

想要快速区分标记的数据时,我们很容易忽略无监督学习。无监督的机器学习本身就非常强大,而聚类是迄今为止这类问题中最常见的方式。
这是三种最流行的聚类方法的快速破解,以及哪种类型的情况最适合。聚类与监督问题有一点共同点就是没有银弹; 每个算法都有其时间和地点,具体取决于您要完成的任务。这应该给你一些直觉,就像何时使用它们一样,只有一点点数学。
分层聚类
想象一下,你有集群的一些数量ķ你有兴趣在寻找。您所知道的是,您可以将数据集分解为顶级的许多不同组,但您可能也对组内的组或这些组内的组感兴趣。为了获得这种结构,我们使用层次聚类。
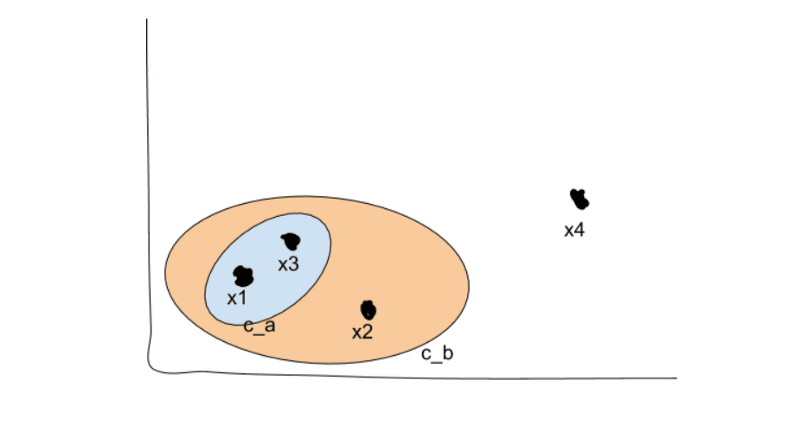
我们从n个不同的点和我们想要发现的k个不同的簇开始; 就我们而言,n = 4,k = 2。
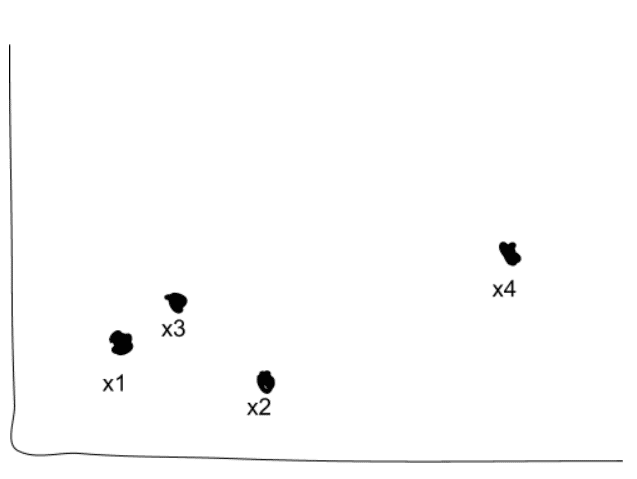
首先将每个点视为自己的集群。

