

本文转自机器之能,原文地址
作者简介:童超,创新奇智产品总监,负责产品规划及管理工作。毕业于乔治华盛顿大学,获得MBA学位,并于香港科技大学获得理学硕士学位。
最近AI伦理科学家Timnit Gebru被大佬Jeff Dean炒鱿鱼的事情搞的沸沸扬扬,两人几番论战也没有明确的结论。但从与朋友的交谈中,让大家更感兴趣的不是这件事情的是非因果,而是Gebru的职位:AI伦理科学家,这是个什么角色,作用是什么?AI又与“伦理”有何联系……而有“伦理”的AI又需要是什么样子?


为何AI会与伦理这个社会科学产生交集
AI是一门自然科学,伦理又是比较纯粹的社会科学,有一些研究背景的同学就会发现,当两者发生交集的时候,我们面对的很有可能是一个哲学问题了……我们这里不讨论让人纠结和烧脑的哲学逻辑,只涉及AI为何会产生这样与传统技术不同的问题。

“不确定”的本质让AI的决策天生隐含争议
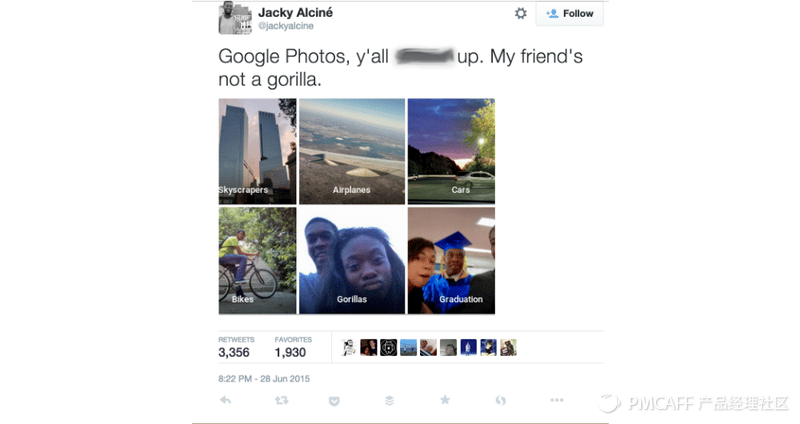
我们打开AI算法(机器学习)的盒子,会发现任何AI模型的输出结果都可以分解为一连串的小数 – 概率,比如AI的结果输出某人信用卡的交易是一笔盗刷,实际上模型输出的结果是P(盗刷 | 也许是个条件概率) = 0.971。这样的决策输出,显然与我们普适接受的“铁证如山”、“铁一般的事实”有不小的出入,这种天生带来的不确定性会让AI参与甚至决定一些重要的决定时收到质疑,甚至争议。那么,当我们利用AI的能力时,如何可以明晰或者接受这种不确定性,就显得尤为重要。更为关键的是,理解并接受这种不确定性不仅仅是技术问题,更是一个需要完整、全面思考的认知问题。一个备受争议的例子,强如Google,还是会犯下如此严重的错误:把我们的黑人朋友识别为大猩猩……Google因为这样的错误,又需要多少公关资源来弥补这样的“不确定”输出?
