

介绍
Yann LeCun将其描述为“过去10年机器学习中最有趣的想法”。当然,来自深度学习领域这样一位杰出研究人员的这种称赞总是对我们所谈论的主题的一个很好的广告!而且,事实上,剖成对抗性网络(甘斯的简称)都产生了巨大的成功,因为他们在2014年的一篇文章中介绍了由Ian J.古德费洛和共同作者剖成对抗性篮网。
那么Generative Adversarial Networks是什么?是什么让他们如此“有趣”?在这篇文章中,我们将看到对抗性训练是一个启发性的想法,其简洁美观,代表了机器学习的真正概念进展,尤其是生成模型(与反向传播相同的方式是一个简单但非常聪明的技巧,使神经网络的基本思想变得如此受欢迎和高效)。
在进入细节之前,让我们快速概述一下GAN的用途。生成性对抗网络属于一组生成模型。这意味着他们能够生成/生成(我们将看到如何)新内容。为了说明这种“生成模型”的概念,我们可以看一些用GAN获得的结果的众所周知的例子。

当然,这种生成新内容的能力使GAN看起来有点“神奇”,至少在第一眼看上去。在以下部分中,我们将克服GAN的明显魔力,以深入了解这些模型背后的想法,数学和建模。我们不仅会讨论Generative Adversarial Networks所依赖的基本概念,而且我们将逐步建立并从一开始就推出导致这些想法的推理。
不用多说,让我们一起重新发现GAN!
注意:虽然我们试图使本文尽可能独立,但仍需要机器学习的基本先验知识。然而,大多数概念将在需要时保留,否则将提供一些参考。我们真的试图让这篇文章尽可能顺利阅读。不要犹豫,在评论部分提及您希望阅读的更多内容(关于该主题的可能的其他文章)。
大纲
在下面的第一节中,我们将讨论从给定分布生成随机变量的过程。然后,在第2节中,我们将通过一个例子展示GAN试图解决的问题可以表示为随机变量生成问题。在第3节中,我们将讨论基于匹配的生成网络,并展示它们如何回答第2节中描述的问题。最后在第4节中,我们将介绍GAN。更具体地说,我们将展示具有其损失功能的一般架构,并且我们将与之前的所有部分建立链接。
生成随机变量
在本节中,我们将讨论生成随机变量的过程:我们提醒一些现有方法,尤其是逆变换方法,它允许从简单的均匀随机变量生成复杂的随机变量。尽管所有这些看起来与我们的物质主题GAN相差甚远,但我们将在下一节中看到与生成模型存在的深层联系。
可以伪随机生成均匀随机变量
计算机基本上是确定性的。因此,从理论上讲,生成真正随机的数字是不可能的(即使我们可以说“真正的随机性是什么?”这个问题很困难)。但是,可以定义生成数字序列的算法,其特性非常接近理论随机数序列的属性。特别是,计算机能够使用伪随机数生成器生成一系列数字,这些数字近似地遵循0和1之间的均匀随机分布。统一的情况是一个非常简单的情况,可以在其上建立更复杂的随机变量不同的方法。
随机变量表示为操作或过程的结果
存在旨在产生更复杂的随机变量的不同技术。其中我们可以找到,例如,逆变换方法,拒绝抽样,Metropolis-Hasting算法等。所有这些方法都依赖于不同的数学技巧,这些技巧主要在于表示我们想要生成的随机变量作为操作(通过更简单的随机变量)或过程的结果。
拒绝抽样表示随机变量是一个过程的结果,该过程不是从复杂分布中采样,而是从众所周知的简单分布中采样,并根据某些条件接受或拒绝采样值。重复此过程直到采样值被接受,我们可以证明,在正确接受条件下,有效采样的值将遵循正确的分布。
