
Google最近发布了一些有关在深度神经网络中对注意力机制进行建模的工作
Author Archive
我的业务要不要用人工智能?引入AI前你需要评估的(一)
这是一个系列文章,从各个角度来评估一个问题:“要不要用 AI ?AI 能否解决我的问题?”本期评估角度——特征。
分类模型评估指标——准确率、精准率、召回率、F1、ROC曲线、AUC曲线

机器学习模型需要有量化的评估指标来评估哪些模型的效果更好。
本文将用通俗易懂的方式讲解分类问题的混淆矩阵和各种评估指标的计算公式。将要给大家介绍的评估指标有:准确率、精准率、召回率、F1、ROC曲线、AUC曲线。
机器学习评估指标大全
所有事情都需要评估好坏,尤其是量化的评估指标。
- 高考成绩用来评估学生的学习能力
- 杠铃的重量用来评估肌肉的力量
- 跑分用来评估手机的综合性能
机器学习有很多评估的指标。有了这些指标我们就横向的比较哪些模型的表现更好。我们先从整体上来看看主流的评估指标都有哪些:

分类问题评估指标:
- 准确率 – Accuracy
- 精确率(差准率)- Precision
- 召回率(查全率)- Recall
- F1分数
- ROC曲线
- AUC曲线
回归问题评估指标:
- MAE
- MSE
分类问题图解
为了方便大家理解各项指标的计算方式,我们用具体的例子将分类问题进行图解,帮助大家快速理解分类中出现的各种情况。
举个例子:
我们有10张照片,5张男性、5张女性。如下图:

有一个判断性别的机器学习模型,当我们使用它来判断「是否为男性」时,会出现4种情况。如下图:

- 实际为男性,且判断为男性(正确)
- 实际为男性,但判断为女性(错误)
- 实际为女性,且判断为女性(正确)
- 实际为女性,但判断为男性(错误)
这4种情况构成了经典的混淆矩阵,如下图:
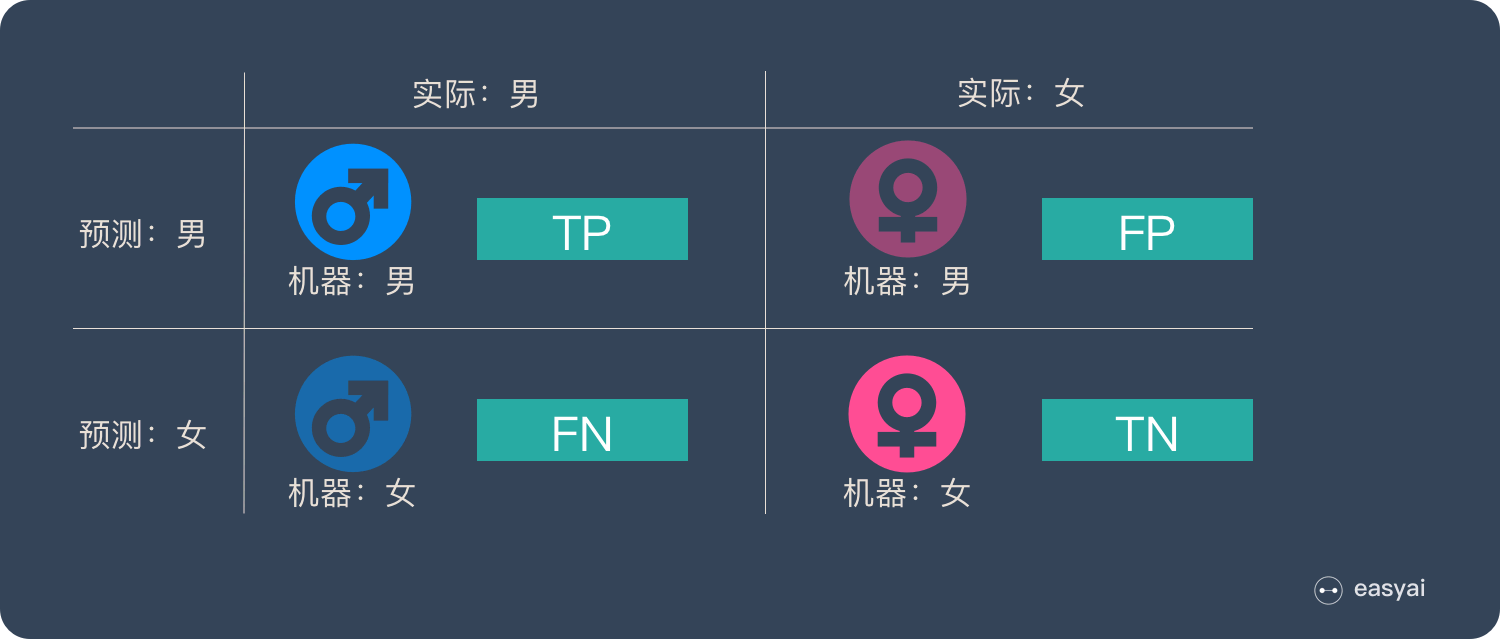
TP – True Positive:实际为男性,且判断为男性(正确)
FN – False Negative:实际为男性,但判断为女性(错误)
TN – True Negative:实际为女性,且判断为女性(正确)
FP – False Positive:实际为女性,但判断为男性(错误)
这4个名词初看起来比较晕(尤其是缩写),但是当我们把英文拆分时就很容易理解了,如下图:

所有的评估指标都是围绕上面4种情况来计算的,所以理解上面4种情况是基础!
分类评估指标详解
下面详细介绍一下分类分为种的各种评估指标详情和计算公式:
准确率 – Accuracy
预测正确的结果占总样本的百分比,公式如下:
准确率 =(TP+TN)/(TP+TN+FP+FN)

虽然准确率可以判断总的正确率,但是在样本不平衡 的情况下,并不能作为很好的指标来衡量结果。举个简单的例子,比如在一个总样本中,正样本占 90%,负样本占 10%,样本是严重不平衡的。对于这种情况,我们只需要将全部样本预测为正样本即可得到 90% 的高准确率,但实际上我们并没有很用心的分类,只是随便无脑一分而已。这就说明了:由于样本不平衡的问题,导致了得到的高准确率结果含有很大的水分。即如果样本不平衡,准确率就会失效。
精确率(差准率)- Precision
所有被预测为正的样本中实际为正的样本的概率,公式如下:
精准率 =TP/(TP+FP)
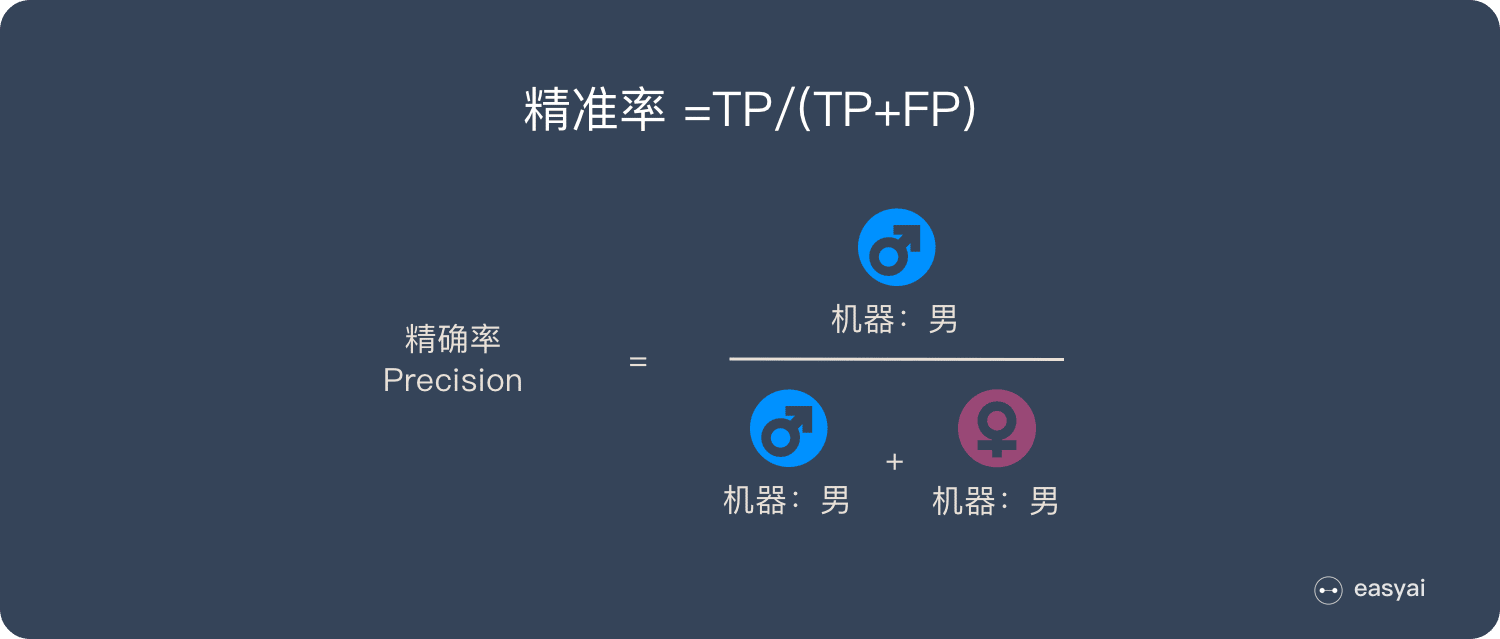
精准率和准确率看上去有些类似,但是完全不同的两个概念。精准率代表对正样本结果中的预测准确程度,而准确率则代表整体的预测准确程度,既包括正样本,也包括负样本。
召回率(查全率)- Recall
实际为正的样本中被预测为正样本的概率,其公式如下:
召回率=TP/(TP+FN)