AI的出现转换了决策主体,必然带来伦理的挑战
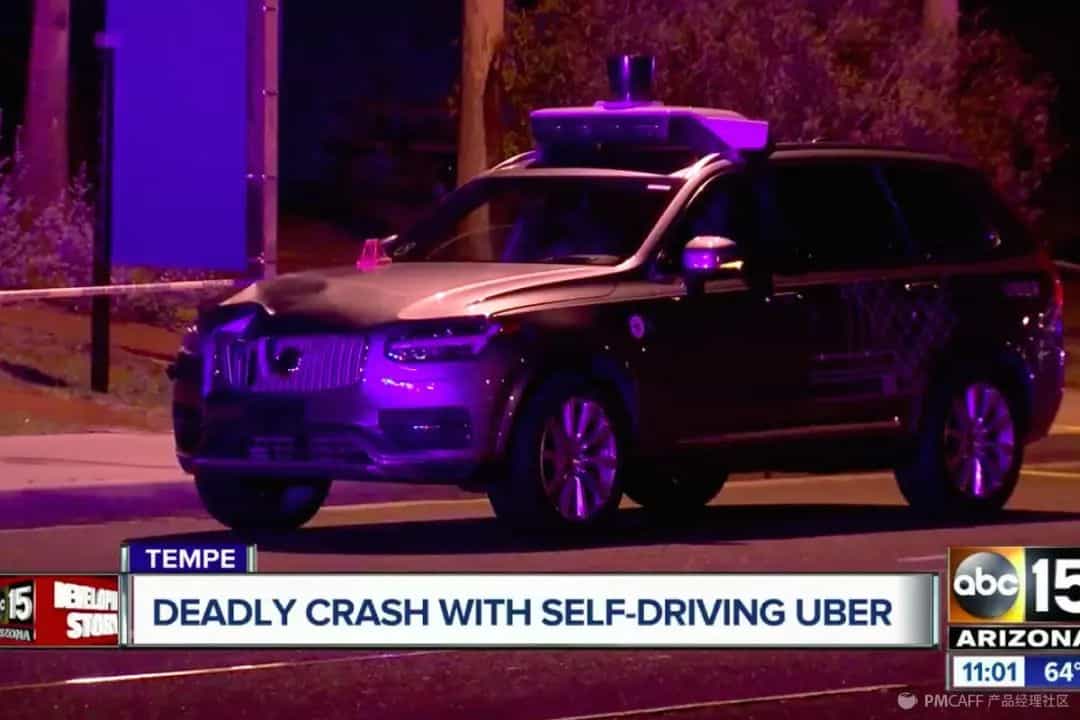
当我们放开双手双脚,把自己交给一个L4的自动驾驶车辆时,显然在道路上的车辆决策主体发生了转移:从司机转移到了车辆,或者更具体的 – AI。与此同时,我们更应该意识到,决策主体的转移会带来责任的转移,无论是车辆安全、道路安全还是行人安全,AI将负担起或者应当成为这种责任主体。我们假设,在高速路上,正在无人驾驶的车辆出现了事故,撞击了行人或者一头鹿,那么谁来负这个最终的责任?车辆的生产商是否需要负责?研发AI的企业是否需要负责?为AI采集和标注数据的个人需要负责?毫无疑问,如果我们把这样的一个系统逻辑延伸到任何行业尤其是与人类关键行为相关的场景时,AI的这种快速革新替代带来的是伦理和立法的重新审视,保证我们安全无忧地与AI相处。
号外 – 关于美国政府对Trustworthy AI的行政命令
就在12月3日,白宫发布了针对AI应用的行政命令(行政命令的定义请各位自行补课)
《Executive Order on Promoting the Use of Trustworthy Artificial Intelligence in the Federal Government》

总结来讲,白宫要求与美国政府预算相关的所有AI应用都要保证遵循以下的原则:
(1) Lawful and respectful of Nation’s value – 服务国家利益
(2) Purposeful and performance-driven – 实用优先
(3) Accurate, reliable and effective – 性能优异
(4) Safe, secure and resilient – 安全保障
(5) Understandable – 用户尤其是SME(Subject Matter Expert)可以理解
(6) Responsible and traceable – AI的权责体系分明
(7) Regularly monitored – AI全程可追踪
(8) Transparent – 面向监管的100%透明
(9) Accountable – 组织围绕AI的体系保障
以上的原则,全部都对AI的设计、建设和运营提出了完全新层次的要求,不仅要可用,好用,更要敢用,放心用,公平的用。能够明确的是,正在发生的科技大战中,美国已经在布局更完整的AI体系了。
可信的AI系统组成
在这里,我们用一个典型的AI流程来观察一个可信的AI系统都需要包含什么元素,用接下来的几个小节来分别展开具体的内容。

可信的AI系统 – 从数据开始
说到Timnit Gebru,我们不妨从她的一篇论文开始探索如何建立一个可信的、AI可用的数据资源,也可以解释AI伦理科学家的一部分工作。以下的结构一部分参考了Gebru的论文《Datasheets for Datasets》,具体内容不再标注:
数据对于机器学习可以类比粮食对人类的重要程度。当我们启动AI项目时,第一步必然是要厘清涉及的数据资源,为我们需要的数据集建立完整的生命周期的档案,能够帮助参与到AI项目的所有人(包含数据工程师、算法工程师、业务专家)对于这个最重要资产有全面和一致的认识。在这里,我们使用一种静态(同样是这个方式的现有局限)的方式做出记录,通过一系列的问题引导出需要的信息,逐步形成一份数据集的数据表(Datasheet)。从数据的使用流程上来看,需要覆盖的是:

(1)规划阶段:在使用数据集之前,需要对数据使用的目的以及数据的组成做出明确的解释,保证后续使用数据的人能够对数据的创建目的有最直接的理解,并且提升完整的AI流程的“透明”程度
使用目的:
- 数据集创建的目的,是否有具体需要完成的任务?用一段话来描述这个任务;
- 创建数据集的负责人是谁,负责人代表的或者所在的部分或者组织是哪里?