在Metropolis-Hasting算法中,想法是找到马尔可夫链(MC),使得该MC的静态分布对应于我们想要对随机变量进行采样的分布。一旦这个MC发现,我们可以在这个MC上模拟足够长的轨迹来考虑我们已经达到稳定状态,然后我们以这种方式获得的最后一个值可以被认为是从感兴趣的分布中得出的。
我们不会再进一步了解拒绝抽样和Metropolis-Hasting的细节,因为这些方法不会引导我们遵循GAN背后的概念(尽管如此,感兴趣的读者可以参考指向的维基百科文章及其中的链接) 。但是,让我们更多地关注逆变换方法。
逆变换方法
逆变换方法的想法只是为了表示我们的复杂性 – 在本文中,“复杂”应该始终被理解为“不简单”而不是数学意义 – 随机变量作为应用于函数的函数的结果统一随机变量我们知道如何生成。
我们在下面的一个例子中考虑。设X是我们想要采样的复杂随机变量,U是[0,1]上的均匀随机变量,我们知道如何从中采样。我们提醒随机变量由其累积分布函数(CDF)完全定义。随机变量的CDF是从随机变量的定义域到区间[0,1]的函数,并且在一个维度中定义,使得

在我们的均匀随机变量U的特定情况下,我们有
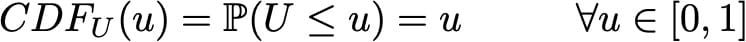
为简单起见,我们在此假设函数CDF_X是可逆的并且表示其反函数

(通过使用函数的广义逆,可以很容易地将该方法扩展到不可逆的情况,但它实际上不是我们想要关注的主要点)。然后,如果我们定义
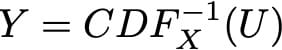
我们有
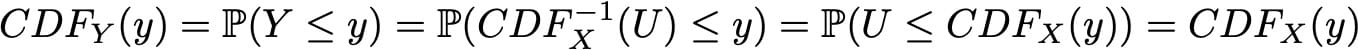
我们可以看到,Y和X具有相同的CDF,然后定义相同的随机变量。因此,通过如上定义Y(作为均匀随机变量的函数),我们设法定义了具有目标分布的随机变量。
总而言之,逆变换方法是通过使均匀随机变量经过精心设计的“变换函数”(逆CDF)来生成遵循给定分布的随机变量的方式。事实上,这种“逆变换方法”的概念可以扩展到“变换方法”的概念,“变换方法”更广泛地说,它是由一些较简单的随机变量生成随机变量(不一定是均匀的,然后变换函数是不再是逆CDF)。从概念上讲,“变换函数”的目的是使初始概率分布变形/重塑:变换函数从初始分布与目标分布相比过高,并将其置于过低的位置。
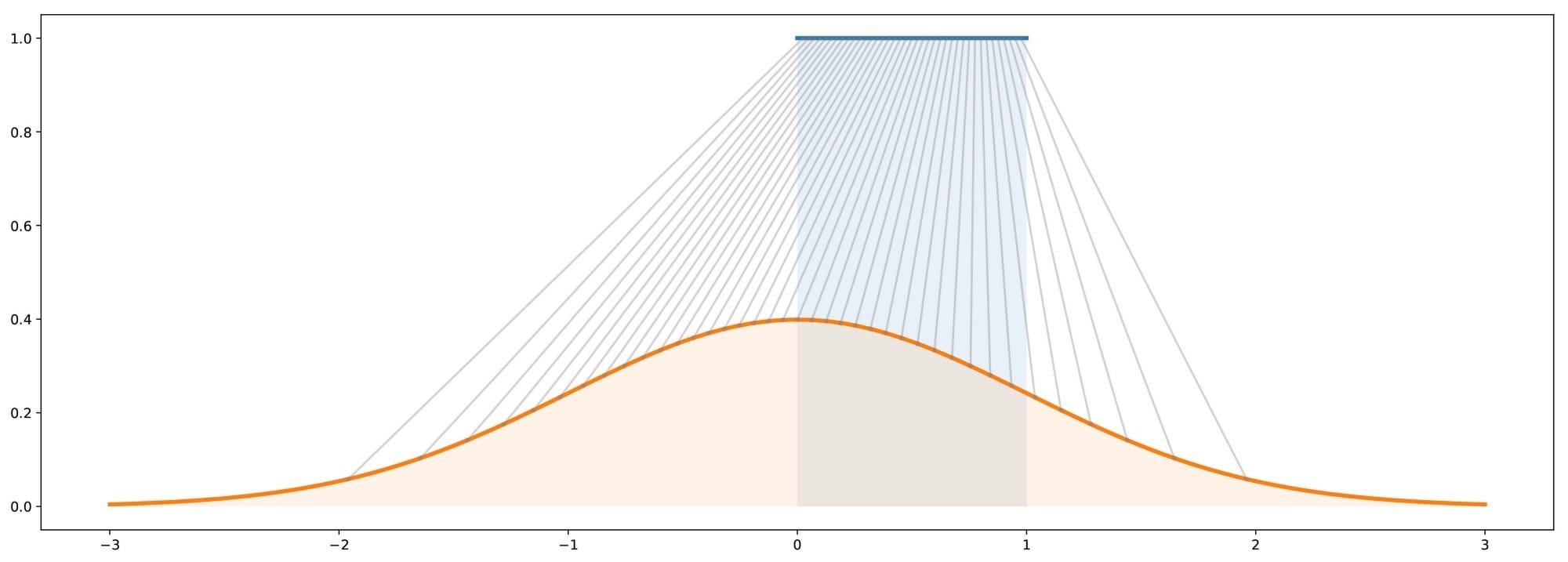
生成模型
我们试图生成非常复杂的随机变量……
假设我们有兴趣生成大小为n乘n像素的狗的黑白方形图像。我们可以将每个数据重新整形为N = n×n维向量(通过将列堆叠在彼此之上),使得狗的图像可以由向量表示。然而,这并不意味着所有的矢量都代表一只狗形状回到正方形!因此,我们可以说,有效地给出看起来像狗的东西的N维向量根据整个N维向量空间上的非常特定的概率分布来分布(该空间的某些点很可能代表狗,而它是对其他人来说极不可能)。同样的精神,在这个N维向量空间上存在猫,鸟等图像的概率分布。
然后,生成狗的新图像的问题等同于在N维向量空间上生成跟随“狗概率分布”的新向量的问题。事实上,我们面临着针对特定概率分布生成随机变量的问题。
在这一点上,我们可以提到两件重要的事情。首先,我们提到的“狗概率分布”是在非常大的空间上非常复杂的分布。其次,即使我们可以假设存在这样的基础分布(实际上存在看起来像狗的图像而其他图像看起来不像),我们显然不知道如何明确地表达这种分布。之前的两点都使得从该分布生成随机变量的过程非常困难。然后让我们尝试解决以下两个问题。
…所以让我们使用神经网络的变换方法作为函数!
