

近年来,我们目睹了无数CNN的诞生。这些网络已经变得如此之深以至于使整个模型可视化变得非常困难。我们停止跟踪它们并将它们视为黑盒模型。
好吧,也许你没有。但如果你还有愧疚,那么,你来对地方了!本文是10种常见 CNN架构的可视化,由您真正亲自挑选。这些插图提供了整个模型的更紧凑的视图,无需向下滚动几次只是为了看到softmax层。除了这些图像之外,我还有一些关于它们如何随时间演变的注释 – 从5到50个卷积层,从普通的卷积层到模块,从2-3个塔到32个塔,从7到7到5 ⨉5-但稍后会更多。
通过’common’,我指的是那些预训练权重通常由深度学习库(如TensorFlow,Keras和PyTorch)共享供用户使用的模型,以及通常在课堂上讲授的模型。其中一些模型在ImageNet大规模视觉识别挑战赛(ILSVRC)等竞赛中取得了成功。
写这篇文章的动机是没有很多博客和文章有这些紧凑的可视化(如果你知道任何,请与我分享)。所以我决定写一个供我们参考。为此,我已经阅读了论文和代码(主要来自TensorFlow和Keras)来提出这些视频。
在这里,我想补充一点,我们在野外看到的众多CNN架构是许多因素的结果 – 改进的计算机硬件,ImageNet竞争,解决特定任务,新想法等等。谷歌研究员Christian Szegedy曾经提到过这一点
“这一进步不仅仅是更强大的硬件,更大的数据集和更大的模型的结果,而且主要是新思想,算法和改进的网络架构的结果。”(Szegedy等,2014)
现在让我们继续讨论这些野兽并观察网络架构如何随着时间的推移而改进!
关于可视化的
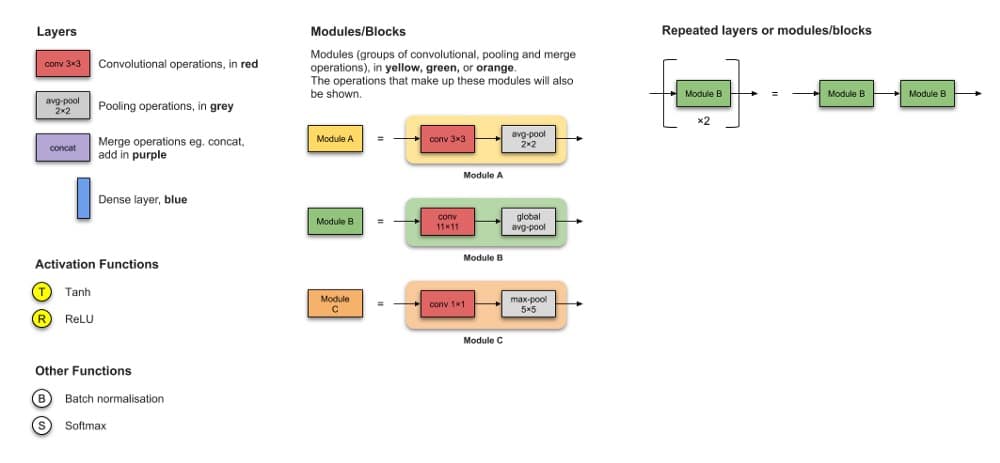
注意事项请注意,我已经排除了卷积过滤器的数量,填充,步幅,丢失以及插图中的展平操作等信息。
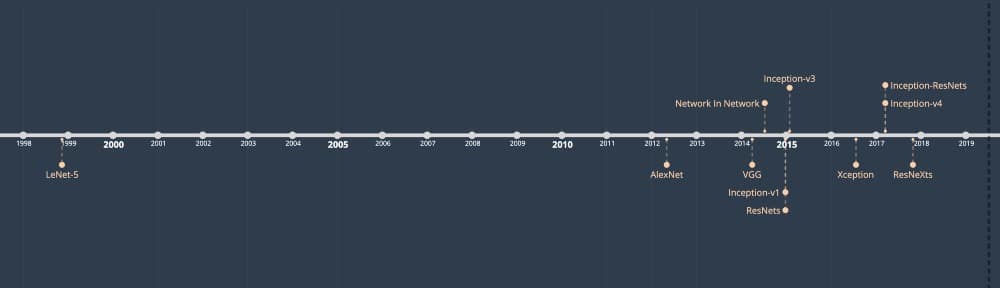
内容(按出版年份排序)
- LeNet-5
- AlexNet
- VGG-16
- Inception-V1
- Inception-V3
- RESNET-50
- Xception
- Inception-V4
- Inception-ResNets
- ResNeXt-50
传说
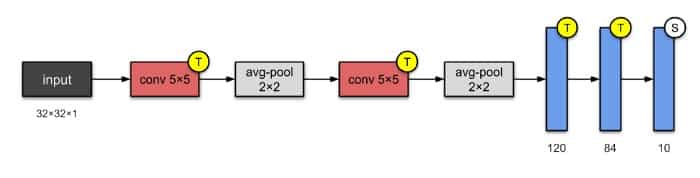
1. LeNet-5(1998)
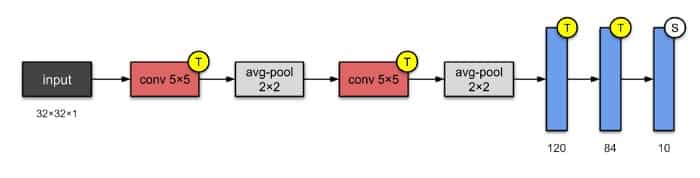
LeNet-5是最简单的架构之一。它具有2个卷积层和3个完全连接层(因此“5” – 神经网络的名称从它们具有的卷积和完全连接层的数量中得出是非常常见的)。我们现在知道的平均汇集层被称为子采样层,它具有可训练的权重(这不是当前设计CNN的当前做法)。该架构有大约60,000个参数。
⭐️什么是小说?
