

大型预训练语言模型无疑是自然语言处理(NLP)最新研究进展的主要趋势。
虽然很多AI专家都认同安娜罗杰斯的说法,即用更多的数据和计算能力获得最先进的结果并不是研究新闻,但其他NLP意见领袖也看到了当前趋势中的一些积极时刻。例如,DeepMind的研究科学家Sebastian Ruder 指出,这些大语言框架有助于我们看到当前范式的基本局限。
由于变形金刚占据了NLP排行榜,因此通常很难遵循修正案的内容,从而使新的大语言模型能够设置出另一种最先进的结果。为了帮助您及时了解最新的NLP突破,我们总结了研究论文,其中包括GLUE基准的当前领导者:来自卡内基梅隆大学的XLNet,来自百度的ERNIE 2.0和来自Facebook AI的RoBERTa。
如果这些可访问的AI研究分析和摘要对您有用,您可以订阅以下我们的常规行业更新。
如果你想跳过,我们推荐的论文如下:
大语言框架
1. XLNET:用于语言理解的广义自回归预训练,由ZHILIN YANG,ZIHANG DAI,YIMING YANG,JAIME CARBONELL,RUSLAN SALAKHUTDINOV,QUOC V. LE
原始摘要
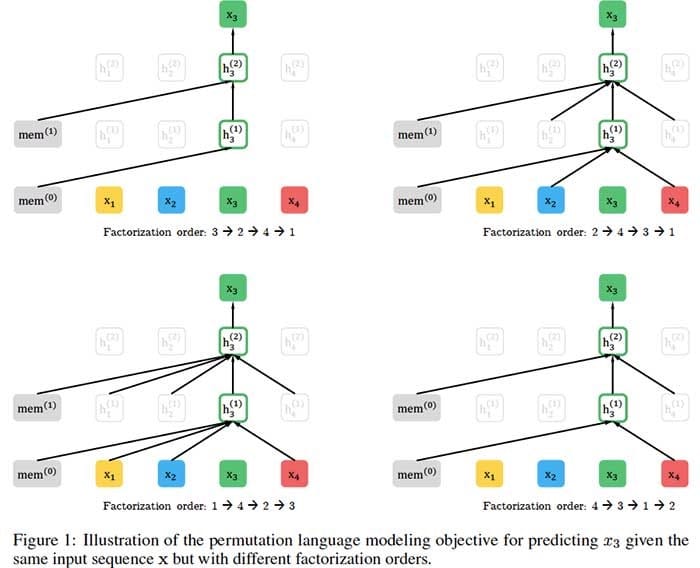
凭借对双向上下文进行建模的能力,基于自动回归语言建模的预训练方法可以实现基于BERT的预训练的去噪自动编码实现更好的性能。然而,依赖于使用掩码破坏输入,BERT忽略了屏蔽位置之间的依赖性并且受到预训练 – 微调差异的影响。根据这些优点和缺点,我们提出了XLNet,一种广义自回归预训练方法,它(1)通过最大化分解阶的所有排列的预期可能性来学习双向上下文,并且(2)由于其自回归,克服了BERT的局限性。公式。此外,XLNet将最先进的自回归模型Transformer-XL的创意整合到预训练中。根据经验,XLNet在20项任务上优于BERT,
我们的总结
来自卡内基梅隆大学和谷歌的研究人员开发了一种新的模型XLNet,用于自然语言处理(NLP)任务,如阅读理解,文本分类,情感分析等。XLNet是一种通用的自回归预训练方法,它利用了自回归语言建模(例如,Transformer-XL)和自动编码(例如BERT)的优点,同时避免了它们的限制。实验证明,新模型优于BERT和Transformer-XL,并在18个NLP任务上实现了最先进的性能。
本文的核心思想是什么?
- XLNet结合了BERT的双向功能和Transformer-XL的自回归技术:
- 与BERT一样,XLNet使用双向上下文,这意味着它会查看给定令牌之前和之后的单词以预测它应该是什么。为此,XLNet针对分解顺序的所有可能排列最大化序列的预期对数似然。
- 作为一种自回归语言模型,XLNet不依赖于数据损坏,因此避免了由于屏蔽导致的BERT限制 – 即,预跟踪 – 微调差异以及未屏蔽的令牌彼此独立的假设。
- 为了进一步改进预训练的架构设计,XLNet集成了Transformer-XL的片段重现机制和相对编码方案。
什么是关键成就?
