

卷積神經網路 – CNN 已經很強大的,為什麼還需要RNN?
本文會用通俗易懂的方式來解釋 RNN 的獨特價值——處理序列數據。同時還會說明 RNN 的一些缺陷和它的變種演算法。
最後給大家介紹一下 RNN 的實際應用價值和使用場景。
為什麼需要 RNN ?獨特價值是什麼?
卷積神經網路 – CNN 和普通的演算法大部分都是輸入和輸出的一一對應,也就是一個輸入得到一個輸出。不同的輸入之間是沒有聯繫的。

但是在某些場景中,一個輸入就不夠了!
為了填好下面的空,取前面任何一個詞都不合適,我們不但需要知道前面所有的詞,還需要知道詞之間的順序。

這種需要處理「序列數據 – 一串相互依賴的數據流」的場景就需要使用 RNN 來解決了。
典型的集中序列數據:
- 文章里的文字內容
- 語音里的音頻內容
- 股票市場中的價格走勢
- ……
RNN 之所以能夠有效的處理序列數據,主要是基於他的比較特殊的運行原理。下面給大家介紹一下 RNN 的基本運行原理。
RNN 的基本原理
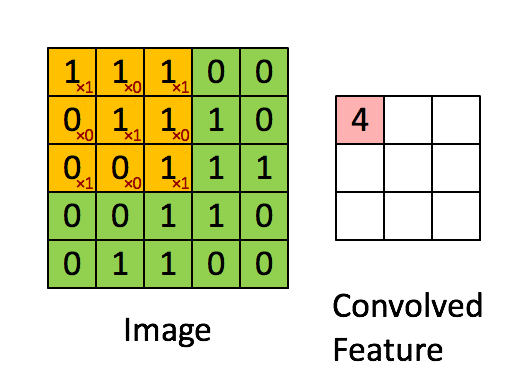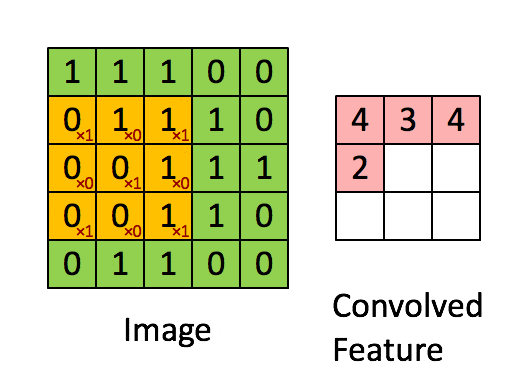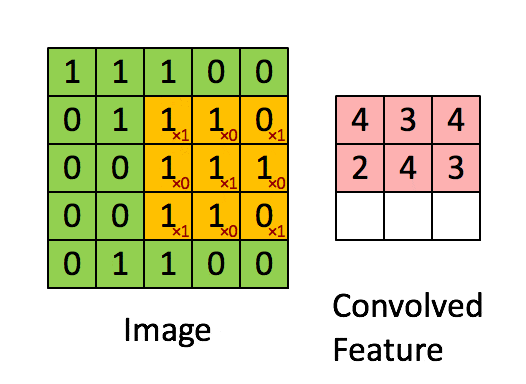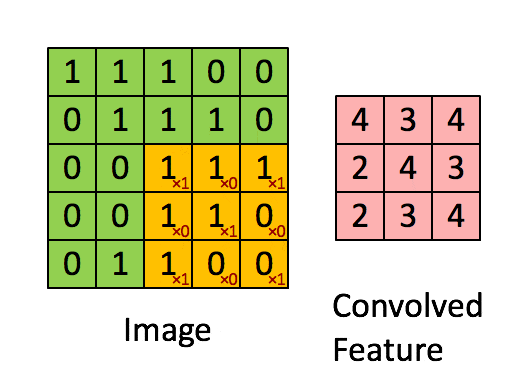
傳統神經網路的結構比較簡單:輸入層 – 隱藏層 – 輸出層。如下圖所示:

RNN 跟傳統神經網路最大的區別在於每次都會將前一次的輸出結果,帶到下一次的隱藏層中,一起訓練。如下圖所示:
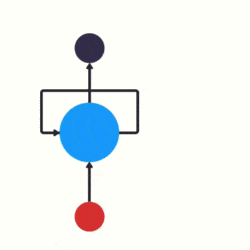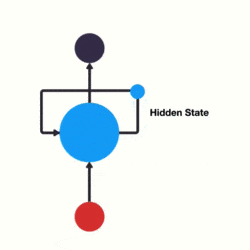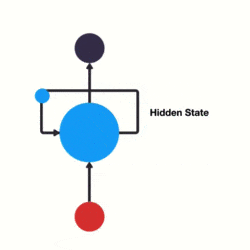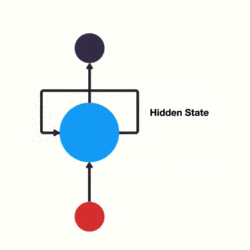
下面用一個具體的案例來看看 RNN 是如何工作的:
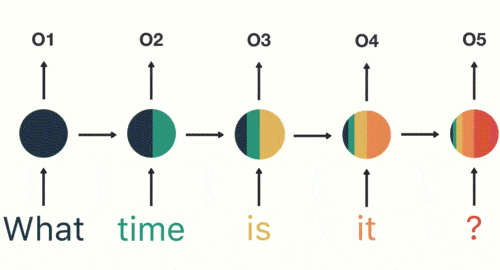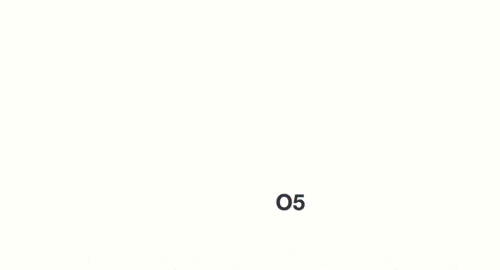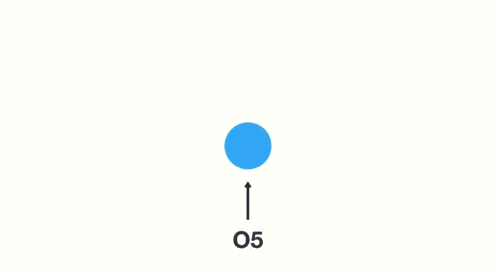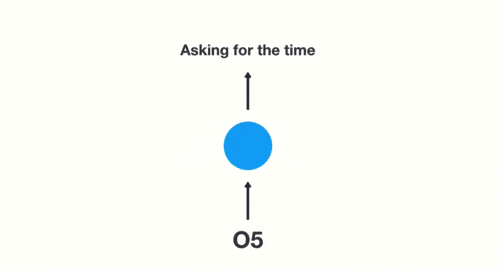
假如需要判斷用戶的說話意圖(問天氣、問時間、設置鬧鐘…),用戶說了一句「what time is it?」我們需要先對這句話進行分詞:

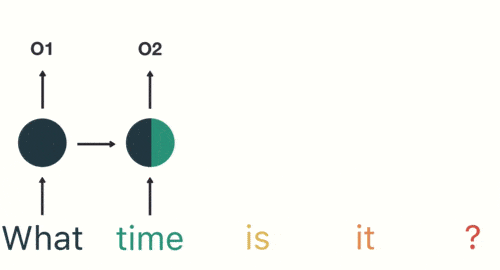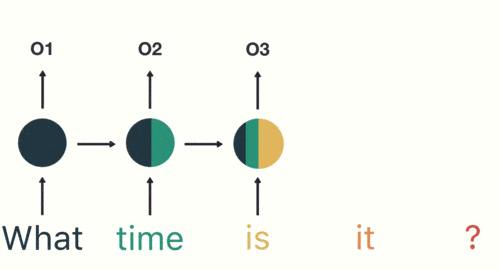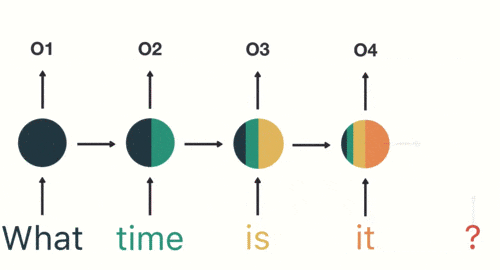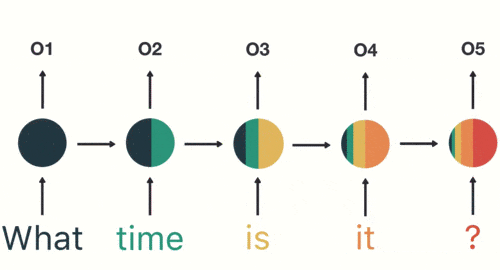
然後按照順序輸入 RNN ,我們先將 「what」作為 RNN 的輸入,得到輸出「01」
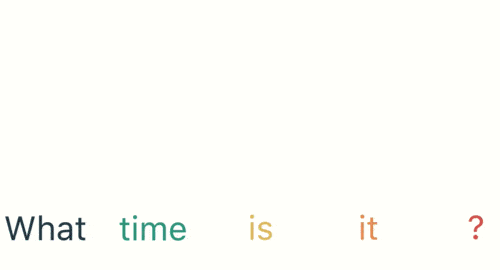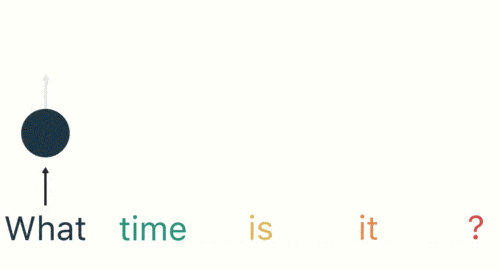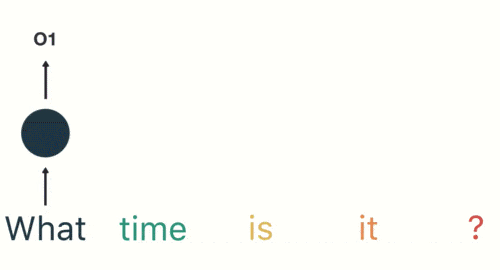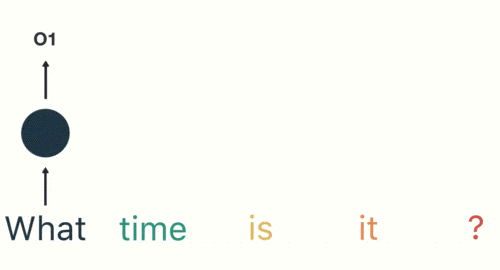
然後,我們按照順序,將「time」輸入到 RNN 網路,得到輸出「02」。
這個過程我們可以看到,輸入 「time」 的時候,前面 「what」 的輸出也產生了影響(隱藏層中有一半是黑色的)。
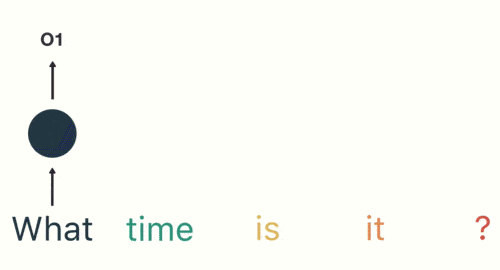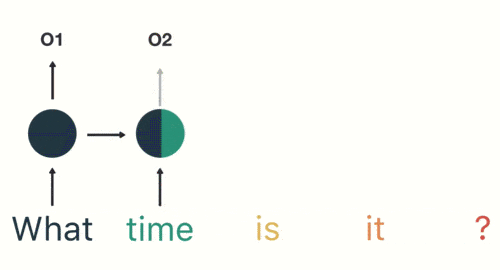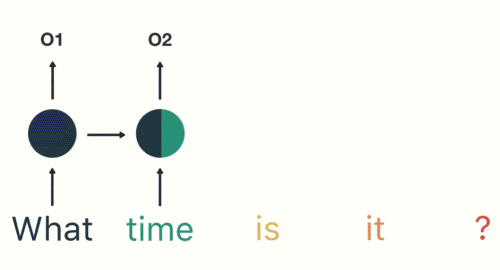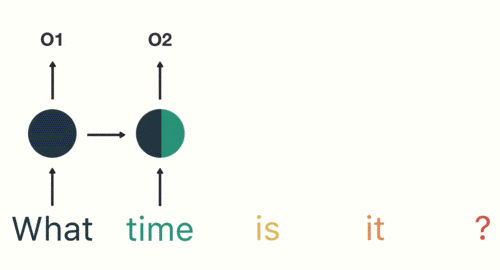
以此類推,前面所有的輸入都對未來的輸出產生了影響,大家可以看到圓形隱藏層中包含了前面所有的顏色。如下圖所示:
當我們判斷意圖的時候,只需要最後一層的輸出「05」,如下圖所示:
RNN 的缺點也比較明顯

通過上面的例子,我們已經發現,短期的記憶影響較大(如橙色區域),但是長期的記憶影響就很小(如黑色和綠色區域),這就是 RNN 存在的短期記憶問題。
- RNN 有短期記憶問題,無法處理很長的輸入序列
- 訓練 RNN 需要投入極大的成本
由於 RNN 的短期記憶問題,後來又出現了基於 RNN 的優化演算法,下面給大家簡單介紹一下。
RNN 的優化演算法
RNN 到 LSTM – 長短期記憶網路
RNN 是一種死板的邏輯,越晚的輸入影響越大,越早的輸入影響越小,且無法改變這個邏輯。
LSTM 做的最大的改變就是打破了這個死板的邏輯,而改用了一套靈活了邏輯——只保留重要的信息。
簡單說就是:抓重點!

