

在最近由Google研究人员发布并在RecSys 2019(丹麦哥本哈根)上发表的论文[ 1 ]中,提供了关于他们的视频平台Youtube如何推荐观看哪些视频的见解。在阅读这篇文章后,我将尝试总结我的发现。
问题
当用户在Youtube上观看视频时,将显示用户可能会按特定顺序喜欢的推荐视频列表。本文着重于两个目标:
1)需要优化不同的目标;尚未定义确切的目标功能,但将目标分为参与度目标(点击次数,时间花费)和满意度目标(喜欢率,解雇率)。
2)减少由于位置而使用户隐式引入的选择偏见,即使排名较低的视频可能会带来更高的参与度和满意度,但由于该位置,用户更有可能点击第一个推荐。
如何有效地学习减少这种偏见是一个悬而未决的问题。
方法
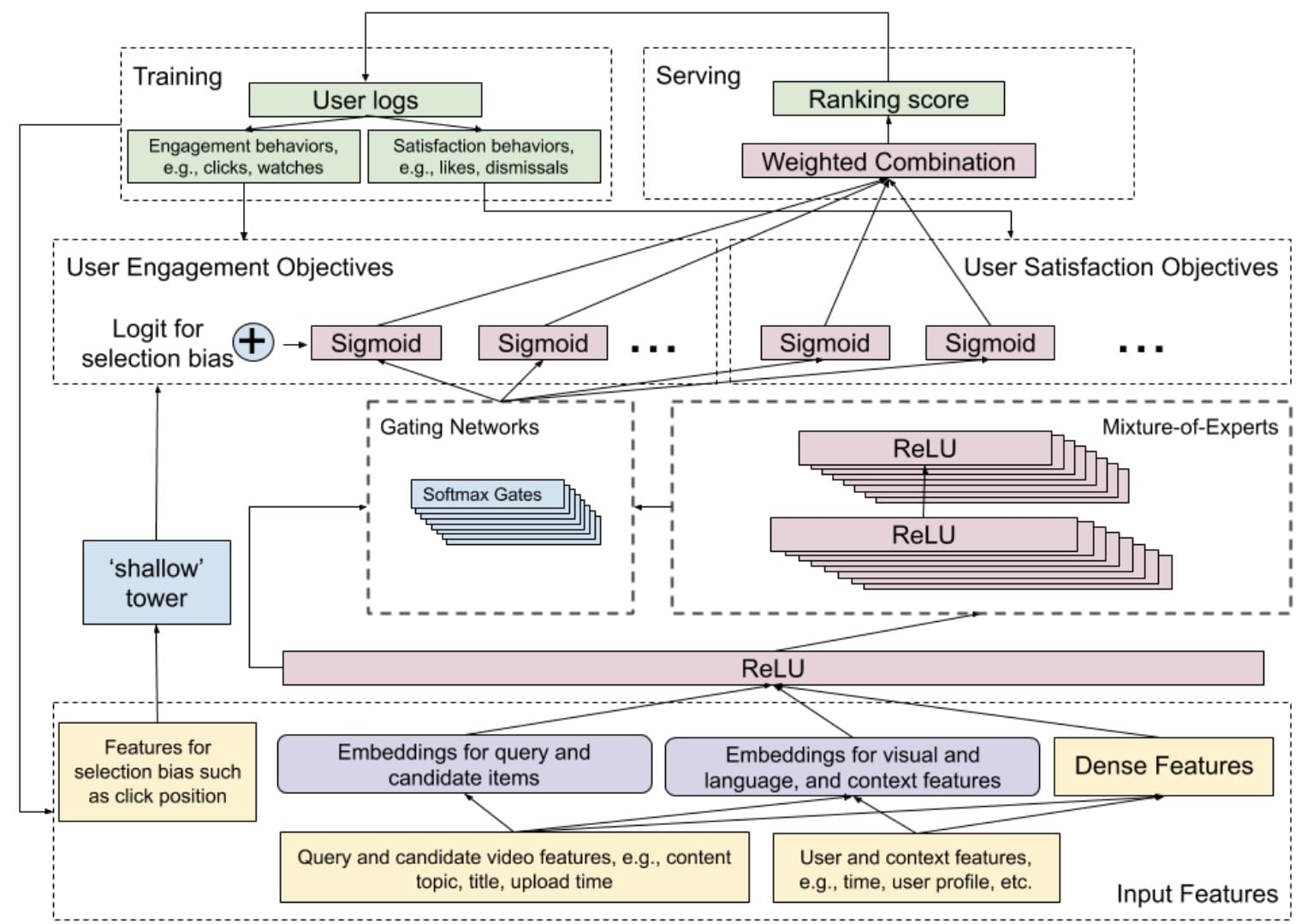
本文中描述的模型着重于两个主要目标。宽而深[ 2使用的模型架构结合了宽模型线性模型(记忆)和深层神经网络(泛化)的功能。广泛和深入的模型将为每个定义的目标(参与度和满意度)生成预测。将目标归类为二进制分类问题(即,是否喜欢视频)和回归问题(即,视频的等级)。在此模型的顶部添加了一个单独的排名模型。这只是作为不同预测目标的输出向量的加权组合。手动调整这些权重以实现不同目标的最佳性能。提出了先进的方法,例如成对或成对的方法来提高性能,但是由于增加了计算时间,因此无法实现生产。
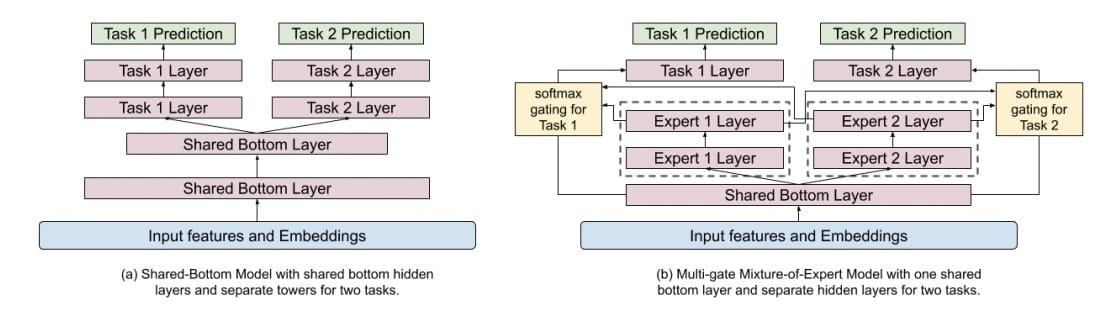
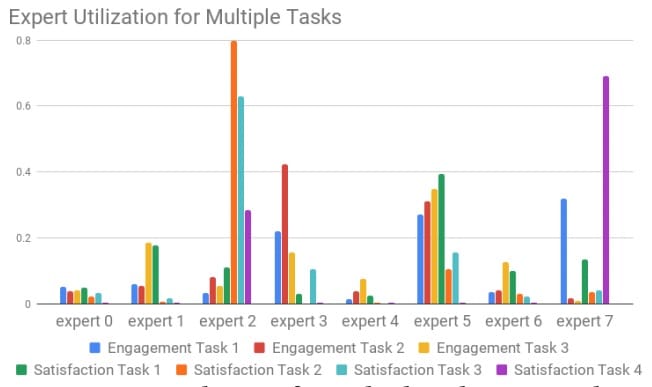
宽和深模型的深层部分是多门专家混合(MMoE)[ 3]模型被采用。输入当前视频的功能(内容,标题,主题,上传时间等)和正在观看的用户(时间,用户个人资料等)。MMoE模型背后的概念基于有效地共享不同目标的权重。共享的底层分为多个专家,所有专家都用于预测不同的目标。每个目标都有一个门功能。此选通功能是softmax功能,具有原始共享层和不同专家层的输入。该softmax函数将确定哪些专家层对于不同目标很重要。如图3所示,不同的专家对于不同的目标更为重要。
