

刘璟,百度NLP资深研发工程师、阅读理解与问答技术负责人。本文根据作者2019年5月26日在“2019自然语言处理前沿论坛”自动问答主题的特邀报告整理而成。
本报告分为以下4个部分:
· 什么是机器阅读理解?
· 阅读理解技术的进步
· 阅读理解的更多挑战
· 百度阅读理解技术的研究工作
1、什么是机器阅读理解?
机器阅读理解,大家对其并不陌生,在我们过去参加的各种语言考试当中都会有阅读理解的题目,基本上题目都会要求答题者阅读完一篇给定的文章之后回答相关的问题,这里如果把答题者换成机器就可以认为是机器阅读理解。
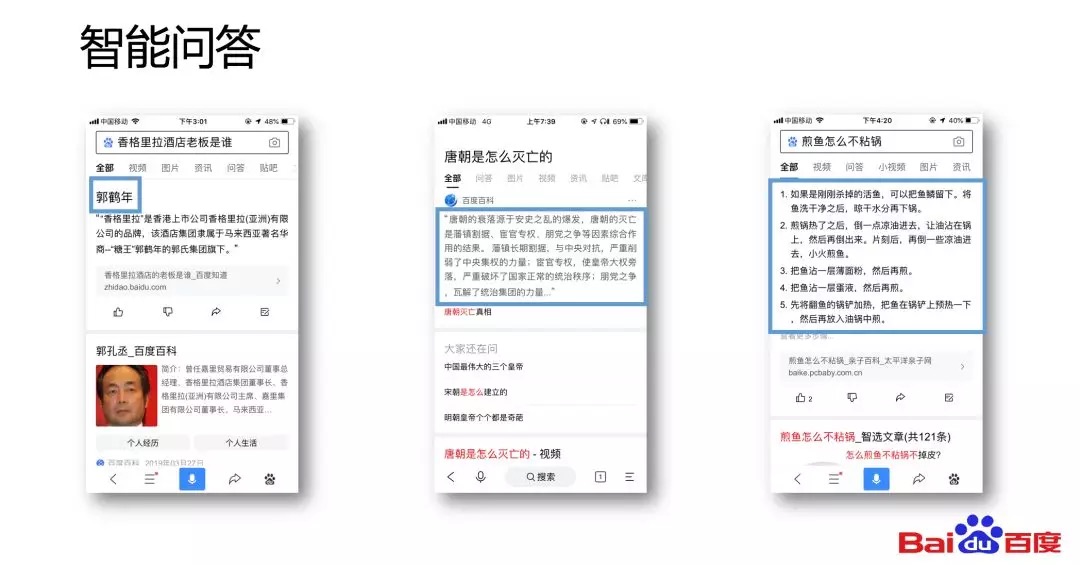
阅读理解题目的形式是非常多样的,包括选择题、回答题等。但是从主流的学术研究和技术落地来看,我们更加关注抽取式数据理解。抽取式数据理解是指给定篇章P和问题Q,我们希望从P当中抽取出答案A,并且通常答案A是篇章P当中的连续片段。下图提供了一篇文章中关于香格里拉酒店的段落,如果我们问香格里拉酒店的老板是谁,我们希望机器能够从篇章P当中抽取出答案。

我们研究机器阅读理解的意义是什么?从应用价值角度来看,机器阅读理解能够解决传统的检索式问答最后一公里的难题,也就是精准定位答案。传统的检索式问答通常是用户在输入一个问题之后,从海量的文档集中检索出若干候选文档,并对这些若干候选文档做段落切分和排序,最后以段落为单位作为答案直接反馈给用户。但是通常这样的段落还包含了较多的冗余信息,在一些小屏设备,例如智能手机上会浪费很多空间;在一些无屏设备,例如智能音箱上就会播报很多的冗余信息。因此我们希望使用阅读理解的技术,能够对答案进行精准的定位。