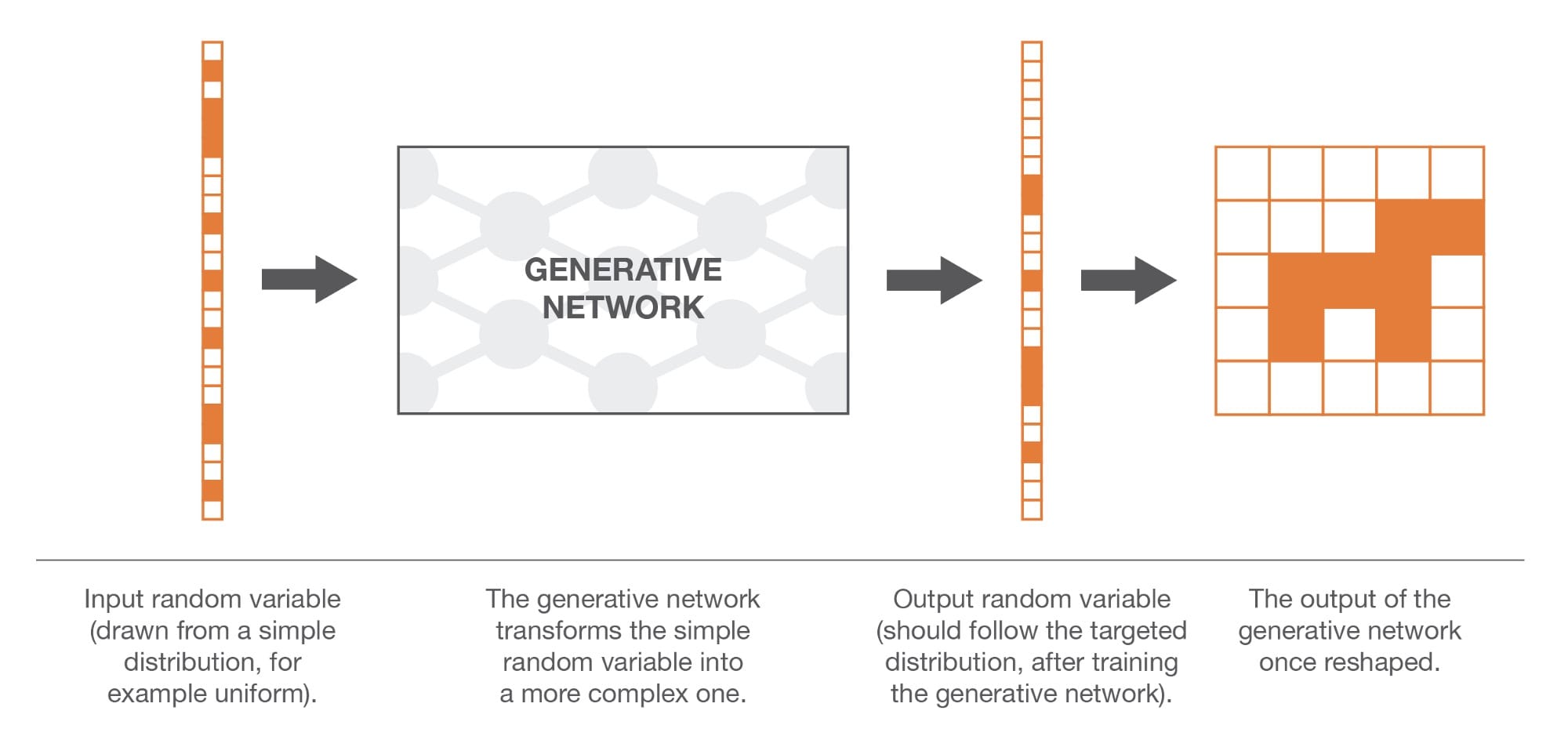
当我们尝试生成狗的新图像时,我们的第一个问题是N维向量空间上的“狗概率分布”是一个非常复杂的问题,我们不知道如何直接生成复杂的随机变量。然而,正如我们非常清楚如何生成N个不相关的均匀随机变量,我们可以使用变换方法。为此,我们需要将N维随机变量表示为应用于简单N维随机变量的非常复杂函数的结果!