召回率的应用场景: 比如拿网贷违约率为例,相对好用户,我们更关心坏用户,不能错放过任何一个坏用户。因为如果我们过多的将坏用户当成好用户,这样后续可能发生的违约金额会远超过好用户偿还的借贷利息金额,造成严重偿失。召回率越高,代表实际坏用户被预测出来的概率越高,它的含义类似:宁可错杀一千,绝不放过一个。
F1分数
如果我们把精确率(Precision)和召回率(Recall)之间的关系用图来表达,就是下面的PR曲线:
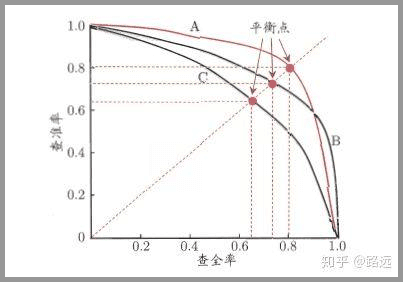
可以发现他们俩的关系是「两难全」的关系。为了综合两者的表现,在两者之间找一个平衡点,就出现了一个 F1分数。
F1=(2×Precision×Recall)/(Precision+Recall)

ROC曲线、AUC曲线
ROC 和 AUC 是2个更加复杂的评估指标,下面这篇文章已经很详细的解释了,这里直接引用这篇文章的部分内容。
上面的指标说明也是出自这篇文章:《一文让你彻底理解准确率,精准率,召回率,真正率,假正率,ROC/AUC》
1. 灵敏度,特异度,真正率,假正率
在正式介绍 ROC/AUC 之前,我们还要再介绍两个指标,这两个指标的选择也正是 ROC 和 AUC 可以无视样本不平衡的原因。 这两个指标分别是:灵敏度和(1- 特异度),也叫做真正率(TPR)和假正率(FPR)。
灵敏度(Sensitivity) = TP/(TP+FN)
特异度(Specificity) = TN/(FP+TN)
- 其实我们可以发现灵敏度和召回率是一模一样的,只是名字换了而已。
- 由于我们比较关心正样本,所以需要查看有多少负样本被错误地预测为正样本,所以使用(1- 特异度),而不是特异度。
真正率(TPR) = 灵敏度 = TP/(TP+FN)
假正率(FPR) = 1- 特异度 = FP/(FP+TN)
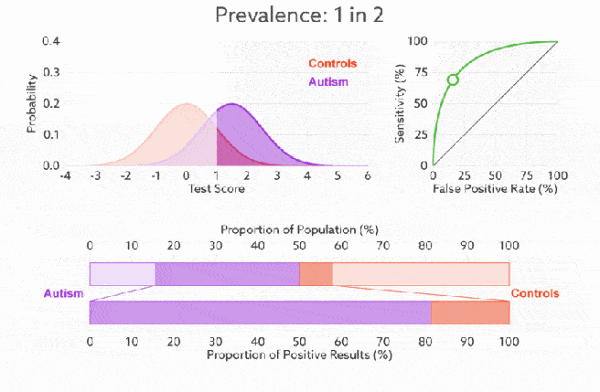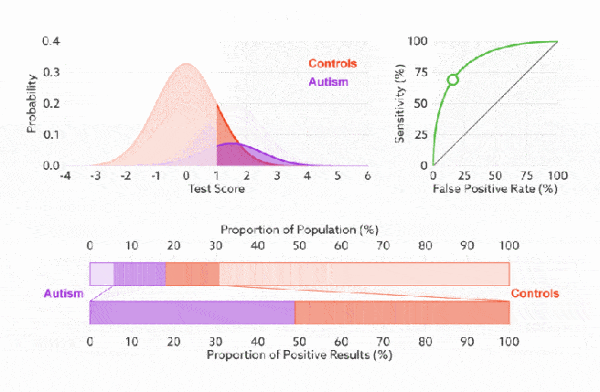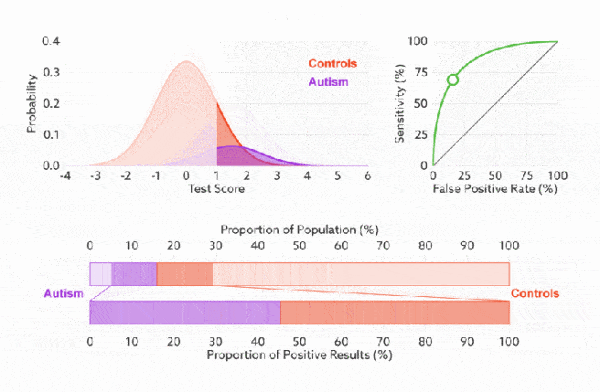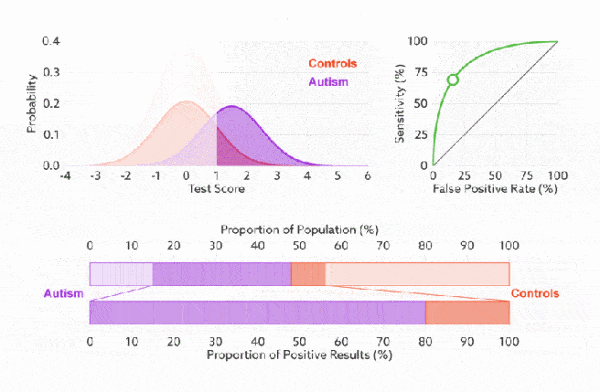
下面是真正率和假正率的示意,我们发现TPR 和 FPR 分别是基于实际表现 1 和 0 出发的,也就是说它们分别在实际的正样本和负样本中来观察相关概率问题。 正因为如此,所以无论样本是否平衡,都不会被影响。还是拿之前的例子,总样本中,90% 是正样本,10% 是负样本。我们知道用准确率是有水分的,但是用 TPR 和 FPR 不一样。这里,TPR 只关注 90% 正样本中有多少是被真正覆盖的,而与那 10% 毫无关系,同理,FPR 只关注 10% 负样本中有多少是被错误覆盖的,也与那 90% 毫无关系,所以可以看出:如果我们从实际表现的各个结果角度出发,就可以避免样本不平衡的问题了,这也是为什么选用 TPR 和 FPR 作为 ROC/AUC 的指标的原因。
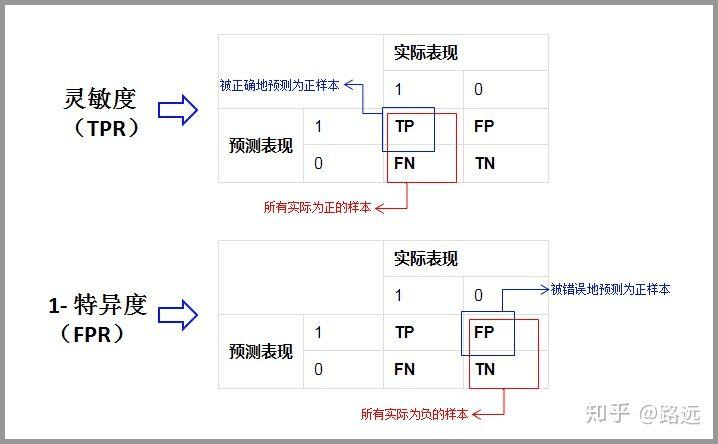
或者我们也可以从另一个角度考虑:条件概率。 我们假设X为预测值,Y为真实值。那么就可以将这些指标按条件概率表示:
精准率 = P(Y=1 | X=1)
召回率 = 灵敏度 = P(X=1 | Y=1)
特异度 = P(X=0 | Y=0)
从上面三个公式看到:如果我们先以实际结果为条件(召回率,特异度),那么就只需考虑一种样本,而先以预测值为条件(精准率),那么我们需要同时考虑正样本和负样本。所以先以实际结果为条件的指标都不受样本不平衡的影响,相反以预测结果为条件的就会受到影响。
2. ROC(接受者操作特征曲线)
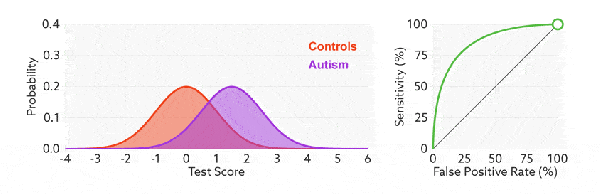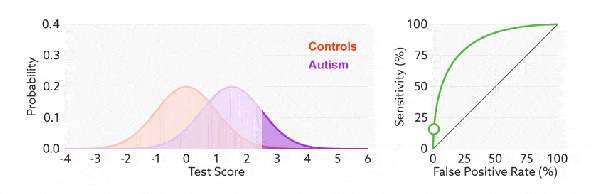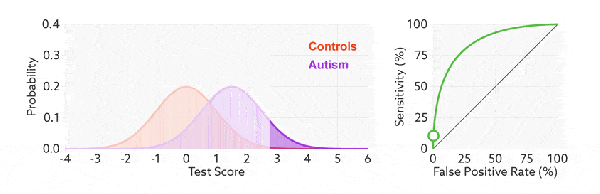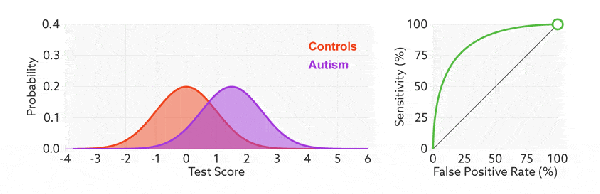
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。该曲线最早应用于雷达信号检测领域,用于区分信号与噪声。后来人们将其用于评价模型的预测能力,ROC 曲线是基于混淆矩阵得出的。
ROC 曲线中的主要两个指标就是真正率和假正率, 上面也解释了这么选择的好处所在。其中横坐标为假正率(FPR),纵坐标为真正率(TPR),下面就是一个标准的 ROC 曲线图。
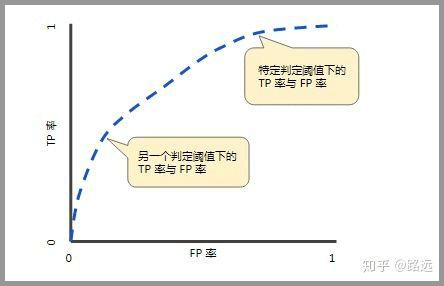
ROC 曲线的阈值问题
与前面的 P-R 曲线类似,ROC 曲线也是通过遍历所有阈值 来绘制整条曲线的。如果我们不断的遍历所有阈值,预测的正样本和负样本是在不断变化的,相应的在 ROC 曲线图中也会沿着曲线滑动。
如何判断 ROC 曲线的好坏?
改变阈值只是不断地改变预测的正负样本数,即 TPR 和 FPR,但是曲线本身是不会变的。那么如何判断一个模型的 ROC 曲线是好的呢?这个还是要回归到我们的目的:FPR 表示模型虚报的响应程度,而 TPR 表示模型预测响应的覆盖程度。我们所希望的当然是:虚报的越少越好,覆盖的越多越好。所以总结一下就是TPR 越高,同时 FPR 越低(即 ROC 曲线越陡),那么模型的性能就越好。 参考如下:

ROC 曲线无视样本不平衡
前面已经对 ROC 曲线为什么可以无视样本不平衡做了解释,下面我们用动态图的形式再次展示一下它是如何工作的。我们发现:无论红蓝色样本比例如何改变,ROC 曲线都没有影响。
3. AUC(曲线下的面积)
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积(Area Under Curve)。
比较有意思的是,如果我们连接对角线,它的面积正好是 0.5。对角线的实际含义是:随机判断响应与不响应,正负样本覆盖率应该都是 50%,表示随机效果。 ROC 曲线越陡越好,所以理想值就是 1,一个正方形,而最差的随机判断都有 0.5,所以一般 AUC 的值是介于 0.5 到 1 之间的。
AUC 的一般判断标准
0.5 – 0.7: 效果较低,但用于预测股票已经很不错了
0.7 – 0.85: 效果一般
0.85 – 0.95: 效果很好
0.95 – 1: 效果非常好,但一般不太可能
AUC 的物理意义
曲线下面积对所有可能的分类阈值的效果进行综合衡量。曲线下面积的一种解读方式是看作模型将某个随机正类别样本排列在某个随机负类别样本之上的概率。以下面的样本为例,逻辑回归预测从左到右以升序排列:

通过以下5个简单步骤将您的机器学习模型投入生产
这篇文章是关于一个成功的ML项目的过程要求的-一个投产的项目。
Attention 机制

Attention 正在被越来越广泛的得到应用。尤其是 BERT 火爆了之后。
Attention 到底有什么特别之处?他的原理和本质是什么?Attention都有哪些类型?本文将详细讲解Attention的方方面面。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
Attention 的本质是什么
Attention(注意力)机制如果浅层的理解,跟他的名字非常匹配。他的核心逻辑就是「从关注全部到关注重点」。

Attention 机制很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图:

我们一定会看清「锦江饭店」4个字,如下图:

但是我相信没人会意识到「锦江饭店」上面还有一串「电话号码」,也不会意识到「喜运来大酒家」,如下图:

所以,当我们看一张图片的时候,其实是这样的:

上面所说的,我们的视觉系统就是一种 Attention机制,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
AI 领域的 Attention 机制
Attention 机制最早是在计算机视觉里应用的,随后在 NLP 领域也开始应用了,真正发扬光大是在 NLP 领域,因为 2018 年 BERT 和 GPT 的效果出奇的好,进而走红。而 Transformer 和 Attention 这些核心开始被大家重点关注。
如果用图来表达 Attention 的位置大致是下面的样子:

这里先让大家对 Attention 有一个宏观的概念,下文会对 Attention 机制做更详细的讲解。在这之前,我们先说说为什么要用 Attention。
Attention 的3大优点
之所以要引入 Attention 机制,主要是3个原因:
- 参数少
- 速度快
- 效果好

参数少
模型复杂度跟 CNN、RNN 相比,复杂度更小,参数也更少。所以对算力的要求也就更小。
速度快
Attention 解决了 RNN 不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
效果好
在 Attention 机制引入之前,有一个问题大家一直很苦恼:长距离的信息会被弱化,就好像记忆能力弱的人,记不住过去的事情是一样的。
Attention 是挑重点,就算文本比较长,也能从中间抓住重点,不丢失重要的信息。下图红色的预期就是被挑出来的重点。

