

创建出色的机器学习系统是一门艺术。
构建出色的机器学习系统时,需要考虑很多因素。但是经常发生的情况是,我们作为数据科学家只担心项目的某些部分。
但是,我们是否曾经考虑过拥有模型后将如何部署模型?
我见过很多机器学习项目,但其中许多注定要失败,因为它们从一开始就没有制定生产计划。
这篇文章是关于一个成功的ML项目的过程要求的-一个投产的项目。
1.在开始时建立基线
您实际上并不需要建立模型来获得基准结果。
假设我们将使用RMSE作为时间序列模型的评估指标。我们在测试集上评估了模型,RMSE为3.64。
3.64是不错的RMSE吗?我们怎么知道?我们需要基线RMSE。
这可能来自用于同一任务的当前使用的模型。或通过使用一些非常简单的启发式方法。对于时间序列模型,失败的基准是最后一天的预测。即,预测前一天的数字。
或图像分类任务如何。抽取1000个标记的样本,并按人类分类。人为准确性可以成为您的基准。如果人类无法在任务上获得70%的预测准确性,那么您的模型达到类似水平时,您总是可以考虑使流程自动化。
学习:在创建模型之前,请先了解要获得的结果。放出一些期望值只会让您和您的客户失望。
2.持续集成是前进的道路

您现在已经创建了模型。它的性能优于本地测试数据集上的基线/当前模型。我们应该前进吗?
我们有两个选择-
- 进入无限循环以进一步改进我们的模型。
- 在生产环境中测试我们的模型,获得更多有关可能出问题的见解,然后通过持续集成继续改进我们的模型。
我是第二种方法的粉丝。在他的真棒 第三场 命名构建学习机项目在Coursera 深度学习专业,安德鲁·Ng表示-
“不要一开始就尝试设计和构建完美的系统。取而代之的是,可能在短短几天内快速构建和训练基本系统。即使基本系统离您可以构建的“最佳”系统相去甚远,检查基本系统的功能还是很有价值的:您将迅速找到线索,向您显示最有价值的投资方向。”
完成比完美更重要。
学习:如果您的新模型比生产中的当前模型更好,或者新模型比基准更好,那么等待上线是没有意义的。
3.您的模型可能会投入生产
您的模型是否比基准更好?它在本地测试数据集上的性能更好,但总体上是否真的能很好地工作?
要测试您的模型优于现有模型的假设的有效性,可以设置A / B测试。一些用户(测试组)看到来自模型的预测,而某些用户(控件)看到来自先前模型的预测。
实际上,这是部署模型的正确方法。您可能会发现实际上您的模型并不像看起来那样好。
错误的确不是错,错误的是不要期望我们会错。
很难指出为什么模型在生产环境中表现不佳的真正原因,但某些原因可能是:
- 您可能会看到实时获得的数据与训练数据有很大的不同。
- 或者您没有正确完成预处理管道。
- 否则您无法正确衡量性能。
- 也许您的实现中存在错误。
学习: 不要全面投入生产。A / B测试始终是前进的绝妙方法。准备好要依靠的东西(也许是旧型号)。可能总会有可能无法预料的事情崩溃。
4.您的模型甚至可能无法投入生产
我创建了这个令人印象深刻的ML模型,它提供了90%的准确性,但是获取预测大约需要10秒。
可以接受吗?也许对于某些用例,但实际上没有。
过去,有许多Kaggle比赛的获胜者最终创造出了怪兽合奏,从而在排行榜上名列前茅。下面是一个特别的令人兴奋的示例模型,该模型用于赢得Kaggle的Otto分类挑战:
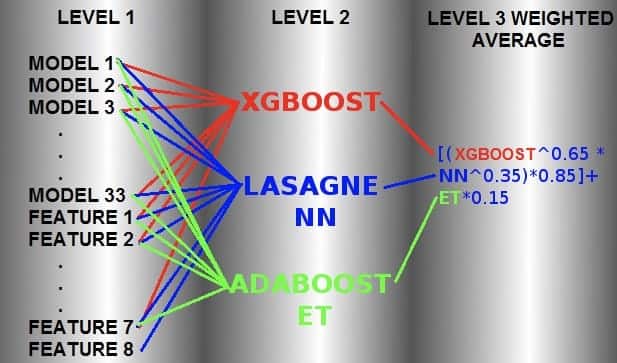
另一个例子是Netflix百万美元推荐引擎挑战赛。 由于涉及的工程成本,Netflix团队最终 从未使用成功的解决方案。
那么如何在机器上使模型准确又容易呢?