得益于近两年阅读理解技术的快速进步,百度已经将阅读理解技术落地在了百度搜索问答当中。如果在百度APP中问刚才所提到的问题,香格里拉酒店的老板是谁,它就能够直接返回一个答案。当然除了这样一些实体或者是数字类的答案,阅读理解的技术还可以帮助更好地定位一些长答案,如图例中的“唐朝是怎么灭亡的”“煎鱼怎么不粘锅”等这样的问题。
2、阅读理解技术的进步
下图左测是斯坦福发布SQuAD数据集后两年左右的时间内,其排行榜上的最好模型F1提升了80%;下图右侧是百度发布的DuReader数据集,其排行榜上最好的系统ROUGE-L提升了75%。可以看到技术进步是非常快的,而这些技术进步主要的原因有两个:一是数据规模的变大,二是深度学习技术的应用。
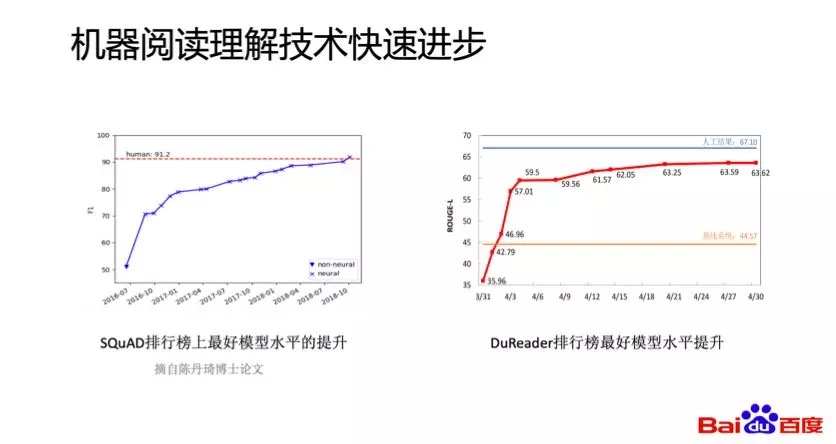
首先我们看下数据规模的变化,在2016年之前比较大的数据集,比如微软发布的MCTest只包含了2600余个问题,SQuAD数据集通过众包的方式标注了10万左右的问题,数据集规模直接提高两了个数量级。之后微软发布的MSMARCO还有百度的DuReader也分别包含了10万和30万个问题。

数据规模的增大也使得深度学习的方法在阅读理解任务上得到了快速的进步。我们可以看到,在2016年之前,大家使用更多的是统计学习的方法,包含了大量的特征工程,非常耗时耗力。在2016年之后,SQuAD数据集发布之后,出现了一些基于注意力机制的匹配模型,比如BiDAF、LSTM等等。这之后出现了各种网络结构比较复杂的模型,相关工作试图通过复杂的网络结构去捕捉问题和篇章之间的匹配关系。虽然在这个阶段跳过了一些复杂的特征工程,但是似乎我们又陷入了更加复杂的网络结构工程。
在2018年之后,随着各种预训练语言模型的出现,阅读理解模型效果得到了近一步大幅的提升,因为表示层的能力变的很强大,任务相关的网络结构开始变的简单起来。

3、阅读理解的更多挑战
在预训练语言模型出现了之后,一些比较简单的阅读理解数据集得到了比较好的解决,比如SQuAD1.1,而针对语言理解应对的不同挑战,更多的数据集被提出。这里面包括了SQuAD2.0,主要是引入了一些无答案的问题;还有面向搜索场景的多文档的数据集,有微软的MARCO,还有百度的DuReader;还有面向对话场景的CoQA、QuAC;以及跨篇章推理的数据集HotpotQA;此外还有近两年比较火的,希望能够通过引入外部知识来做阅读理解的数据集,比如ReCoRD、CommonsenseQA等等。

4、百度阅读理解技术的研究工作
我会重点介绍百度面向搜索的多文档阅读理解上的研究工作V-NET,以及在引入外部知识阅读理解任务上的工作KT-NET,分别发表在去年和今年的ACL上。

首先我们介绍一下面向搜索场景的多文档阅读理解工作。面向搜索场景的多文档阅读理解任务和单文档阅读理解任务比较大的不同有两点:
一、这里面的问题都是来自搜索场景的真实问题;
二、每一个问题都包含了多个候选段落。

这样的特点为语言理解带来了一些挑战,因为每一个问题包含了多个候选文档,因此可能会包含较多的歧义和混淆的信息。从下图的这个例子来看,这个问题是问细胞混合培养和纯培养的区别,这里面的关键词Culture我们通常看到的意思是文化,实际上在这个问题里面指的是细胞的培养。可以看到在若干个候选文档当中,有些包含了文化的意思,有些包含了细胞培养的意思,这就为阅读理解模型的预测带来了一定的挑战。

虽然存在这样的挑战,但是如果我们通过仔细的观察会发现,事实上有一些候选文档只包含了部分和正确答案相关的信息,如果我们从每一个文档都抽取一个候选答案,让这些答案之间互相验证或者互相投票,也许能够帮助我们更好的定位到正确答案。

