

如果你不知道什么是ML模型,请看一下这篇文章。
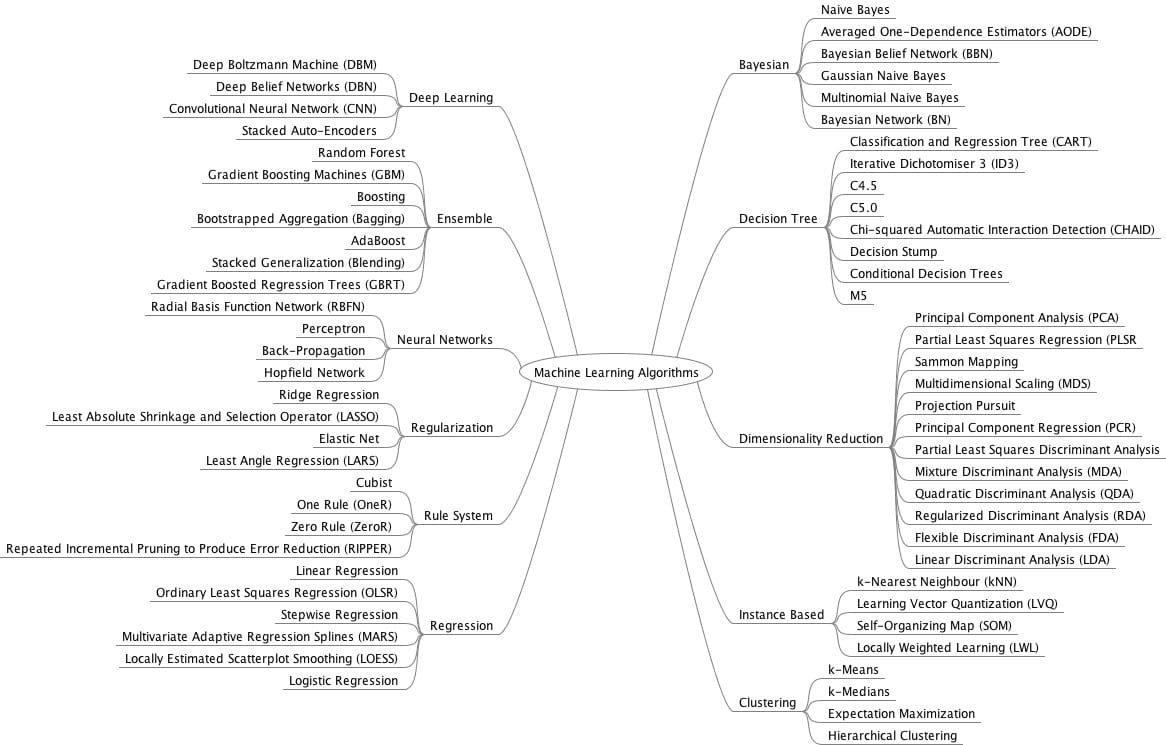
学习机器学习的课程和关于它的阅读文章并不一定告诉你使用哪台机器学习模型。它们只是让您直观了解这些模型的工作原理,这可能会让您无法为问题选择合适的模型。
在我与ML的旅程开始时,关于解决问题,我会尝试很多ML模型并使用最有效的模型,我现在仍然这样做,但我遵循一些最佳实践 – 关于如何选择机器学习模型 – 我从经验,直觉和同事那里学到,这些最佳实践使事情变得更容易,这就是我收集的内容。
我会告诉你根据问题的性质使用哪种机器学习模型,我会尝试解释一些概念。

分类
首先,如果你有一个分类问题“预测给定输入的类”。
请记住,您将对输入进行分类的类数,因为有些分类器不支持多类预测,它们仅支持2类预测。
– 缓慢但准确
– 快
注意:SVM内核使用(来自Andrew NG的课程)