在这里,我们可以强调这样的事实:找到变换函数并不像我们在描述逆变换方法时所做的那样只采用累积分布函数(我们显然不知道)的闭式逆。转换函数无法明确表达,因此,我们必须从数据中学习它。
在这些情况下,大多数情况下,非常复杂的功能自然意味着神经网络建模。然后,我们的想法是通过一个神经网络对变换函数进行建模,该神经网络将一个简单的N维均匀随机变量作为输入,并作为输出返回另一个N维随机变量,在训练之后,该随机变量应遵循正确的“狗概率分布” 。一旦设计了网络架构,我们仍然需要对其进行培训。在接下来的两节中,我们将讨论培训这些生成网络的两种方法,包括GAN背后的对抗训练的想法!
生成匹配网络
免责声明:“生成匹配网络”的名称不是标准的。但是,我们可以在文献中找到,例如,“Generative Moments Matching Networks”或“Generative Features Matching Networks”。我们只是想在这里使用稍微更一般的面额来描述我们所描述的内容。
培养生成模型
到目前为止,我们已经证明了我们生成狗的新图像的问题可以被重新描述为在N维向量空间中生成跟随“狗概率分布”的随机向量的问题,并且我们建议使用变换方法,用神经网络来模拟变换函数。
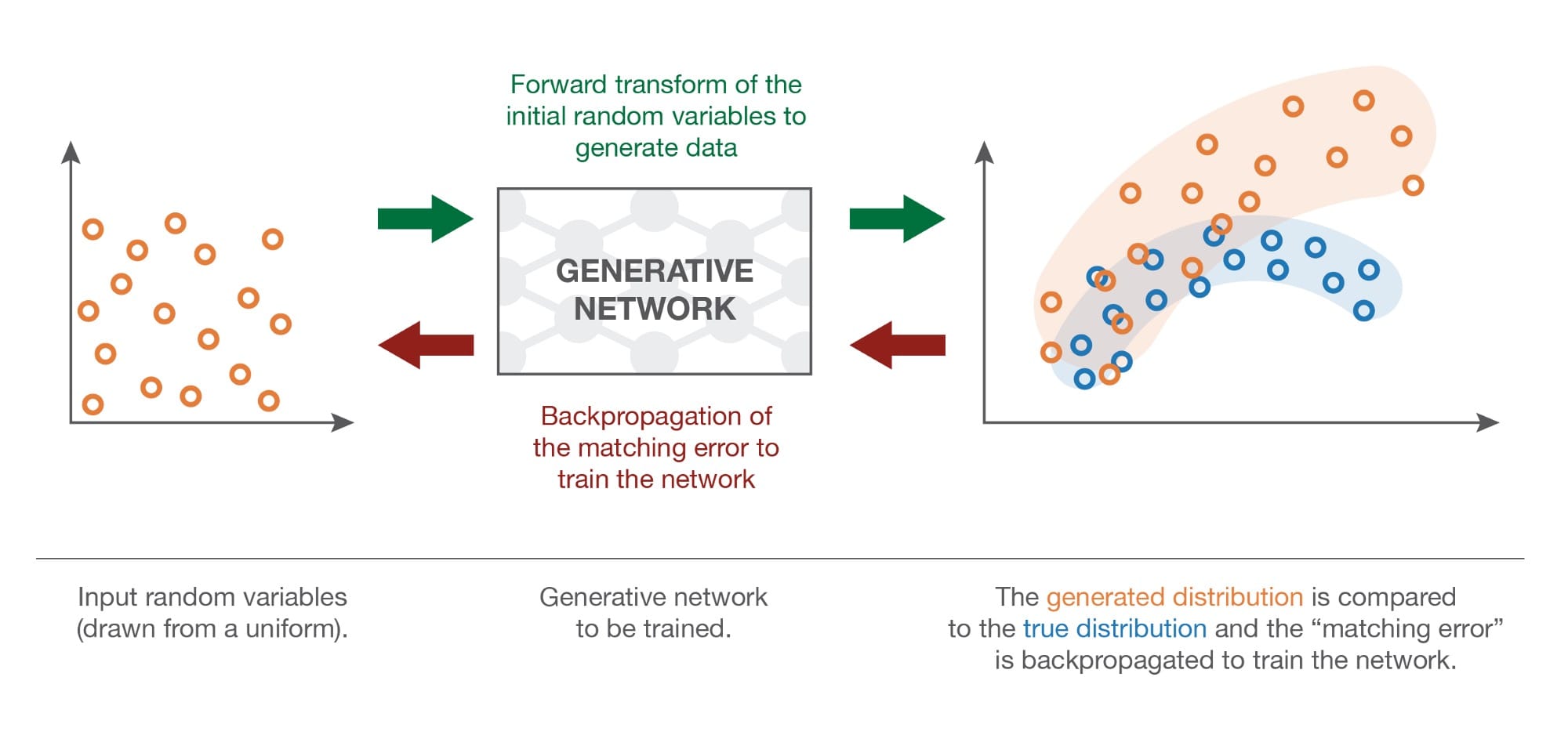
现在,我们仍然需要训练(优化)网络来表达正确的变换功能。为此,我们可以建议两种不同的训练方法:直接训练方法和间接训练方法。直接训练方法包括比较真实和生成的概率分布,并通过网络反向传播差异(误差)。这是规则生成匹配网络(GMNs)的想法。对于间接训练方法,我们不直接比较真实和生成的分布。相反,我们通过使这两个分布经过选择的下游任务来训练生成网络,使得生成网络相对于下游任务的优化过程将强制生成的分布接近真实分布。最后一个想法是生成对抗网络(GAN)背后的一个,我们将在下一节中介绍。但就目前而言,让我们从直接方法和GMN开始。
比较基于样本的两个概率分布
