

上一篇:《为建模做好数据准备:特征工程,特征选择,降维(第1部分》
一旦有了足够的数据,就可以选择特征选择或特征提取(它们大部分都可以完成相同的工作,并且可以互换使用)。通常有两种方法:
- 特征提取/选择
- 降维或特征减少
让我们一步一步地找出它们。
第2部分:特征提取/选择
那么什么是特征选择?特征提取?他们的区别?
→在机器学习和统计中,特征选择(也称为变量选择)是选择相关特征子集(变量,预测变量)以用于模型构建的过程。
→特征提取用于创建一组新的较小的特征,这些特征仍会捕获大多数有用的信息。
→同样,特征选择保留原始特征的子集,而特征提取则创建新特征。
特征选择/提取的重要性
→当功能数量很大时,这一点变得尤为重要。
→您无需使用所有可用功能来创建算法。
→您可以通过仅提供真正重要的功能来辅助算法。
在哪里使用功能选择?
→它使机器学习算法的训练速度更快,降低了复杂度并使其更易于解释。
→如果选择了正确的子集,则可以提高模型的准确性。
→这样可以减少过度拟合的情况。
它可以大致分为两种技术(尽管这不是“ 那里的唯一方法 ”)
一世。单变量特征选择
ii。多元特征选择
ünivariate功能选择:该技术涉及多个手工样的工作的。访问每个功能并与目标一起检查其重要性。为了实施“单变量特征选择” ,您应该掌握一些技巧。
→如果您具有适当的领域知识并信任您的判断电话,则始终从此步骤开始。分析所有功能并删除所有不需要的功能。是的,这是耗时费力的步骤,但是,嘿,您会更信任的人,“机器还是您自己”
→ 检查所有功能的方差(是的,一直是令人困惑的偏差方差折衷:)。此处的经验法则规则设置了一个阈值(例如,方差为0的特征表示每个样本具有相同的值,因此该特征不会给模型带来任何预测能力)相应地删除特征。
→ 皮尔逊相关系数的使用:这可能是三种方法中最适用的技术。如果您不了解或困惑,请先阅读本文。
- 简而言之,它为我们提供了目标变量和功能之间的相互依存关系。

- 使用Pearson相关的Thumb规则:
一世。只选择与目标变量的中等至强关系。(请参见上图)。
ii。当两个要素本身与目标变量之间具有很强的关系时,则选择它们中的任何一个(选择两者都不会增加任何值)。使用“ seaborn.heatmap() ”进行可视化和选择,这很有帮助。
iii。这里有个陷阱。它对线性数据最有效,而对非线性数据则效果较差(因此请避免使用)。
中号ultivariate功能选择:当你有很多的功能(如他们的数百或数千个),那么它真的成为不可能去和手动检查他们中的每一个,或者如果你没有足够的领域知识,那么你得相信以下技术。因此,用通俗易懂的术语讲,就是一次选择多个功能。
多元特征选择大致分为三类:

让我们检查一下(我们将讨论每个类别中使用最广泛的技术)
过滤方式:
→过滤方法通常用作预处理步骤。功能的选择与任何机器学习算法无关。
→过滤器方法对功能进行一些排名。排名表示每个功能可能对分类有多“有用”。一旦计算出该排名,就创建了由最佳N个特征组成的特征集。
→在各种统计测试中,根据要素的得分选择要素与结果变量的相关性。(此处的相关性是一个主观术语)。

- 皮尔森的相关性:哦,是的!皮尔逊相关是过滤方法。我们已经讨论过了。
- 差异 阈值:我们已经讨论过了。
- 线性判别分析:目标是将数据集投影到具有良好类可分离性的低维空间上,以避免过度拟合(“ 维数的诅咒 ”)并降低计算成本。
→不进行数学运算,LDA将所有较高维度的变量(我们无法绘制和分析)带到2D图形上,同时这样做会删除无用的功能。
→LDA还是一种“ 降低维数”技术,比“ 选择”更具特征提取能力(因为它通过减小维数来创建新变量)。因此,它仅适用于标记的数据。
→最大限度地提高了类之间的可分离性。(技术术语过多,对。不用担心,请观看视频)。
其他:
方差分析:方差分析它与LDA相似,不同之处在于它使用一个或多个类别独立特征和一个连续从属特征进行操作。它提供了几个组的均值是否相等的统计检验。
卡方:这是一种统计测试,应用于分类特征组,以使用它们的频率分布来评估它们之间相关或关联的可能性。
应该记住的一件事是,滤波方法不会消除多重共线性。因此,在训练数据模型之前,您还必须处理要素的多重共线性。