- 当要素数大于观察数时,请使用线性内核。
- 当观察数量大于特征数量时,使用高斯核心。
- 如果观测数量大于50k,使用高斯核时速度可能是一个问题; 因此,人们可能想要使用线性内核。
回归
如果你有一个回归问题“这预测了一个连续的价值,比如预测房子的价格给出了房子的大小,房间的数量等等”。
– 准确但缓慢
– 快
聚类
如果你有一个聚类问题“根据它们的特征将数据分成k组,使得同一组中的对象具有某种程度的相似性”。
分层聚类(也称为分层聚类分析或 HCA)是一种聚类分析方法,旨在构建聚类层次结构。层次聚类策略通常分为两种:
- 凝聚性:这是一种“自下而上”的方法:每个观察都在它自己的集群中开始,并且当一个集群向上移动时,它们将被合并。
- 分裂:这是一种“自上而下”的方法:所有观察都在一个集群中开始,并且当一个集体向下移动时,递归地执行分割。
非等级聚类:
如果您正在使用分类数据进行聚类
维度降低
PCA可以被认为是对数据拟合n维椭球,其中椭球的每个轴代表主要成分。如果椭圆体的某个轴很小,那么沿该轴的方差也很小,并且通过从数据集的表示中省略该轴及其相应的主成分,我们仅丢失相应的少量信息。
如果您想进行主题建模(下面的说明),您可以使用奇异值分解(SVD)或潜在Dirichlet分析(LDA),并在概率主题建模的情况下使用LDA。
- 主题建模是一种统计模型,用于发现文档集合中出现的抽象“主题”。主题建模是一种常用的文本挖掘工具,用于在文本体中发现隐藏的语义结构。
我希望现在对你来说更容易,我会根据你从反馈和实验中获得的信息更新文章。
我会给你留下这两个很棒的摘要。
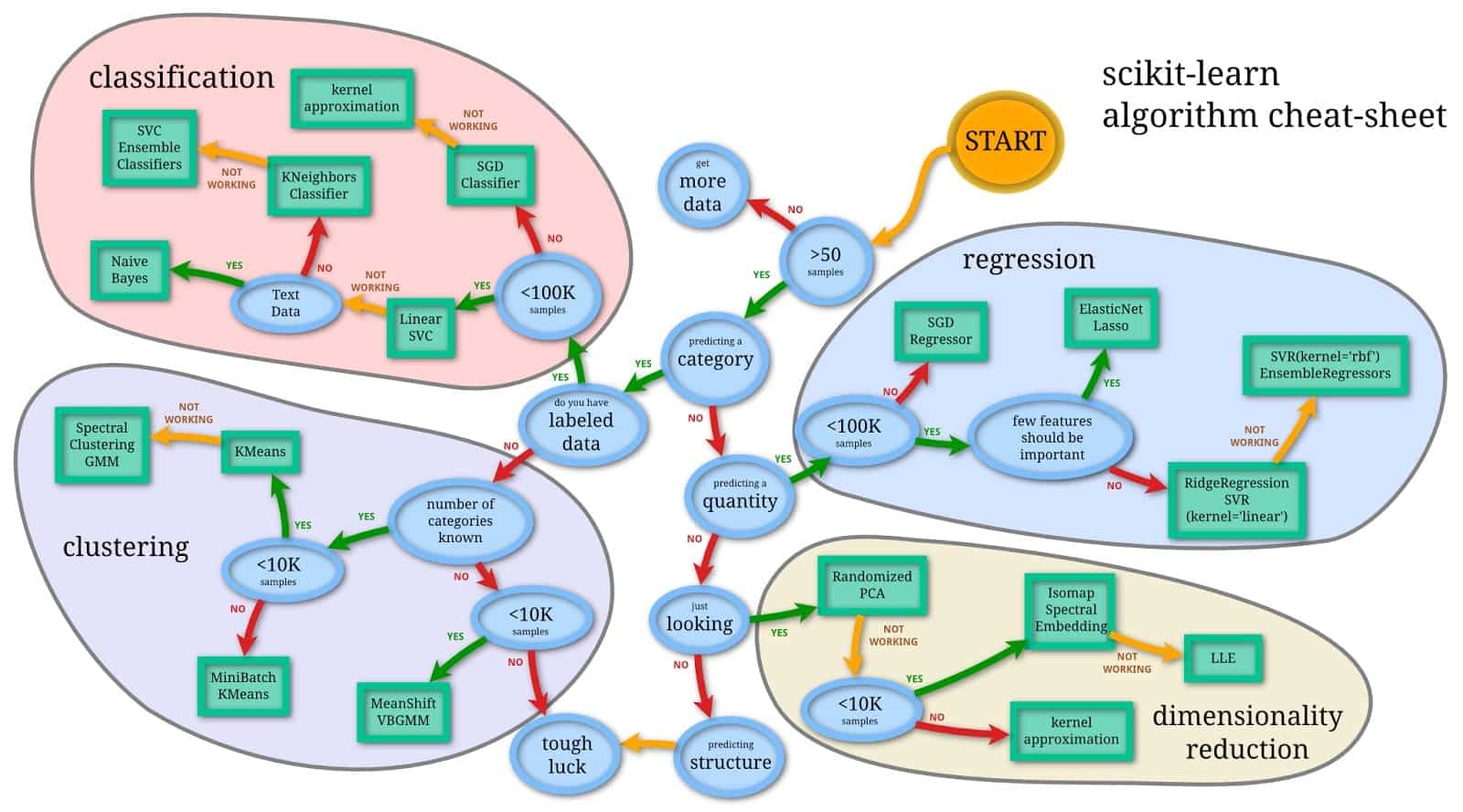
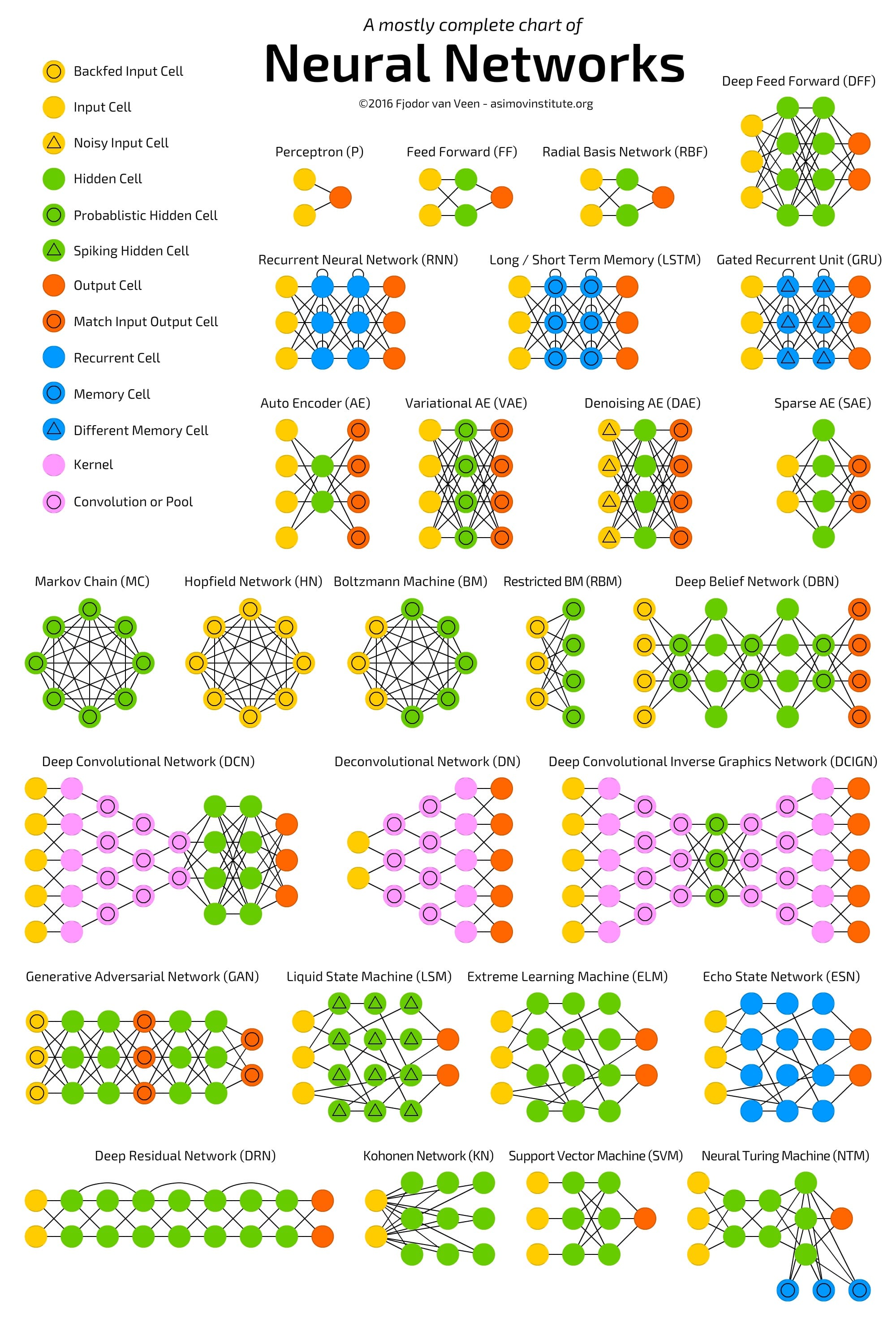
本文转自towardsdatascience,原文地址

Comments