如上所述,GMN的想法是通过直接将生成的分布与真实分布进行比较来训练生成网络。但是,我们不知道如何明确表达真正的“狗概率分布”,我们也可以说生成的分布过于复杂而无法明确表达。因此,基于显式表达式的比较是不可能的。但是,如果我们有一种比较基于样本的概率分布的方法,我们可以使用它来训练网络。实际上,我们有一个真实数据的样本,我们可以在训练过程的每次迭代中生成生成数据的样本。
虽然理论上可以使用任何能够有效比较基于样本的两个分布的距离(或相似性度量),但我们可以特别提到最大均值差异(MMD)方法。MMD定义了可以基于这些分布的样本计算(估计)的两个概率分布之间的距离。虽然它不完全超出了本文的范围,但我们决定不再花费更多时间来描述MDD。但是,我们的项目很快就会发布一篇文章,其中将包含有关它的更多详细信息。想要了解MMD的更多信息的读者可以参考这些幻灯片,本文或本文。
反向传播分布匹配错误
因此,一旦我们定义了一种基于样本比较两种分布的方法,我们就可以定义GMN中生成网络的训练过程。给定具有均匀概率分布的随机变量作为输入,我们希望所生成的输出的概率分布是“狗概率分布”。然后,GMN的想法是通过重复以下步骤来优化网络:
- 产生一些统一的输入
- 使这些输入通过网络并收集生成的输出
- 比较真实的“狗概率分布”和基于可用样本生成的一个(例如计算真实狗图像样本与生成的样本的样本之间的MMD距离)
- 使用反向传播来进行梯度下降的一个步骤,以降低真实分布和生成分布之间的距离(例如MMD)
如上所述,当遵循这些步骤时,我们在网络上应用梯度下降,其具有损失函数,该函数是当前迭代中的真实分布与生成分布之间的距离。
生成性对抗网络
“间接”训练方法
上面提出的“直接”方法在训练生成网络时直接比较生成的分布与真实分布。规则GAN的好主意在于用间接的替代方式替换这种直接比较,后者采用这两种分布的下游任务的形式。然后对该任务进行生成网络的训练,使得它迫使所生成的分布越来越接近真实分布。
