

如果您最近一直在研究某些数学,统计或计算模型,那么您一定听说过机器学习是一种“GIGO”类型的东西。这意味着,如果你把垃圾送到垃圾场,那么你也应该期望它的垃圾概率很高。如果你真的想避免你的机器学习模型产生垃圾结果的尴尬局面,你需要理解标题所暗示的“有效数据预处理和特征工程”的重要性。为简单起见,我们将标题划分为单独的模块。
数据预处理
数据预处理是一个巨大的主题,因为预处理技术因数据而异。不同类型的数据(图像,文本,声音,视频,csv文件等)具有不同的预处理方法,但有一些方法几乎适用于任何类型的数据。这些方法中最重要的一个恰好是:
- 转化为载体
- 标准化
- 处理缺失的值
转化为载体
所有ML模型都需要输入数据以向量的形式。如果你有原始文本数据,你需要一些机制将这些字符串转换成一些有意义的数字表示,如tf-idf,word2vec等。如果你有图像,它们被处理为像素矩阵,如果你有声音,他们需要要从模拟波转换为数字信号,如果您在csv文件中获得了分类数据,则可能需要应用标签编码或单热编码。您基本上将所有数据转换为float(或者在某些情况下,整数),以便您的ML模型可以轻松处理所有这些。每个记录(每个句子,如果它是文本;声波,如果它是声音)表示您的输入的单行,并且对于多个记录,您获得输入矩阵(通常用X表示)。
趋势AI文章:
标准化
强烈建议您的数据正确缩放,这意味着您的数据不应该对每个列(功能)有很大的偏差。如果您的列的值介于0-1之间,并且您有另一个值介于100-1000之间的功能,那么这些值范围的差异可能会导致优化程序进行大的梯度更新,并且您的网络/模型可能不会收敛。因此,一种好的方法是将您的值标准化,介于100-1000之间,将它们缩放到0-1之间。分解步骤,应该应用以下步骤以获得标准化的最大好处:
- 较小的值:尝试将所有值设置为0到1或-1到1。
- 同质性:所有列的值应大致相同。
- 均值:标准化,使每列的平均值为0。
- 标准偏差:标准化,使每列的标准偏差为1。
处理缺失的值
您的数据可能并不总是理想的数据。在数据集中缺少值是非常常见的,并且处理缺失值的有效方法导致更好的模型训练。一种方法是将所有缺失值替换为0,前提是0尚未表示数据中的有意义信息。如果数据中有很多缺失值,并且用0替换它们,模型最终将会知道所有0都没有在模型的决策过程中发挥任何建设性作用,并且几乎会忽略它们通过赋予它们较低的权重。如果您的数据相当一致,特别是在时间序列或基于序列的数据集的情况下,数据的插值也会成为一个有意义的选项。否则,大多数缺失值都被替换为平均值,
特色工程
如果你认为这些数据是21世纪的原油,那么这一步就是精炼的地方,并且会提升其价值。特征工程基本上意味着您从原始数据中推导出一些隐藏的见解,并从中提取一些有意义的特征。如果要有效地完成,这一步需要一些大量的领域知识。例如,如果您要使用外汇数据设计新功能,您需要对外汇,全球经济和货币的实际运作方式有一个很好的理解。
考虑一个非常简单的例子,你想要开发一个需要一些输入的系统,并输出一天的时间。现在,您可以通过多种方式执行此操作。这样做的一种粗略方法是,您将模型的几个图像传递给模型,并标记当天的时间。你的模型可以浏览成千上万的图像,学习时钟指针和给定时间之间的视觉关系,并最终学会告诉你一天的时间估计。听起来够厉害?对?
另一种方法是,你了解时间实际如何工作,并将图像数据转换为数字,只存储时钟’手’的x和y坐标。现在将其与之前的原始图像方法进行比较。假设您传递256×256个时钟图像,这意味着需要处理65,536个值,但是当您设计坐标功能时,您只需要处理4个值!不仅这个特征工程将使模型更准确,而且速度也快数千倍。
现在,让我们先行一步,并说你已经获得了关于时钟实际如何工作的非常详细的见解,并且你能够测量两个时钟指针的角度。在这种情况下,你只需要两个角度(每只手一个),就是这样!当你获得角度,并且对测量时间所涉及的所有数学有深入的了解时,你可能只是编写一些方程的代码,因此不需要机器学习模型(但这只是一个非常简单的例如;对于更复杂的场景,ML将是一种更好的方法,而不是编码所有可能的规则)。
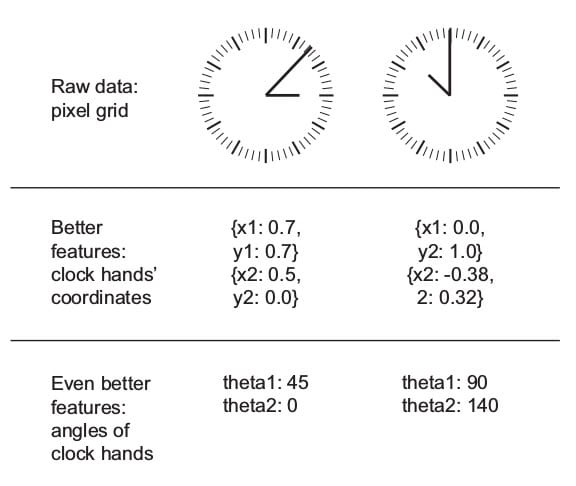
最后,总结一切,
- 好的功能可以让您使用更少的计算资源更优雅地解决问题。
- 良好的功能将让您训练一个有效数据很少的模型。
本文转自medium,原文地址


Comments