Attention 的原理
Attention 经常会和 Encoder–Decoder 一起说,之前的文章《一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq》 也提到了 Attention。
下面的动图演示了attention 引入 Encoder-Decoder 框架下,完成机器翻译任务的大致流程。
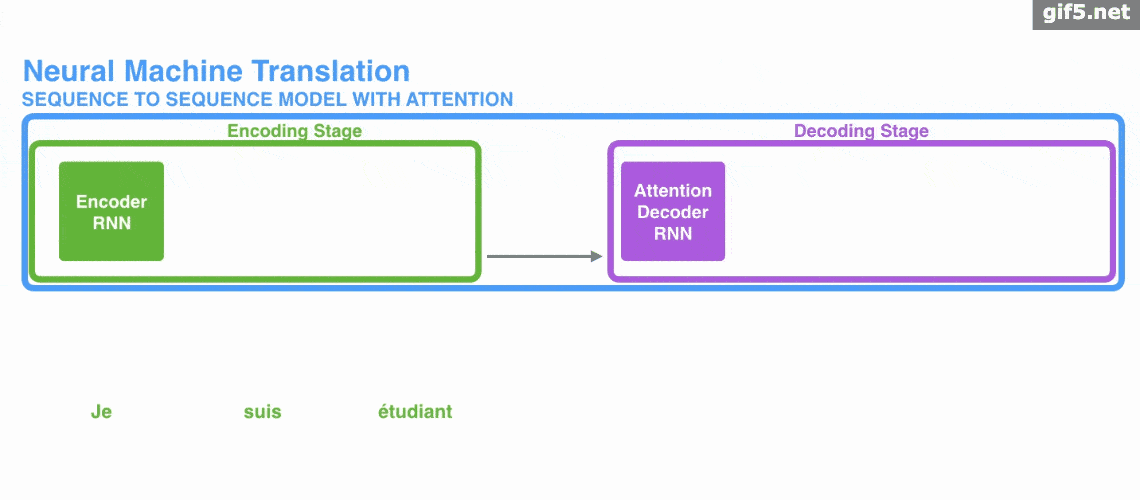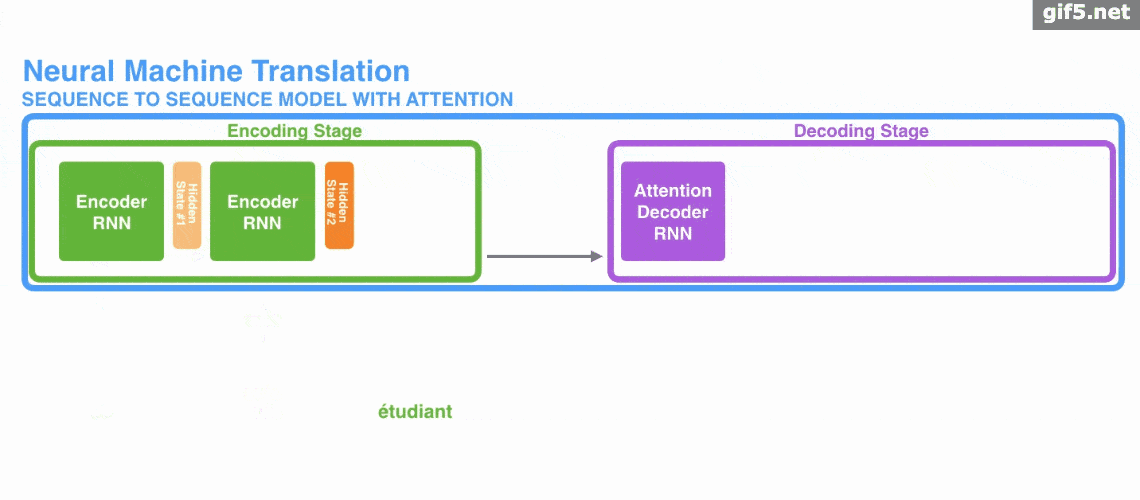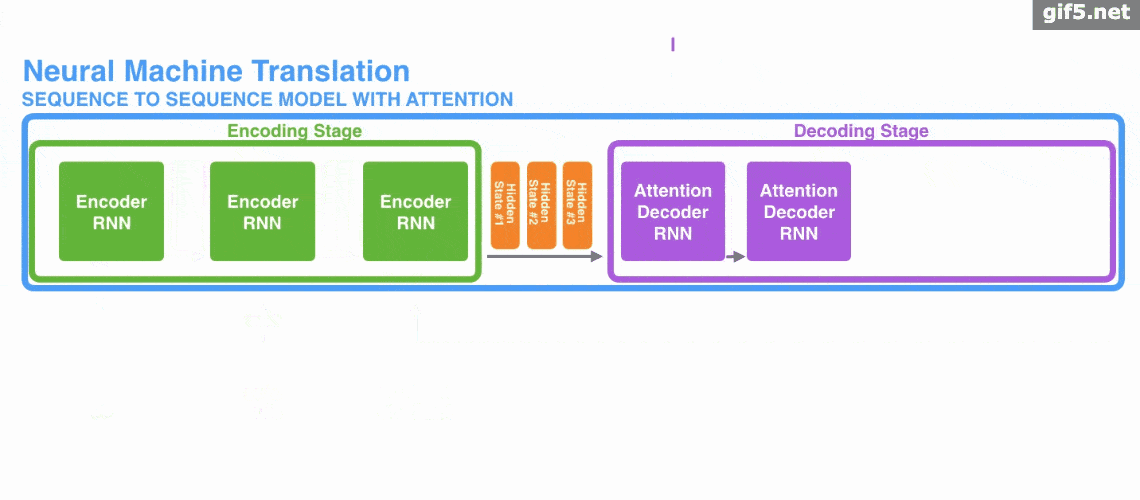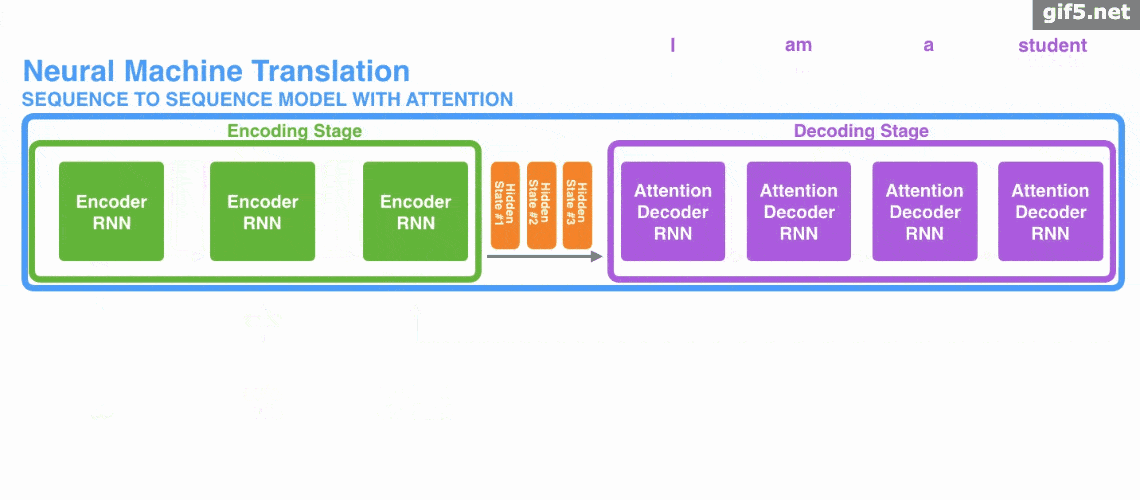
但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。
下面的图片则是脱离 Encoder-Decoder 框架后的原理图解。
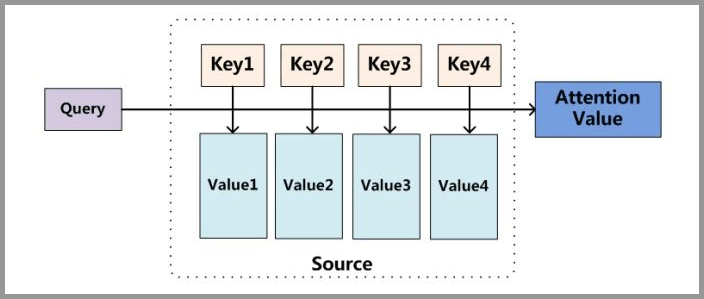
小故事讲解
上面的图看起来比较抽象,下面用一个例子来解释 attention 的原理:

图书管(source)里有很多书(value),为了方便查找,我们给书做了编号(key)。当我们想要了解漫威(query)的时候,我们就可以看看那些动漫、电影、甚至二战(美国队长)相关的书籍。
为了提高效率,并不是所有的书都会仔细看,针对漫威来说,动漫,电影相关的会看的仔细一些(权重高),但是二战的就只需要简单扫一下即可(权重低)。
当我们全部看完后就对漫威有一个全面的了解了。
Attention 原理的3步分解:

第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)->提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)->融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)->登峰造极(沉浸地大量练习)。
这也如同attention的发展脉络,RNN 时代是死记硬背的时期,attention 的模型学会了提纲挈领,进化到 transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。
要回答为什么 attention 这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。
——阿里技术
想要了解更多技术细节,可以看看下面的文章或者视频:
「文章」深度学习中的注意力机制
「文章」探索 NLP 中的 Attention 注意力机制及 Transformer 详解
Attention 的 N 种类型
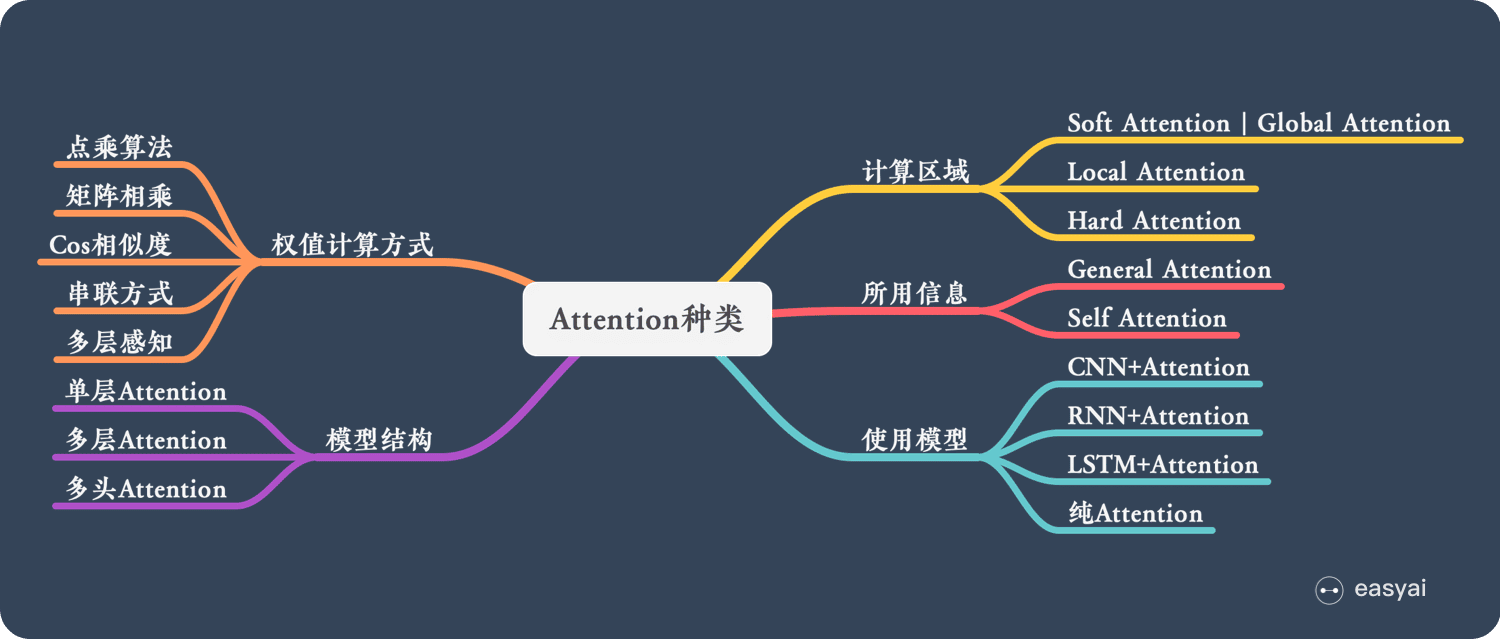
Attention 有很多种不同的类型:Soft Attention、Hard Attention、静态Attention、动态Attention、Self Attention 等等。下面就跟大家解释一下这些不同的 Attention 都有哪些差别。
由于这篇文章《Attention用于NLP的一些小结》已经总结的很好的,下面就直接引用了:
本节从计算区域、所用信息、结构层次和模型等方面对Attention的形式进行归类。
1. 计算区域
根据Attention的计算区域,可以分成以下几种:
1)Soft Attention,这是比较常见的Attention方式,对所有key求权重概率,每个key都有一个对应的权重,是一种全局的计算方式(也可以叫Global Attention)。这种方式比较理性,参考了所有key的内容,再进行加权。但是计算量可能会比较大一些。
2)Hard Attention,这种方式是直接精准定位到某个key,其余key就都不管了,相当于这个key的概率是1,其余key的概率全部是0。因此这种对齐方式要求很高,要求一步到位,如果没有正确对齐,会带来很大的影响。另一方面,因为不可导,一般需要用强化学习的方法进行训练。(或者使用gumbel softmax之类的)
3)Local Attention,这种方式其实是以上两种方式的一个折中,对一个窗口区域进行计算。先用Hard方式定位到某个地方,以这个点为中心可以得到一个窗口区域,在这个小区域内用Soft方式来算Attention。
2. 所用信息
假设我们要对一段原文计算Attention,这里原文指的是我们要做attention的文本,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息。
1)General Attention,这种方式利用到了外部信息,常用于需要构建两段文本关系的任务,query一般包含了额外信息,根据外部query对原文进行对齐。
比如在阅读理解任务中,需要构建问题和文章的关联,假设现在baseline是,对问题计算出一个问题向量q,把这个q和所有的文章词向量拼接起来,输入到LSTM中进行建模。那么在这个模型中,文章所有词向量共享同一个问题向量,现在我们想让文章每一步的词向量都有一个不同的问题向量,也就是,在每一步使用文章在该步下的词向量对问题来算attention,这里问题属于原文,文章词向量就属于外部信息。
2)Local Attention,这种方式只使用内部信息,key和value以及query只和输入原文有关,在self attention中,key=value=query。既然没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行Attention计算,相当于寻找原文内部的关系。
还是举阅读理解任务的例子,上面的baseline中提到,对问题计算出一个向量q,那么这里也可以用上attention,只用问题自身的信息去做attention,而不引入文章信息。
3. 结构层次
结构方面根据是否划分层次关系,分为单层attention,多层attention和多头attention:
1)单层Attention,这是比较普遍的做法,用一个query对一段原文进行一次attention。
2)多层Attention,一般用于文本具有层次关系的模型,假设我们把一个document划分成多个句子,在第一层,我们分别对每个句子使用attention计算出一个句向量(也就是单层attention);在第二层,我们对所有句向量再做attention计算出一个文档向量(也是一个单层attention),最后再用这个文档向量去做任务。
3)多头Attention,这是Attention is All You Need中提到的multi-head attention,用到了多个query对一段原文进行了多次attention,每个query都关注到原文的不同部分,相当于重复做多次单层attention:

最后再把这些结果拼接起来:

4. 模型方面
从模型上看,Attention一般用在CNN和LSTM上,也可以直接进行纯Attention计算。
1)CNN+Attention
CNN的卷积操作可以提取重要特征,我觉得这也算是Attention的思想,但是CNN的卷积感受视野是局部的,需要通过叠加多层卷积区去扩大视野。另外,Max Pooling直接提取数值最大的特征,也像是hard attention的思想,直接选中某个特征。
CNN上加Attention可以加在这几方面:
a. 在卷积操作前做attention,比如Attention-Based BCNN-1,这个任务是文本蕴含任务需要处理两段文本,同时对两段输入的序列向量进行attention,计算出特征向量,再拼接到原始向量中,作为卷积层的输入。
b. 在卷积操作后做attention,比如Attention-Based BCNN-2,对两段文本的卷积层的输出做attention,作为pooling层的输入。
c. 在pooling层做attention,代替max pooling。比如Attention pooling,首先我们用LSTM学到一个比较好的句向量,作为query,然后用CNN先学习到一个特征矩阵作为key,再用query对key产生权重,进行attention,得到最后的句向量。
2)LSTM+Attention
LSTM内部有Gate机制,其中input gate选择哪些当前信息进行输入,forget gate选择遗忘哪些过去信息,我觉得这算是一定程度的Attention了,而且号称可以解决长期依赖问题,实际上LSTM需要一步一步去捕捉序列信息,在长文本上的表现是会随着step增加而慢慢衰减,难以保留全部的有用信息。
LSTM通常需要得到一个向量,再去做任务,常用方式有:
a. 直接使用最后的hidden state(可能会损失一定的前文信息,难以表达全文)
b. 对所有step下的hidden state进行等权平均(对所有step一视同仁)。
c. Attention机制,对所有step的hidden state进行加权,把注意力集中到整段文本中比较重要的hidden state信息。性能比前面两种要好一点,而方便可视化观察哪些step是重要的,但是要小心过拟合,而且也增加了计算量。
3)纯Attention
Attention is all you need,没有用到CNN/RNN,乍一听也是一股清流了,但是仔细一看,本质上还是一堆向量去计算attention。
5. 相似度计算方式
在做attention的时候,我们需要计算query和某个key的分数(相似度),常用方法有:
1)点乘:最简单的方法, 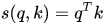
2)矩阵相乘:
3)cos相似度: 
4)串联方式:把q和k拼接起来, 
5)用多层感知机也可以: 
如何选择机器学习模型
有没有想过我们如何将机器学习算法应用于问题,以便分析,可视化,发现趋势并找到数据中的相关性?在本文中,我将讨论建立机器学习模型的常见步骤以及为数据选择正确模型的方法。本文的灵感来自于常见的访谈问题,这些问题被问及如何处理数据科学问题以及为什么选择上述模型。
拆解 YouTube 下一个视频的推荐机制
本文详解 YouTube 的推荐机制,他们是如何给用户推荐下一个视频的。
特征选择:重要性及方法详解
在本文中,我将与您分享我在Fiverr领导的上一个项目期间研究的一些方法。
您将获得有关我尝试的基本方法以及更复杂的方法的一些想法,该方法获得了最佳效果-删除了60%以上的功能,同时保持了准确性并为我们的模型实现了更高的稳定性。我还将分享我们对该算法的改进。
Encoder-Decoder 和 Seq2Seq