然后,我们开始将每个单点集群合并为更大的集群,使用最接近的集群。我们找到距离成对距离矩阵的最小距离 – 这只是每个群集与其他群集距离的表格。
这被初始化为每个点之间的欧几里德距离,但在此之后,我们切换到测量簇距离的各种不同方式之一。如果您有兴趣了解有关这些技术的更多信息,请查看单链路聚类,完整链路聚类,clique边距和Ward’s方法。
无论如何,我们开始合并最接近的集群。假设我们知道x1和x3最接近。然后我们将这两个合并到一个新的集群中,ca。
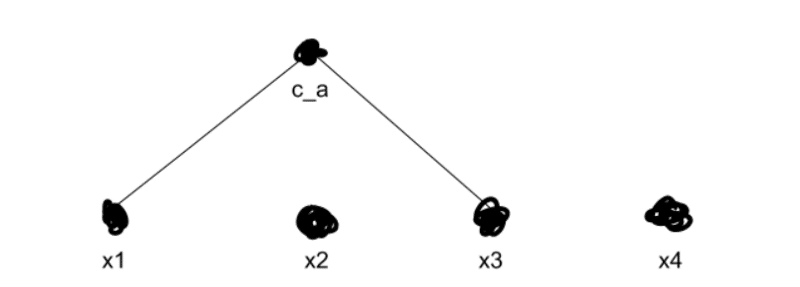
我们现在使用我们偏爱上述抓斗的方法重新计算每个其他群集的距离。然后我们重复,一遍又一遍地合并我们的聚类,直到我们得到k个顶级聚类 – 在我们的例子中,两个聚类。假设我们发现x2更接近于ca而不是x4。
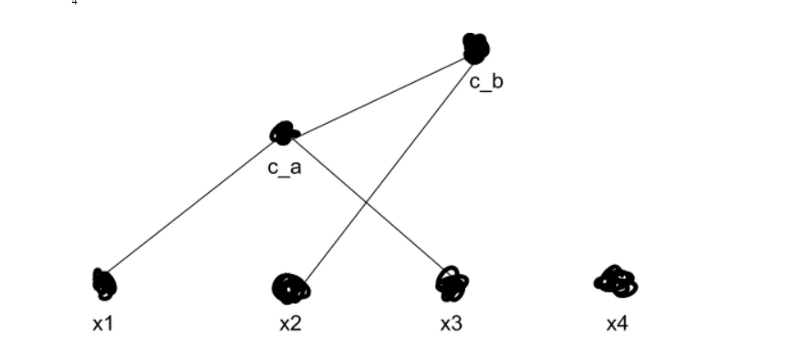
我们现在有两个顶级集群,cb和x4(请记住,每个点都作为自己的集群开始)。我们现在可以搜索我们创建的树结构来搜索子集群,在我们原来的2-D视图中看起来像这样:
基于密度的聚类
分层聚类有助于理解数据中的任何隐藏结构,但它有一个主要的缺陷。在上面显示的版本中,我们假设每个数据点都是相关的 – 在现实世界中几乎不是这种情况。
基于密度的聚类方法提供安全阀。我们不会假设每个点都是某个集群的一部分,而是只关注紧密堆积的点并假设其他所有点都是噪声。
该方法需要两个参数:半径ε和邻域密度Σ。对于每个点,我们计算Neps(x) – 距离x最多ε的点数。如果Neps(x)≥Σ,不计算x,那么x被认为是核心点。如果一个点不是核心点,但它是核心点邻域的成员,那么它被认为是边界点。其他一切都被认为是噪音。
基于密度的聚类的最常见且实际上是表演性实现之一是基于密度的具有噪声的应用的空间聚类,更好地称为DBSCAN。DBSCAN的工作原理是跨不同的核心点运行连接组件算法。如果两个核心点共享边界点,或者核心点是另一个核心点邻域中的边界点,那么它们就是相同连通组件的一部分,这组成了一个集群。
假设我们有一个相对较小的ε和一个相当大的Σ。我们可能会结束这样的集群:
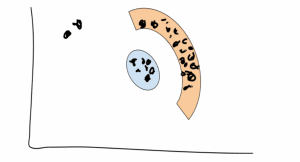
看到?那两个孤独的点距离两个星团很远,而且他们真的没有什么意义 – 所以它们只是噪音。
请注意,我们也能够以这种方式发现非凸簇(参见橙色弧)。很简约!
我们不需要为基于密度的聚类指定一些我们感兴趣的聚类 – 它将根据您的ε和Σ自动发现一些聚类。当您希望所有群集具有相似的密度时,这尤其有用。
K-Means聚类
分层聚类擅长于发现数据中的嵌入式结构,而基于密度的方法在寻找具有相似密度的未知数量的聚类方面表现优异。但是,两者都无法在整个数据集中找到“共识”。分层聚类可以将看起来很接近的聚类放在一起,但不考虑其他点的信息。基于密度的方法仅查看附近点的小邻域,同样无法考虑完整数据集。
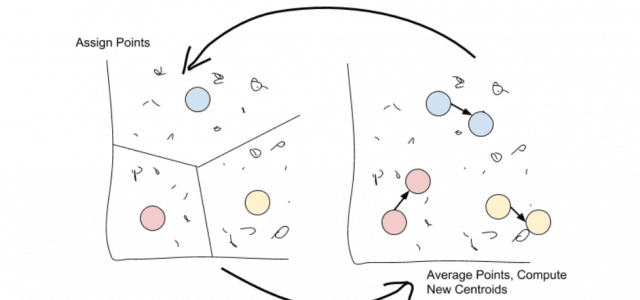
这就是K-means聚类的用武之地。从某种意义上说,K-means考虑数据集中的每个点,并使用该信息在一系列迭代中进化聚类。
K-means通过选择k个中心点或装置来工作,因此选择K-Means。然后将这些均值用作其群集的质心:任何最接近给定均值的点都将分配给该均值的群集。
分配完所有点后,移动每个群集并获取其包含的所有点的平均值。这个新的“平均”点是集群的新均值。
只需重复这两个步骤,直到点分配停止变化!
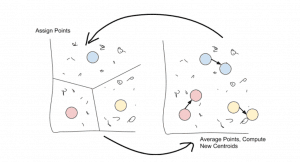
一旦点分配停止改变,该算法就会被收敛。
我们现在将拥有k个不同的簇,每个簇的质心更接近其簇中的每个点,而不是任何其他质心。再次计算质心不会改变分配,所以我们停下来。这就是K-means的全部内容,但它是一种非常强大的方法,可以在考虑整个数据集时查找已知数量的聚类。
有很多方法可以初始化你的资金。Forgy方法从数据中随机选择k个随机观测值并将其作为起点。随机分区方法将数据集中的每个点分配给随机簇,然后根据这些点计算质心并恢复算法。
虽然K-means是一个NP难问题,但是启发式方法能够在多项式时间内找到对全局最优的适当近似,并且能够有效地处理大数据集,在某些情况下使其成为层次聚类的可靠选择。
聚类是一个奇怪的世界,拥有更奇怪的技术集合。这三种方法只是最流行的一些方法,但它们可以帮助您在数据中发现未知分组。集群在探索性数据分析,查找其他分析的初始化点以及部署非常简单方面非常有用。明智地使用群集可以为您的数据提供令人惊讶的见解。考虑一下你腰带上的另一个缺口。
本文转自medium,原文地址

Comments