- XLnet在20项任务上的表现优于BERT,通常大幅提升。
- 新模型在18个NLP任务上实现了最先进的性能,包括问答,自然语言推理,情感分析和文档排名。
AI社区的想法是什么?
- “国王死了。吾皇万岁。BERT的统治可能即将结束。XLNet是CMU和谷歌人的新模型,在20项任务上胜过BERT。“ – Deepmind的研究科学家Sebastian Ruder。
- “XLNet可能会成为任何NLP从业者的重要工具…… [它]是NLP最新的尖端技术。” – Keita Kurita,卡内基梅隆大学。
未来的研究领域是什么?
- 将XLNet扩展到新的领域,例如计算机视觉和强化学习。
什么是可能的商业应用?
- XLNet可以帮助企业解决各种NLP问题,包括:
- 聊天机器人一线客户支持或回答产品查询;
- 基于客户评论和社交媒体评估品牌知名度和认知度的情绪分析;
- 在文件库或在线等搜索相关信息
你在哪里可以得到实现代码?
- 作者发布了XLNet的官方Tensorflow实现。
- GitHub上也提供了PyTorch模型的实现。
2. ERNIE 2.0:语言理解的持续预培训框架,由YU SUN,SHUOHUAN WANG,YUKUN LI,SHIKUN FENG,HAO TIAN,WU WU,HAIFENG WANG
原始摘要
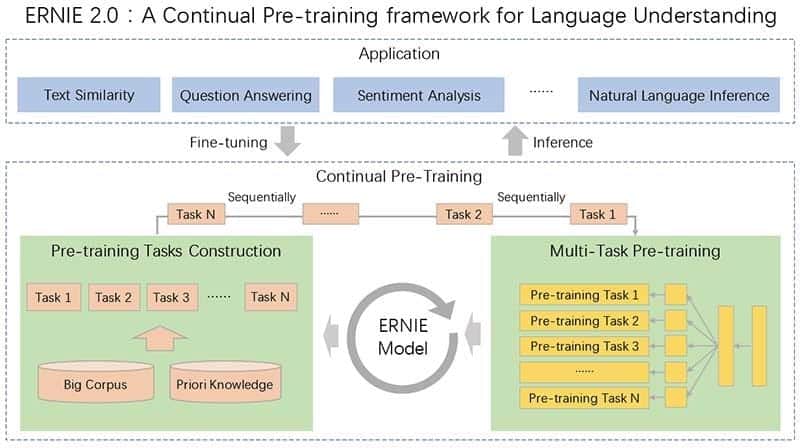
最近,预训练模型在各种语言理解任务中取得了最新成果,这表明大型语料库的预训练可能在自然语言处理中起着至关重要的作用。目前的预训练程序通常侧重于通过几个简单的任务来训练模型,以掌握单词或句子的共现。然而,除了共存之外,训练语料库中还存在其他有价值的词汇,句法和语义信息,如命名实体,语义接近和语篇关系等。为了最大限度地提取来自训练语料库的词汇,句法和语义信息,我们提出了一个名为ERNIE 2.0的连续预训练框架,该框架通过持续的多任务学习来逐步建立和学习预训练任务。实验结果表明,ERNIE 2.0在16项任务上优于BERT和XLNet,包括GLUE基准上的英语任务和中文的几项常见任务。源代码和预先训练的模型已发布于https://github.com/PaddlePaddle/ERNIE。
我们的总结
大多数最先进的自然语言处理模型分析了预训练中句子中单词的共现。但是,句子中包含的附加信息包括句子顺序和接近度,命名实体和语义相似性,模型没有捕获。在百度研究者(通过创建一个连续预训练框架ERNIE 2.0解决此问题Ë nhanced ř epresentation至K Ñ owledge 我 nt下ëgration),通过多任务学习不断引入和培训定制任务。因此,该模型可以跨任务编码词法,句法和语义信息,而不会忘记以前训练过的参数。ERNIE 2.0在英语GLUE基准测试中优于BERT和XLNet,为中文处理设定了新的技术水平。
本文的核心思想是什么?