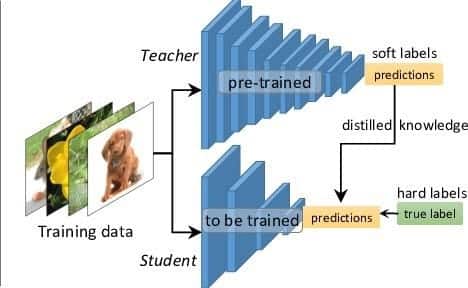
这是师生模型或知识蒸馏的概念。在知识蒸馏中,我们在已经训练好的较大的老师模型上训练了较小的学生模型。
在这里,我们使用教师模型中的软标签/概率,并将其用作学生模型的训练数据。
关键是老师正在输出课堂概率–“软标签”而不是“硬标签”。例如,水果分类器可能会说“ Apple 0.9,Pear 0.1”而不是“ Apple 1.0,Pear 0.0”。何必?因为这些“软标签”比原始标签提供的信息更多-告诉学生,是的,特定的苹果确实有点像梨。学生模型通常可以非常接近教师水平的表现,即使使用的参数减少了1-2个数量级!— 来源
学习:有时候,我们在预测时没有很多可用的计算,因此我们希望有一个更轻便的模型。我们可以尝试建立更简单的模型,或者尝试针对此类用例使用知识提炼。
5.维护和反馈循环
世界不是恒定不变的,您的模型权重也是如此
我们周围的世界正在迅速变化,两个月前可能适用的方法现在可能已不重要。在某种程度上,我们建立的模型是对世界的反映,如果世界在变化,我们的模型应该能够反映这种变化。
