

即使在机器学习这个花哨的世界中,就像人类无法在崎vehicles不平的道路上驾驶汽车一样,机器学习算法也无法在大量不需要的杂项数据上产生预期的结果。因此,让我们深入探讨所有用于优化数据的选项。
注意:这可能有点冗长。因此,我将其分为三个部分。因此,请逐步进行探索。
第1部分:特征工程
什么是特征工程,为什么要打扰?
特征工程是使用数据的领域知识来创建使机器学习算法起作用的特征的过程。特征工程是机器学习应用的基础,既困难又昂贵。但是,如果操作正确,可能会带来奇迹。这是相同算法工作不佳和性能出色之间的区别。
这很重要,不能忽略。让我们看看它的总体思路:
- 数据清理和预处理
→处理异常值
→处理缺失值
→处理偏斜
- 缩放比例
- 编码方式
- 数据清理和预处理: 在现实世界中,我们永远不会获得完美适合算法的量身定制数据。我们需要通过以下方式做到这一点。

i)处理异常值:异常值是不遵循数据总体趋势的数据点。许多算法对异常值敏感。那么问题是怎么办?
→如果数量很少,请完全将其取出。您可以设置阈值以识别它们,然后将其删除。如果列中有很多离群值,则最好完全删除该列,行也一样。
→您可以将所有内容转换为“日志形式”,因为日志可以使所有内容保持相同的距离。(尽管仅适用于数字数据)
→ 使用散点图,直方图以及箱形图和晶须图可视化数据,并寻找极值。还有很多其他技术可以用来处理离群值,我建议您仔细阅读。
ii)处理缺失值: 为什么要缺失价值处理?
训练数据集中的数据丢失会降低模型的功效/拟合度。缺少值可能会导致模型产生偏差,因为我们没有正确分析其行为以及与其他变量的关系。这很有用,因为某些算法无法使用或利用丢失的数据。因此,重要的是识别并标记该丢失的数据。标记后,即可准备替换值。
→用均值,中位数,众数替换缺失值(这完全取决于判断结果)。您可以将sklearn.preprocessing.impute用于相同的目的。
→如果需要,您可以用全新的数据替换(再次调用判断)。
→或者,如果缺少太多值,则可以删除完整的列。因此,这主要需要判断调用,再次!!!
iii)偏斜度:偏斜度是分布不对称的度量。偏斜度是对称性的量度,或更准确地说,是缺乏对称性的量度。
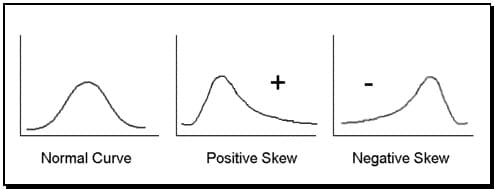
为什么要处理偏度?
→许多模型构建技术都假设预测变量值呈正态分布并具有对称形状。因此,有时处理偏斜度至关重要。
→对称分布优于倾斜分布,因为它更易于解释和生成推论。
→使用对数变换,平方根变换等。
2. 缩放: 就像处理缺失值是强制性的一样,缩放不是必须的。但这并不意味着它不那么重要。考虑一种情况,您的某一列(例如A)的值在10k到100k的范围内,而一列的值在0到1(例如B)的范围内,那么A将比B具有不适当的优势因为它将携带更多的重量。
→ 缩放将要素修改为介于给定的最小值和最大值之间,通常介于零和一之间,或者将每个要素的最大绝对值缩放为单位大小,以提高某些模型的数值稳定性。
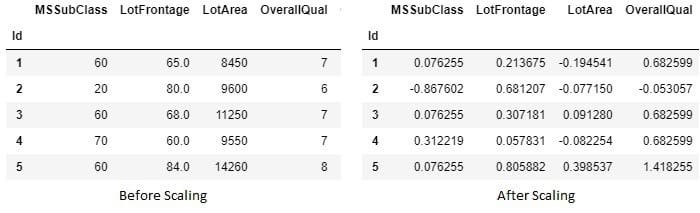
→但是标准化/缩放不能应用于分类数据,因此我们将分类数据和数值数据分开以使数值数据标准化。
→ MinMax缩放器,Standard Scler,Normalizer等是一些技术。可以使用“ sklearn.preprocessing.scaler”执行所有操作
(我建议您访问此博客以更深入地研究Scaling)
3.编码:那么,什么以及为什么编码?
我们使用的大多数算法都使用数值,而分类数据通常采用文本/字符串(男性,女性)或bin(0–4、4–8等)形式。
一种选择是将这些变量排除在算法之外,而仅使用数字数据。但是这样做,我们可能会丢失一些关键信息。因此,通常最好将类别变量包括在您的算法中,方法是将其编码以转换为数字值,但首先让我们了解有关类别变量的一两件事。
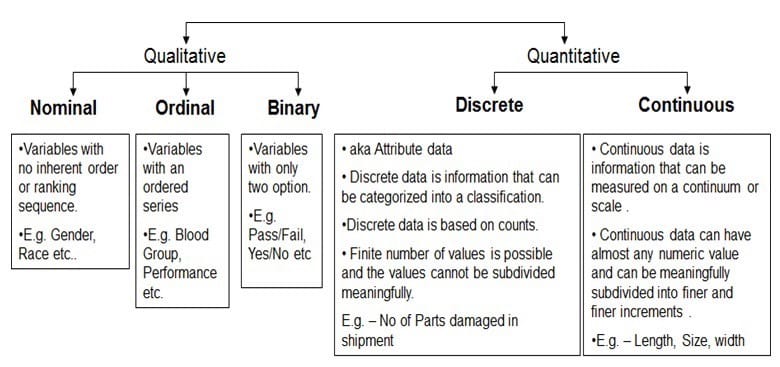
通常,对数据执行两种类型的编码,即标签编码和一种热编码(或pandas.get_dummies)。
i)标签编码:给每个类别一个标签(例如0、1、2等)。标签编码是一种对分类变量进行编码的便捷技术。但是,这样编码的名义变量可能最终会被误解为序数。因此,标签编码仅对序数类型的数据(具有某种顺序感)进行。
→因此,即使在标签编码之后,所有数据也不会丢失其排名或重要性级别。

可以使用“ sklearn.preprocessing.LabelEncoder”执行
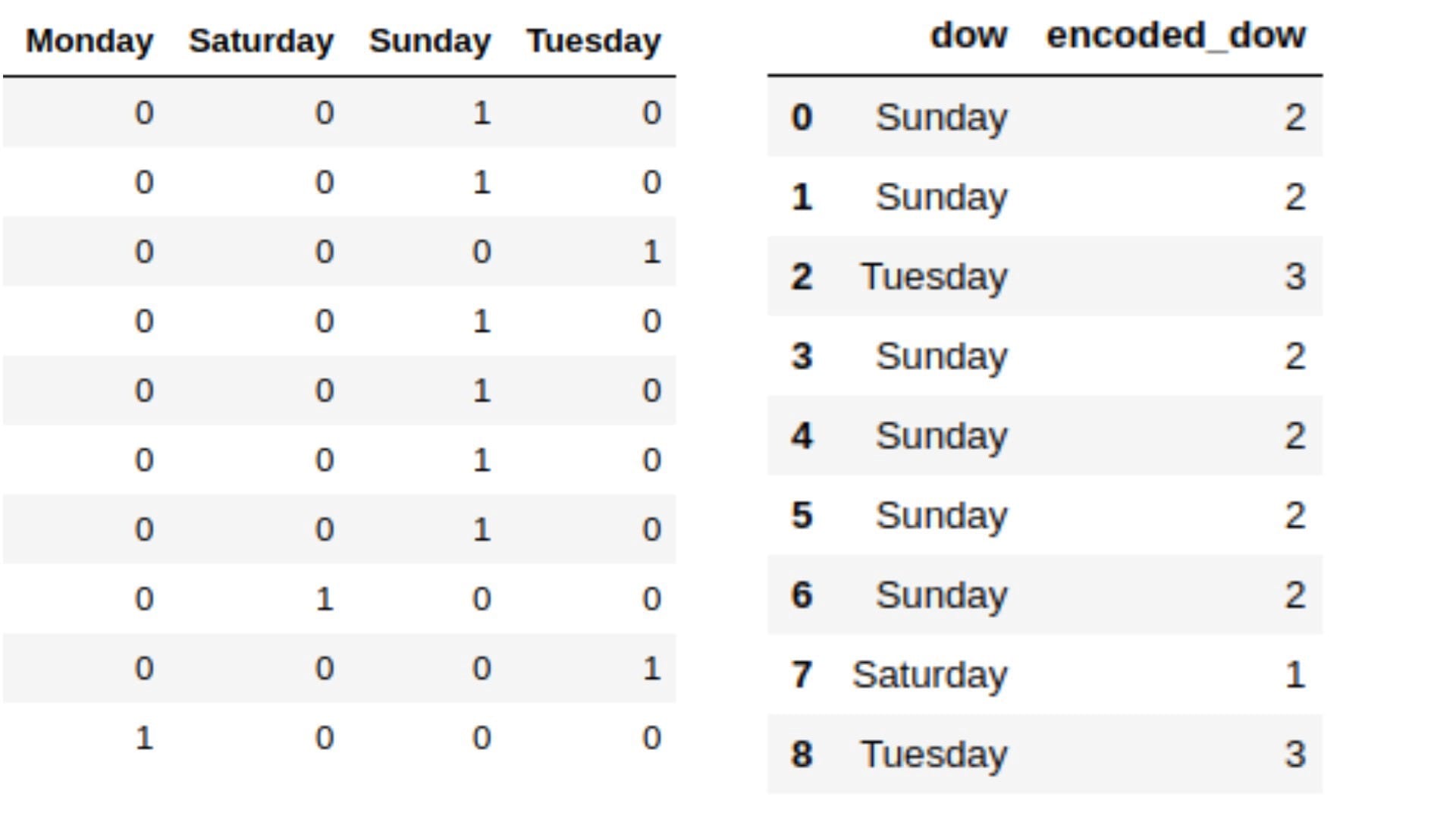
ii)一种热编码:标签编码无法在标称或二进制上执行,因为我们无法根据它们的属性对其进行排名。每个数据均被平等对待。考虑以下两个类别变量及其值,例如
→颜色:蓝色,绿色,红色,黄色
→学历:小学,中学,研究生,研究生,博士学位。
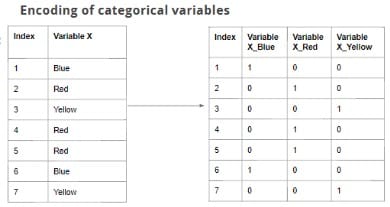
可以使用“ pd.get_dummies”或“ sklearn.preprocessing.OneHotEncoder”执行
具有更大维度的数据集需要更多参数才能使模型理解,这意味着需要更多行才能可靠地学习这些参数。使用一个热编码器的效果是增加了许多列(尺寸)。
如果数据集中的行数是固定的,那么在不增加更多信息以供模型学习的情况下添加额外维度可能会对最终模型的准确性产生不利影响。
至此,第1部分结束了。请阅读第2部分,其中将讨论特征提取和超重要的降维。


Comments