- 数据集的提供者或者资源提供方是谁?
数据组成:
- 组成数据集的实体是什么?图片、文件、自然人信息或者几种实体类型的组合?罗列出所有的实体类型;
- 数据集中,不同类型的实体数量有多少?
- 建立的数据集包含能够获取的最多的、最完整的记录?还是从完整记录中抽取的一部分数据集,抽取的方式如何?
- 数据集的一条原始数据组成示例;
- 数据及是否存在一些标注(Label)或者目标变量?
- 每条记录中是否有缺失的字段或者信息?缺失的原因是什么?
- 数据集的记录之间是否存在某些显著的联系?比如社交网络的连接?
- 是否有对数据集切分策略的建议?如何切分training, validation, test的比例和方法;
- 数据集中是否存在一些记录错误、固有噪声或者冗余信息等;
- 数据集的组成是否是独立的?如果依靠外部来源组成数据,那么外部的来源是什么,外部数据的输入是否持续,是否有获取的风险?
- 数据集的组成是否存在涉密的信息?若有,请列出涉密的字段及描述;
- 数据集是否包含个人信息?如有,请列出与个人相关的信息描述;
- 数据集是否包含一些关于人口的统计信息,例如年龄,性别等?
- 数据集是否有可能通过任何的方法识别定位到个人,如若干信息的组合?
- 数据集是否报其他的一些敏感信息,比如涉及国家安全、企业营收等?
(2)使用阶段:数据的使用阶段,清晰翔实的数据信息可以显著地减少数据工程师和算法工程师冷启动的时间,提升团队内部和团队之间的沟通效率。
数据收集:
- 数据集的每一条记录收集的途径,直接从业务系统或者从其他数据集间接计算获得?
- 数据集的每一条记录收集的方式,是通过传感器、软件系统、API还是人工录入?这些方式是否可以验证有效性和安全性;
- 如果数据集来源于原始数据的抽样(Sampling),抽样的策略是什么?
- 数据集收集过程的参与者是谁?这些人员是如何获取报酬的?
- 数据集获取的时间周期是什么?
- 数据集的收集过程是否受到过机构或者组织的审查和验证?
- 如果数据集涉及到个人,还需要回到如下的问题(如果没有则可跳过):
- 获取个人数据的方式是从当事人直接授权,还是从第三方渠道获取?获取的渠道是什么;
- 如果是从个人直接获取,当事人是否知晓并同意数据会被收集并被模型使用;
- 如果当事人同意,是否有机制保障他(她)随时可以撤销这种授权?
- 是否有对于这种使用个人数据的AI模型做出对个人影响程度的分析?
预处理/标注:
- 数据集使用的任何预处理或者标注的技术,如缺失值处理、特征抽取、数据分桶等;
- 在预处理之后,原始数据集是否也同步保存?
- 预处理或者标注的过程是否使用到了一些软件或者工具?工具的名称是什么;
数据使用:
- 数据集是否已经被用到了其他的AI任务中?如有,罗列任务并作出描述;
- 数据集的使用过程相关的论文或者系统的列表;
- 这个数据集是否可能会被用到其他的任务中?
- 数据集组成或者预处理阶段的记录是否会影响使用阶段,具体来讲会对建模造成对一些特定团队或者个人的不公平待遇?
- 数据集是否有不应该被使用的任务中?
(3)运营阶段:这个阶段是数据集通过分析或者建模之后直接面向用户或者场景提供服务能力,持续地更新和追踪数据集,能够及时管理数据和模型的效果和性能,也保证应用的可信程度。
数据分发:
- 数据集是否会被授权分发至第三方,授权方是谁?
- 数据集分发的方式是什么,tarball, GitHub, API还是其他?
- 数据集分发的时间?
- 数据集分发是否会涉及知识产权或者使用条款与协议?
- 数据集分发时,原始数据的收集是否会有连带的知识产权责任?
