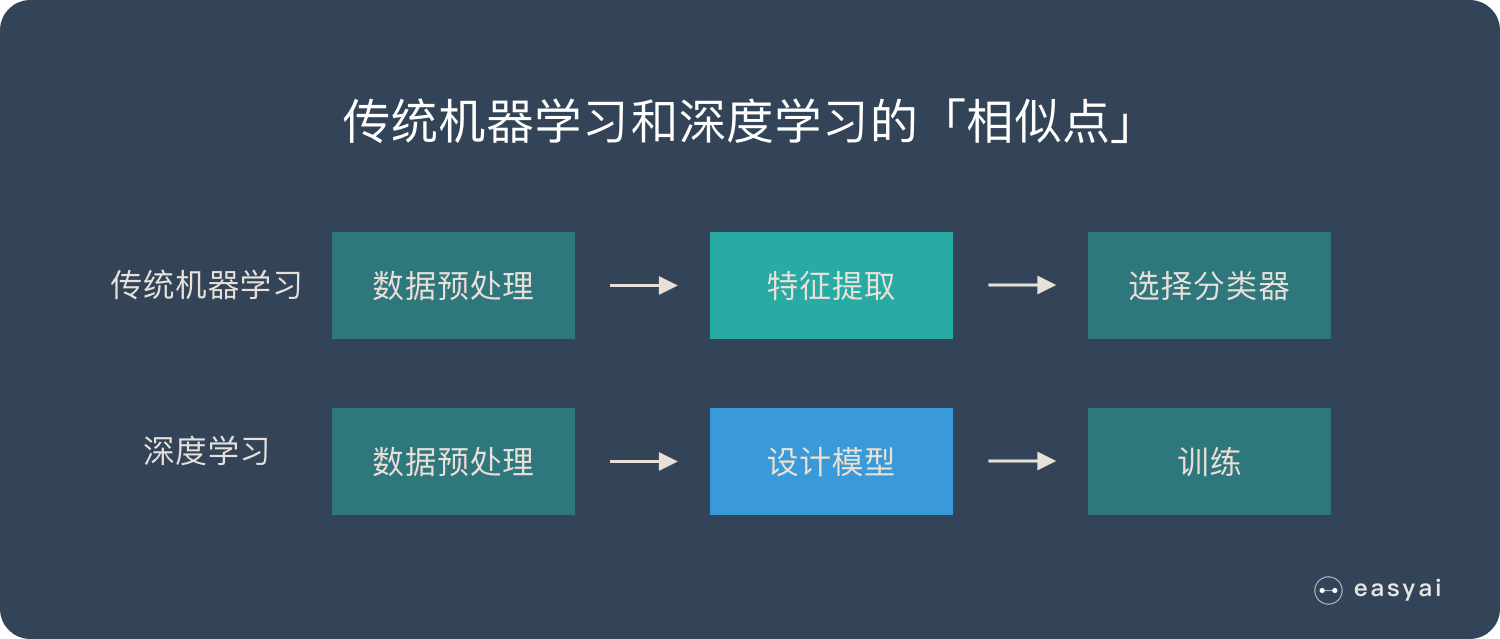
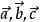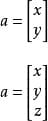什么是标量
标量只有大小概念,没有方向的概念。通过一个具体的数值就能表达完整。
比如:重量、温度、长度、提及、时间、热量等都数据标量。

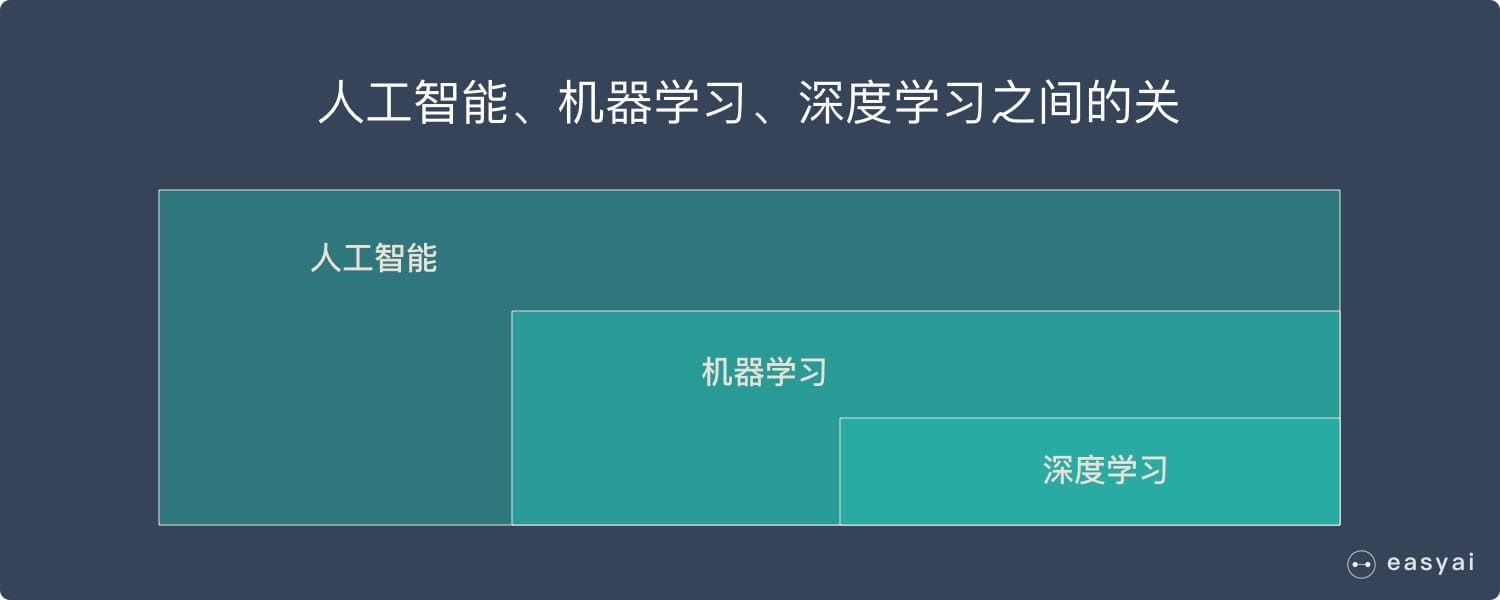
标量、向量、矩阵、张量的关系
这4个概念是维度不断上升的,我们用点线面体的概念来比喻解释会更加容易理解:

感兴趣的可以通过下面的内容了解详情:
《一文看懂标量》
《一文看懂向量》
《一文看懂矩阵》
《一文看懂张量》
百度百科和维基百科
百度百科版本
标量(scalar),亦称“无向量”。有些物理量,只具有数值大小,而没有方向,部分有正负之分。物理学中,标量(或作纯量)指在坐标变换下保持不变的物理量。用通俗的说法,标量是只有大小,没有方向的量。
维基百科版本
标量是一个的元素字段,其用于定义一个向量空间。由多个标量描述的量,例如具有方向和幅度,被称为矢量。在线性代数,实数或场的其它元素被称为标量,并涉及到在载体通过的操作的向量空间标量乘法,其中载体可以由多个以产生另一矢量相乘。更一般地,可以通过使用任何字段而不是实数来定义向量空间,例如复数。然后该向量空间的标量将成为相关字段的元素。