GAN的下游任务是真实样本和生成样本之间的歧视任务。或者我们可以说“非歧视”任务,因为我们希望歧视尽可能地失败。因此,在GAN架构中,我们有一个鉴别器,它可以获取真实数据和生成数据的样本,并尝试尽可能地对它们进行分类,以及一个经过培训的发生器,以尽可能地欺骗鉴别器。让我们看一个简单的例子,为什么我们提到的直接和间接方法理论上应该导致相同的最优生成器。
理想的情况:完美的发电机和鉴别器
为了更好地理解为什么训练生成器以欺骗鉴别器将导致与直接训练生成器以匹配目标分布相同的结果,让我们采用简单的一维示例。我们暂时忘记了如何表示生成器和鉴别器,并将它们视为抽象概念(将在下一小节中指定)。而且,两者都被认为是“完美的”(具有无限的容量),因为它们不受任何类型(参数化)模型的约束。
假设我们有一个真正的分布,例如一维高斯分布,并且我们想要一个从这个概率分布中采样的生成器。我们所谓的“直接”训练方法将包括迭代地调整生成器(梯度下降迭代)以校正真实分布和生成分布之间的测量差异/误差。最后,假设优化过程完美,我们应该最终得到与真实分布完全匹配的生成分布。
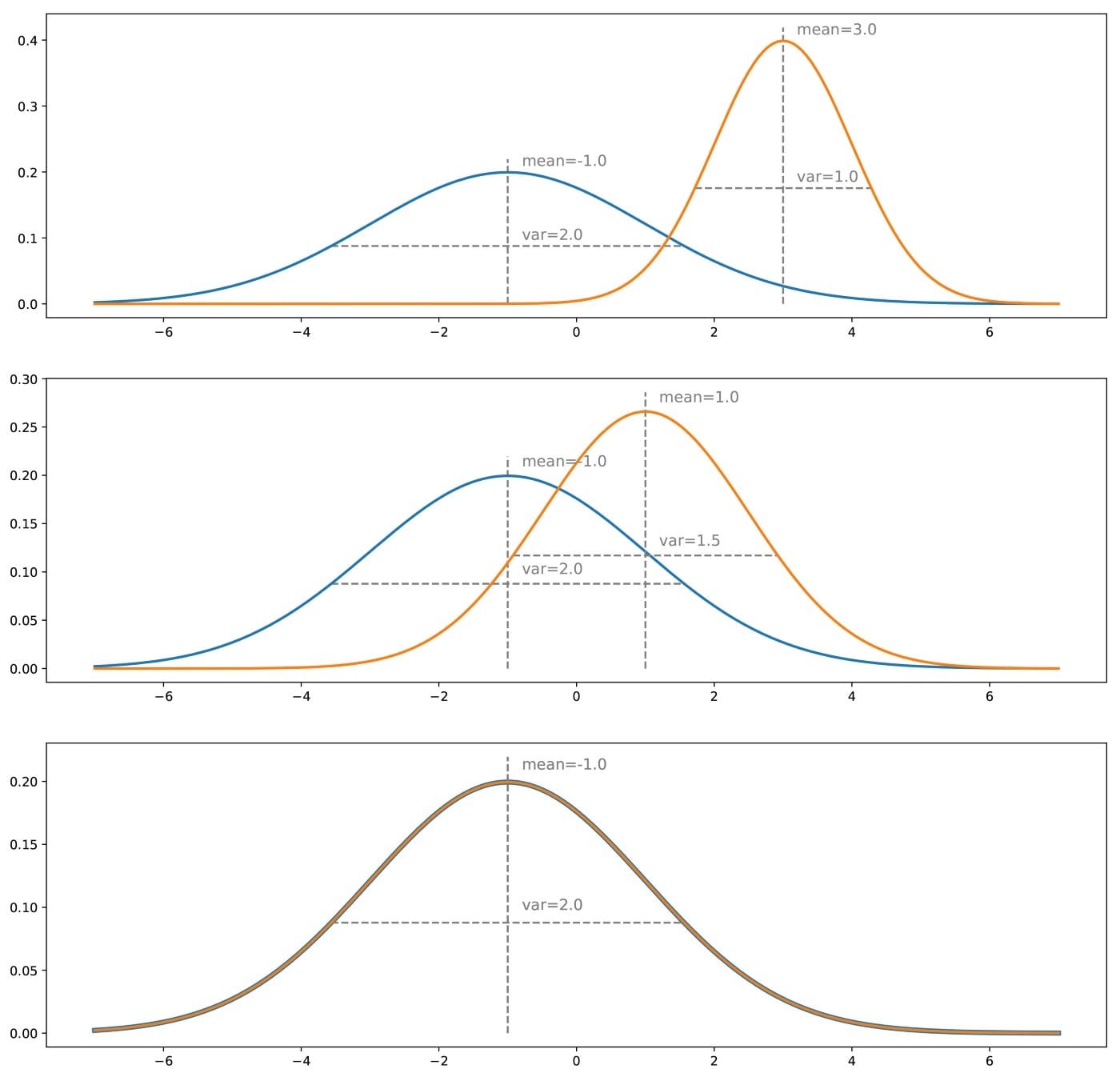
对于“间接”方法,我们还必须考虑一个鉴别器。我们现在假设这个鉴别器是一种oracle,它确切知道什么是真实和生成的分布,并且能够根据这些信息预测任何给定点的类(“真”或“生成”)。如果这两个分布很明显,那么鉴别器将能够轻松地进行分类,并且可以高度自信地将我们呈现给它的大多数点分类。如果我们想欺骗鉴别器,我们必须使生成的分布接近真实的分布。当两个分布在所有点上相等时,鉴别器将最难预测类:在这种情况下,

在这一点上,似乎有理由怀疑这种间接方法是否真的是一个好主意。实际上,它似乎更复杂(我们必须基于下游任务而不是直接基于分布来优化生成器)并且它需要我们在此认为是给定oracle的鉴别器,但实际上,它既不是已知的也不完美。对于第一点,直接比较基于样本的两个概率分布的难度抵消了间接方法的明显更高的复杂性。对于第二点,很明显,鉴别器是未知的。但是,它可以学到!