- 数据集分发时,是否有专家或者负责人来监督分发过程及对分发的结果负责?
数据维护:
- 负责数据集维护的负责人是谁?负责人的联系方式?
- 数据集是否存在勘误表,如何访问?
- 数据集是否会更新,更新的内容是什么?
- 如果涉及到个人数据的使用,是否有数据使用的期限或其他限制?
- 数据集是否存在版本?新老版本的管理方式是如何的,老版本的数据集是否还需继续维护?
- 涉及到数据集的更新/维护,数据集的贡献者贡献机制是什么?
一个完整的例子可以参考论文中的样例
以上的问题尽可能详细,保证我们在观察和使用数据时,都可以从技术、业务、商业、法律、伦理多个维度来分析数据在完整的AI流程中的可信度。
可信的AI系统 – 模型的“黑盒子”
对于AI的信任程度,除了对原始数据的考察之外,更让人捉摸不透的是那些看起来神秘且复杂的机器学习模型,如果无法理解或者接受这些模型,由模型输出的结果必然也会收到质疑。这样的问题在一些与社会资源相关的公共问题上尤为明显,例如就业、医疗、金融服务、执法等。在美国有这样的一个例子,一些地方法院法官开始利用AI模型进行嫌疑犯量刑的刑期预测,我们暂不展开讨论这个应用的正义性,假设从法律和道德上可以接受,那么能够让法官放心使用的一个核心考量就是他们是否能够理解AI模型,能够认为AI做出的判断与他们的逻辑相符。

在这里,我又会提到Gebru,在研究中,她的Google团队以及多伦多大学的学者共同提出了一种类似于Datasheets的方法 – Model Cards(模型卡片)。模型卡片是一个附在几个发布的机器学习模型的1-2页的记录描述,用于向相应的读者解释模型的多维度信息,以求打开AI模型的“黑盒子”。
一个模型卡片可以分为以下的几个元素:
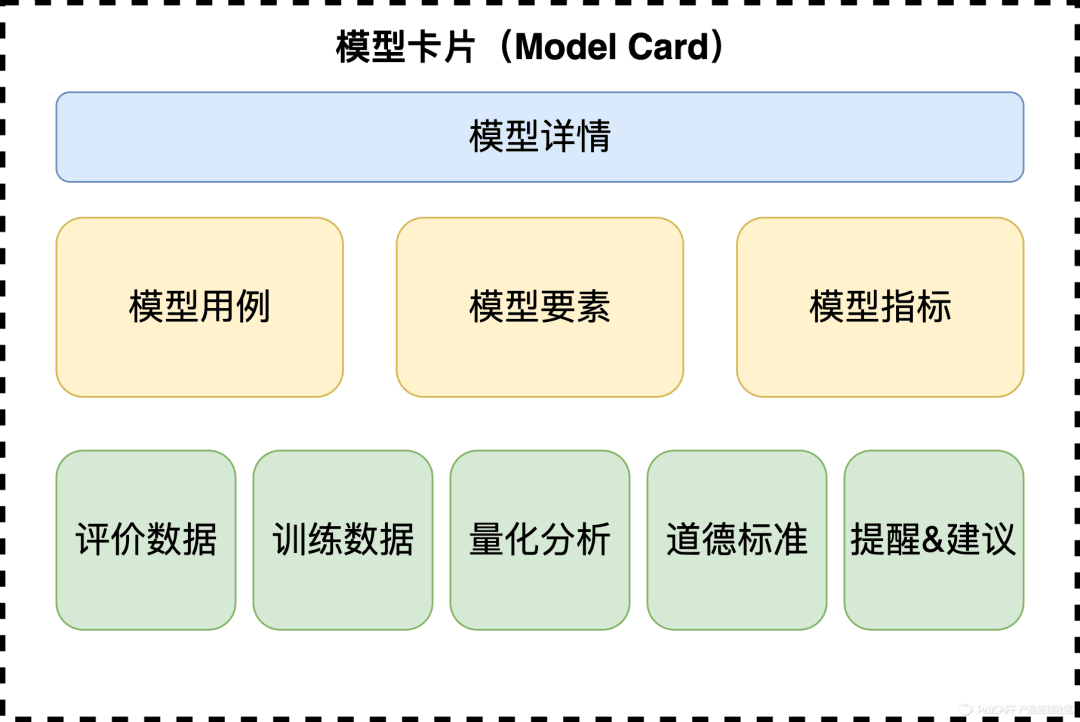
模型详情:
- 模型开发者(组织):负责的自然人或者团队;
- 模型发布日期:模型发布上线的日期及时间;
- 模型版本:模型发布时的版本编号;
- 模型类型:是传统机器学习模型,深度模型等等;
- 模型参考或者复现的论文,或者借鉴的开源工具及来源;
- 模型引用的规范;
- 模型的使用许可;
- 关于模型的反馈方式(联系方式);
模型用例:
- 模型应用的用户用例,或者场景描述,例如用在信用卡实时的交易反欺诈;
- 模型应用面向的用户(群体);
- 模型应用的限制或者禁用的用例,例如不能被用作何种群体的人脸识别;
模型要素:
- 模型适用的群体描述:尤其是涉及到自然人的模型,清晰地定义适用的群体,以及在不同群体之间的模型表现及差异;
- 模型适用的外部设备或系统描述:如一些CV的场景,不同的摄像头型号都可能会引起模型表现的差异;
- 模型适用的外部环境描述:同样的,在CV场景下,不同的光照条件、环境温湿度都可能造成模型效果的漂移甚至错误;