该体系结构已成为标准的“模板”:堆叠卷积和池化层,以及使用一个或多个完全连接的层结束网络。
📝Publication
- 论文:基于梯度的学习应用于文献识别
- 作者:Yann LeCun,LéonBottou,Yoshua Bengio和Patrick Haffner
- 发表于:IEEE会议论文集(1998)
2. AlexNet(2012)

凭借60M参数,AlexNet有8层–5个卷积和3个完全连接。AlexNet刚刚在LeNet-5上堆叠了几层。在发表时,作者指出他们的架构是“迄今为止ImageNet子集中最大的卷积神经网络之一”。
⭐️什么是小说?
他们是第一个将整流线性单元(ReLUs)作为激活功能实现的。
2. CNN中的重叠池。
📝Publication
- 论文:使用深度卷积神经网络的ImageNet分类
- 作者:Alex Krizhevsky,Ilya Sutskever,Geoffrey Hinton。加拿大多伦多大学。
- 发表于:NeurIPS 2012
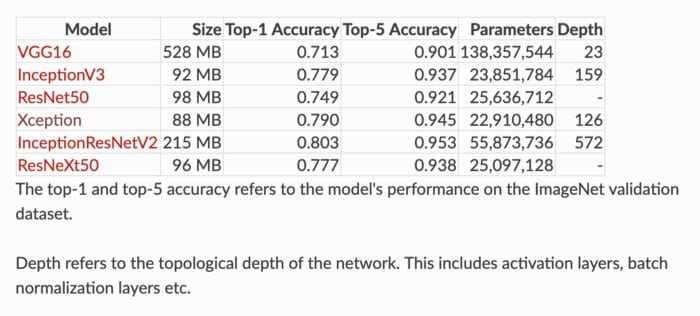
3. VGG-16(2014年)

到现在为止,你已经注意到CNN开始越来越深。这是因为提高深度神经网络性能的最直接方法是增加它们的大小(Szegedy等人)。视觉几何组织(VGG)的人们发明了VGG-16,它有13个卷积层和3个完全连接层,带有AlexNet的ReLU传统。同样,这个网络只是将更多层叠加到AlexNet上。它由138M 参数组成,占用大约500MB的存储空间😱。他们还设计了更深层的变体VGG-19。
⭐️什么是小说?
- 正如他们的摘要中所提到的,本文的贡献是设计更深层次的网络(大约是AlexNet的两倍)。
📝Publication
- 论文:用于大规模图像识别的非常深的卷积网络
- 作者:Karen Simonyan,Andrew Zisserman。英国牛津大学。
- arXiv preprint,2014
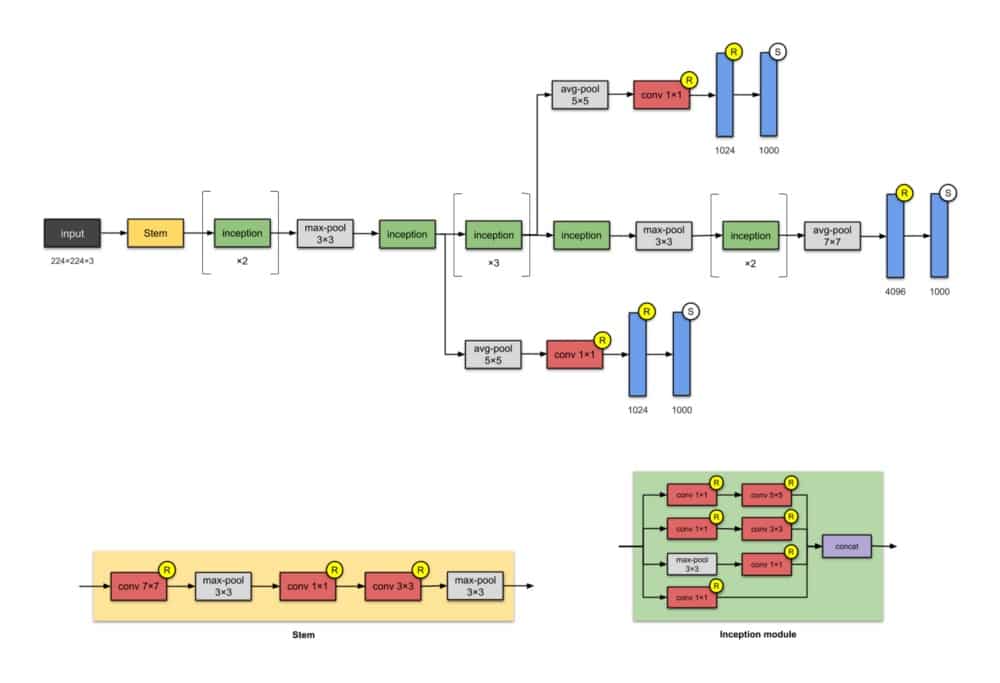
4.Inception-v1(2014)
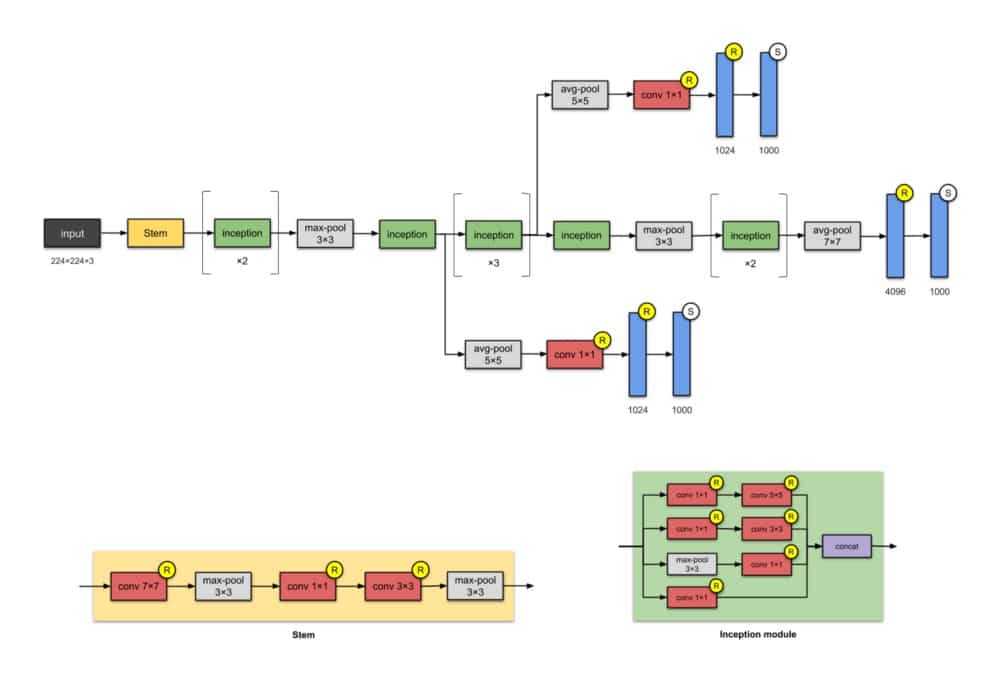
