
本文展示了DP可以为一些简单但经典的控制问题带来什么,我们通常会使用强化学习(RL)。基于DP的模型不仅学习了比RL更有效的控制策略,而且还能更快地训练数量级。
Author Archive
无监督学习K均值聚类和PCA的最佳实践
关于k均值聚类和主成分分析(PCA)的快速教程。
深度!移动机器人(AGV)产业链全分析
移动机器人(AGV)是工业机器人的一种。它由计算机控制,具有移动、自动导航、多传感器控制、网络交互等功能,在实际生产中最主要的用途是搬运,可以说只要有搬运需求的地方,就有移动机器人的应用可能。
3大主流聚类方法分别在什么情况下使用?
想要快速区分标记的数据时,我们很容易忽略无监督学习。无监督的机器学习本身就非常强大,而聚类是迄今为止这类问题中最常见的方式。
词性标注 – Part of speech

想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是词性标注?

维基百科上对词性的定义为:In traditional grammar, a part of speech (abbreviated form: PoS or POS) is a category of words (or, more generally, of lexical items) which have similar grammatical properties.
词性指以词的特点作为划分词类的根据。词类是一个语言学术语,是一种语言中词的语法分类,是以语法特征(包括句法功能和形态变化)为主要依据、兼顾词汇意义对词进行划分的结果。
从组合和聚合关系来说,一个词类是指:在一个语言中,众多具有相同句法功能、能在同样的组合位置中出现的词,聚合在一起形成的范畴。词类是最普遍的语法的聚合。词类划分具有层次性。如汉语中,词可以分成实词和虚词,实词中又包括体词、谓词等,体词中又可以分出名词和代词等。
词性标注就是在给定句子中判定每个词的语法范畴,确定其词性并加以标注的过程,这也是自然语言处理中一项非常重要的基础性工作,所有对于词性标注的研究已经有较长的时间,在研究者长期的研究总结中,发现汉语词性标注中面临了许多棘手的问题。
中文词性标注的难点
汉语是一种缺乏词形态变化的语言,词的类别不能像印欧语那样,直接从词的形态变化上来判别。
常用词兼类现象严重。《现代汉语八百词》收取的常用词中,兼类词所占的比例高达22.5%,而且发现越是常用的词,不同的用法越多。由于兼类使用程度高,兼类现象涉及汉语中大部分词类,因而造成在汉语文本中词类歧义排除的任务量巨大。
研究者主观原因造成的困难。语言学界在词性划分的目的、标准等问题上还存在分歧。目前还没有一个统的被广泛认可汉语词类划分标准,词类划分的粒度和标记符号都不统一。词类划分标准和标记符号集的差异,以及分词规范的含混性,给中文信息处理带来了极大的困难。
词性标注4种常见方法

