

本文转自《How to Fool Artificial Intelligence》
原文是英文,Google机器翻译的效果并不好,但不影响整体理解。
自动驾驶汽车。语音操作的智能家居。自动化医学诊断。可以代替老师和治疗师的聊天机器人。
多亏了人工智能,这些技术不再只存在于牵强的科幻世界中。在AI的推动下,在 数百项行业颠覆性技术中,它们仅占四分之三。
人工智能正在迅速融入我们的日常生活。
但是,在我们将大量的责任交予神奇地为我们完成工作的算法之前,问题仍然存在。
他们总是工作吗?我们可以一直信任他们吗?
我们可以相信他们的生活吗?
如果不良行为者有办法故意诱使算法做出错误的决定,该怎么办?
不管是好是坏,这实际上已经在机器学习的一个子领域中进行了广泛研究,该领域称为对抗机器学习。它孕育了能够“愚弄” ML模型的技术和可以抵御这些攻击的技术。
对抗性攻击涉及提供模型对抗性示例,这些示例是攻击者设计的输入,目的是故意欺骗模型以产生错误的输出。
在深入研究对抗性示例的创建方式之前,让我们看一些示例。
对抗中的例子
让我们玩一个发现差异的游戏:

如果您什么都没想到,请不要担心。屏幕疲劳的眼睛还没有使您失望。
在人眼中,它们看起来应该与蓬松的熊猫完全一样。
但是对于图像分类算法,两者之间存在很大的差异。这是获奖的视觉识别系统GoogLeNet看到的内容:

它在第二张图像上犯了一个错误的错误。实际上,它对将熊猫误认为长臂猿的误解甚至比最初的正确决定更有信心。
发生了什么!?
如上所示,将滤镜应用于原始图像。尽管变化对我们来说是难以察觉的-我们仍然看到相同的黑白大衣,钝嘴和告诉我们正在看熊猫的经典黑眼圈-算法所看到的却完全不同。
熊猫图像与一层噪声(通常称为扰动)相结合,是一个对抗性示例,导致模型分类错误。
其他一些视觉对抗示例:
就像机器的视觉幻觉一样,视觉对抗示例可以使模型“半透明”,并看到不存在的东西。
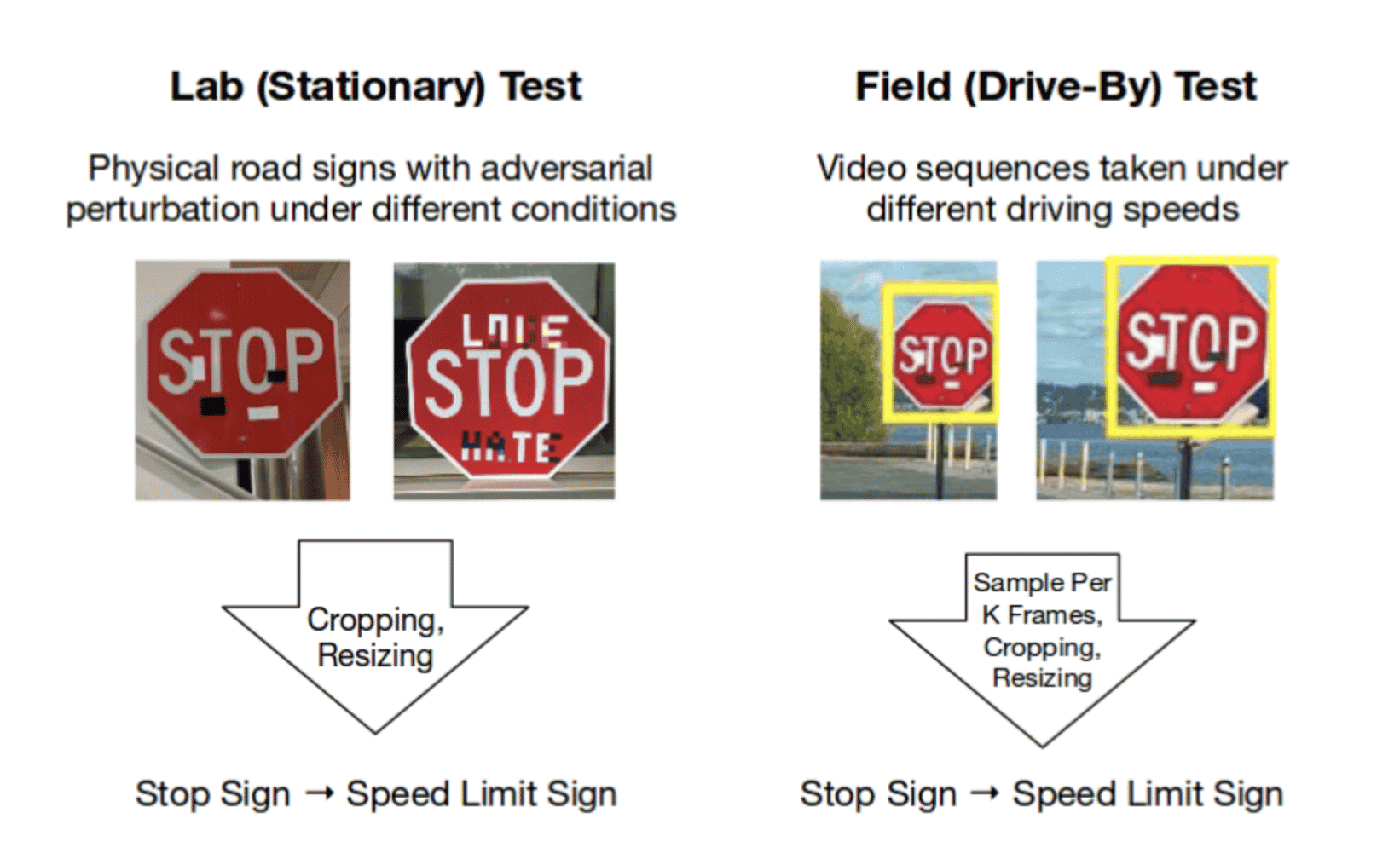
试想一下,一旦自动驾驶汽车问世,这将带来什么影响。尽管磁带很容易被误认为是我们的粗心涂鸦,但汽车会无视停车标志,直接向前驶入事故。

如果整合到T恤设计中,则可以有效地成为自动监视系统的“隐形斗篷”。
还有一个音频示例…

您可以想象,对音频输入进行大幅度更改的能力(我们甚至听不到自己的声音)在语音控制的智能家居的未来中可能会带来相当严重的后果。
总而言之,对抗性例子非常酷……也非常令人担忧。
为了了解所有这些最新算法的“破坏力”,让我们看一下模型是如何首先学会进行决策的。
训练机器学习算法
在最基本的层次上,机器学习算法由人工神经元组成。如果我们将神经网络看作是从输入中剔除输出的工厂,那么神经元就像是较小的流水线,即组成更全面处理系统的子单元。
神经元输入输入(Xn),每个输入均乘以权重(Wn),相加,加到偏差(b)上,并在分离输出之前馈入激活函数。
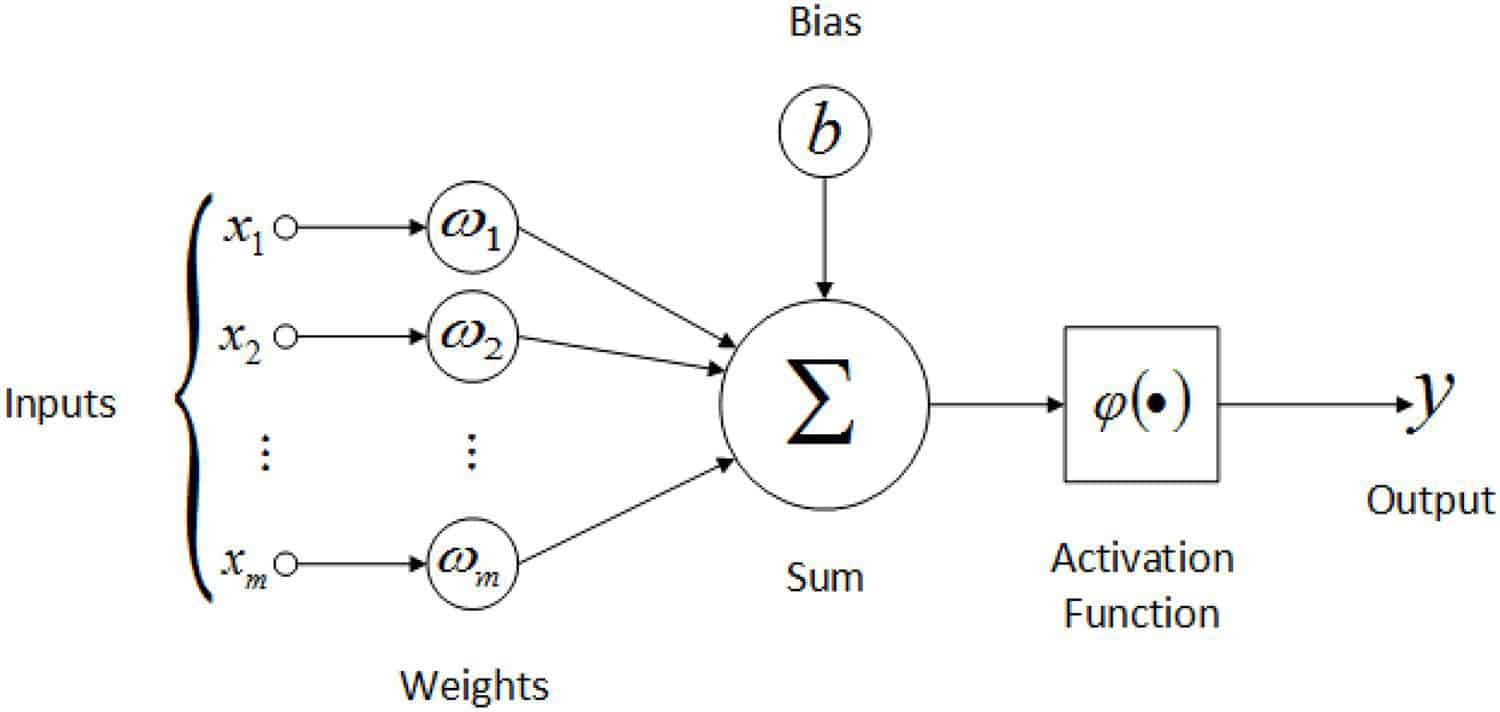
无论重量和偏见被认为是模型参数,模型的内部变量,允许它以特定的方式处理输入数据。在训练过程中,通过更新参数可以提高模型的准确性。
当多层神经元相互堆叠时,一层的输出成为下一层的输入,我们得到了深层的神经网络。这样可以进行更复杂的计算和数据处理。
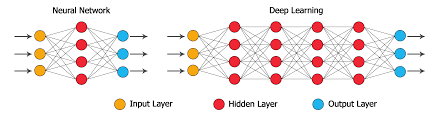
这些节点中的每个节点都有自己的权重和偏差,所有这些都对整个模型的参数集有所贡献。
那么,我们如何训练这些模型参数,以便它们给我们最准确的输出?
答案:损失函数。
从概念上讲,损失函数表示模型输出与目标输出之间的距离。它基本上告诉我们我们的模型“有多好”。从数学上讲,较高的损耗值表示精度较低的输出,而较低的损耗值表示精度较高的输出。
能够根据模型的输入,实际输出,预期输出和参数找到模型的损失函数,这是训练模型的关键。
梯度下降:找到最佳模型参数
直观地,我们希望在更新每个参数值的同时使损失函数最小化,以便模型的预测可以变得更加准确。我们通过梯度下降来完成此过程,该过程使我们能够找到损失函数的最小点。