该模型的主要部分集中于减少推荐视频位置所引入的系统选择偏差。这个较宽的部分被称为“浅塔”,它可以是简单的线性模型,它使用简单的功能(例如单击位置视频和用于观看视频的设备)。浅塔的输出与MMoE模型的输出相结合,后者是Wide&Deep模型体系结构的关键组成部分。这样,模型将更加专注于视频的位置。在训练期间,使用10%的辍学率来防止位置特征在模型中变得太重要。如果您不使用Wide&Deep架构,而是将位置添加为单个要素,则该模型可能根本不关注该要素。
结果
本文的结果表明,用MMoE替换共享底层可以提高模型的参与度(观看推荐视频所花费的时间)和满意度(调查响应)的性能。MMoE专家的数量和乘法运算的增加进一步提高了模型的性能。由于计算限制,无法在实时设置中增加此数字。

进一步的结果表明,通过减少由于使用浅塔而导致的选择偏差,可以提高接合度。与仅在MMoE模型中添加输入功能相比,这是一个重大改进。

有趣的话
- 尽管Google拥有强大的计算基础架构,但在培训和服务成本方面仍需谨慎。
- 通过使用广泛而深入的模型,您可以设计一个预定义对您而言很重要的功能的网络。
- 当您需要具有多目标的模型时,MMoE模型会非常有效。
- 即使具有强大而复杂的模型架构,人类仍在手动调整最后一层的权重,以根据不同的客观预测确定实际排名。
关于作者
Tim Elfrink是荷兰数据科学咨询公司Vantage AI的数据科学家。如果您需要帮助为数据创建机器学习模型,请随时通过info@vantage-ai.com与我们联系。
资源
[1]原始论文:https://dl.acm.org/citation.cfm?id = 3346997[2]深度学习的工作原理说明:https://ai.googleblog.com/2016/06/wide- deep-learning-better-together-with.html
[3]带有视频的MMoE解释:https ://www.kdd.org/kdd2018/accepted-papers/view/modeling-task-relationships-in-multi-task- 多门混合学习
本文转自 medium,原文地址

Comments