包装方法:

→根据从先前模型得出的推论,我们决定从您的子集中添加或删除特征。
→之所以称为包装器方法,是因为它们将分类器包装在特征选择算法中。通常,选择一组功能。确定这套装置的效率;进行一些更改以更改原始集,并评估新集的效率。
→这种方法的问题是特征空间很大,查看每个可能的组合将花费大量时间和计算量。
→从本质上讲,该问题已简化为搜索问题。这些方法通常在计算上非常昂贵。
- 正向选择:正向选择是一种迭代方法,我们从模型中没有任何特征开始。在每次迭代中,我们都会不断添加最能改善模型的功能,直到添加新变量不会改善模型的性能为止。
- 向后消除:在向后消除中,我们从所有特征开始,并在每次迭代时都删除最不重要的特征,从而提高了模型的性能。我们重复此过程,直到在去除特征方面未观察到任何改善。
- 递归特征消除(RFE):它通过递归删除属性并基于剩余的属性构建模型来工作。它使用外部估计器为要素(例如线性模型的系数)分配权重,以识别哪些属性(以及属性的组合)对预测目标属性的贡献最大。
→这是一种贪婪的优化算法,旨在找到性能最佳的特征子集。
→它会反复创建模型,并在每次迭代时保留性能最佳或最差的功能。
→它将构建具有左侧特征的下一个模型,直到用尽所有特征。然后,根据特征消除的顺序对特征进行排序。
# Recursive Feature Elimination from sklearn.feature_selection import RFE from sklearn.linear_model import LinearRegression# create a base classifier used to evaluate a subset of attributes model = LinearRegression()X, y = iowa.iloc[:,:-1], iowa.iloc[:,-1] # create the RFE model and select 3 attributes rfe = RFE(model, 10) rfe = rfe.fit(X, y)# summarize the selection of the attributes print(rfe.support_) print(rfe.ranking_) Output: [False False True True False False False False False False False False False False False True True True False True True True True False True False False False False False False False False False] [16 24 1 1 4 9 18 13 14 15 11 6 7 12 10 1 1 1 2 1 1 1 1 5 1 23 17 20 22 19 8 21 25 3]
→这就是以上示例中发生的情况,
一世。’ rfe.support_ ‘ 顺序给出有关特征的结果(显然是基于所选模型,而没有要求)。
ii。’ rfe.ranking_ ‘分别给所有特征赋予等级。当您需要的功能多于您向“ n_features_to_select”输入的功能时(例如上面的10个),这确实很方便。因此,您可以设置阈值并分别选择其上方的所有功能。
4.顺序特征选择器:顺序特征选择算法是一系列贪婪搜索算法,用于将初始 d维特征空间缩小为 k维特征子空间(其中 k <d)。
→逐步进行功能选择从评估每个单独的功能开始,然后选择那些性能最佳的选定算法模型。
→后退特征选择紧密相关,您可能已经猜到了,它从整个特征集开始,然后从那里进行反作用,删除特征以找到预定义大小的最佳子集。
→什么是“最佳”?
这完全取决于定义的评估标准(AUC,预测准确性,RMSE等)。接下来,评估所选特征和后续特征的所有可能组合,并选择第二个特征,依此类推,直到选择了所需的预定义数量的特征。
→简而言之,SFA会根据分类器的性能同时删除或添加一个特征,直到达到所需大小k的特征子集为止。
注意:我建议您访问官方文档以通过示例更详细地了解它
顺序特征选择器— mlxtend一个由有用的工具和扩展组成的库,用于日常数据科学任务。rasbt.github.io
嵌入方法:
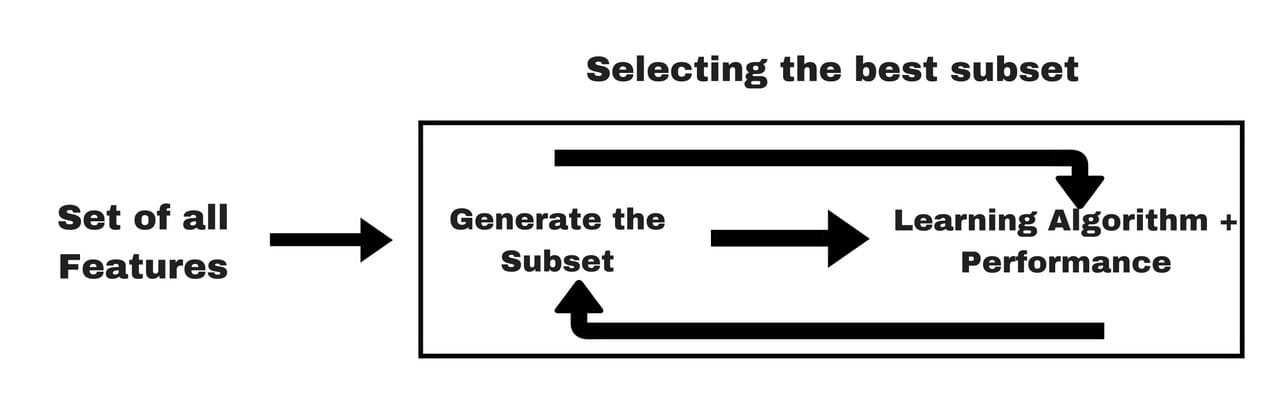
→嵌入式方法结合了过滤器和包装器方法的质量。它由具有自己的内置功能选择方法的算法实现。
→因此,这不是任何一种特殊的特征选择或提取技术,它们还有助于避免过度拟合。
- 线性回归中的套索正则化
- 在随机森林中选择k最佳
- 梯度提升机(GBM)
过滤器和包装器方法之间的区别