基于刚才的idea,我们提出了面向多文档阅读理解的模型V-NET。V-NET主要的创新点在于,在BiDAF的基础之上,引入基于注意力机制的答案校验。从下图可以看出,前三层是使用BiDAF对每一个文档进行答案抽取。在抽取出答案之后,在第四层我们希望获得每一个答案的表示,在最后一层我们希望在这个表示之下让答案之间互相做验证,进而更精准的定位到答案。同时我们还可以看到模型的最后三层,实际上都规定了各自的任务,我们还可以进一步引入联合训练。
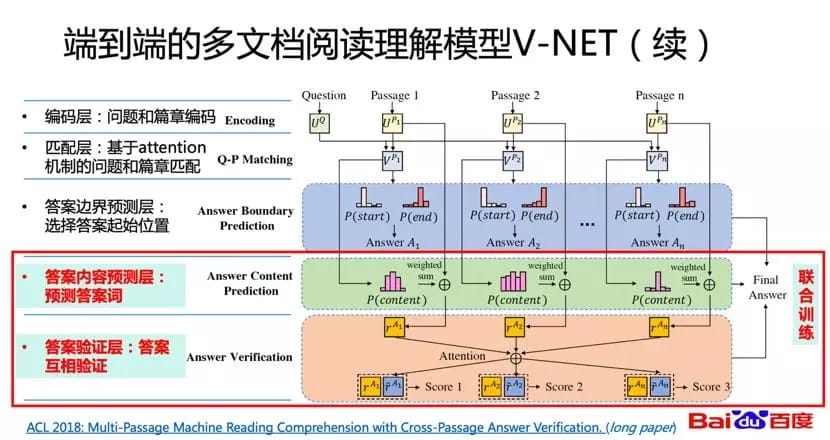
下图为实验结果,我们在MSMARCO上做了实验,V-Net的效果超过了R-Net和S-Net等,无论是多答案的校验、联合训练还是答案的表示,都让模型获得了正向的收益。同时在去年该模型在MSMARCO数据集排行榜上三次获得了第一。

第二个工作,引入外部知识的阅读理解,这是我们今年被ACL录取的一篇论文。所谓引入知识的阅读理解是指我们希望在做阅读理解的时候不仅依靠文档的内容进行理解,同时也需要一些外部的知识作为支撑,这样才能够正确的回答问题或者更好的回答问题。
举个例子,下图左边这个问题“《人在囧途》是谁的代表作”,基于文本表示的阅读理解抽取出来的答案是“李卫”。这里我们可以观察到,模型能够较好的捕捉到答案的类型。但是当一个片段中包含多个类型相同的侯选答案的时候模型就很容易犯错,所以在这个例子中,模型没有抽取出正确的答案“徐峥”,而是把“李卫”当做一个正确的答案。如果我们能够从知识库当中获取到一些外部的知识,例如能告诉我们徐峥是一个演员,很有可能模型能够通过演员和代表作相关的信息正确地判断出答案。

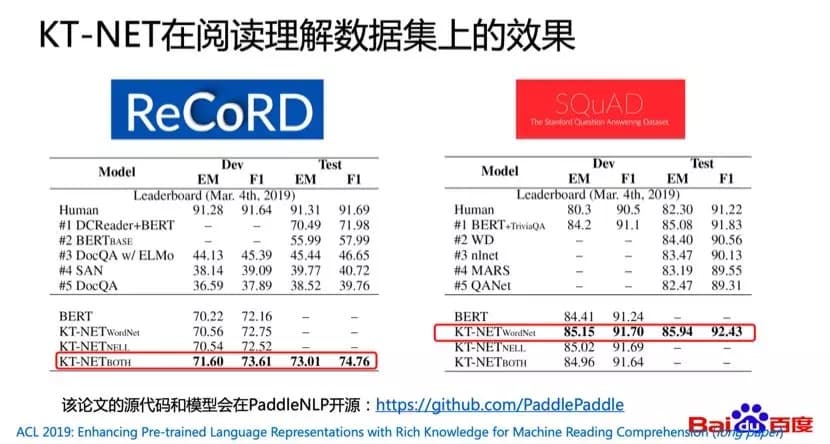
基于这个idea,我们提出了文本表示和知识表示融合的模型,叫做KT-NET,这里K是指Knowledge,T就是Text。KT-NET中,第一步我们使用预训练的语言模型,对问题和文档中的每一个词进行编码表示;第二步我们使用一些传统的方式对知识库中的关系或者实体进行预训练编码表示;第三步我们会从知识库当中检索到一些和文本相关的知识,同时获取这些知识的预训练表示。因为这些相关的候选知识是比较多的,所以我们还进一步希望通过注意力的机制,将最相关的知识和文本表示进行融合,在融合的基础之上获得了一个知识增强的文本表示,最后在这样一个知识增强的文本表示基础之上预测答案,这就是KT-NET主要结构。