这种具有5M参数的22层架构称为Inception-v1。在这里,网络网络(见附录)方法被大量使用,如本文所述。这是通过’初始模块’完成的。Inception模块的体系结构设计是近似稀疏结构研究的产物(阅读论文了解更多!)。每个模块提出3个想法:
- 具有不同滤波器的并行卷积塔,随后是串联,以1×1,3×3和5×5捕获不同的特征,从而“聚类”它们。这个想法是由Arora等人提出的。在本文中,Provable学习了一些深层表示,建议采用逐层构造,其中人们应该分析最后一层的相关统计数据,并将它们聚类成具有高相关性的单元组。
- 1×1卷积用于降低维数以消除计算瓶颈。
- 1×1卷积在卷积内添加非线性(基于Network In Network论文)。
- 作者还引入了两个辅助分类器,以鼓励在分类器的较低阶段进行区分,增加传播回来的梯度信号,并提供额外的正则化。所述辅助网络(被连接到辅助分类分支)在推理时间将被丢弃。
值得注意的是,“这种架构的主要标志是提高了网络内部计算资源的利用率。”
注意:
模块的名称(Stem和Inception)在其更高版本(即Inception-v4和Inception-ResNets)之前未用于此版本的Inception。我在这里添加了它们以便于比较。
⭐️什么是小说?
- 使用密集模块/块构建网络。我们不是堆叠卷积层,而是堆叠模块或块,其中是卷积层。因此名称为Inception(参考由Leonardo DiCaprio主演的2010年科幻电影Inception)。
📝Publication
- 论文:更加深入了解卷积
- 作者:Christian Szegedy,Wei Liu,Yangqing Jia,Pierre Sermanet,Scott Reed,Dragomir Anguelov,Dumitru Erhan,Vincent Vanhoucke,Andrew Rabinovich。谷歌,密歇根大学,北卡罗来纳大学
- 发表于:2015 IEEE计算机视觉和模式识别会议(CVPR)
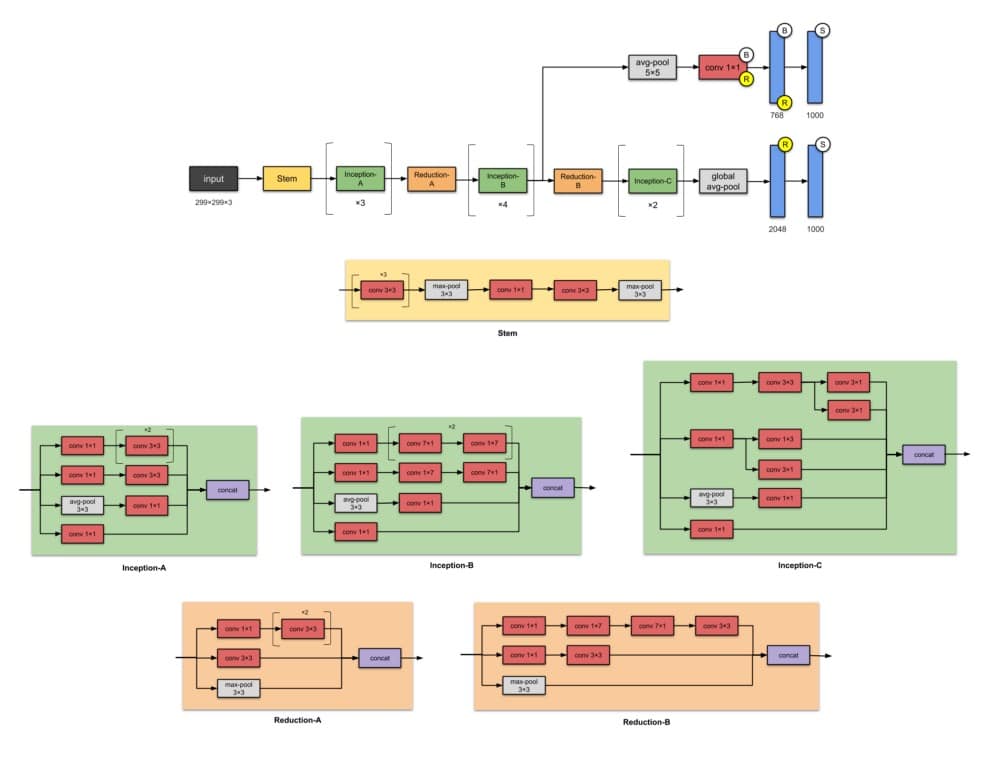
5.Inception-v3(2015)
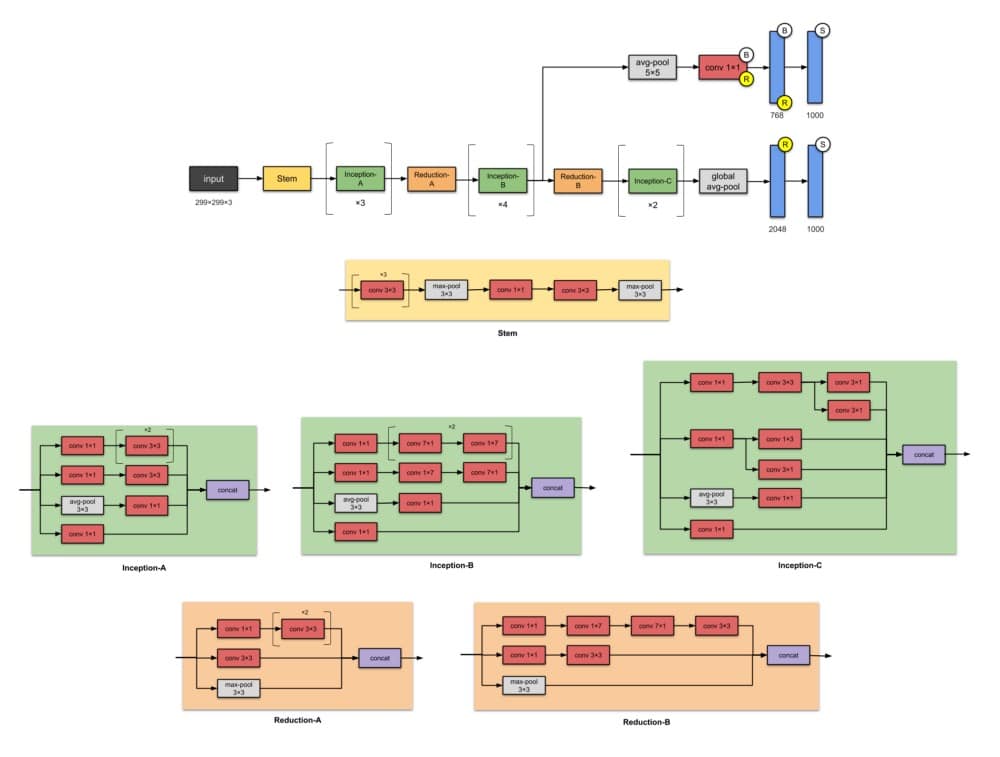