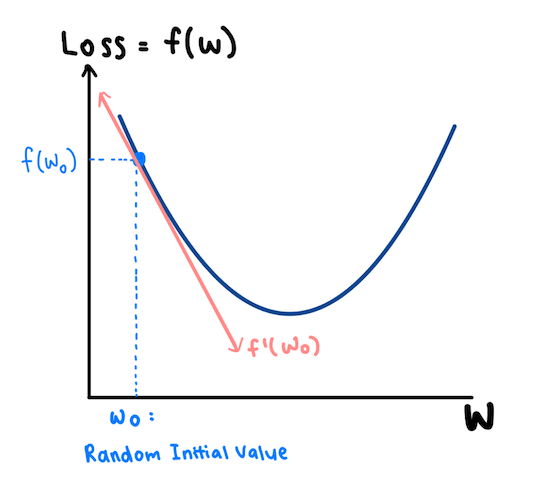
让我们来看一个例子。假设损失函数f(w)由左侧所示的二次函数表示。它仅取决于一个参数:w。
该算法首先选取一个随机的初始值W0,然后计算衍生物F’(瓦特₀ )的F(W 0)在W 0,由于衍生物的斜率是负的,我们知道,我们可以减少F(X),通过增加W 0。
因此,我们在模型中使用重量轻推得到的权利,从W 0至W 1,作为我们的损失减少F(w ^ ₀ )到F(w ^ ₁ )。这种简单的调整称为学习步骤。在(瓦特₁,F(瓦特₁ )),该衍生物被再次服用。由于它再次具有负斜率,因此需要在右侧和下方进行另一个学习步骤。
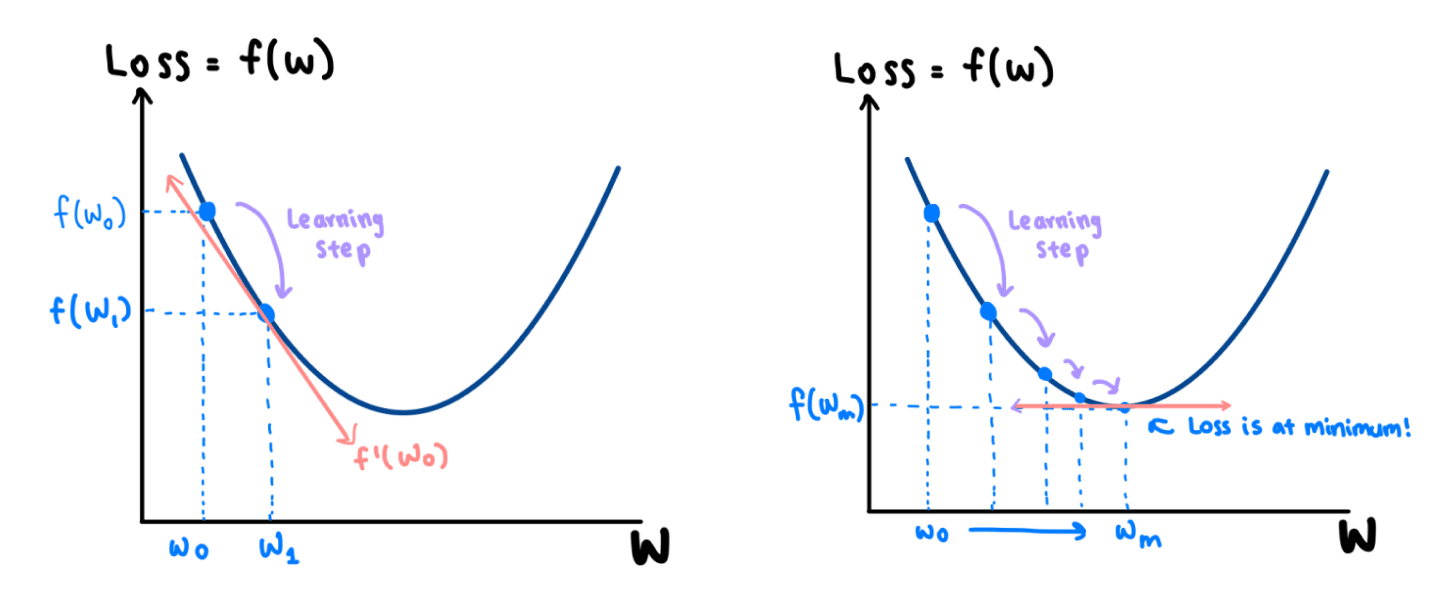
逐步地,我们在wm处达到曲线的最小值,其中导数的斜率是0。在这一点上,我们的损失是最小的。
还有…中提琴!我们最终得到了权重w,该权重已被训练以帮助我们的模型做出更准确的决策。
当模型的参数涉及大量的权重和偏差时,此过程的复杂度要高得多。代替二次曲线,将针对所有权重和偏差绘制损失函数图。这是我们什至无法可视化的尺寸。
但是,直觉保持不变。我们将对每个参数采用损失函数的导数,并以逐步的方式相应地更新参数集。
现在我们对机器学习模型的学习方式有了基本的了解,我们可以深入研究如何制作对抗性示例来“打破”它们。
如何创建对抗性示例?
此过程还依赖于损失函数。本质上,我们以与学习机器学习模型相同的方式攻击机器学习模型。
训练是通过在 最小化损失函数的同时更新模型参数来进行的,而对抗性示例是通过在最大化损失函数的同时更新输入来生成的。
但是,请稍等。难道这不只是为我们提供看起来与原始输入截然不同的输入吗?我们看到的对抗性示例(如本文开头的熊猫)如何与原始图片看起来一样?
为了回答这个问题,让我们看一下对抗性示例的数学表示形式:
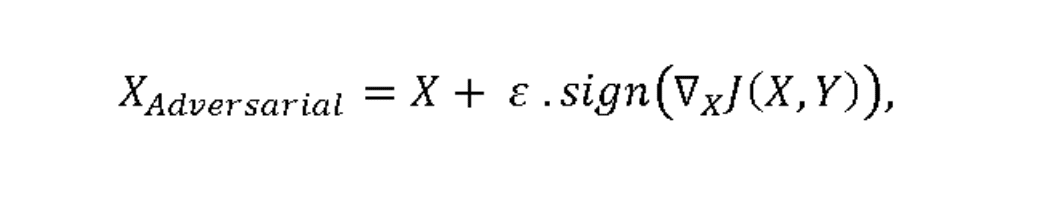
J(X,Y)表示损失函数,其中X为输入, Y为输出。在图像数据的情况下,X将是代表每个像素的数值矩阵。
的∇符号代表的取导数操作 的功能在所有其输入像素。与以前一样,当我们尝试确定是向上还是向下微调每个像素值时,每个导数斜率的正负号(正负)都很重要,因此sign()函数起作用。
为了使我们的眼睛看不到对像素值的调整,将这些变化乘以非常小的值ε。
因此,整个ε.sign(∇xJ(X,Y))值就是我们的扰动,表示每个图像像素变化的值矩阵。扰动被添加到我们的原始图像中以创建对抗图像。
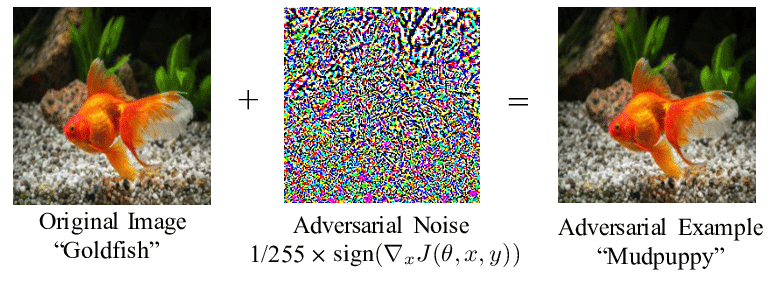
这称为快速渐变符号方法(FGSM)。
一个警告:假设攻击者可以完全访问模型的渐变和参数。在现实世界中,通常情况并非如此。
通常,只有模型开发人员才能了解算法的确切参数。但是,由于存在多种攻击方法,因此有多种方法可以解决此问题。
对抗攻击的类型
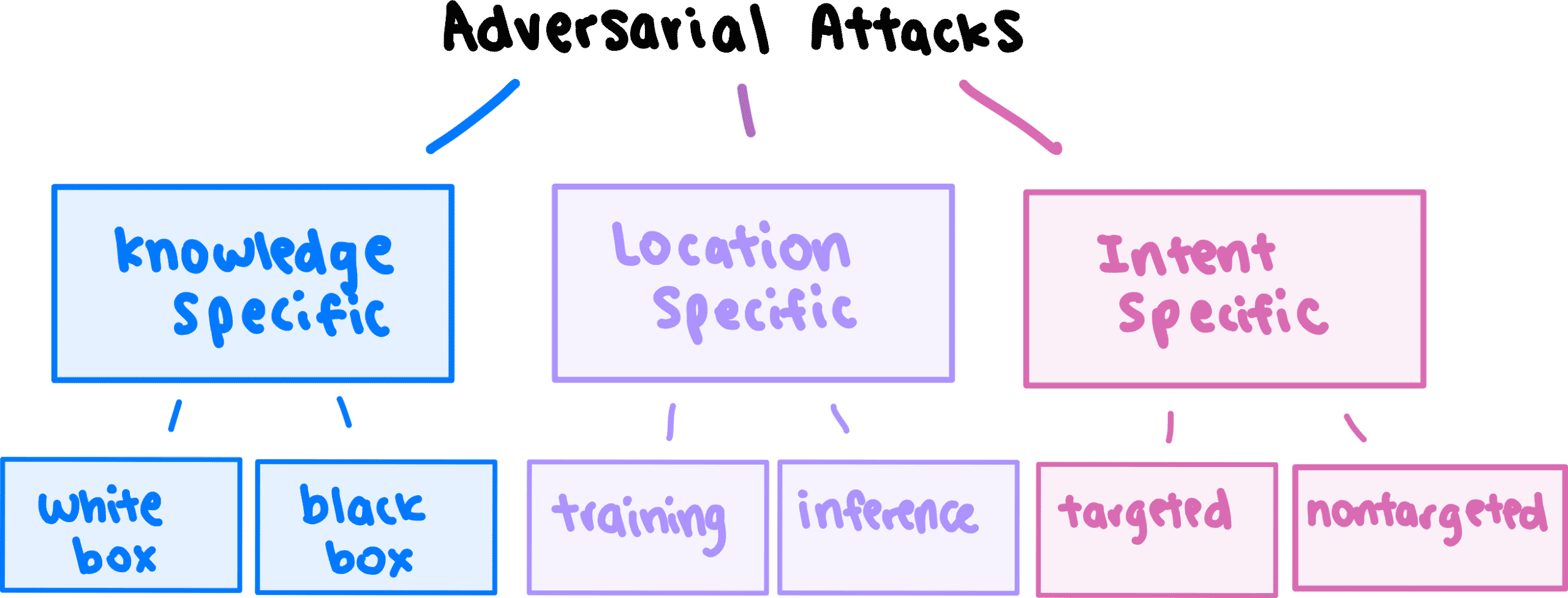
可以根据三种不同的标准对攻击方法进行分类:
- 量的知识,攻击者具有对模型
- 该位置的模型开发和部署期限内攻击
- 攻击者的意图或目标。
让我们进一步分解。
知识特定攻击
- 白盒攻击:攻击者可以完全访问模型的内部结构(包括渐变和参数),然后可以使用该内部结构生成对抗性示例。
- 黑匣子攻击:攻击者没有有关模型内部结构的信息。该模型被视为“黑匣子”,因为它只能从外部观察到–我们只能看到它为输入提供了什么输出。但是,使用这些输入和输出,我们可以创建和训练“代理”模型,从中可以生成对抗性示例。
特定位置的攻击
- 训练攻击:将与错误输出相对应的操纵输入注入训练数据中,因此,即使在部署之前,模型架构本身也存在缺陷。
- 推理攻击:不会对训练数据或模型架构进行篡改。在训练模型以提示不正确的输出后,将对抗性输入输入模型。
目的特定攻击
- 有针对性的攻击:操纵输入将输出更改为特定的 错误答案时。例如,攻击者的目标可能是将停车标志识别为限速标志。
- 非目标攻击:操纵输入将输出更改为除正确答案之外的任何内容。例如,在生成对抗性示例时,攻击者可以将停止标志识别为限速标志,屈服标志或掉头标志,这样就可以了。
我们所采用的方法FGSM是一种白盒式非针对性攻击。对于上面列出的不同应用,还存在其他机制,例如基本迭代方法(BIM)和基于雅可比显着图的攻击(JSMA)。
为了使本文处于入门级别,我不会深入探讨其他方法的工作方式。如果您有兴趣,我建议您阅读美国国家标准技术研究院的综合分类法:NIST内部或跨部门报告(NISTIR)8269(草稿),…的分类法和术语此NIST机构间/内部报告(NISTIR)旨在迈向确保人工…csrc.nist.gov
对抗性例子的应用
现在我们对什么是对抗攻击以及它们如何工作有了很好的了解,请允许我暂时放大。
让我们将技术因素放在上下文中。
如果释放出真实世界,对抗性例子会带来什么危险?
- 自动驾驶汽车:除了前面显示的停车标志示例之外,自动驾驶系统还可以从策略性地放置在地面上的几条胶带上,转入错误的车道或以相反的方向行驶。
- 医学诊断:良性肿瘤可能被误分类为恶性肿瘤,导致患者不必要的治疗。
- 面部识别:这些人不超过一副眼镜(价格仅为0.22美元),因此欺骗了面部识别系统以将其识别为名人。甚至FBI的面部识别数据库似乎也不再不可避免。

4.军事打击:随着AI算法越来越多地集成到军事防御系统中,对抗性攻击对国家安全本身构成了非常明显的威胁。如果对预定目标发动了罢工怎么办?
5.语音命令:越来越多的Alexas和Echos进入家庭。声音纯净的声音消息可以向这些虚拟助手发送“静音”命令,从而禁用警报并打开门。
嗯是的。这是非常非常令人担忧的。
幸运的是,这并不意味着是时候放弃我们宝贵的算法了。正在进行有关防御机制的研究,这些机制可以保护我们的模型免受这些黑客攻击。
防御对抗攻击
对抗训练是最常见的防御方式。
它涉及预先生成对抗性示例,并教我们的模型以使其在训练阶段与正确的输出匹配。这就像加强模型的免疫系统,为模型在发生之前的攻击做好准备。
尽管这是一个直观的解决方案,但它绝对不是完美的。它不仅非常繁琐,而且几乎从来都不是万无一失的。必须生成大量的对抗示例,这在计算上是昂贵的。更不用说该模型对于未经训练的任何示例仍然是毫无防御的。
正如领先的机器学习研究员Ian Goodfellow所说的那样,这就像“玩一玩w鼠游戏;它可能会关闭某些漏洞,但会打开其他漏洞。”
好吧,所以…我们还能做什么?
视神经科学为灵感
这就是它变得更有趣的地方。
在阅读本文时,您可能会质疑:为什么首先存在对抗性示例?当机器学习模型无法做到时,为什么我们的眼睛如此擅长观察图像的微小扰动?
一些研究人员认为,模型对对抗性示例的敏感性不是“错误”,而是人类和算法看待世界的根本不同方式的自然结果。
换句话说,虽然噪声对我们来说似乎微不足道,但它们是机器学习模型能够采用的重要功能,因为它们以更高的复杂度处理信息。
有关此理论的更多信息,我强烈建议您查看以下文章。对抗性例子不是错误,而是功能阅读论文下载数据集在过去的几年中,有一些对抗性的例子-或输入内容略有不足…gradientscience.org
如果由于人类大脑和模型处理数据的方式存在重大差异而存在对抗性示例,那么我们是否可以通过 使机器学习模型更像大脑来解决问题?
事实证明,这是MIT-IBM Watson AI Lab解决的确切问题。具体来说,研究人员希望通过添加模仿哺乳动物视觉皮层的元素,使卷积神经网络(处理视觉数据的算法)更加健壮。
而且有效!该模型称为VOneBlock,其性能优于现有的最新算法。
弥合神经科学与AI之间的鸿沟-更具体地说,将神经科学发现整合到机器学习模型体系结构的开发中-是令人兴奋的研究领域。
幸运的是,我们几乎没有刮过表面。对于我们等不及拥有智能家居,自动驾驶汽车,更快,更准确的医疗诊断,更容易获得的教育和心理健康资源等等的世界,还有很多希望。
更强大的机器学习算法正在开发中。
重要要点
- 对抗性攻击涉及为机器学习模型提供输入,这些输入有目的地提示错误的输出,实质上是在“欺骗”模型。
- 损失函数表示模型的输出与真实输出之间的距离。
- 通过在最小化损失函数的同时更新其内部参数来训练机器学习模型。
- 通过在最大化损失函数的同时更新输入来创建对抗性示例。
- 可以基于攻击者的知识和意图以及攻击的位置对不同类型的对抗攻击进行分类。
- 对抗性攻击可能会对自动驾驶汽车,面部识别和语音助手等中使用的视听系统造成灾难性后果。
- 通过对抗训练可以防御对抗攻击。
- 最近的研究表明,通过从神经科学中获得启发,可以使机器学习模型对付对抗性示例变得更加健壮。
资料来源
- http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-easier-than-defending-it.html
- https://www.toptal.com/machine-learning/adversarial-machine-learning-tutorial
- https://arxiv.org/abs/1707.08945
- https://arxiv.org/abs/1602.02697
- https://venturebeat.com/2021/01/08/is-neuroscience-the-key-to-protecting-ai-from-adversarial-attacks/
- https://www.biorxiv.org/content/10.1101/2020.06.16.154542v1
- https://spectrum.ieee.org/automaton/artificial-intelligence/embedded-ai/adversarial-attacks-and-ai-systems
- https://csrc.nist.gov/publications/detail/nistir/8269/draft

Comments