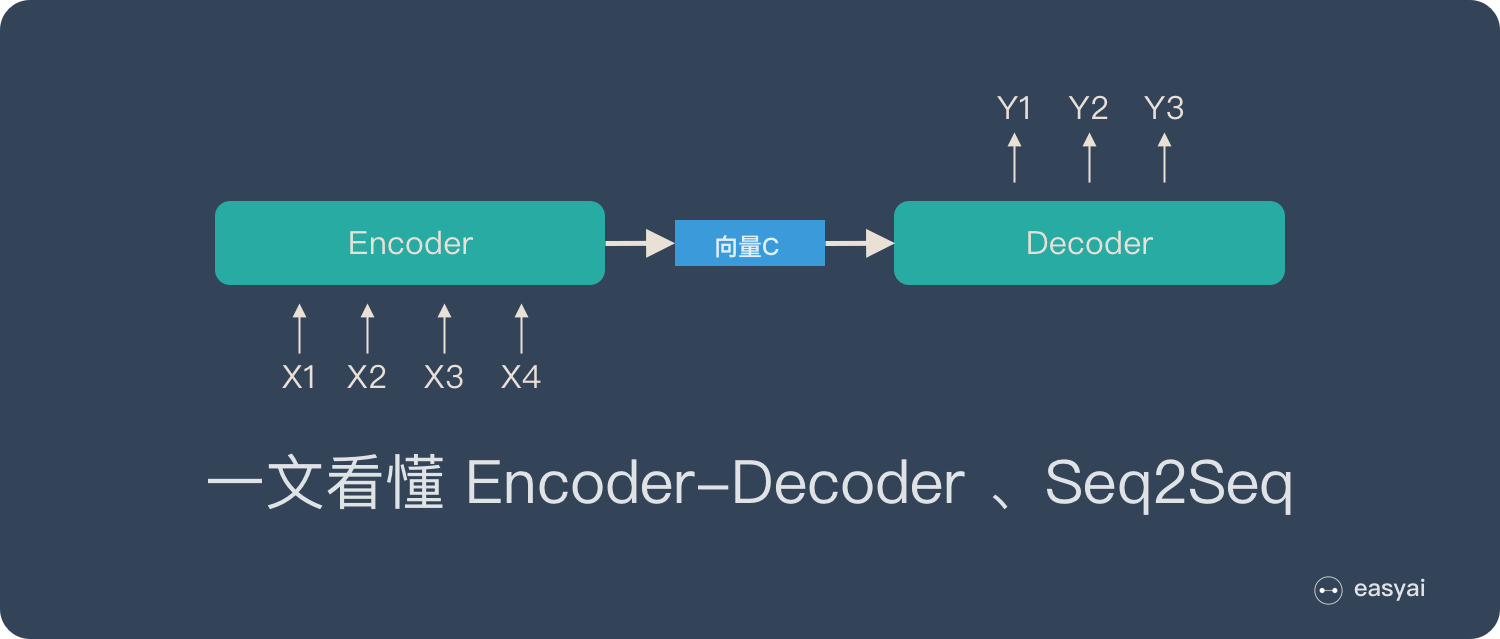
Encoder-Decoder 是 NLP 领域里的一种模型框架。它被广泛用于机器翻译、语音识别等任务。
本文将详细介绍 Encoder-Decoder、Seq2Seq 以及他们的升级方案Attention。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 Encoder-Decoder ?
Encoder-Decoder 模型主要是 NLP 领域里的概念。它并不特值某种具体的算法,而是一类算法的统称。Encoder-Decoder 算是一个通用的框架,在这个框架下可以使用不同的算法来解决不同的任务。
Encoder-Decoder 这个框架很好的诠释了机器学习的核心思路:
将现实问题转化为数学问题,通过求解数学问题,从而解决现实问题。
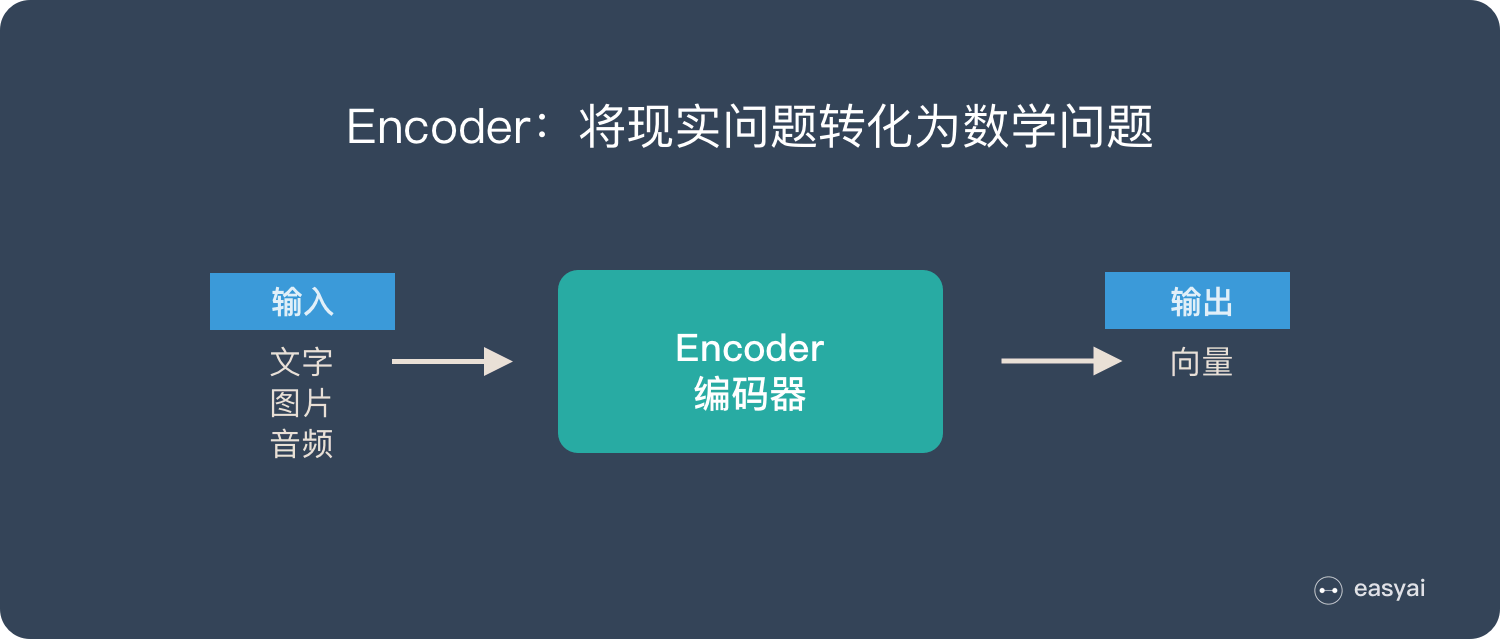
Encoder 又称作编码器。它的作用就是「将现实问题转化为数学问题」
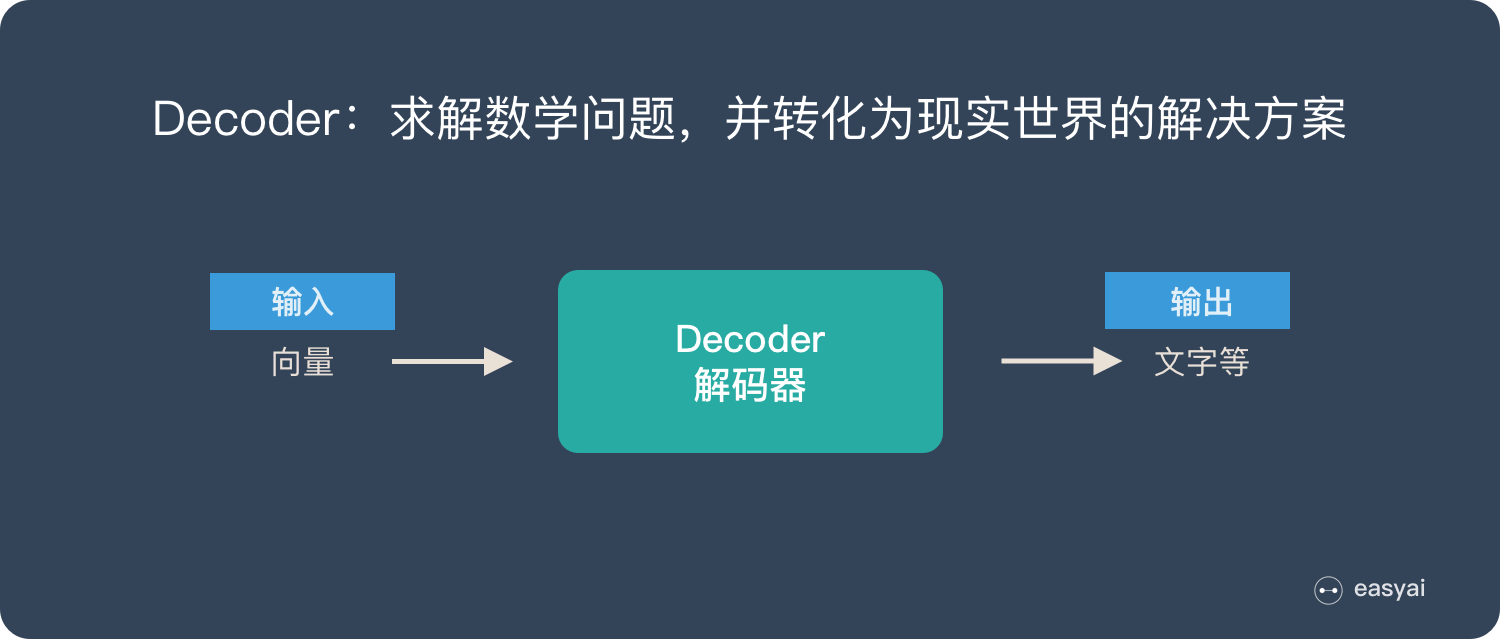
Decoder 又称作解码器,他的作用是「求解数学问题,并转化为现实世界的解决方案」
把 2 个环节连接起来,用通用的图来表达则是下面的样子:
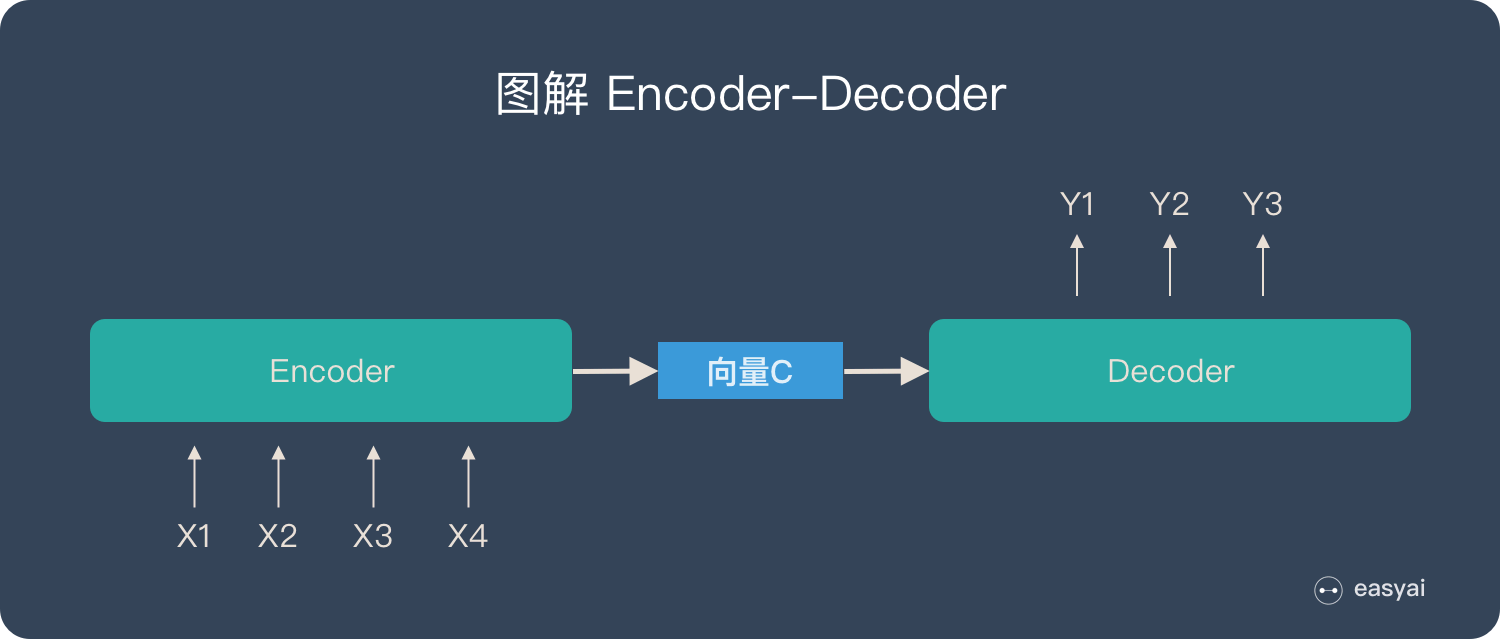
关于 Encoder-Decoder,有2 点需要说明:
- 不论输入和输出的长度是什么,中间的「向量 c」 长度都是固定的(这也是它的缺陷,下文会详细说明)
- 根据不同的任务可以选择不同的编码器和解码器(可以是一个 RNN ,但通常是其变种 LSTM 或者 GRU )
只要是符合上面的框架,都可以统称为 Encoder-Decoder 模型。说到 Encoder-Decoder 模型就经常提到一个名词—— Seq2Seq。
什么是 Seq2Seq?
Seq2Seq(是 Sequence-to-sequence 的缩写),就如字面意思,输入一个序列,输出另一个序列。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。例如下图:
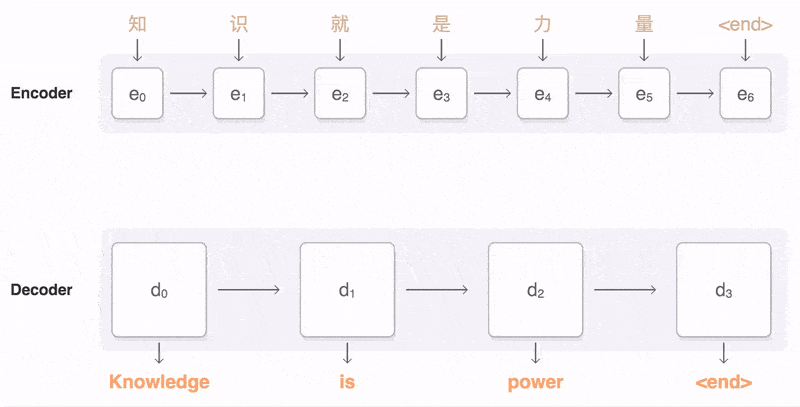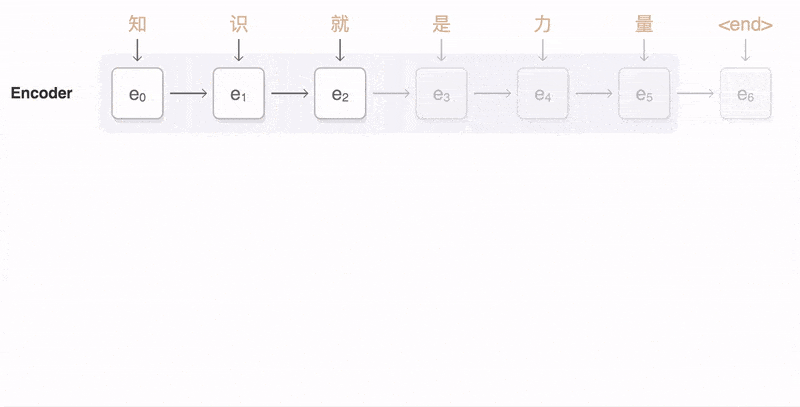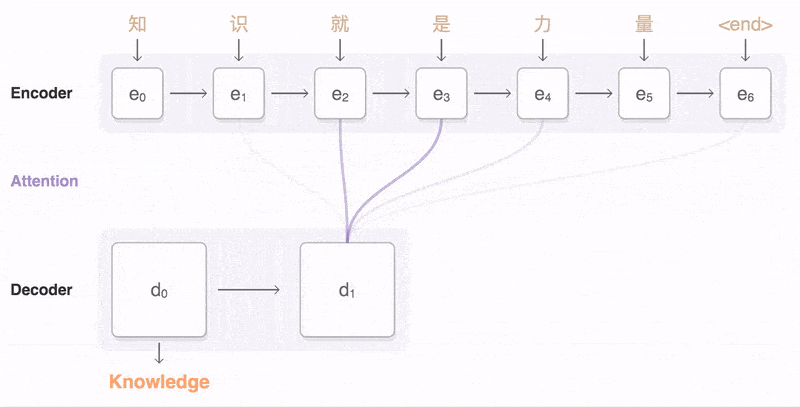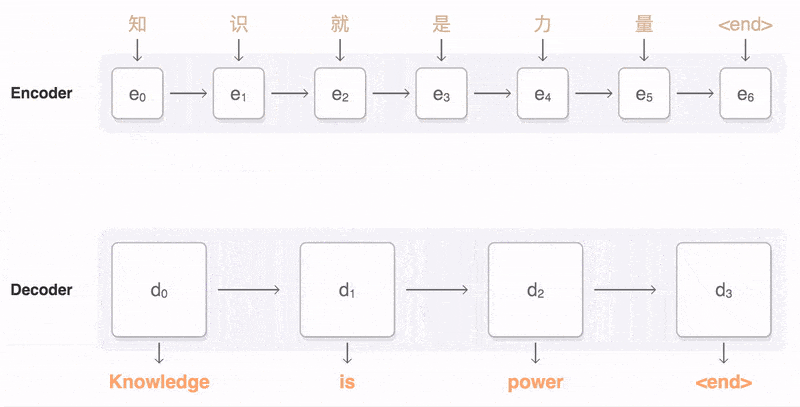
如上图:输入了 6 个汉字,输出了 3 个英文单词。输入和输出的长度不同。
Seq2Seq 的由来
在 Seq2Seq 框架提出之前,深度神经网络在图像分类等问题上取得了非常好的效果。在其擅长解决的问题中,输入和输出通常都可以表示为固定长度的向量,如果长度稍有变化,会使用补零等操作。
然而许多重要的问题,例如机器翻译、语音识别、自动对话等,表示成序列后,其长度事先并不知道。因此如何突破先前深度神经网络的局限,使其可以适应这些场景,成为了13年以来的研究热点,Seq2Seq框架应运而生。
「Seq2Seq」和「Encoder-Decoder」的关系
Seq2Seq(强调目的)不特指具体方法,满足「输入序列、输出序列」的目的,都可以统称为 Seq2Seq 模型。
而 Seq2Seq 使用的具体方法基本都属于Encoder-Decoder 模型(强调方法)的范畴。
总结一下的话:
- Seq2Seq 属于 Encoder-Decoder 的大范畴
- Seq2Seq 更强调目的,Encoder-Decoder 更强调方法
Encoder-Decoder 有哪些应用?