Inception-v3是Inception-v1的后继产品,具有24M参数。等待Inception-v2的位置?不要担心它 – 它是v3的早期原型,因此它与v3非常相似但不常用。当作者推出Inception-v2时,他们在其上进行了许多实验,并记录了一些成功的调整。Inception-v3是包含这些调整的网络(调整优化器,丢失功能并向辅助网络中的辅助层添加批量标准化)。
Inception-v2和Inception-v3的动机是避免表征性瓶颈(这意味着大幅减少下一层的输入维度),并通过使用因子分解方法进行更有效的计算。
注意:
模块的名称(Stem,Inception-A,Inception-B等)直到其更高版本即Inception-v4和Inception-ResNets才用于此版本的Inception。我在这里添加了它们以便于比较。
⭐️什么是小说?
- 首批使用批量标准化的设计师(为简单起见,未在上图中反映)。
✨从以前的版本Inception-v1改进了什么?
- 将n × n卷积分解为非对称卷积:1× n和n ×1 卷积
- 分解5×5卷积到两个3×3卷积运算
- 将7×7替换为一系列3×3圈
📝Publication
- 论文:重新思考计算机视觉的初始架构
- 作者:Christian Szegedy,Vincent Vanhoucke,Sergey Ioffe,Jonathon Shlens,Zbigniew Wojna。谷歌,伦敦大学学院
- 发表于:2016 IEEE计算机视觉和模式识别会议(CVPR)
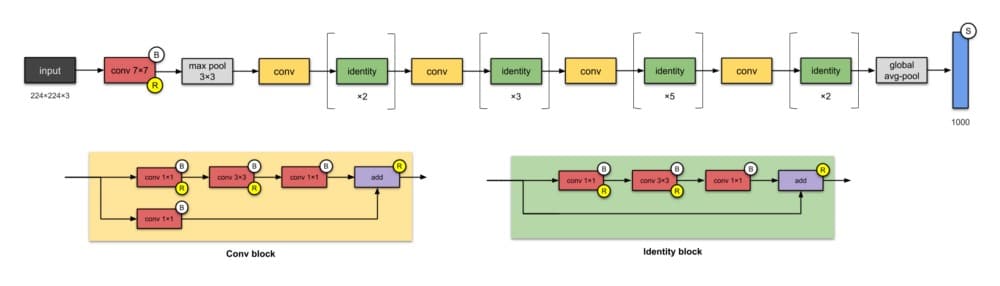
6. ResNet-50(2015)
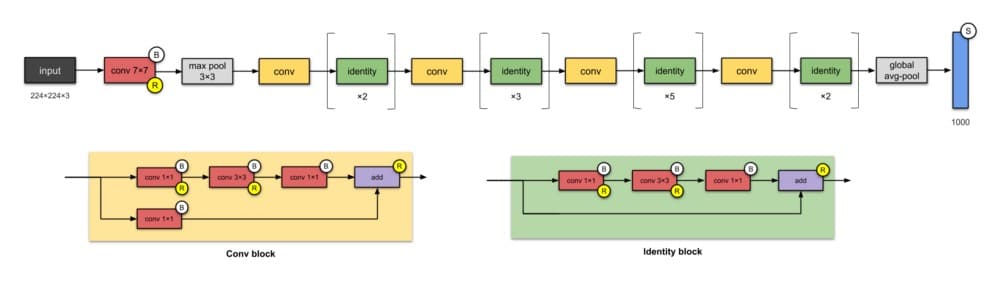
是的,这是您在文章顶部看到的问题的答案。
从过去的几个CNN中,我们看到的只是设计中越来越多的层,并且实现了更好的性能。但是“随着网络深度的增加,准确度变得饱和(这可能不足为奇),然后迅速降级。”微软研究院的人们用ResNet解决了这个问题 – 使用跳过连接(又称快捷连接,残差),同时构建更深层次的模型。
ResNet是批量标准化的早期采用者之一(由Ioffe和Szegedy撰写的批量标准文件于2015年提交给ICML)。上面显示的是ResNet-50,具有26M参数。
ResNets的基本构建块是conv和identity块。因为它们看起来很相似,你可能会像这样简化ResNet-50(不要引用我这个!):
⭐️什么是小说?
- 推广跳过连接(他们不是第一个使用跳过连接)。
- 设计更深的CNN(最多152层),而不会影响模型的泛化能力
- 首先使用批量标准化。
📝Publication
- 论文:图像识别的深度残留学习
- 作者:何开明,张翔宇,任少卿,孙建。微软
- 发表于:2016 IEEE计算机视觉和模式识别会议(CVPR)
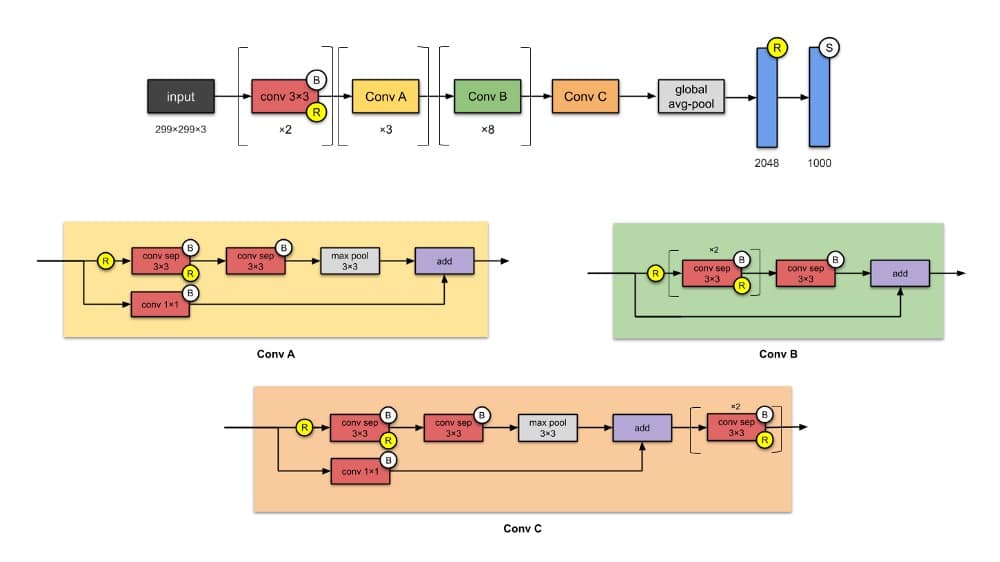
7. Xception(2016)
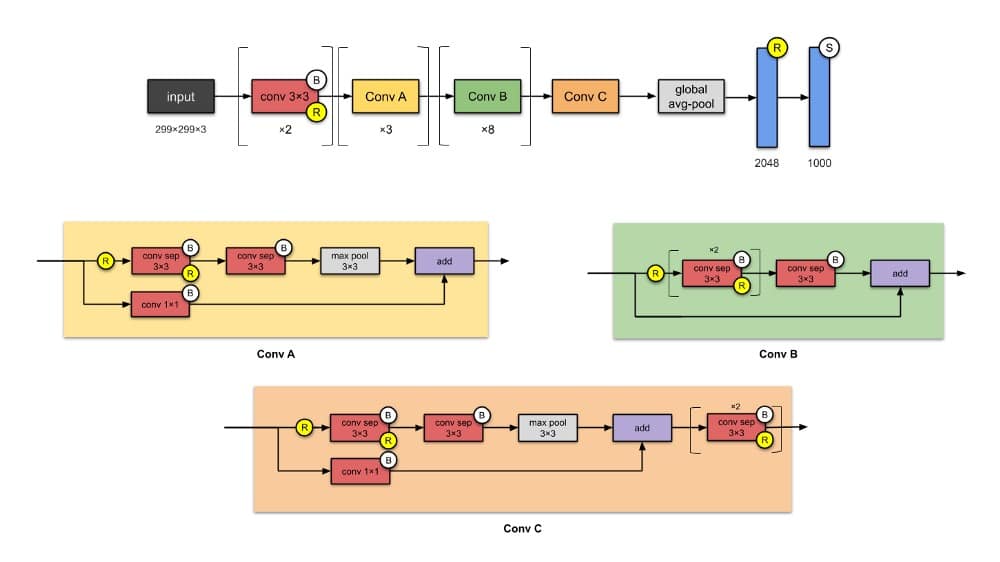
Xception是Inception的改编版,其中Inception模块已被深度可分离卷积替换。它与Inception-v1(23M)的参数数量大致相同。
Xception将Inception假设引入eXtreme(因此得名)。什么是初始假设?谢天谢地,本文中明确提到了这一点(感谢弗朗索瓦!)。
- 首先,通过1×1卷积捕获跨通道(或交叉特征映射)相关性。
- 因此,通过常规的3×3或5×5卷积捕获每个通道内的空间相关性。
将这个想法推向极端意味着对每个通道执行1×1 ,然后对每个输出执行3×3 。这与使用深度可分离卷积替换初始模块相同。
⭐️什么是小说?
- 完全基于深度可分离卷积层引入CNN。
📝Publication
- 论文:Xception:深度学习与深度可分离的卷积
- 作者:FrançoisChollet。谷歌。
- 发表于:2017年IEEE计算机视觉和模式识别大会(CVPR)
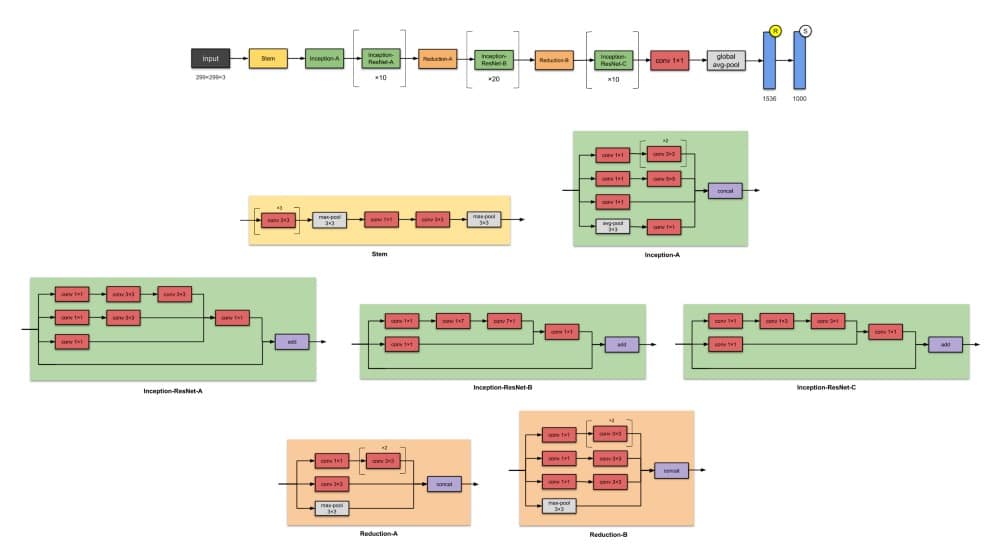
8.Inception-v4(2016)
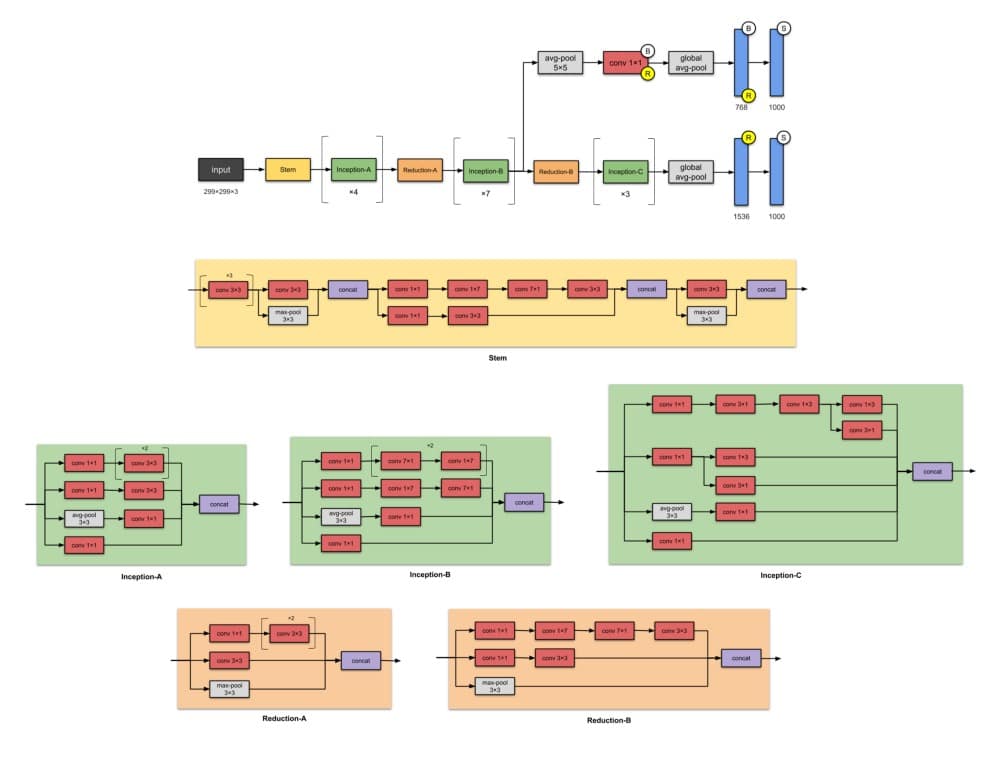
来自Google的人们再次使用Inception- v4,43M参数进行攻击。同样,这是Inception-v3的改进。主要区别在于Stem组和Inception-C模块中的一些小变化。作者还“为每个网格大小的Inception块做出了统一的选择。”他们还提到“剩余连接可以显着提高训练速度”。
总而言之,请注意,由于模型大小的增加,Inception-v4的效果更好。
✨从以前的版本Inception-v3开始有哪些改进?
- 更改Stem模块。
- 添加更多Inception模块。
- 统一选择Inception-v3模块,意味着为每个模块使用相同数量的过滤器。
📝Publication
- 论文:Inception-v4,Inception-ResNet以及残余连接对学习的影响
- 作者:Christian Szegedy,Sergey Ioffe,Vincent Vanhoucke,Alex Alemi。谷歌。
- 发表于:第三十一届AAAI人工智能会议论文集
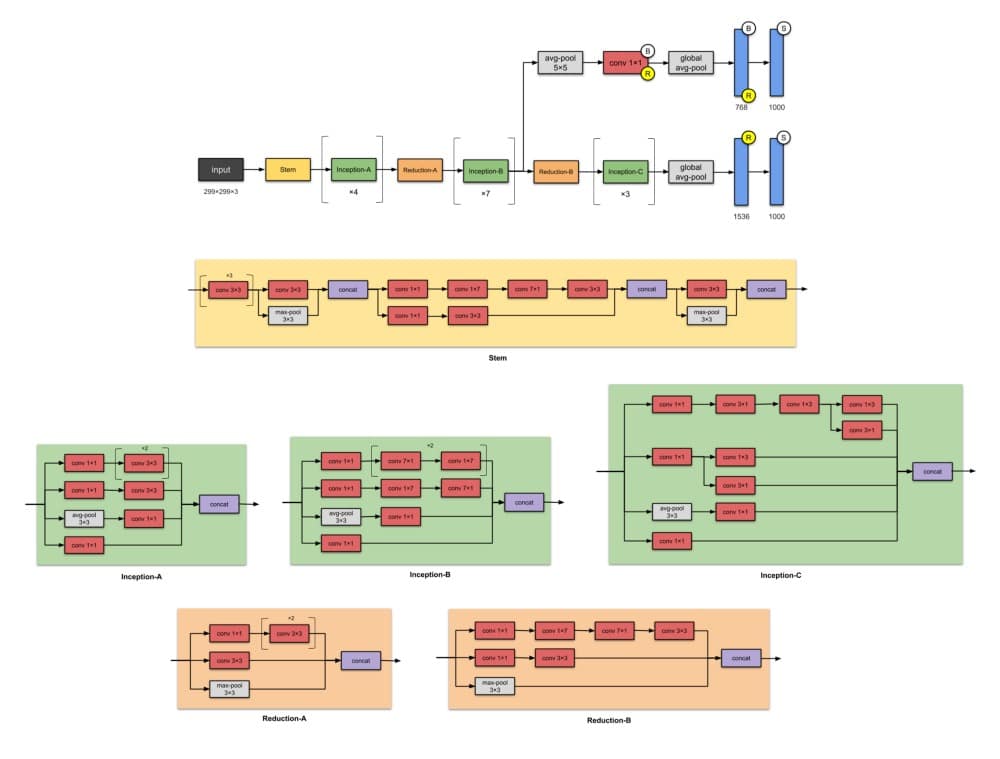
9. Inception-ResNet-V2(2016)
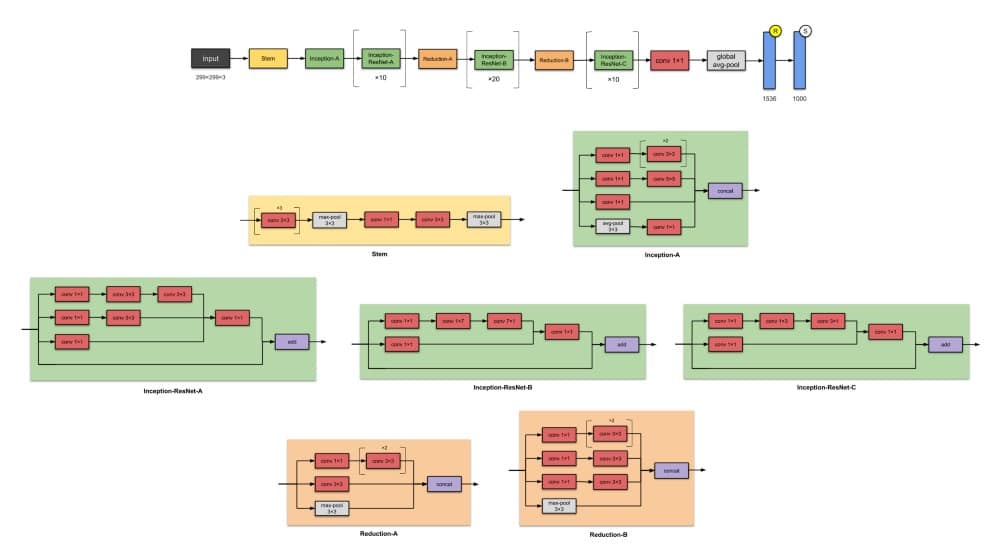
在与Inception-v4相同的论文中,同一作者还介绍了Inception-ResNets – 一系列Inception-ResNet-v1和Inception-ResNet-v2。该系列的后一个成员有56M参数。
✨从以前的版本Inception-v3开始有哪些改进?
- 将Inception模块转换为Residual Inception块。
- 添加更多Inception模块。
- 在Stem模块之后添加新类型的Inception模块(Inception-A)。
📝Publication
- 论文:Inception-v4,Inception-ResNet以及残余连接对学习的影响
- 作者:Christian Szegedy,Sergey Ioffe,Vincent Vanhoucke,Alex Alemi。谷歌
- 发表于:第三十一届AAAI人工智能会议论文集
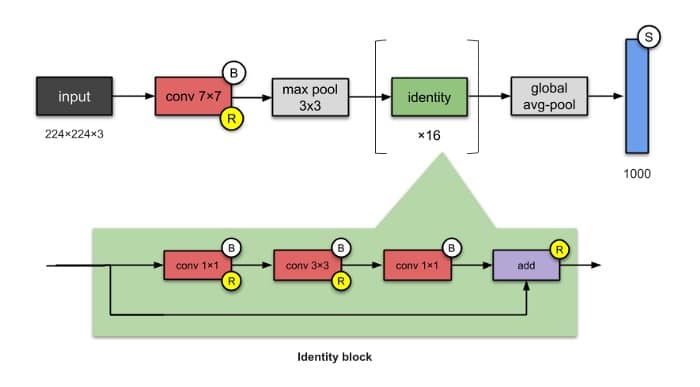
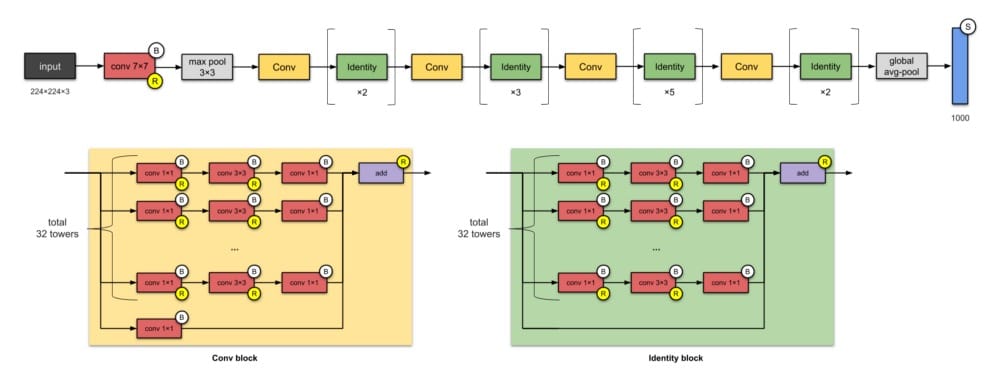
10. ResNeXt-50(2017)
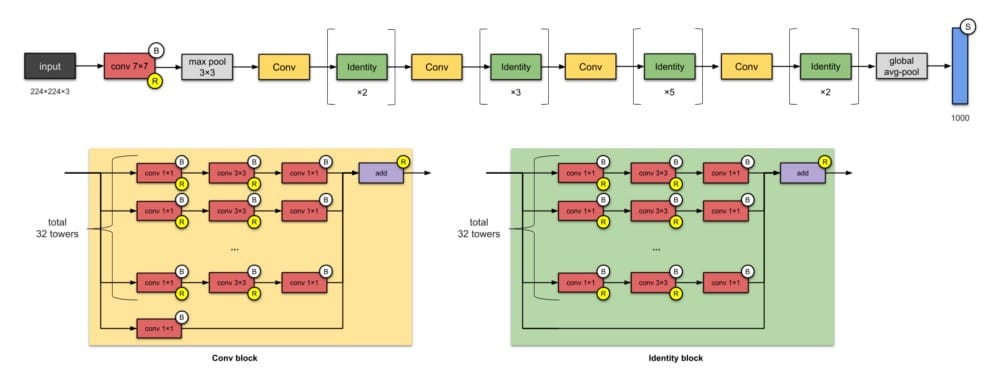
如果您正在考虑ResNets,是的,它们是相关的。ResNeXt-50有25M参数(ResNet-50有25.5M)。ResNeXts的不同之处在于在每个模块中添加了并行塔/分支/路径,如上面“总共32个塔”所示。
⭐️什么是小说?
- 扩大模块中并行塔的数量(“基数”)(我的意思是这已经被Inception网络探索过了……)
📝Publication
- 论文:深度神经网络的聚合残差变换
- 作者:Saining Xie,Ross Girshick,PiotrDollár,Zhuowen Tu,Kaiming He。加州大学圣地亚哥分校,Facebook Research
- 发表于:2017年IEEE计算机视觉和模式识别大会(CVPR)
附录:网络网络(2014年)
回想一下,在卷积中,像素的值是滤波器和当前滑动窗口中权重的线性组合。作者提出,不是这种线性组合,而是让我们拥有一个带有1个隐藏层的迷你神经网络。这就是他们创造的Mlpconv。所以我们在这里处理的是(卷积神经网络)中的(简单的1隐藏层)网络。
Mlpconv的这种想法被比作1×1卷积,并成为Inception架构的主要特征。
⭐️什么是小说?
- MLP卷积层,1×1卷积
- 全局平均合并(取每个特征图的平均值,并将得到的矢量输入softmax图层)
📝Publication
- 论文:网络中的网络
- 作者:林敏,陈强,水水燕。新加坡国立大学
- arXiv preprint,2013
让我们再次在这里显示它们以便于参考:
LeNet-5
AlexNet

VGG-16

Inception-V1
Inception-V3
Inception-V4
Inception-RESNET-V2
Xception
RESNET-50
ResNeXt-50
神经网络可视化的资源
以下是一些可视化您的神经网络的资源:
- Netron 😍
- TensorFlow的TensorBoard API
plot_modelKeras的APIpytorchviz包
类似的文章
CNN架构:LeNet,AlexNet,VGG,GoogLeNet,ResNet等……
参考
我使用了上述提出架构的论文供参考。除此之外,以下是我在本文中使用的其他一些内容:
https://github.com/tensorflow/models/tree/master/research/slim/nets(github.com/tensorflow)
从 Keras 团队实施深度学习模型(github.com/keras-team)
卷积神经网络架构讲义:从LeNet到ResNet(slazebni.cs.illinois.edu)
评论:NIN – 网络网络(图像分类)(towardsdatascience.com)
您在可视化中发现了任何错误吗?还有什么你认为我应该包括在内的吗?在下面给我发表评论!
本文转自towardsdatascience,原文地址


Comments