我们也在两个数据集——ReCoRD和SQuAD上做了实验,最后发现KT-NET在这两个数据集上都获得了比BERT_large要好的效果。这个论文相关的工作也会以PaddleNLP的形式在GitHub上进行开源。
除了在技术上不断投入,我们还希望能够利用百度的数据优势推动中文机器阅读理解技术的一些进步。所以我们去年发布了面向搜索场景的中文阅读理解数据集DuReader 2.0,相比于SQuAD数据集,DuReader主要有四个特点:首先,DuReader数据集中的问题都是来自于搜索的真实问题;其次,数据中的文档是来自全网的真实文档;第三,DuReader数据集目前是最大规模的中文数据集;第四,数据集当中包含了丰富的答案和问题类型标注。因为DuReader数据集当中包含丰富的问题类型标注,所以相比于SQuAD数据集,除了实体类、数据类、描述类和事实类问题,DuReader还包括观点类和是否类的问题,目前这个数据集也可以通过百度大脑开放数据平台下载。

我们的初衷是使中文阅读理解技术获得进步。因此在过去的两年内,我们和中国中文信息学会和中国计算机学会联合举办了阅读理解评测任务。在去年的评测中吸引到了1000多个队伍来报名,也收到1500份结果提交。今年的比赛还在继续,吸引到了2000多个队伍来报名。今年我们还提供了基于PaddlePaddle的基线系统,所有的参赛选手都可以在AI Studio上面使用百度提供免费的GPU的计算资源,训练自己的模型。

讲完了百度在机器阅读理解技术方面的研究和一些应用落地,最后我想从工业应用需求的角度看一下百度还会在哪些方面对阅读理解技术展开研究。

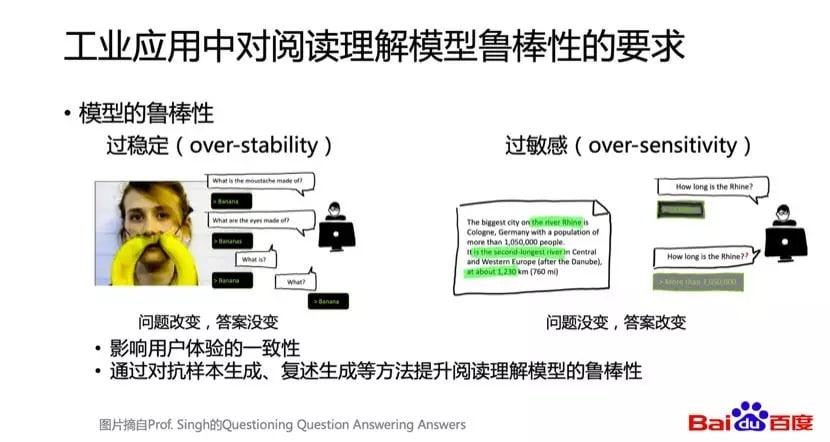
(1)工业应用中对于模型鲁棒性的要求
现在用到的深度学习模型存在着很多模型不稳定,鲁棒性的问题,包括过稳定问题和过敏感问题。过稳定问题主要是指问题的语义改变了,但是我们发现模型预测的答案没有变。过敏感问题是指问题的说法改变了,语义并没有改变,但是模型预测的答案却改变了,通常对问题加了一个简单的问号,答案就改变了。不管是过稳定问题还是过敏感问题,其实都不是我们所期望的,尤其在应用当中,是非常影响用户体验的。近两年学术界有一些研究通过对抗样本的生成,还有问题复述生成的方式,尝试解决模型鲁棒性的问题。
(2)工业应用中对于模型泛化能力的要求
这两年我们可以看到很多的新闻,就是某家机构在某个数据集上又超越了人类。但是实际上思考一下,我们会疑惑是不是真的把某一个任务解决好了?其实不是的,我们只能讲我们比较好的解决了某一个数据集,而不是真正地解决了某一个任务。在工业应用当中,比如我在百科数据集上训练了一个模型,当应用到知道数据集的时候,我们期望只需要引入很少量的标注数据就能够获得很好的效果,能够很快很好地迁移到一个新的领域上。后面我们也会投入更多的资源在这方面展开研究,希望能够真的提高模型的泛化能力,使得这些模型在工业应用当中取得更好的效果。

最后总结一下我们在百度阅读理解的技术工作,V-NET是面向搜索场景的多文档阅读理解,KT-NET是知识表示和文本表示融合模型,以及大规模中文阅读理解的DuReader数据集。

至此,“2019自然语言处理前沿论坛”自动问答主题《百度阅读理解技术研究及应用》的分享结束,下一期将分享新的主题,敬请关注。
百度自然语言处理(Natural Language Processing,NLP)以『理解语言,拥有智能,改变世界』为使命,研发自然语言处理核心技术,打造领先的技术平台和创新产品,服务全球用户,让复杂的世界更简单。
本文转自公众号 百度NLP,原文地址

Comments