

本文轉載自公眾號 讀芯術,原文地址
為了建立性能良好的機器學習(ML)模型,必須在來自相同目標分佈的數據上訓練模型並進行測試。然而,有時我們只能從目標分佈中收集到有限數量的數據。這些數據可能不足以構建所需的訓練/開發/測試集。
與此同時,來自其他數據分佈的類似數據可能隨時可用。在這種情況下該怎麼辦?讓我們對一些想法進行討論吧!
一些背景知識
如果你還不熟悉基本的機器學習概念,你可以仔細閱讀此版塊,以便更好地理解本文內容:
· 訓練集,開發集及測試集:注意,dev集也被稱為validation或hold-on集。
· 偏差(欠擬合)和方差(過擬合)誤差:這是對這些誤差的一個非常簡單的解釋。
· 如何正確地拆分訓練/開發/測試集。
場景
假設你正在構建一個狗狗圖像分類器應用程序,其可用來確定某圖像是否為狗。
該應用程序適用於農村地區的用戶,他們可以通過移動設備拍攝動物的照片,以便應用程序為他們分類動物。
通過對目標數據分佈的研究,我們發現圖像大多是模糊的、低分辨率的,如下圖所示:

你只能收集到8000張這樣的圖像,這還不足以構建訓練/開發/測試集。假設你已確定至少需要100000張圖像。
你想知道是否可以使用另一個數據集中的圖像-以及你收集到的8000張圖像-來構建訓練/開發/測試集。
你意識到可以很容易地通過網絡抓取來建立一個包含100000張或更多圖像的數據集,這些圖像的頻率與我們需要的狗圖像和非狗圖像的頻率類似。
但是,很明顯這個web數據集來自不同的分佈,其圖像清晰且分辨率高,如:

如何構建訓練/開發/測試集?
你不能只使用收集的8000張原始圖像來構建訓練/開發/測試集,因為它們不足以構成一個性能良好的分類器。通常,計算機視覺像其他自然感知問題(語音識別或自然語言處理)一樣,需要大量的數據。
此外,你不能只用web數據集。分類器不能很好地處理用戶的模糊圖像,這與用於訓練模型的高清晰度的web圖像不同。所以,你需要做些什麼?讓我們考慮一些可能性。
一個可能的選項-數據洗牌(shufflig)
你可以做的是將兩個數據集組合起來並對它們進行隨機洗牌。然後,將生成的數據集拆分為訓練/開發/測試集。
假設你決定按96:2:2%拆分成訓練/開發/測試集,這個過程將類似於:

拆分完畢後,訓練/開發/測試集將按要求來自相同的分佈,如上圖所示。
然而,這裡有一個很大的缺點!
如果你查看開發集,在2000張圖像中,平均只有148張圖像來自目標分佈。
這意味着在大多數情況下,你都在優化web圖像分佈(2000張圖像中有1852張)的分類器——這並不是你想要的!
當根據測試集評估分類器的性能時,情況類似。所以,該方法並不太適合用來分割訓練/開發/測試集。
一個更好的選擇
另一種選擇是使開發/測試集來自目標分佈數據集,訓練集來自web數據集。
假設你仍像以前一樣按照96:2:2%拆分成訓練/開發/測試集。每個開發/測試集包含2000張圖像-來自目標數據集-其餘圖像將被分到訓練集,如下圖所示:
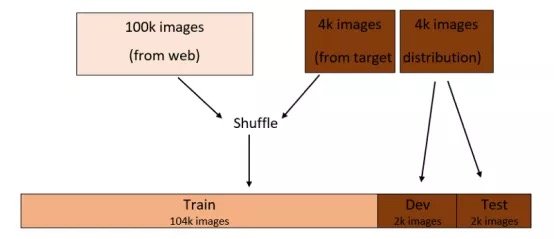
通過此拆分,你將優化分類器,使其在目標分佈上表現良好,這正是你所關心的。這是因為開發集的圖像僅來自目標分佈。
但是,訓練分佈現在不同於開發/測試分佈。這意味着在大多數情況下,你都是在web圖像上訓練分類器。因此,優化模型將花費越來越多的時間。
更重要的是,相對於訓練集上的誤差,你將無法輕鬆地判斷開發集上的分類器誤差是方差誤差,數據不匹配誤差,或是兩者都有。
讓我們更詳細地考慮這個問題,看看我們能做些什麼。
方差與數據不匹配
考慮上面第二個選項中的訓練/開發/測試集的拆分。簡單起見,假設人為誤差為零。
另外,假設你發現訓練誤差為2%,開發誤差為10%。這兩個誤差之間8%的誤差中有多少是由於兩個數據集之間數據不匹配造成的(假定它們來自不同的分佈)?而模型的方差(過擬合)是多少?我們不知道。
讓我們修改訓練/開發/測試的拆分。取出訓練集中的一小部分,稱之為「橋」集。橋集不會被用於訓練分類器,而是一個獨立的集合。這種拆分會產生4個集合,這四個集合屬於兩個數據分佈,如下所示:

方差
通過這種拆分,我們假設你發現訓練和開發誤差分別是2%和10%,發現橋集的誤差是9%,如下所示:

現在,訓練集誤差和開發集誤差之間的8%的誤差有多少是方差誤差?有多少是數據不匹配誤差?
很簡單!答案是7%的方差誤差和1%的數據不匹配誤差。但是為什麼呢?
這是因為橋集和訓練集是來自相同的分佈,它們之間的誤差差是7%。這意味着分類器在訓練集上過擬合。這說明我們現在有一個高方差問題。
數據不匹配誤差
現在,我們假設你發現橋集的誤差達到了3%,其餘的和之前一樣,如下所示:

訓練集和開發集之間8%的誤差中有多少是方差誤差?有多少數據不匹配誤差?
答案是1%的方差誤差,7%的數據不匹配誤差。為什麼?
這一次,是因為如果分類器來自相同的分佈(如橋集),那麼它在以前從未見過的數據集上表現良好。如果它來自不同的分佈,比如開發集,那麼它的性能就很差。因此,我們有一個數據不匹配的問題。
減少方差是機器學習中一項常見的任務。例如,你可以用正則化方法(regularization methods),或者分配一個更大的訓練集。
減少數據不匹配誤差是一個更有趣的問題,下面我們就來討論一下。
緩解數據不匹配
為了減少數據不匹配誤差,你需要以某種方式將開發/測試數據集(目標分佈)併入訓練集。
從目標分佈中收集更多數據添加到訓練集常常是最佳選擇。但是,如果這不可行的話(正如我們在討論開始時假設的那樣),你可以嘗試以下方法。
誤差分析
分析開發集上的誤差以及這些誤差與訓練集上誤差的不同之處可以為解決數據不匹配問題提供思路。
例如,如果發現開發集上的許多誤差發生在動物圖像的背景為岩石的情況下,可以通過在訓練集和中添加具有岩石背景的動物圖像來減輕這些誤差。
人工數據合成
將開發/測試集的特性合併到訓練集的另一種方法時合成具有類似特性的數據。
例如,我們之前提到過,我們開發/訓練集中的圖像大多是模糊的,而我們的訓練集大多是由網絡上的清晰圖像構成的。可以人為地將訓練集中的圖像模糊化,使其更類似於開發/測試集,如下所示:

然而,這裡有一個重要的注意點!
最終可能會因為你所做的人工特徵使分類器過擬合。
在我們的示例中,由某些數學函數人為生成的模糊可能只是目標分佈圖像中存在的模糊的一個子集。
換言之,目標分佈中的模糊可能是由多種原因造成的。例如,霧,低分辨率相機,物體的移動都可能是原因。但是合成的模糊可能並不代表所有的這些原因。
一般來說,當為訓練集(該訓練集可用於解決任何類型的問題,例如計算機視覺或語音識別)進行合成數據時,在建立該合成數據集的模型時,可能會發生過度擬合。
在人眼看來,這個數據集看起來足夠代表目標分佈。但實際上,它只是目標分佈的一小部分。所以,在使用這個強大的工具-數據合成時請記住這一點。
總結
在開發一個機器學習模型時,理想情況下,訓練/開發/測試數據集都應該來自同一個數據分佈,即當用戶使用該模型時將遇到的數據分佈。
但是,有時無法從目標分佈中收集到足夠的數據來構建訓練/開發/測試集,而其他分佈中的類似數據卻很容易得到。
在這種情況下,開發/測試集應該來自目標分佈,而來自其他分佈的數據可以被用於構建(大多數的)訓練集。可以使用數據匹配技術來緩解訓練集和開發/測試集之間的數據分佈差異。

Comments