- 其他“静默”要素:除了上述要素之外,还有可能隐藏在表面之下的要素会影响模型的效果;
- 评价要素:一些评价指标的设计是否会影响模型考察的全面性?
模型指标:
- 模型选择的指标有哪一些?选择这一些指标的原因是什么?
- 指标阈值,调整一些关键指标默认阈值的原因是什么?
- 应对不确定性和可变性的方式方法是什么?
评价数据:
- 用于评价的数据集描述及选择这一部分数据集的原因;
- 这一部分数据集是否经过预处理?预处理的方式是什么?
训练数据:
- 可以参考上方Datasheets的内容进行引用或者精简复述至此;
量化分析:
- 回溯到模型要素的框架内,对于不同要素之内的分析要做到量化结果输出,并打印到模型卡片内;
- 在不同的模型要素之间,输出量化的分析结果输出;
伦理考量:
- 在开发的过程当中,是否用到了隐私数据?
- 模型是否会被应用到一些对于人类很关键的事务中,例如安全、医疗等;
- 模型的使用是否存在一些风险和对于一些人群的伤害?
- 在模型开发的过程中,有否执行一些降低风险的方法;
- 在模型用例的罗列中,是否存在一些有争议的用例?
提醒&建议:
- 罗列出以上还未包含但很重要的模型的相关信息;
给出一个例子:
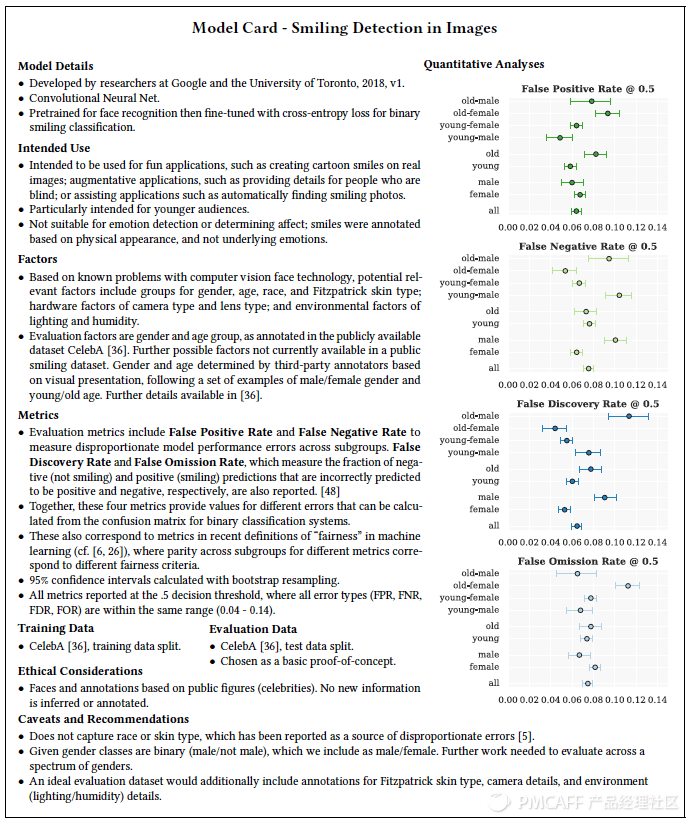
模型卡片的输出延续了针对数据的Datasheets的方法,通过一系列的问题形成一个可以执行的思维框架,连接不同的AI利益相关人共同提升AI的透明度和可信度。在我看来,这也是目前为止AI的伦理研究给出的最接地气的方案,推进很难,但这个功课对于任何一个成熟的AI应用来讲,迟早都是要补上的课。
可信的AI系统 – 人机协作
AI的技术视角从来都是以“无人化”、“自动化”作为追求的目标,这显然也是我们希望AI能够实现的目标,但从解决问题的产品或者社会视角来看,AI的应用更好的方式一定是人机协作或者人机协同,缺少了AI的人力,就是回到之前的生活,缺乏了一些效率,人类的工作要更枯燥乏味一些;但是缺少了人的AI,则很有可能面对的是失败、滥用甚至叛乱。
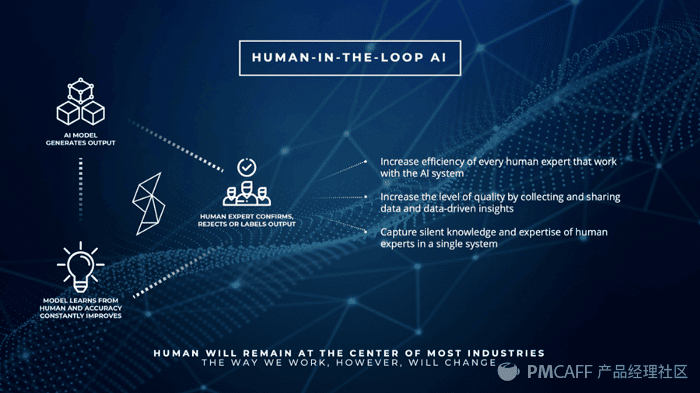
在人与AI的协作当中,形成的完整循环(Human-in-the-loop AI)让这两种思考对象形成合力,更快、更准确地解决共同的问题。
从HILP的角度来看,创造一个可信的AI我们同样要试着回答自己这几个问题:
(1)人与AI是否有共同要解决的任务,我们在设计和开发阶段是否能够保证这两方的利益相同?
(2)人是否能够从数据开始在每一个环节都可以参与到AI的输入和输出,保证人的随时介入与信息输入?
(3)AI的设计能否及时甚至实时响应人的正确建议和调整方向,优化算法目标?