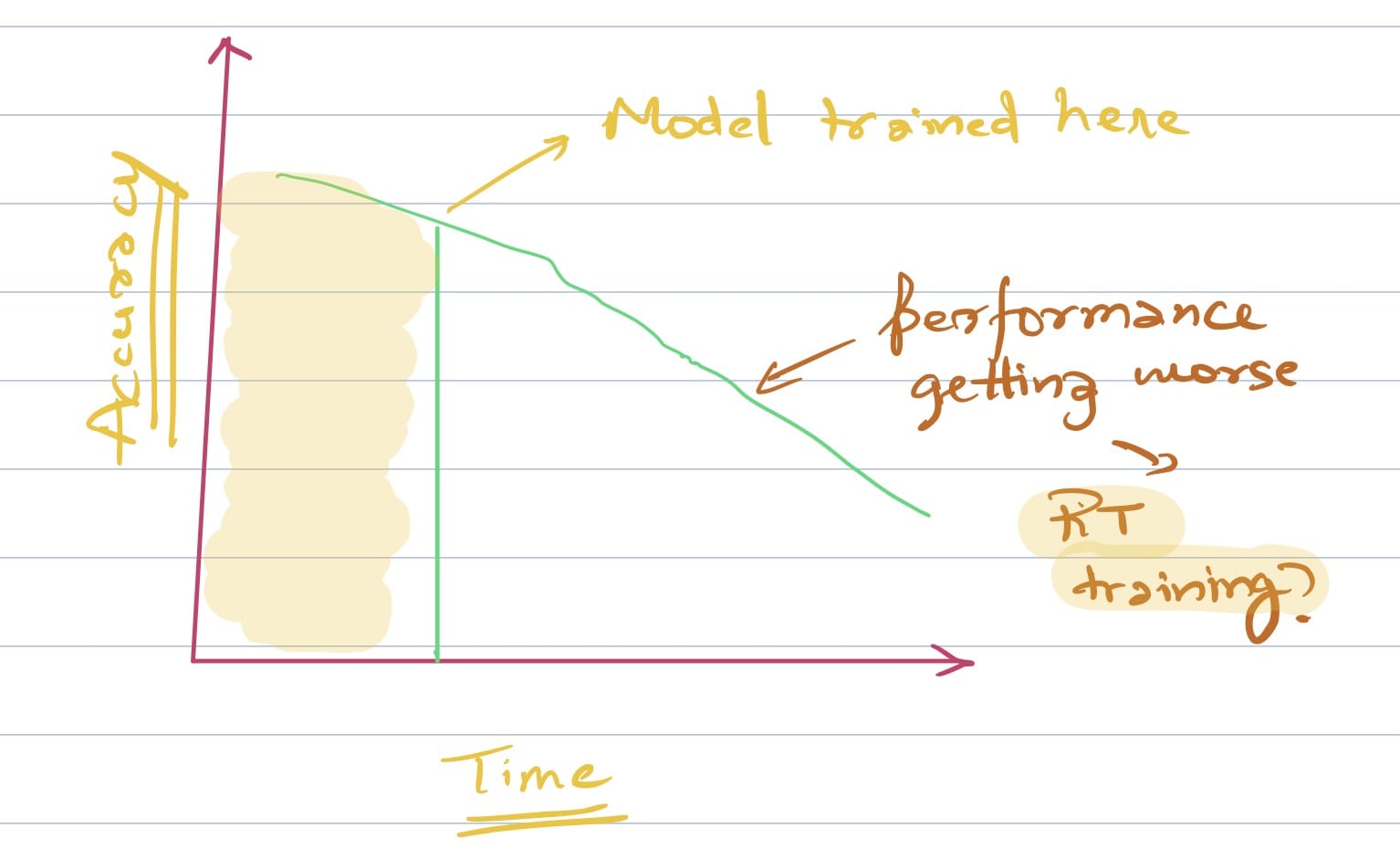
模型性能通常会随着时间而下降。
因此,我们必须从一开始就考虑在维护周期中升级模型的方法。
此周期的频率完全取决于您要解决的业务问题。在广告预测系统中,用户往往会变幻无常,并且购买模式不断出现,因此频率需要非常高。在评论情绪分析系统中,频率不必那么高,因为语言不会改变其结构。
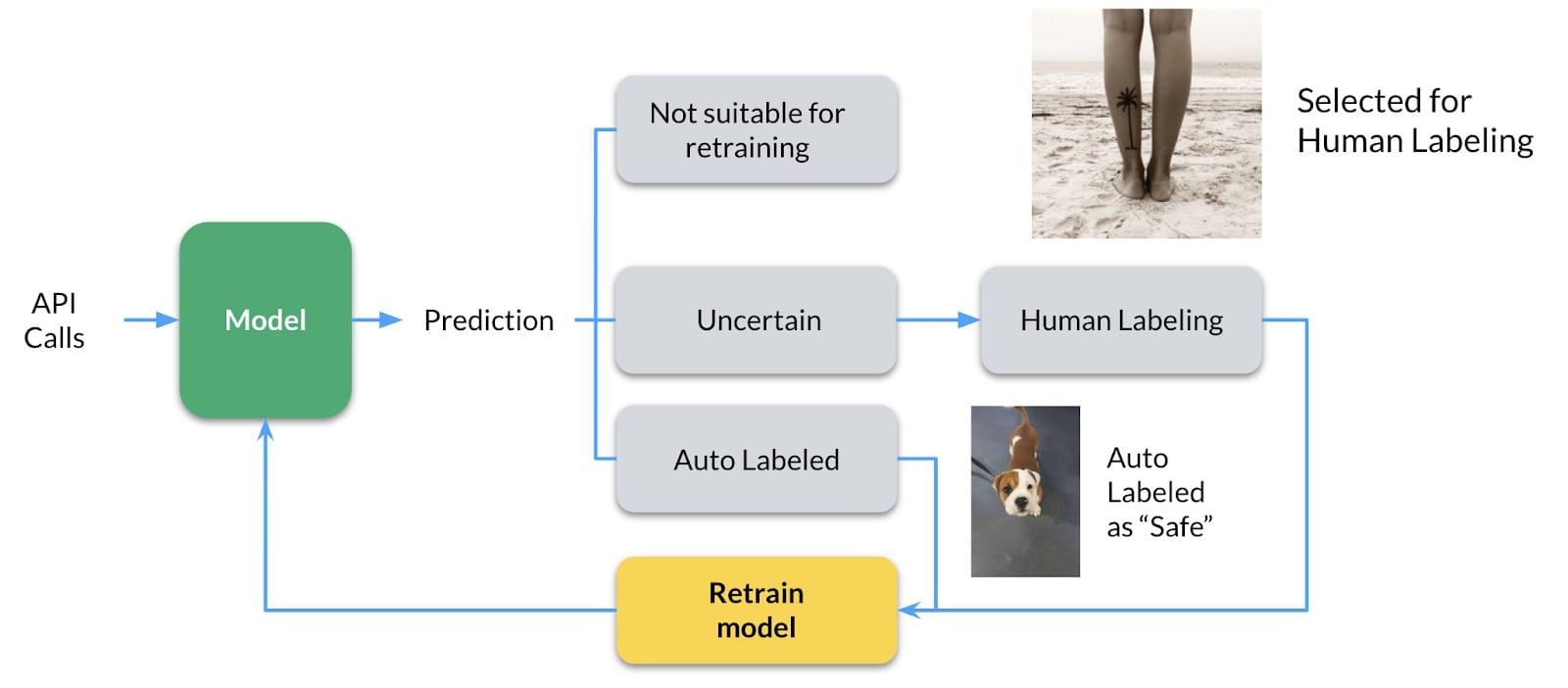
我还想承认反馈循环在机器学习系统中的重要性。假设您预测在狗对猫分类器中,特定图像是狗的可能性很小。我们可以从这些低置信度的例子中学到什么吗?您可以将其发送到手动审阅,以检查它是否可以用于重新训练模型。这样,我们就可以在不确定的实例上训练分类器。
学习:考虑生产时,还要提出一个计划,以使用反馈来维护和改进模型。
结论
在考虑将模型投入生产之前,这些都是我发现重要的事情。
尽管这并不是您需要考虑的事情的清单,也可能会出错的事情的清单不完整,但无疑会在您下次创建机器学习系统时起到深思熟虑的作用。
本文转自medium,原文地址


Comments