近似:对抗性神经网络
现在让我们描述采用GANs架构中的生成器和鉴别器的具体形式。生成器是一个模拟转换函数的神经网络。它将一个简单的随机变量作为输入,并且必须在训练后返回一个跟随目标分布的随机变量。由于它非常复杂和未知,我们决定用另一个神经网络对鉴别器进行建模。该神经网络模拟判别函数。它将一个点(在我们的狗示例中为N维向量)作为输入,并将该点的概率作为输出返回为“真”。
请注意,我们现在强加一个参数化模型来表达生成器和鉴别器(而不是前一小节中的理想化版本)的事实,实际上并没有对上面给出的理论论证/直觉产生巨大影响:我们只是然后,在一些参数化空间而不是理想的全空间中工作,因此,在理想情况下我们应达到的最佳点可以被视为由参数化模型的精确容量“舍入”。
一旦定义,两个网络就可以联合(同时)进行相反的目标训练:
- 生成器的目标是欺骗鉴别器,因此训练生成神经网络以最大化最终分类错误(真实数据和生成数据之间)
- 鉴别器的目标是检测伪造的数据,因此训练判别神经网络以最小化最终的分类错误
因此,在训练过程的每次迭代中,更新生成网络的权重以增加分类错误(错误梯度上升到生成器的参数),同时更新判别网络的权重以减少此错误(误差梯度下降超过鉴别器的参数)。
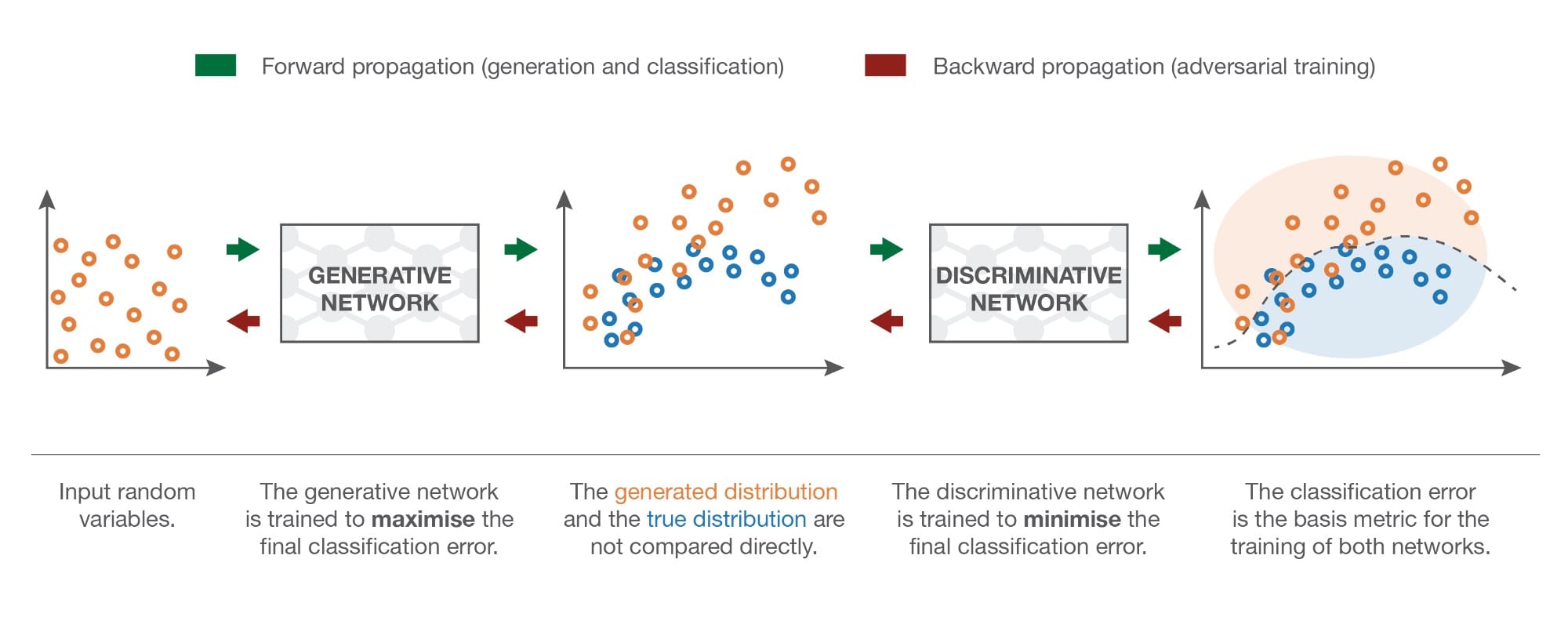
这些相反的目标和两个网络的对抗性训练的隐含概念解释了“对抗性网络”的名称:两个网络都试图相互击败,这样做,它们都变得越来越好。他们之间的竞争使这两个网络在各自的目标方面“进步”。从博弈论的角度来看,我们可以将此设置视为极小极大双玩家游戏,其中均衡状态对应于发生器从精确目标分布生成数据并且鉴别器预测“真实”或“生成”的情况“它接收的任何一点的概率为1/2。
关于GAN的数学细节
注意:本节更具技术性,对于全面了解GAN并非绝对必要。所以,现在不想读一些数学的读者可以暂时跳过这一部分。对于其他人,让我们看看上面给出的直觉是如何在数学上形式化的。
放弃:下面的等式不是Ian Goodfellow的文章。我们在这里提出另一个数学形式化有两个原因:第一,保持更接近上面给出的直觉,第二,因为原始论文的方程已经非常清楚,只是重写它们是没有用的。另请注意,我们绝对不会参与与不同可能的损失函数相关的实际考虑(消失梯度或其他)。我们强烈建议读者也要看看原始论文的方程式:主要区别在于Ian Goodfellow和共同作者使用交叉熵误差而不是绝对误差(正如我们所做的那样)。此外,在下文中我们假设具有无限容量的发生器和鉴别器。
神经网络建模本质上需要定义两件事:架构和损失函数。我们已经描述了Generative Adversarial Networks的架构。它包含两个网络:
- 生成网络G(。),其采用密度为p_z的随机输入z,并返回输出x_g = G(z),该输出应遵循(训练后)目标概率分布
- 一个判别网络D(。),它取一个可以是“真”的输入x(x_t,其密度用p_t表示)或“生成”的一个(x_g,其密度p_g是由密度p_z引起的密度通过G)并将x的概率D(x)返回为“真实”数据
现在让我们仔细看看GAN的“理论”损失函数。如果我们以相同的比例向鉴别器“真实”和“生成”数据发送,则鉴别器的预期绝对误差可以表示为
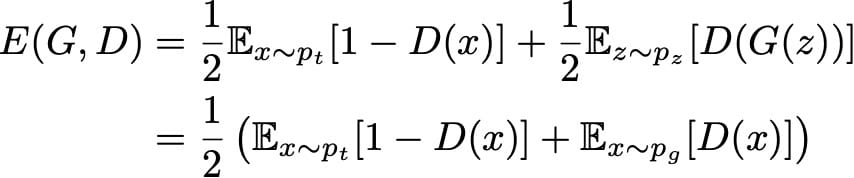