机器翻译、对话机器人、诗词生成、代码补全、文章摘要(文本 – 文本)
「文本 – 文本」 是最典型的应用,其输入序列和输出序列的长度可能会有较大的差异。
Google 发表的用Seq2Seq做机器翻译的论文《Sequence to Sequence Learning with Neural Networks》
语音识别(音频 – 文本)
语音识别也有很强的序列特征,比较适合 Encoder-Decoder 模型。
Google 发表的使用Seq2Seq做语音识别的论文《A Comparison of Sequence-to-Sequence Models for Speech Recognition》

图像描述生成(图片 – 文本)
通俗的讲就是「看图说话」,机器提取图片特征,然后用文字表达出来。这个应用是计算机视觉和 NLP 的结合。
图像描述生成的论文《Sequence to Sequence – Video to Text》

Encoder-Decoder 的缺陷
上文提到:Encoder(编码器)和 Decoder(解码器)之间只有一个「向量 c」来传递信息,且 c 的长度固定。
为了便于理解,我们类比为「压缩-解压」的过程:
将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 3000X3000 像素的图片也压缩到 100KB,看上去就模糊了。
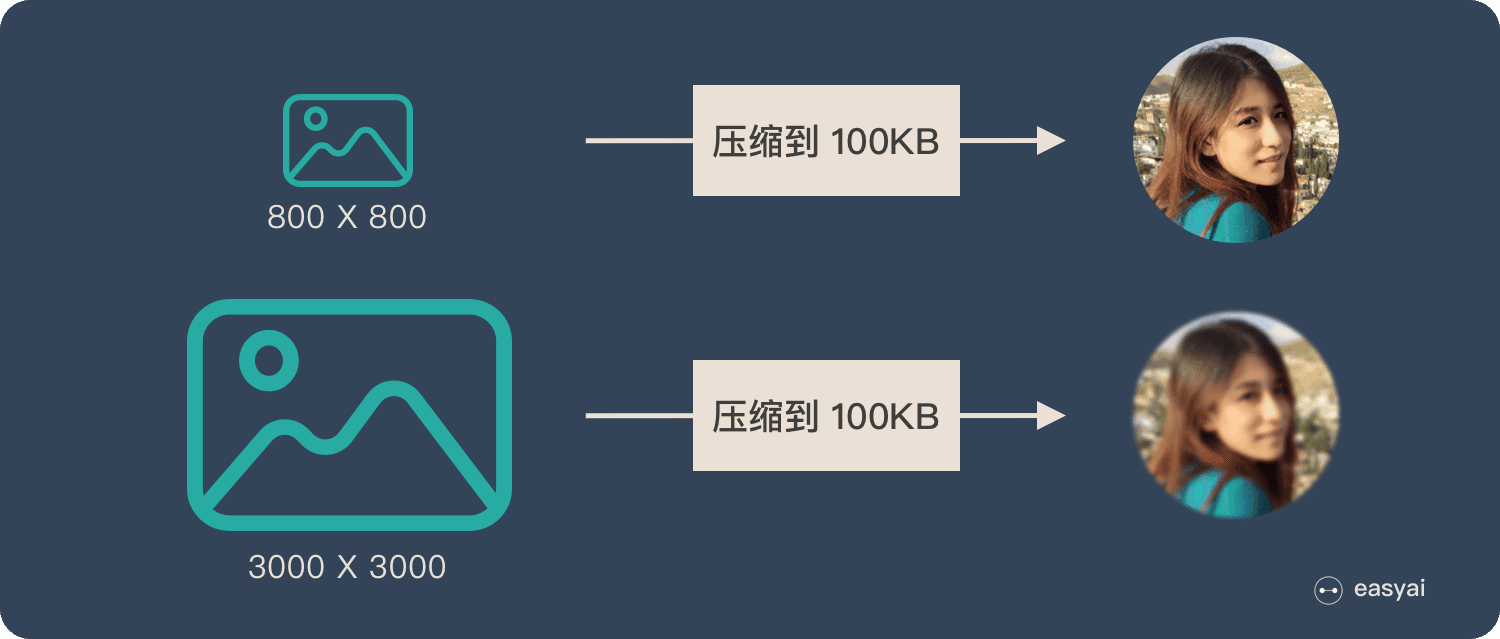
Encoder-Decoder 就是类似的问题:当输入信息太长时,会丢失掉一些信息。
Attention 解决信息丢失问题
Attention 机制就是为了解决「信息过长,信息丢失」的问题。
Attention 模型的特点是 Eecoder 不再将整个输入序列编码为固定长度的「中间向量 C」 ,而是编码成一个向量的序列。引入了 Attention 的 Encoder-Decoder 模型如下图:
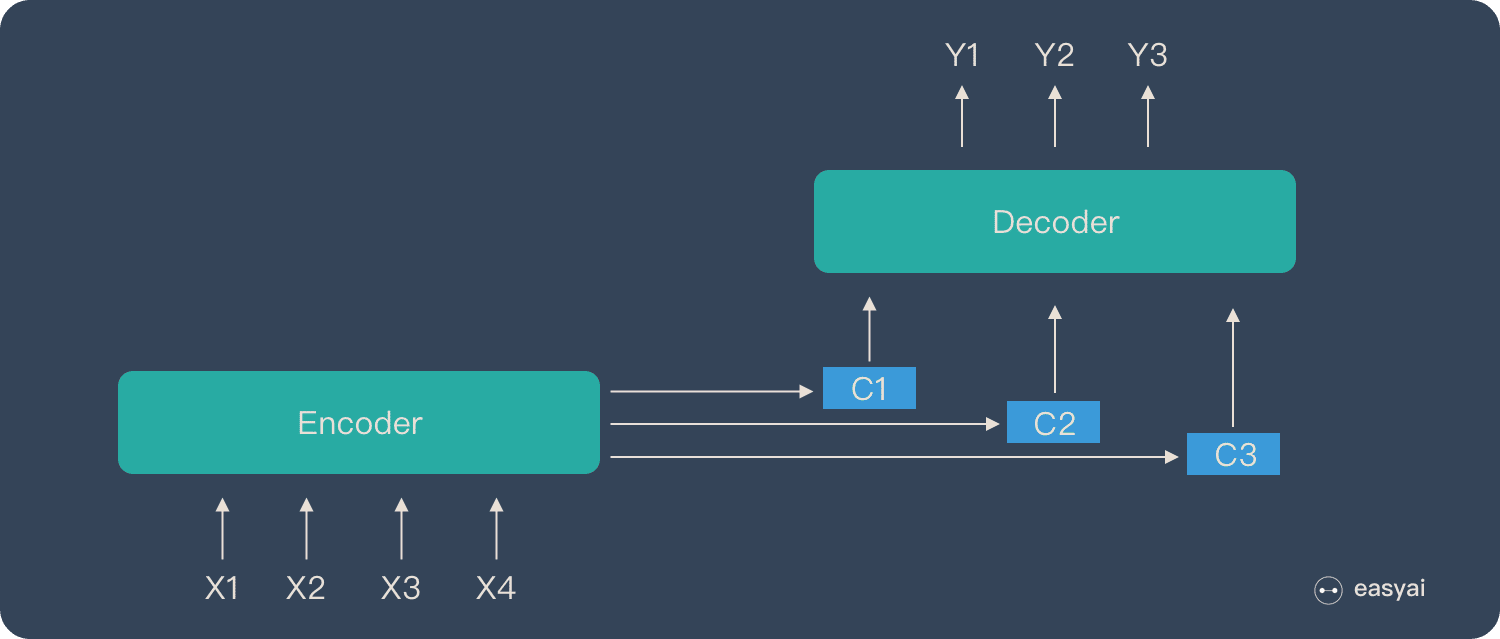
这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。而且这种方法在翻译任务中取得了非常不错的成果。
Attention 是一个很重要的知识点,想要详细了解 Attention,请查看《一文看懂 Attention(本质原理+3大优点+5大类型)》
NLP 领域里的8 种文本表示方式及优缺点
文本表示( text representation)是NLP任务中非常基础,同时也非常重要的一部分。本文将介绍文本表示的发展历史及各方法的优缺点