第3部分:缩小尺寸
因此,再次从相同的问题开始,什么是降维?
简单来说,是将初始d维特征空间缩小为k维特征子空间(其中k <d)。
那么特征选择和提取为什么呢?
从某种意义上说是肯定的(但仅限于“ 外行 ”)。要了解这一点,我们必须更深入地研究。
在机器学习中,维数只是指数据集中特征(即输入变量)的数量。当特征数量相对于数据集中的观测数量非常多时,某些算法将难以训练有效的模型。这称为“维数诅咒”,它与依赖于距离计算的聚类算法特别相关。
(Quora用户为“维数诅咒”提供了一个很好的类比,看看)
因此,当您拥有100甚至1000个特征时,那次您只有一个选择Dimension Reduction。让我们讨论两种极其健壮和流行的技术。
- 线性判别分析(LDA):是的,它与Filter方法(如上所述)一起也被用作降维技术。
→当标记了功能时,我们在监督学习中使用了LDA。
→请准备并了解LDA(如果尚未安装)。
2.主成分分析(PCA):PCA的主要目的是对数据进行分析以识别模式,并找到模式以减小数据集的维数,同时将信息损失降至最低。
→PCA将尝试通过探索数据的一个特征如何根据其他特征(线性相关性)来表达来降低维数。相反,特征选择要考虑目标。
→PCA在具有3个或更大维度的数据集上效果最佳。因为,随着维数的增加,从结果数据云中进行解释变得越来越困难。
(PCA有点复杂,是的。在这里进行解释会使这个已经很长的博客更加无聊。因此,请使用这两个出色的资料来理解,
ii。乔什·斯塔默(Josh Starmer)的视频解释(来自StatQuest的同一个人)
w ^敲击起来:但不是由包装方法(杜…😜)。这到系列的结尾。最后(但不是列表)提示:
一世。永远不要忽略特征工程或特征选择,并将所有内容保留在算法中。
ii。在尾注中,我分享了两个非常有用且功能强大的工具(请记住我的话,这对您有很大帮助)


Comments