

基于最近的一些对话,我意识到文本预处理是一个被严重忽视的话题。我接触过的一些人提到他们的NLP应用程序的结果不一致只是意识到他们没有预处理他们的文本或者他们的项目使用了错误的文本预处理。
考虑到这一点,我想到了解文本预处理的真正含义,文本预处理的不同方法,以及估计可能需要多少预处理的方法。对于那些感兴趣的人,我也为你做了一些文本预处理代码片段。现在,让我们开始吧!
什么是文本预处理?
预处理文本只是意味着将文本转换为可预测 且可分析的任务形式。这里的任务是方法和域的组合。例如,使用来自推文(域)的tfidf(方法)提取顶级关键字是任务的示例。
任务=方法+域
一项任务的理想预处理可能成为另一项任务中最糟糕的噩梦。请注意:文本预处理不能直接从任务转移到任务。
让我们举一个非常简单的例子,假设你试图发现新闻数据集中常用的单词。如果您的预处理步骤涉及删除停用词,因为其他任务使用了它,那么您可能会错过一些常用词,因为您已经将其删除了。实际上,这不是一种通用的方法。
文本预处理技术的类型
有不同的方法来预处理您的文本。以下是您应该了解的一些方法,我将尝试强调每种方法的重要性。
统一为小写字母
降低所有文本数据,尽管通常被忽略,但它是文本预处理中最简单,最有效的形式之一。它适用于大多数文本挖掘和NLP问题,并且可以在数据集不是很大并且显着有助于预期输出的一致性的情况下提供帮助。
最近,我的一位博客读者为相似性查找训练了一个嵌入模型的单词。他发现输入资本化的不同变化(例如“加拿大”与“加拿大”)给了他不同类型的输出或根本没有输出。这可能是因为数据集中出现了“加拿大”这个词的混合情况,并且没有足够的证据证明神经网络能够有效地学习不常见版本的权重。当您的数据集相当小时,这种类型的问题肯定会发生,而小写是处理稀疏性问题的好方法。
下面是小写如何解决稀疏性问题的示例,其中具有不同情况的相同单词映射到相同的小写形式:

小写非常有用的另一个例子是搜索。想象一下,您正在寻找包含“美国”的文档。然而,没有结果显示,因为“美国”被索引为“美国”。现在,我们应该责怪谁?设置界面的UI设计者或设置搜索索引的工程师?
虽然小写应该是标准做法,但我也有保留大写的重要性。例如,在预测源代码文件的编程语言时。SystemJava中的单词与systempython中的单词完全不同。降低两者使它们相同,导致分类器失去重要的预测特征。虽然小写通常很有用,但它可能不适用于所有任务。
词干提取
词干化是将词语中的变形(例如麻烦,烦恼)减少到其根形式(例如麻烦)的过程。在这种情况下,“根”可能不是真正的根词,而只是原始词的规范形式。
词干使用粗略的启发式过程来切断单词的末尾,以期正确地将单词转换为其根形式。因此,“麻烦”,“困扰”和“麻烦”这些词实际上可能会被转换为,troubl而不是trouble因为两端被切断(呃,多么粗糙!)。
词干有不同的算法。最常见的算法,也称为对英语有经验效果,是Porters算法。以下是Porter Stemmer采取行动的一个例子:

词干对于处理稀疏性问题以及标准化词汇量非常有用。我在搜索应用程序中取得了成功。这个想法是,如果你说你正在寻找“深度学习课程”,你也想要提出提及“深度学习课程 ”以及“深度学习课程”的文件,尽管后者听起来不对。但是你得到了我们的目标。您希望匹配单词的所有变体以显示最相关的文档。
然而,在我之前的大多数文本分类工作中,仅仅略微提高了分类准确性,而不是使用更好的工程特征和文本丰富方法,例如使用单词嵌入。
词形还原
表面上的词形还原与词干非常相似,其目标是删除变形并将单词映射到其根形式。唯一的区别是,词形还原试图以正确的方式去做。它不只是切断了它,它实际上将单词转换为实际的根。例如,“更好”这个词会映射到“好”。它可以使用诸如WordNet的字典来进行映射或一些基于规则的特殊方法。以下是使用基于WordNet的方法实现的词形还原的示例:

根据我的经验,词形简化与搜索和文本分类目的相比没有明显的优势。实际上,根据您选择的算法,与使用非常基本的词干分析器相比,它可能要慢得多,您可能必须知道相关单词的词性才能得到正确的引理。本文发现,词形还原对神经结构文本分类的准确性没有显着影响。
我会亲自使用词形还原。额外的开销可能是也可能不值得。但您可以随时尝试查看它对您的效果指标的影响。
删除停用词
停用词是一种语言中常用的词汇。英语中的停用词的例子是“a”,“the”,“is”,“are”等。使用停用词背后的直觉是,通过从文本中删除低信息词,我们可以专注于重要词而不是。
例如,在搜索系统的上下文中,如果您的搜索查询是“什么是文本预处理?”,您希望搜索系统专注于表面文档,这些text preprocessing文档可以讨论谈论的文档what is。这可以通过阻止停止词列表中的所有单词进行分析来完成。停用词通常应用于搜索系统,文本分类应用程序,主题建模,主题提取等。
根据我的经验,停止删除单词虽然在搜索和主题提取系统中有效,但在分类系统中显示为非关键。但是,它确实有助于减少所考虑的功能数量,这有助于保持模型的大小。
以下是停止删除单词的示例。所有停用词都替换为虚拟角色,W:

停止单词列表可以来自预先建立的集合,也可以为您的域创建自定义单词列表。某些库(例如sklearn)允许您删除X%文档中出现的单词,这也可以为您提供单词删除效果。
规范化
一个被高度忽视的预处理步骤是文本规范化。文本规范化是将文本转换为规范(标准)形式的过程。例如,“gooood”和“gud”这个词可以转换为“good”,即其规范形式。另一个例子是将近似相同的单词(例如“停用词”,“停止词”和“停止词”)映射到“停用词”。
文本规范化对于嘈杂的文本非常重要,例如社交媒体评论,短信和对博客文章的评论,其中缩写,拼写错误和使用词汇外词(oov)很普遍。本文通过使用推文的文本归一化策略,他们能够将情绪分类准确度提高约4%。
这是标准化之前和之后的单词示例:
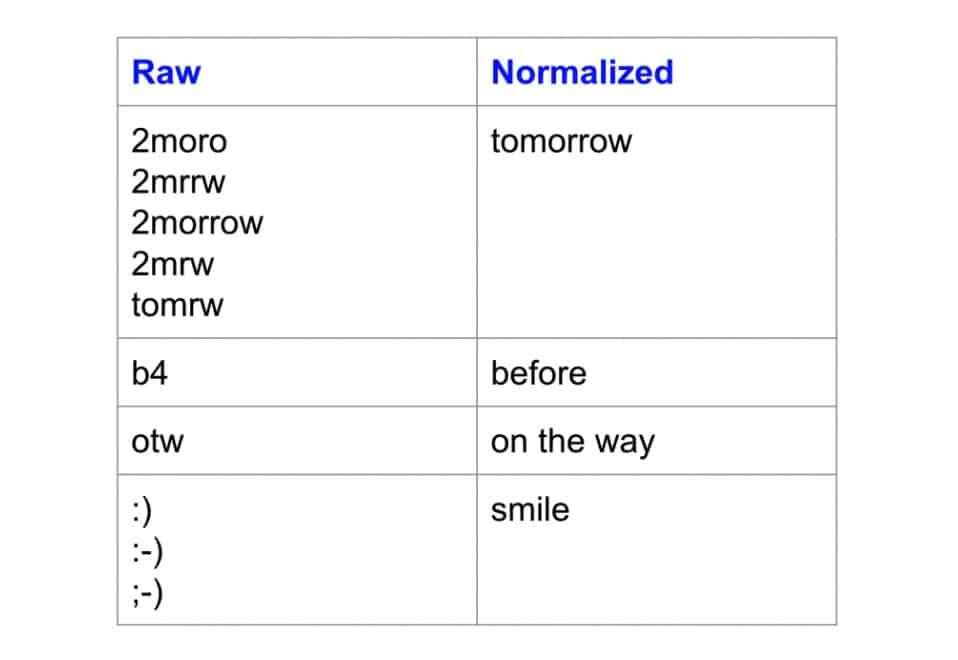
请注意变体如何映射到相同的规范形式。
根据我的经验,文本规范化甚至可以有效地分析高度非结构化的临床文本,其中医生以非标准方式记笔记。我还发现它对于主题提取很有用,其中近似同义词和拼写差异是常见的(例如主题建模,主题建模,主题建模,主题建模)。
不幸的是,与词干和词形还原不同,没有一种标准化的文本化方法。它通常取决于任务。例如,您将临床文本标准化的方式可能与您对短信文本消息的标准化方式有所不同。
文本规范化的一些常用方法包括字典映射(最简单),统计机器翻译(SMT)和基于拼写校正的方法。这篇有趣的文章比较了使用基于字典的方法和SMT方法来规范化文本消息。
噪音消除
噪声去除有关删除characters digits,并pieces of text可以与您的文本分析干扰。噪声消除是最基本的文本预处理步骤之一。它也是高度依赖域的。
例如,在推文中,噪声可能是除了主题标签之外的所有特殊字符,因为它表示可以表征推文的概念。噪音的问题在于它会产生下游任务中不一致的结果。我们来看下面的例子:
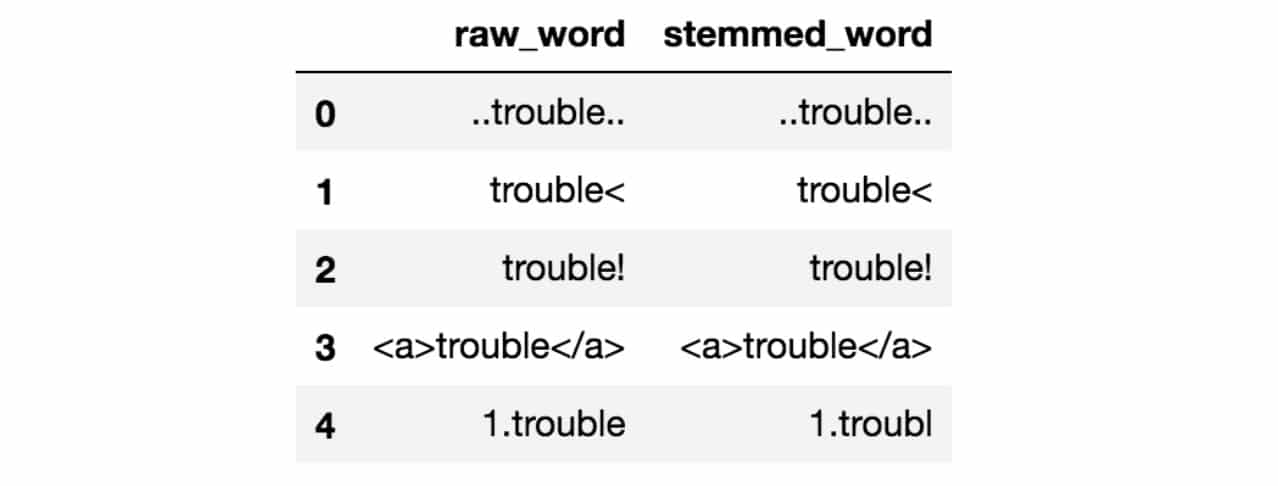
请注意,上面的所有原始单词都有一些周围的噪音。如果你干掉这些词,你会发现词干结果看起来不太漂亮。他们都没有正确的词干。但是,通过本笔记本中的一些清洁,结果现在看起来好多了:
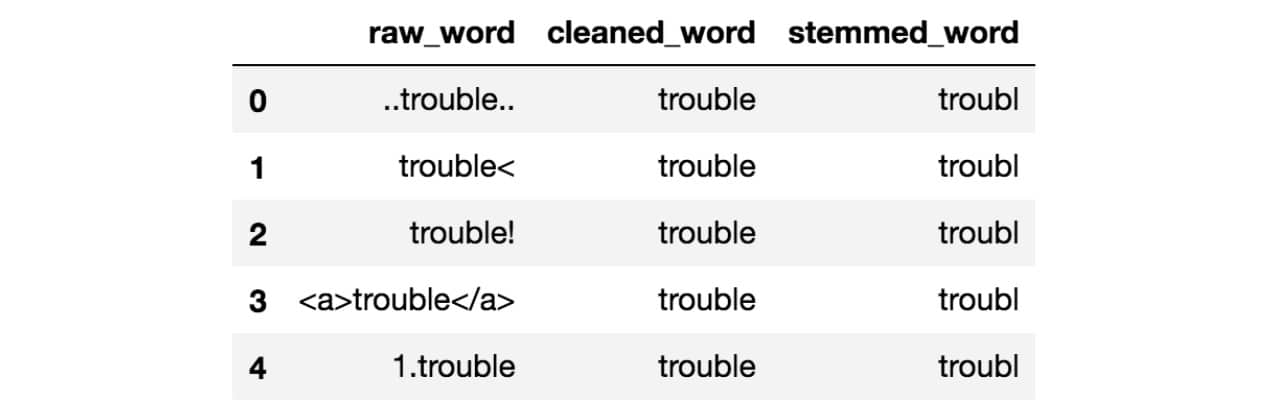
在Text Mining和NLP中,噪声消除是您应该首先考虑的事情之一。有各种方法可以消除噪音。这包括标点删除,特殊字符删除,数字删除,html格式删除,特定于域的关键字删除 (例如转发的’RT’),源代码删除,标题删除等。这一切都取决于您正在从事哪个领域以及为您的任务带来的噪音。我的笔记本中的代码片段显示了如何进行一些基本的噪音消除。
文字丰富/增强
文本丰富涉及使用您以前没有的信息来扩充原始文本数据。文本丰富为原始文本提供了更多语义,从而提高了预测能力以及可以对数据执行的深度分析。
在信息检索示例中,扩展用户的查询以改进关键字的匹配是一种增强形式。像查询一样text mining可以成为text document mining analysis。虽然这对人类没有意义,但它可以帮助获取更相关的文档。
您可以通过丰富文本的方式获得真正的创意。您可以使用词性标注来获取有关文本中单词的更详细信息。
例如,在文档分类问题中,单词书作为名词的出现可能导致与作为动词的书不同的分类,因为在阅读的上下文中使用了一个,而在保留某些内容的上下文中使用另一个。本文讨论了如何结合使用名词和动词作为输入特征来改进中文文本分类。
然而,随着大量文本的可用性,人们开始使用嵌入来丰富单词,短语和句子的含义,以便进行分类,搜索,汇总和文本生成。在基于深度学习的NLP方法中尤其如此,其中字级嵌入层非常常见。您可以从预先建立的嵌入开始,也可以创建自己的嵌入并在下游任务中使用它。
丰富文本数据的其他方法包括短语提取,您可以将复合词识别为一个(也称为分块),使用同义词进行扩展和依赖性解析。
你需要这一切吗?

不是真的,但如果你想获得良好,一致的结果,你必须确实做到这一点。为了让你了解最低限度应该是什么,我把它分解为Must Do,Should Do和Task Dependent。在决定您确实需要之前,所有依赖于任务的东西都可以进行定量或定性测试。
请记住,少即是多,您希望尽可能保持优雅。您添加的开销越多,遇到问题时您将需要剥离的层数越多。
必须要做的:
- 噪音消除
- 小写(在某些情况下可以依赖于任务)
应该做的:
- 简单规范化 – (例如,标准化几乎相同的单词)
根据任务判断是否要做:
- 高级标准化(例如,解决词汇外单词)
- 停止删除单词
- 词干/词形还原
- 文本丰富/增强
因此,对于任何任务,您应该做的最小值是尝试小写文本并消除噪音。噪音取决于您的域名(请参阅噪音消除部分)。您还可以执行一些基本的规范化步骤以获得更高的一致性,然后根据需要系统地添加其他图层。
一般经验法则
并非所有任务都需要相同级别的预处理。对于某些任务,您可以尽量减少。但是,对于其他人来说,数据集是如此嘈杂,如果你没有进行足够的预处理,它将是垃圾垃圾。
这是一般的经验法则。这并不总是成立,但适用于大多数情况。如果你有一个很好的书面文本可以在相当普通的领域中使用,那么预处理并不是非常关键; 你可以勉强逃脱(例如使用所有维基百科文本或路透社新闻文章训练一个嵌入模型的单词)。
但是,如果您在一个非常狭窄的领域工作(例如关于健康食品的推文)并且数据稀疏且嘈杂,您可以从更多的预处理层中受益,尽管您添加的每个层(例如,停止删除词,词干化,规范化)都需要被定量或定性地验证为有意义的层。这是一个表格,总结了您应该对文本数据执行多少预处理:
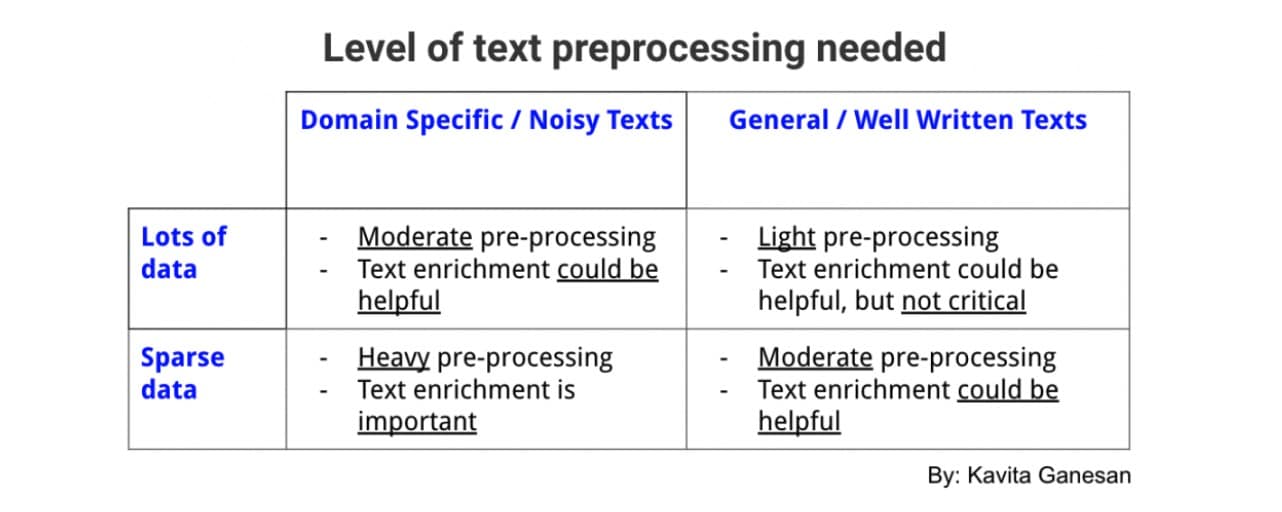
我希望这里的想法可以引导您为项目选择正确的预处理步骤。记住,少即是多。我的一位朋友曾经向我提到他是如何通过抛弃不必要的预处理层来使大型电子商务搜索系统更高效,更少错误。
资源
本文转载自medium,原文地址(需要科学上网)

Comments