

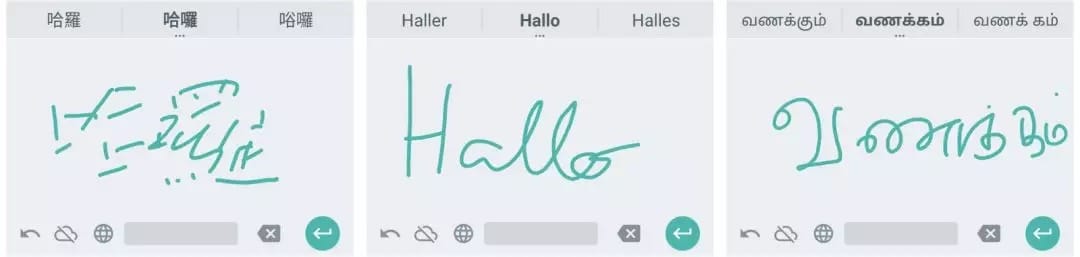
手写输入作为与设备的一种重要交互方式一直都受到各个厂商的重视,特别是对于中老年朋友来说,更喜欢通过手写而不是键盘的方式来进行输入。此外,对于一些复杂的语言、交互演示场景、试教等,手写输入扮演着不可或缺的作用。

15年时谷歌曾经推出了支持82种语言的手写输入,并在去年升级为100种语言。但随着机器学习的迅速发展,研究人员也在不断重构着以往的方法为用户带来更快更准的体验。
先前的模型基于人工设计的方法,将输入笔画切分成单个字符并利用对应的解码器进行理解。为了提高准确率和速度,研究人员开发了基于循环神经网络的端到端手写识别系统,通过将输入笔画转为贝塞尔曲线序列进行分析处理,利用RNN得到了准确率更高的识别结果。在这篇文章中,研究人员以拉丁字母为例详解了新型手写字符识别背后的故事。

触点、曲线和循环神经网络
任何手写字符识别系统都需要从识别手指/输入设备的触点。我们在屏幕或者手写板上输入的笔画可以看做是一系列包含时间戳的出触点序列。考虑到输入的设备在尺寸、分辨率上各不相同,研究人员首先对输入的触点坐标进行了归一化处理。而后利用三次贝塞尔曲线来对触点序列进行描述,以便RNN能够更好的理解笔画序列的形状。
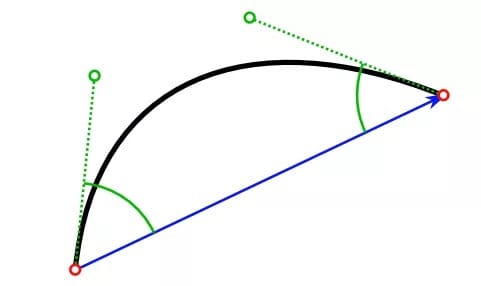
贝塞尔曲线在手写识别中有着很长的应用历史,基于贝塞尔曲线可以对输入数据进行更加连续的表达,对于不同的采样率和分辨率更加鲁棒。在贝塞尔曲线表达中,每一条曲线可以被表示为起始点、终止点和两个控制点的多项式,较少的参数精确的表达输入笔画。

这种方法代替了谷歌先前基于分割-解码的方案,先前的方案需要先将输入的笔画分割成单个字符,而后利用解码的方式寻找最有可能的字符。使用贝塞尔曲线表达输入笔画的另一个优点在于它可以更加紧致的表述输入的触点序列,这将便于模型从输入中抽取输入的时序依赖性。上图中显示了利用贝塞尔曲线拟合“go”字符的过程。原始的输入点集包含了186个触点坐标,其中对于字母g可以用图中的黄色、蓝色、粉色和绿色点来表示四条三次贝塞尔曲线的序列,而对于字母o可以用橙色、翠绿色和白色表示的三条贝塞尔曲线序列来描述。
在贝塞尔曲线序列表示的输入基础上,我们需要对序列进行解码才能得到所表示的字符。RNN是处理序列输入的有效方式,所以研究人员利用了多层RNN来对序列数据进行解码,并为每一个输入序列生成一个表示其所代表字母可能性的矩阵,从而计算出手写笔画代表的字符。

在实际过程中,研究人员选择了一种双向的准循环神经网络来作为处理模型,这种模型中具有交替的卷积和回归层在理论上具有并行处理的可能性,同时也在网络权重较少的情况下保持模型的能力。由于手写字符识别更多的是在移动设备上进行,小尺寸的模型是保持速度的关键所在。
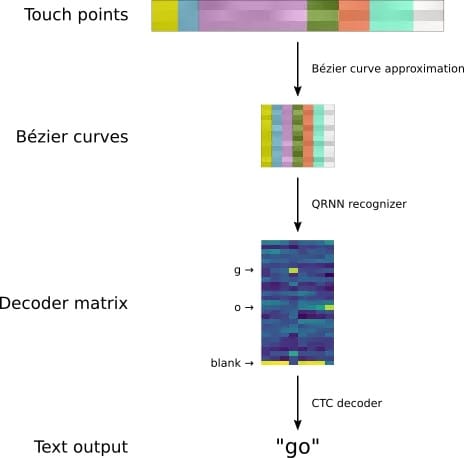
为了对曲线序列进行解码,识别出对应的字符,循环神经网络会生成一个表示字母可能性的解码矩阵。矩阵的每一列代表了一条贝塞尔曲线,而每一行则代表了对应输入曲线对应的字母可能性。在上图中的解码矩阵中,对于每一列我们可以看到它和先前的序列一起构成了26个字母上对应的概率分布。第一到第三条曲线序列都对应着blank(代表还没有识别出字符,来自于CTC算法),而到了第四条曲线时网络在g字母处得到了较高的概率,这意味着RNN从前面的四条曲线中识别出了字母g,而后面的第八条曲线上我们又可以看到字母o对应的位置有较高的概率。通过序列处理就能将曲线解码为对应的字符。
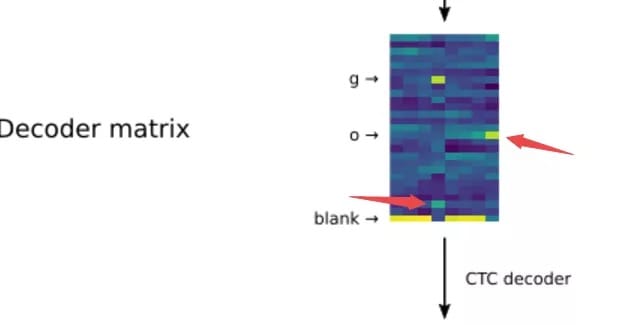
此外还有两个有趣的现象值得注意,对于字母g的识别,在第四列中y字母(倒数第二个)对应的激活也比较高,这是因为g和y看起来比较类似。而对于o字母的识别,每一条曲线输入后o对应的概率在不断提升,这也和我们的直觉相吻合,o代表的圆圈画的越完整是o的可能性就越大。
此外研究人员还引入了有限状态语言模型解码器来对网络的输出进行组合,对于某些常见的字符组合会有更大的可能性输入,这样就可以快速的将解码出的字符转换为单词输出。
总结下来新方法一共分为了三个主要步骤,首先将触点序列转为紧凑的贝塞尔曲线,随后利用QRNN进行解码,最后利用字符结果组合出对应的单词。虽然看起来很简单,但这种方法相比原先的方法使得识别的错误率下降了20%-40%!
关于模型训练
模型的训练分为两部分,一部分是基于connectionist temporal classification(CTC)损失对模型进行训练,另一部分是基于贝叶斯优化的解码器调参。训练的数据主要包含了三个数据集,分别是IAM-OnDB在线手写字符数据集,IBM-UB-1英语数据集,以及ICDAR 2013的中文数据集Chinese Isolated Characters,ICFHR2018中的越南语数据集。详细的数据集链接请参看文末参考文献。
设备部署
对于手写识别来说,精确的模型没有速度的保证对于用户来说是无法忍受的。为了减小手写输入的延时,研究人员将模型在tensorflow Lite上进行了实现,通过如量化等一系列手段成功地减小了模型和最终应用安装包的大小。完善的模型加上小巧的实现将让手机更容易看懂我们笔迹。如果想要了解更多细节,请参考原文
本文转自公众号 将门创投,原文地址

Comments