关于词性标注的研究比较多,这里介绍一波常见的几类方法,包括基于规则的词性标注方法、基于统计模型的词性标注方法、基于统计方法与规则方法相结合的词性标注方法、基于深度学习的词性标注方法等。
基于规则的词性标注方法
基于规则的词性标注方法是人们提出较早的一种词性标注方法,其基本思想是按兼类词搭配关系和上下文语境建造词类消歧规则。早期的词类标注规则一般由人工构建。
随着标注语料库规模的增大,可利用的资源也变得越来越多,这时候以人工提取规则的方法显然变得不现实,于是乎,人们提出了基于机器学习的规则自动提出方法。
基于统计模型的词性标注方法
统计方法将词性标注看作是一个序列标注问题。其基本思想是:给定带有各自标注的词的序列,我们可以确定下一个词最可能的词性。
现在已经有隐马尔可夫模型(HMM)、条件随机域(CRF)等统计模型了,这些模型可以使用有标记数据的大型语料库进行训练,而有标记的数据则是指其中每一个词都分配了正确的词性标注的文本。
基于统计方法与规则方法相结合的词性标注方法
理性主义方法与经验主义相结合的处理策略一直是自然语言处理领域的专家们不断研究和探索的问题,对于词性标注问题当然也不例外。
这类方法的主要特点在于对统计标注结果的筛选,只对那些被认为可疑的标注结果,才采用规则方法进行歧义消解,而不是对所有情况都既使用统计方法又使用规则方法。
基于深度学习的词性标注方法
可以当作序列标注的任务来做,目前深度学习解决序列标注任务常用方法包括LSTM+CRF、BiLSTM+CRF等。
值得一提的是,这一类方法近年来文章非常多,想深入了解这一块的朋友们可以看这里:NLP-progress – GitHub
最后再放一个词性标注任务数据集 – 人民日报1998词性标注数据集
词性标注工具推荐
Jieba
“结巴”中文分词:做最好的 Python 中文分词组件,可以进行词性标注。
SnowNLP
SnowNLP是一个python写的类库,可以方便的处理中文文本内容。
THULAC
THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包,具有中文分词和词性标注功能。
StanfordCoreNLP
斯坦福NLP组的开源,支持python接口。
HanLP
HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。
NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。
SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。
本文转自 公众号 AI小白入门,原文地址
成分句法分析
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
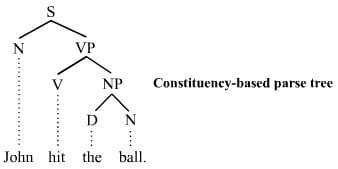
什么是成分句法分析?
维基百科上给的定义如下:The constituency-based parse trees of constituency grammars (= phrase structure grammars) distinguish between terminal and non-terminal nodes. The interior nodes are labeled by non-terminal categories of the grammar, while the leaf nodes are labeled by terminal categories.
句子的组成成分叫句子成分,也叫句法成分。在句子中,词与词之间有一定的组合关系,按照不同的关系,可以把句子分为不同的组成成分。句子成分由词或词组充当。
句法结构分析是指对输入的单词序列(一般为句子)判断其构成是否合乎给定的语法,分析出合乎语法的句子的句法结构。句法结构一般用树状数据结构表示,通常称之为句法分析树(syntactic parsing tree)或简称分析树(parsing tree),而完成这种分析过程的程序模块称为句法结构分析器(syntactic parser),也简称分析器(parser)。
基本任务
句法结构分析的基本任务主要有三个:1.判断输入的字符串是否属于某种语言。2.消除输入句子中的词法和结构等方面的歧义。3.分析输入句子的内部结构,如成分构成、上下文关系等。
如果一个句子有多种结构表示,句法分析器应该分析出该句子最有可能的结构。有时人们也把句法结构分析称为语言或句子识别。
一般构造一个句法分析器需要考虑二部分:语法的形式化表示和词条信息描述问题,分析算法的设计。目前在自然语言处理中广泛使用的是上下文无关文法(CFG)和基于约束的文法(又称合一语法)。
常见方法
句法结构分析可以分为基于规则的分析方法、基于统计的分析方法以及近年来基于深度学习的方法等。
基于规则的分析方法:其基本思路是由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构歧义的消除。
基于统计的分析方法:统计句法分析中目前最成功当属基于概率上下文无关文法(PCFG或SCFG)。该方法采用的模型主要包括词汇化的概率模型(lexicalized probabilistic model)和非词汇化的概率模型(unlexicalized probabilistic model)两种。
基于深度学习的分析方法:近几年深度学习在nlp基础任务取得了不错的效果,也涌现出了不少论文。
短语结构和依存结构关系
短语结构树可以被一一对应地转化成依存关系树,反过来则不然,因为一棵依存关系树可能对应多个短语结构树。转化方法可以通过如下实现:
定义中心词抽取规则,产生中心词表;
根据中心词表,为句法树中每个结点选择中心子结点;
同一层内将非中心子结点的中心词依存到中心子结点的中心词上,下一层的中心词依存到上一层的中心词上,从而得到相应的依存结构。
工具推荐
StanfordCoreNLP
斯坦福的,提供成分句法分析功能。
Berkeley Parser
伯克利大学nlp组开源的工具。提供英文的句法分析功能。
SpaCy
工业级的自然语言处理工具,遗憾的是不支持中文。
参考:
1. 统计自然语言处理
2. 中文信息处理报告-2016
可解释的机器学习
机器学习模型被许多人称为“黑匣子”。这意味着虽然我们可以从中获得准确的预测,但我们无法清楚地解释或识别这些预测背后的逻辑。但是我们如何从模型中提取重要的见解呢?要记住哪些事项以及我们需要实现哪些功能或工具?这些是在提出模型可解释性问题时会想到的重要问题。
在GAN中毕业:从了解生成对抗网络到运行自己的网络
阅读生成性对抗性网络(GAN)研究和评估如何开发然后实现您自己的GAN以生成手写数字
「详解GAN」为什么训练生成对抗网络如此困难!
本文是GAN系列的一部分,我们将研究为什么培训如此难以捉摸。通过这项研究,我们了解了一些驱动许多研究人员方向的基本问题。我们将研究一些分歧,以便我们知道研究可能会去哪里。在研究这些问题之前,让我们快速回顾一下GAN方程。
生成性对抗网络(Gan)的兴起
5年前,GANs开始了深度学习的革命。这场革命产生了一些重大的技术突破。本文将详细介绍 GAN 的历史以及不同模型的效果。