舉個例子,我們先快速的閱讀下面這段話:

當我們快速閱讀完之後,可能只會記住下面幾個重點:

LSTM 類似上面的劃重點,他可以保留較長序列數據中的「重要信息」,忽略不重要的信息。這樣就解決了 RNN 短期記憶的問題。
具體技術上的實現原理就不在這裡展開了,感興趣的可以看看 LSTM 的詳細介紹《長短期記憶網路 – LSTM》
從 LSTM 到 GRU
Gated Recurrent Unit – GRU 是 LSTM 的一個變體。他保留了 LSTM 劃重點,遺忘不重要信息的特點,在long-term 傳播的時候也不會被丟失。

GRU 主要是在 LSTM 的模型上做了一些簡化和調整,在訓練數據集比較大的情況下可以節省很多時間。
RNN 的應用和使用場景
只要涉及到序列數據的處理問題,都可以使用到,NLP 就是一個典型的應用場景。

文本生成:類似上面的填空題,給出前後文,然後預測空格中的詞是什麼。
機器翻譯:翻譯工作也是典型的序列問題,詞的順序直接影響了翻譯的結果。
語音識別:根據輸入音頻判斷對應的文字是什麼。
生成圖像描述:類似看圖說話,給一張圖,能夠描述出圖片中的內容。這個往往是 RNN 和 CNN 的結合。

視頻標記:他將視頻分解為圖片,然後用圖像描述來描述圖片內容。
總結
RNN的獨特價值在於:它能有效的處理序列數據。比如:文章內容、語音音頻、股票價格走勢…
之所以他能處理序列數據,是因為在序列中前面的輸入也會影響到後面的輸出,相當於有了「記憶功能」。但是 RNN 存在嚴重的短期記憶問題,長期的數據影響很小(哪怕他是重要的信息)。
於是基於 RNN 出現了 LSTM 和 GRU 等變種演算法。這些變種演算法主要有幾個特點:
- 長期信息可以有效的保留
- 挑選重要信息保留,不重要的信息會選擇「遺忘」
RNN 幾個典型的應用如下:
- 文本生成
- 語音識別
- 機器翻譯
- 生成圖像描述
- 視頻標記
百度百科+維基百科
循環神經網路(Recurrent Neural Network, RNN)是一類以序列(sequence)數據為輸入,在序列的演進方向進行遞歸(recursion)且所有節點(循環單元)按鏈式連接形成閉合迴路的遞歸神經網路(recursive neural network)。
對循環神經網路的研究始於二十世紀80-90年代,並在二十一世紀初發展為重要的深度學習(deep learning)演算法 ,其中雙向循環神經網路(Bidirectional RNN, Bi-RNN)和長短期記憶網路(Long Short-Term Memory networks,LSTM)是常見的的循環神經網路。
循環神經網路具有記憶性、參數共享並且圖靈完備(Turing completeness),因此能以很高的效率對序列的非線性特徵進行學習。循環神經網路在自然語言處理(Natural Language Processing, NLP),例如語音識別、語言建模、機器翻譯等領域有重要應用,也被用於各類時間序列預報或與卷積神經網路(Convoutional Neural Network,CNN)相結合處理計算機視覺問題。
循環神經網路(RNN)是一類神經網路,其中節點之間的連接形成一個有向圖沿著序列。這允許它展示時間序列的時間動態行為。與前饋神經網路不同,RNN可以使用其內部狀態(存儲器)來處理輸入序列。這使它們適用於諸如未分段,連接手寫識別或語音識別等任務。
術語「遞歸神經網路」被不加選擇地用於指代具有類似一般結構的兩大類網路,其中一個是有限脈衝而另一個是無限脈衝。兩類網路都表現出時間動態行為。有限脈衝遞歸網路是一種有向無環圖,可以展開並用嚴格的前饋神經網路代替,而無限脈衝循環網路是一種無法展開的有向循環圖。
有限脈衝和無限脈衝周期性網路都可以具有額外的存儲狀態,並且存儲可以由神經網路直接控制。如果存儲包含時間延遲或具有反饋循環,則存儲也可以由另一個網路或圖表替換。這種受控狀態稱為門控狀態或門控存儲器,並且是長短期存儲器網路(LSTM)和門控循環單元的一部分。



















 。 它們直接對性能目標
。 它們直接對性能目標  進行梯度下降進行優化,或者間接地,對性能目標的局部近似函數進行優化。優化基本都是基於 同策略 的,也就是說每一步更新只會用最新的策略執行時採集到的數據。策略優化通常還包括學習出
進行梯度下降進行優化,或者間接地,對性能目標的局部近似函數進行優化。優化基本都是基於 同策略 的,也就是說每一步更新只會用最新的策略執行時採集到的數據。策略優化通常還包括學習出  ,作為
,作為  的近似,該函數用於確定如何更新策略。
的近似,該函數用於確定如何更新策略。 的近似函數:
的近似函數:  。它們通常使用基於
。它們通常使用基於  and
and  之間的聯繫得到的。智能體的行動由下面的式子給出:
之間的聯繫得到的。智能體的行動由下面的式子給出: