

初学者该用什么样的 DL 架构?当然是越简单越好、训练速度越快越好、测试准确率越高越好!那么我们到底该选择 PyTorch 还是 Keras 呢?
Keras 和 PyTorch 当然是对初学者最友好的深度学习框架,它们用起来就像描述架构的简单语言一样,告诉框架哪一层该用什么。这样减少了很多抽象工作,例如设计静态计算图、分别定义各张量的维度与内容等等。
但是,到底哪一个框架更好一点呢?当然不同的开发者和研究者会有不同的爱好,也会有不同的看法。本文主要从抽象程度和性能两个方面对比 PyTorch 与 Keras,并介绍了一个新的基准,它复现并对比了两个框架的所有预训练模型。
在 Keras 和 PyTorch 基准项目中,MIT 在读博士 Curtis G. Northcutt 复现了 34 个预训练模型。该基准结合了 Keras 和 PyTorch,并将它们统一到一个框架内,这样我们就能知道这两个框架的对比结果,知道不同模型用什么框架好。例如,项目作者表示 ResNet 架构的模型使用 PyTorch 要比 Keras 效果好,Inception 架构的模型使用 Keras 又要比 PyTorch 好。
Keras 和 PyTorch 基准项目:https://github.com/cgnorthcutt/benchmarking-keras-pytorch
两大框架的性能与易用性
作为 TensorFlow 的高度封装,Keras 的抽象层次非常高,很多 API 细节都隐藏了起来。虽然 PyTorch 比 TensorFlow 的静态计算图更容易使用,但总体上 Keras 隐藏的细节更多一些。而对于性能,其实各框架都会经过大量的优化,它们的差别并不是很明显,也不会作为主要的选择标准。
易用性
Keras 是一个更高级别的框架,将常用的深度学习层和运算封装进便捷的构造块,并像积木一样搭建复杂模型,开发者和研究者不需要考虑深度学习的复杂度。
PyTorch 提供一个相对较低级别的实验环境,使用户可以更加自由地编写自定义层、查看数值优化任务等等。例如在 PyTorch 1.0 中,编译工具 torch.jit 就包含一种名为 Torch Script 的语言,它是 Python 的子语言,开发者使用它能进一步对模型进行优化。
我们可以通过定义简单的卷积网络看看两者的易用性:
model = Sequential()model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))model.add(MaxPool2D())model.add(Conv2D(16, (3, 3), activation='relu'))model.add(MaxPool2D())model.add(Flatten())model.add(Dense(10, activation='softmax'))如上所示为 Keras 的定义方式,很多时候运算都会作为参数嵌入到 API 中,因此代码会显得非常简洁。如下所示为 PyTorch 的定义方式,它一般都是通过类和实例的方式定义,且具体运算的很多维度参数都需要定义。
class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 32, 3) self.conv2 = nn.Conv2d(32, 16, 3) self.fc1 = nn.Linear(16 * 6 * 6, 10) self.pool = nn.MaxPool2d(2, 2) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 6 * 6) x = F.log_softmax(self.fc1(x), dim=-1) return xmodel = Net()虽然 Keras 感觉比 PyTorch 更易于使用,但两者的差别不大,都期望模型的编写能更便捷。
性能
目前有很多对比各框架性能的实验都表明 PyTorch 的训练速度相比 Keras 会快一些。如下两张图表展示了不同框架在不同硬件和模型类型的表现:
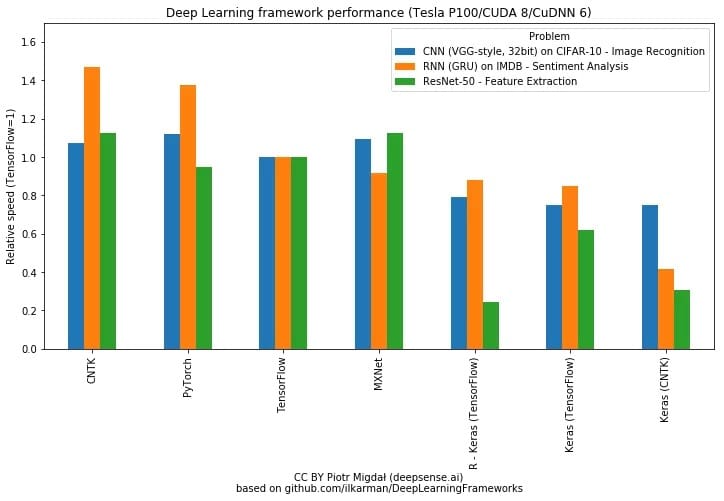
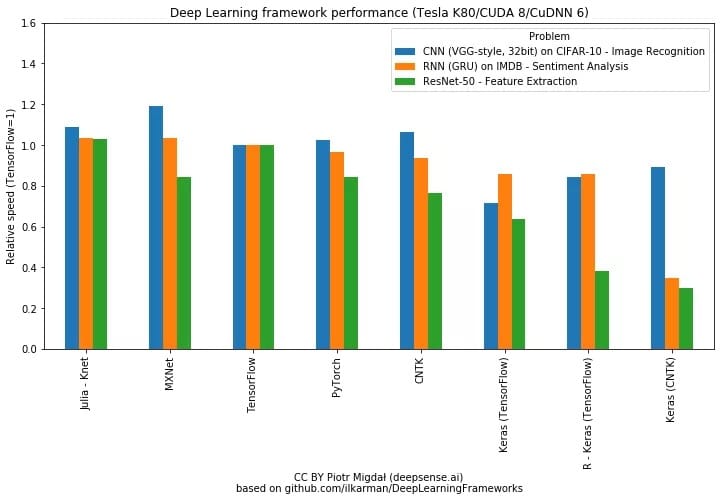
下面两张同样展示了不同模型在 PyTorch 和 Keras 框架下的性能,这两份 18 年的测试都表明 PyTorch 的速度要比 Keras 快那么一点点。
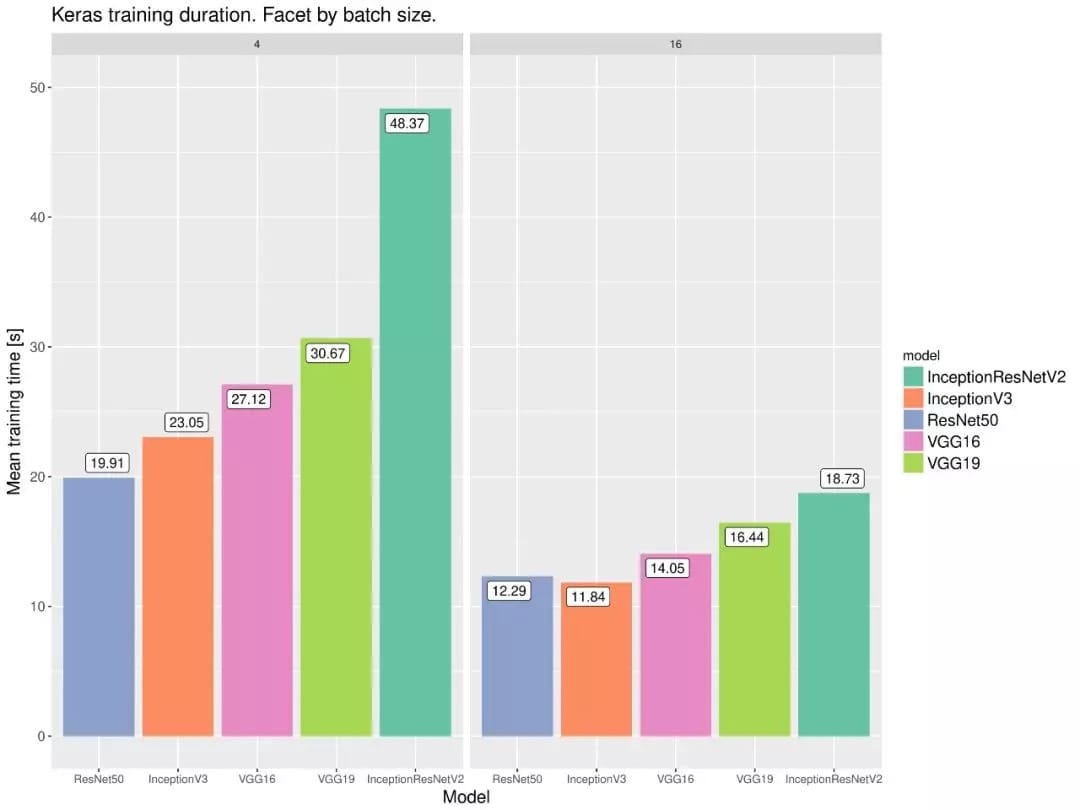
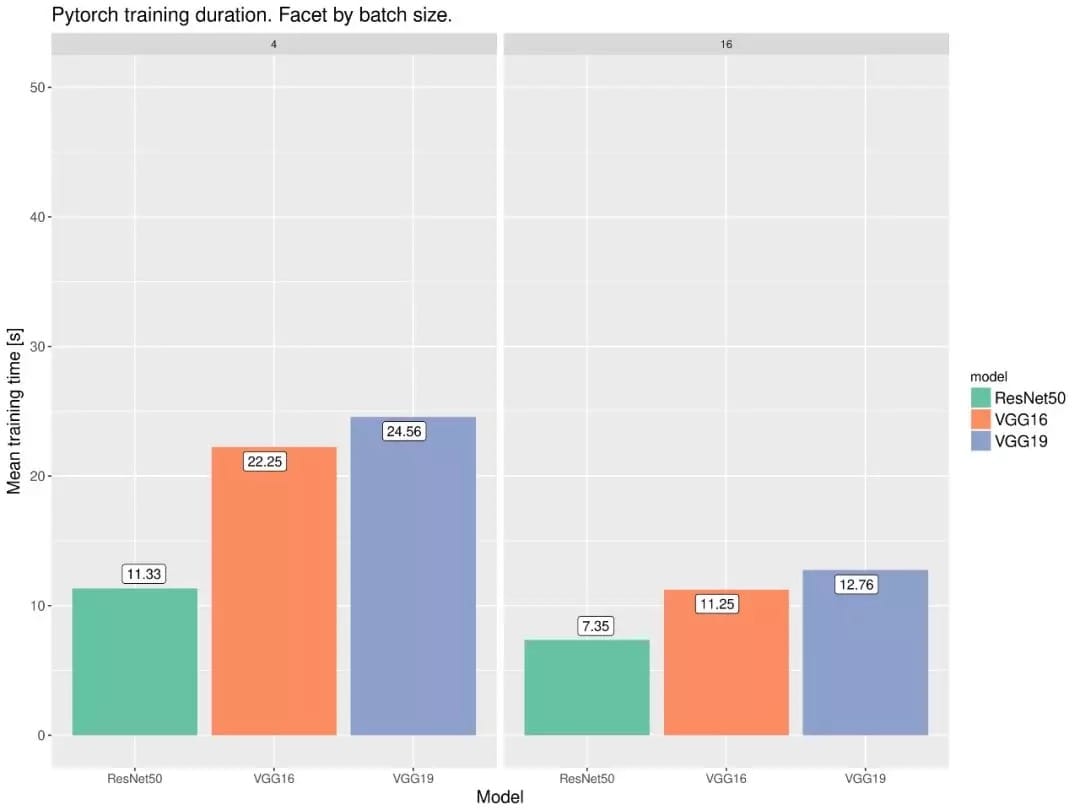
这两份对比细节可查阅:
- https://github.com/ilkarman/DeepLearningFrameworks/
- https://wrosinski.github.io/deep-learning-frameworks/
Keras 和 PyTorch Benchmark
现在如果我们从预训练模型的角度看,那么相同的模型在不同的框架上,验证集准确度又是什么样的?在这个项目中,作者用两个框架一共复现了 34 个预训练模型,并给出了所有预训练模型的验证准确率。所以该项目不仅能作为对比依据,同时还能作为学习资源,又有什么比直接学习经典模型代码更好的方法呢?
预训练模型不是已经可以复现了吗?
在 PyTorch 中是这样的。然而有些 Keras 用户却觉得复现非常难,他们遇见的问题可以分为三类:
1. 不能复现 Keras 已发布的基准结果,即使完全复制示例代码也没有用。实际上,他们报告的准确率(截止到 2019 年 2 月)通常略高于实际准确率。
2. 一些预训练的 Keras 模型在部署到某个服务器或与其他 Keras 模型一起依次运行时会产生不一致或较低的准确率。
3. 使用批归一化(BN)的 Keras 模型可能并不可靠。对于一些模型,前向传播评估仍然会导致推理阶段中的权重改变。
这些问题都是现实存在的,原 GitHub 项目为每个问题都提供了链接。项目作者的目标之一是通过为 Keras 预训练模型创建可复现基准,从而帮助解决上述的一些问题。解决方法可分为以下三个方面,在 Keras 中要做到:
- 推理期间避免分批(batches)。
每次运行一个样本,这样做非常慢,但可以为每个模型得出一个可复现的输出。
只在本地函数或 with 语句中运行模型,以确保在加载下一个模型时,前一个模型的任何东西都不会保存在内存中。
预训练模型复现结果
以下是 Keras 和 PyTorch 的「实际」验证集准确度表(已经在 macOS 10.11.6、Linux Debian 9 和 Ubuntu 18.04 上得到验证)。
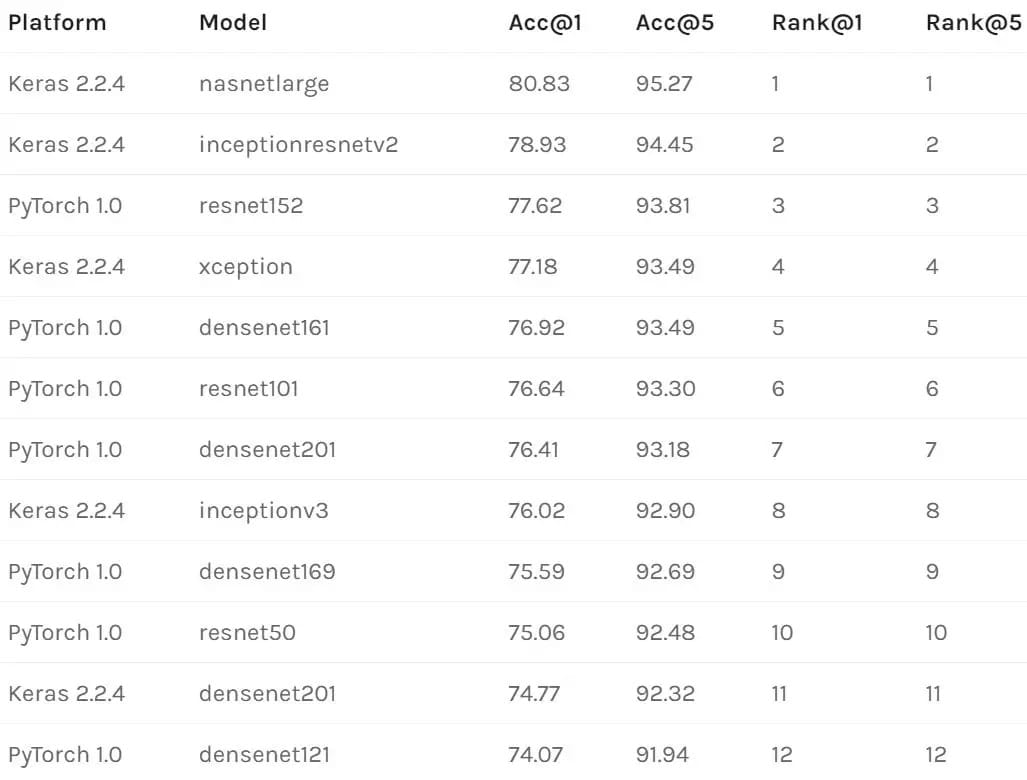
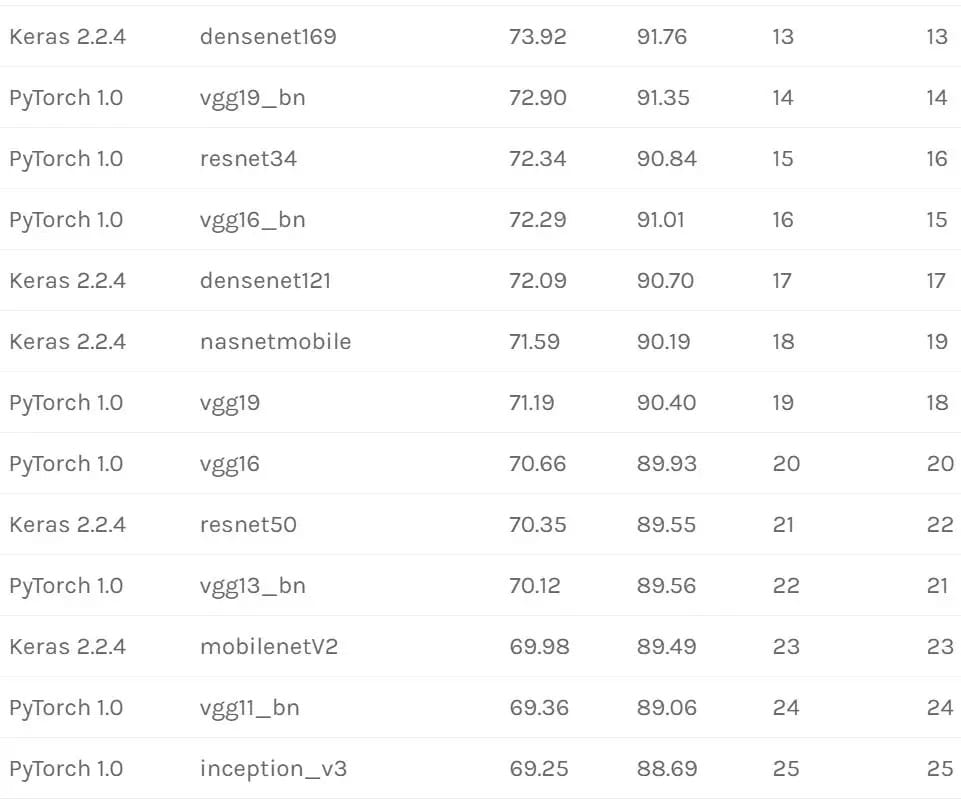
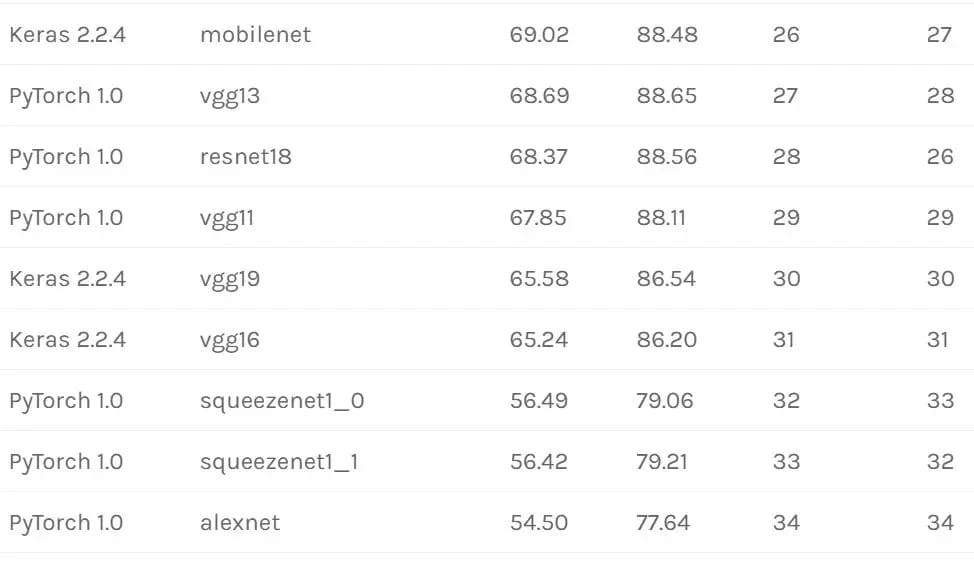
复现方法
首先需要下载 ImageNet 2012 验证集,该数据集包含 50000 张图片。在 ILSVRC2012_img_val.tar 下载完成后,运行以下命令行预处理/提取验证集:
# Credit to Soumith: https://github.com/soumith/imagenet-multiGPU.torch$ cd ../ && mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xvf ILSVRC2012_img_val.tar$ wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bashImageNet 验证集中每个示例的 top 5 预测已经进行了预计,运行以下命令行将直接使用这些预计算结果,并在几秒内复现 Keras 和 PyTorch 基准。
$ git clone https://github.com:cgnorthcutt/imagenet-benchmarking.git$ cd benchmarking-keras-pytorch$ python imagenet_benchmarking.py /path/to/imagenet_val_data不使用预计算数据也可以复现每个 Keras 和 PyTorch 的推理输出。Keras 的推理要花很长时间(5-10 小时),因为每次只计算一个示例的前向传播,还要避免向量计算。如果要可靠地复现同样的准确率,这是目前发现的唯一的方法。PyTorch 的推理非常快(一个小时都不到)。复现代码如下:
$ git clone https://github.com:cgnorthcutt/imagenet-benchmarking.git$ cd benchmarking-keras-pytorch$ # Compute outputs of PyTorch models (1 hour)$ ./imagenet_pytorch_get_predictions.py /path/to/imagenet_val_data$ # Compute outputs of Keras models (5-10 hours)$ ./imagenet_keras_get_predictions.py /path/to/imagenet_val_data$ # View benchmark results$ ./imagenet_benchmarking.py /path/to/imagenet_val_data你可以控制 GPU 的使用、批大小、输出存储目录等。运行时加上-h flag,可以查看命令行参数选项。
本文转自 机器之心,原文地址

Comments