生成器的目标是欺骗鉴别器,其目标是能够区分真实数据和生成数据。因此,在训练生成器时,我们希望最大化此错误,同时我们尝试将其最小化以用于鉴别器。它给了我们
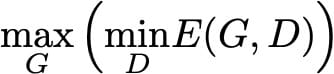
对于任何给定的发生器G(以及诱导概率密度p_g),最佳可能的鉴别器是最小化的鉴别器

为了最小化(相对于D)这个积分,我们可以最小化x的每个值的积分内的函数。然后,它为给定的发电机定义最佳可能的鉴别器

(事实上,最好的因为x值,使得p_t(x)= p_g(x)可以用另一种方式处理,但对于后面的内容并不重要)。然后我们搜索G最大化

同样,为了最大化(相对于G)这个积分,我们可以最大化x的每个值的积分内的函数。由于密度p_t独立于发电机G,我们不能比设置G更好
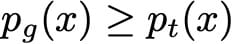
当然,由于p_g是应该与1整合的概率密度,我们必然拥有最佳的G
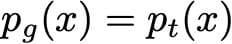
因此,我们已经证明,在具有无限容量发生器和鉴别器的理想情况下,对抗性设置的最佳点使得发生器产生与真密度相同的密度,并且鉴别器不能比真实的更好。一个案例中有两个,就像直觉告诉我们的那样。最后,还要注意G最大化
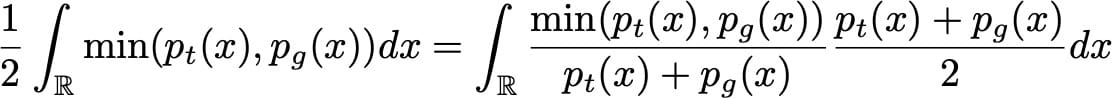
在这种形式下,我们最好看到G想要最大化鉴别器出错的预期概率。
小贴士
本文的主要内容是:
- 计算机基本上可以生成简单的伪随机变量(例如,它们可以生成非常接近均匀分布的变量)
- 存在不同的方法来生成更复杂的随机变量,包括“变换方法”的概念,其包括将随机变量表示为一些更简单的随机变量的函数。
- 在机器学习中,生成模型试图从给定(复杂)概率分布生成数据
- 深度学习生成模型被建模为神经网络(非常复杂的函数),它将一个简单的随机变量作为输入,并返回一个跟随目标分布的随机变量(“变换方法”)
- 这些生成网络可以“直接”训练(通过比较生成数据与真实分布的分布):这就是生成匹配网络的思想
- 这些生成网络也可以“间接”训练(通过试图欺骗同时训练的另一个网络来区分“生成的”数据和“真实”数据):这就是生成对抗网络的想法
即使围绕GAN的“炒作”可能有点夸张,我们可以说Ian Goodfellow及其合着者提出的对抗性训练的想法确实很棒。这种扭曲损失函数从直接比较到间接比较的方式实际上可以激发深度学习领域的进一步工作。总而言之,让我们说我们不知道GAN的概念是否真的是“机器学习中过去10年中最有趣的想法”……但很明显它至少是最有趣的一个!
本文转自towardsdatascience,原文地址

8 Comments
这里面有些是直接谷歌翻译的?太生硬了。
新闻类的文章的确是Google翻译的,由于自己一个人维护网站,所以没有做更好的翻译,只要读者能理解文章大意目的就达到了。请谅解
谢谢小强,喜欢你的讲解,页面简洁大气,配图精美,让我对GAN有了更清晰的认识!
多谢你的肯定,觉得不错可以推荐给身边的朋友
这篇文章给我的感觉一会讲的通熟易懂,一会这说的是人话吗!?
机器翻译的,有些地方会不通顺
HALLO, 能把原网站贴出来么
文末有原文地址