(4)人是否可以及时从这个人机协作的系统中及时抽取前所未见的洞察或者知识纳入自己的知识体系?
实现一个人机协作的AI系统是不容易的,但有了这样的人机协同,可信这样的一个结果呈现就可以融入到人机协作的每一次操作与建议中,变成一种过程变量,信任也会形成累积效应,降低了“可信”的门槛和周期。
可信的AI系统 – 第三方认证
自从产生信用这个词开始,信用都一定需要一个机构进行背书,大到国家,小到专家认证,才能够支撑信用体系的运行和延续。那么从AI的应用开始,如果要建设一个可信的系统,建设方就一定需要一个第三方的背书,来从外部验证信用,并且AI的消费者或者使用方也可以最快速度得到这一份信用的确认。从现在来看,可能会有几种方式:
(1)GDPR(General Data Protection Regulation):从GDPR来看,这是适用企业需要无条件遵守的,并不是一个资格证书。但是符合GDPR的认证或者认可,目前还没有统一的方式,我们可以通过ISO体系的一些认证和专家的指导来只限符合GDPR框架的“认证”;
(2)CCPA(California Consumer Privacy Act):从2018年开始执行,加州的要求与GDPR性质相同,我们也无法直接进行认证,而是需要类似的方法按照CCPA的要求寻找已经存在的认证方式;
(3)等保认证:我们国家公安部颁布的信息系统安全等级保护认证,这应该是国内企业最直接可以得到的权威认证;
(4)ISO体系认证;
(5)各行业的行业公约或者协议:比如银行业的巴塞尔公约等;
Reference
1、《Datasheets for Datasets》, Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, Kate Crawford
2、《model cards for model reporting》, Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, Timnit Gebru
3、《Executive Order on Promoting the Use of Trustworthy Artificial Intelligence in the Federal Government》
4、《GDPR Regulations》
5、《CCPA Fact Sheet》
6、https://www.partnershiponai.org/

1 Comment
Very good information. Lucky me I ran across your blog by accident (stumbleupon).
I’ve saved as a favorite for later!