- 现有的自然语言处理模型主要通过利用单词或句子的共现信息来解决单词级和句级推理任务,而不能掌握训练语料库中包含的其他有价值的信息。
- 为了充分学习文本中包含的词汇,句法和语义信息,百度研究团队引入了一个连续的预训练框架ERNIE 2.0,其中通过多任务学习逐步引入和学习预训练任务:
- 可以随时自由引入不同的自定义任务。
- 这些任务共享相同的编码网络,并通过多任务学习进行培训。
- 当新任务到达时,框架递增地训练分布式表示而不忘记先前训练的参数。
什么是关键成就?
- 根据论文中报道的实验,ERNIE 2.0在英语GLUE基准测试中优于BERT和XLNet:
- 与BERT的得分80.5相比,平均得分为83.6。
- 在八个单独的任务类别中的七个中,它比XLNet表现更好。
- ERNIE 2.0还为众多中国NLP任务设定了最先进的性能水平。
AI社区的想法是什么?
- ERNIE 2.0是关于GitHub的热门论文。
未来的研究领域是什么?
- 在持续的预训练框架中引入更多和更多样化的预训练任务,以进一步提高模型的性能。
什么是可能的商业应用?
- 与其他大型预训练语言框架一样,ERNIE 2.0可以帮助企业完成各种NLP任务,包括聊天机器人,情绪分析,信息检索等。
你在哪里可以得到实现代码?
- 本研究中使用的源代码和预训练模型可 在GitHub上获得。
3. ROBERTA:一种稳健优化的BERT预训练方法,由YINHAN LIU,MYLE OTT,NAMAN GOYAL,杜景飞,MANDAR JOSHI,DANQI CHEN,OMER LEVY,MIKE LEWIS,LUKE ZETTLEMOYER,VESELIN STOYANOV
原始摘要
语言模型预训练带来了显着的性能提升,但不同方法之间的仔细比较具有挑战性。培训计算成本很高,通常在不同大小的私有数据集上完成,正如我们将要展示的,超参数选择对最终结果有重大影响。我们提出了BERT预训练的复制研究(Devlin等,2019),该研究仔细测量了许多关键超参数和训练数据大小的影响。我们发现BERT显着不足,并且可以匹配或超过其后发布的每个模型的性能。我们最好的模型在GLUE,RACE和SQuAD上实现了最先进的结果。这些结果突出了之前被忽视的设计选择的重要性,并提出了有关最近报告的改进的来源的问题。我们发布我们的模型和代码。
我们的总结
由于引入了预训练方法,自然语言处理模型取得了显着进步,但是训练的计算费用使得复制和微调参数变得困难。在这项研究中,Facebook AI和华盛顿大学的研究人员分析了谷歌的变换器双向编码器表示(BERT)模型的培训,并确定了培训程序的几个变化,以提高其性能。具体而言,研究人员使用新的更大的数据集进行训练,在更多迭代中训练模型,并删除了下一个序列预测训练目标。由此产生的优化模型RoBERTa(稳健优化的BERT方法)与GLUE基准上最近推出的XLNet模型的得分相匹配。
本文的核心思想是什么?
- Facebook人工智能研究团队发现BERT非常重要,并建议改进其训练方法,称为RoBERTa:
- 更多数据:160GB的文本,而不是最初用于训练BERT的16GB数据集。
- 更长的培训:将迭代次数从100K增加到300K再增加到500K。
- 较大的批次:原始BERT基础模型中的8K而不是256。
- 具有50K子字单元的较大字节级BPE词汇表,而不是大小为30K的字符级BPE词汇表。
- 从训练过程中删除下一个序列预测目标。
- 动态地改变应用于训练数据的掩蔽模式。
什么是关键成就?
- RoBERTa在通用语言理解评估(GLUE)基准测试的所有单个任务中优于BERT。
- 新模型与GLUE基准测试中最近推出的XLNet模型相匹配,并在九个单独任务中的四个中设置了最新的技术水平。
未来的研究领域是什么?
- 结合更复杂的多任务微调程序。
什么是可能的商业应用?
- 像RoBERTa这样的大型预训练语言框架可以在业务环境中用于各种下游任务,包括对话系统,问答,文档分类等。
你在哪里可以得到实现代码?
- 本研究中使用的模型和代码可 在GitHub上获得。
本文转自TOPBOTS,原文地址


Comments