

该协会为计算语言学第57届年会(ACL 2019)将于本周开始在意大利的佛罗伦萨。我们借此机会回顾了动画NLP空间的主要研究趋势,并从业务角度阐述了一些含义。这篇文章得到了统计数据的支持 – 猜测 – 过去20年来基于NLP的ACL论文分析。
1.动机
与其他物种相比,自然语言是人类思维的主要USP之一。NLP是当今技术讨论的一个主要流行语,涉及计算机如何理解和生成语言。NLP在过去几十年的崛起得到了几个全球发展的支持 – 围绕AI的普遍炒作,深度学习领域的指数级进展以及不断增加的可用文本数据量。但是嗡嗡声背后的实质是什么?事实上,NLP是一个高度复杂的跨学科领域,由语言学,数学和计算机科学的高质量基础研究不断提供。ACL会议将这些不同的角度结合在一起。如下图所示,过去几年的研究活动蓬勃发展:
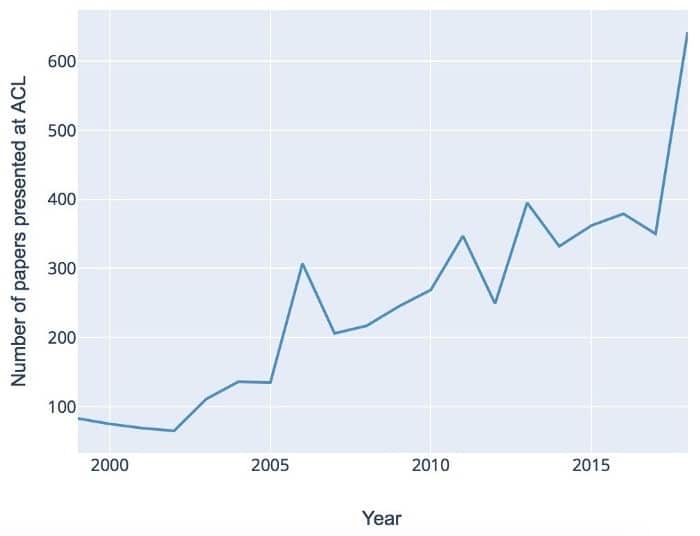
在下文中,我们总结了数据策略,算法,任务以及多语言NLP方面的一些核心趋势。该分析基于自1998年以来发表的ACL论文,该论文使用针对NLP和机器学习领域的领域特定本体进行处理。
2.数据:解决瓶颈问题
免费提供的文本数据量呈指数级增长,这主要是由于Web内容的大量生成。但是,这大量数据带来了一些关键挑战。首先,大数据本质上是嘈杂的。想想石油和金属等自然资源 – 在最终产品中使用之前,需要进行精炼和净化处理。数据也是如此。一般来说,生产渠道越“民主”,数据越脏 – 这意味着必须花更多的精力来清理它。例如,来自社交媒体的数据将需要更长的清洁管道。除此之外,你还需要处理像表情符号和不规则标点符号这样的自我表达的浪漫,这些通常在科学论文或法律合同等更正式的环境中不存在。
另一个主要挑战是标记数据瓶颈:严格来说,大多数最先进的算法都受到监督。他们不仅需要标记数据 – 他们需要大标签数据。这与深度学习系列的高级复杂算法特别相关。就像孩子的大脑首先需要最大的输入才能学习它的母语一样,要“深入”,算法首先需要大量的数据才能在整个复杂性中包含语言。
传统上,小规模的训练数据已经手动注释。但是,大型数据集的专用手动注释带来了效率权衡,这种权衡很少被接受,尤其是在业务环境中。
有哪些可能的解决方案?一方面,管理方面有一些改进,包括。众包和培训数据即服务(TDaaS)。另一方面,机器学习社区也提出了一系列用于创建带注释数据集的自动变通方法。下图显示了一些趋势:
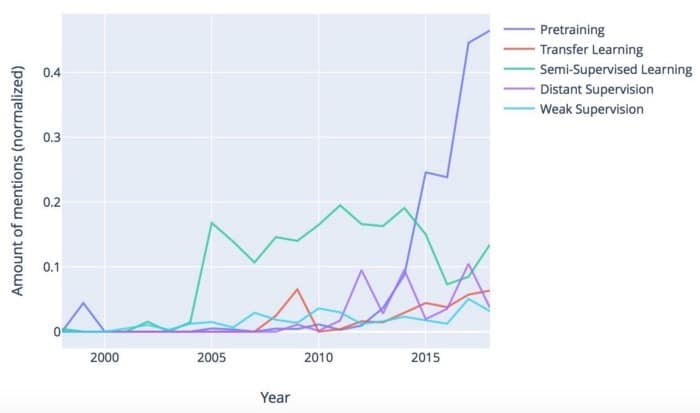
显然,预训练在过去五年中增幅最大。在预训练中,模型首先在大型通用数据集上进行训练,然后根据任务特定数据和目标进行调整。它的受欢迎程度很大程度上是因为Google和Facebook等公司正在为开源社区提供开箱即用的大型模型。特别是预训练的单词嵌入,如Word2Vec,FastText和BERT,使NLP开发人员能够跳到更高的水平。转移学习是在不同任务中重用模型的另一种方法。如果现有模型的重用不是一种选择,那么可以利用少量标记数据自动标记更大量的数据,如在远程和监管不力 – 但请注意,这些方法通常会导致标签精度下降。
3.算法:深度学习中的一系列中断
在算法方面,近年来的研究主要集中在深度学习系列:
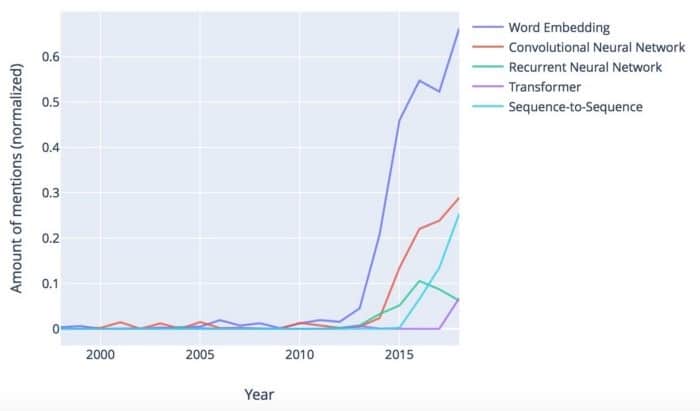
Word嵌入显然正在占据上风。在其基本形式中,Mikolov等人引入了嵌入词。(2013年)。单词嵌入背后的通用语言原则是分布相似性:一个单词可以通过其出现的上下文来表征。因此,作为人类,我们通常可以用“交易”或“合同”等合适的词语完成句子“客户在今天签署___”这一句子。Word嵌入允许自动执行此操作,因此非常强大,可以解决上下文感知问题的核心问题。
虽然word2vec(原始嵌入算法)是统计的,并不考虑生活的复杂性,如模糊性,语境敏感性和语言结构,后续方法丰富了包含各种语言信息的词嵌入。而且,顺便说一下,你不仅可以嵌入单词,还可以嵌入其他东西,如感官,句子和整个文档。
神经网络是深度学习的主力(参见Goldberg和Hirst(2017),介绍了NLP环境中的基本架构)。卷积神经网络在过去几年中有所增加,而传统的递归神经网络(RNN)的普及正在下降。一方面,这要归功于更高效的基于RNN的架构,如LSTM和GRU。另一方面,序列到序列中引入了一种新的,相当破坏性的顺序处理机制 – 注意力Sutskever等人的(seq2seq)模型。(2014)。如果你使用谷歌翻译,你可能已经注意到几年前翻译质量的超越 – seq2seq是罪魁祸首。虽然seq2seq仍然依赖于管道中的RNN,但变压器架构是2017年的另一个重大进步,最终摆脱了复发并完全依赖于注意机制(Vaswani等人2017)。
深度学习是一个充满活力和迷人的领域,但从应用程序的角度来看,它也可能非常令人生畏。如果确实如此,请记住,大多数开发都是通过提高大数据规模的效率,上下文感知以及针对不同任务和语言的可扩展性来实现的。对于数学介绍,Young等人。(2018)提供了对最先进算法的出色概述。
4.整合各种NLP任务
当我们查看特定的NLP任务(例如情绪分析和命名实体识别)时,库存比基础算法更稳定。多年来,从预处理任务(如句法解析和信息提取)到语义导向任务(如情感/情感分析和语义分析)的梯度演变。这对应于Cambria等人描述的三种“全局”NLP发展曲线 – 语法,语义和语境感知。(2014)。正如我们在上一节中看到的那样,第三条曲线 – 对更大背景的认识 – 已经成为新的深度学习算法背后的主要驱动因素之一。
从更一般的角度来看,任务不可知的研究有一个有趣的趋势。在第2节中,我们看到了现代数学方法的泛化能力如何在转移学习和预训练等场景中得到充分利用。实际上,现代算法正在开发出惊人的多任务处理能力 – 因此,手头特定任务的相关性会降低。下图显示自2006年以来对特定NLP任务的讨论总体下降:

5.关于多语言研究的说明
随着全球化,走向国际成为业务增长的必要条件。传统上,英语是大多数NLP研究的起点,但近年来对可扩展多语言NLP系统的需求也在增加。这种需求如何反映在研究界?将不同的语言视为不同的镜头,通过它们我们可以看到同一个世界 – 它们共享许多属性,这一事实完全被现代学习算法所支持,并且具有越来越强大的抽象和泛化能力。尽管如此,特别是在预处理阶段,必须彻底解决特定于语言的功能。如下图所示,ACL研究中所涉及的语言多样性不断增加:

然而,正如上一节中针对NLP任务所看到的那样,一旦语言特定的差异被中和到下一波算法中,我们就可以期待合并。图6总结了最流行的语言。
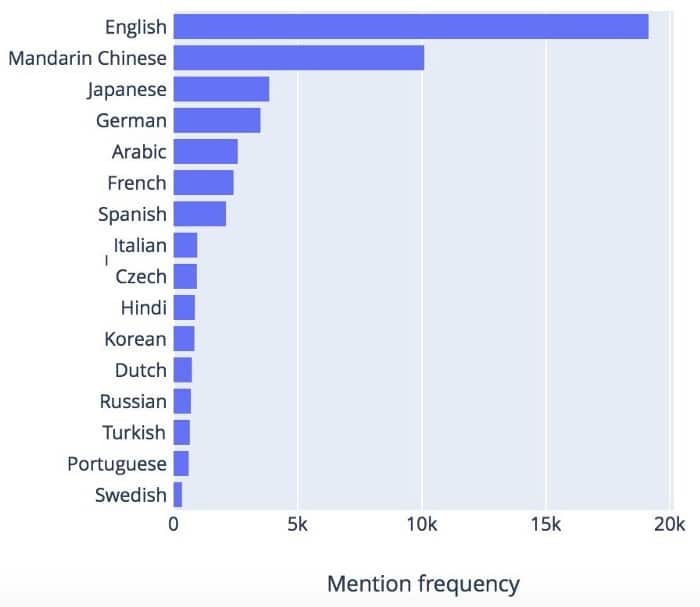
对于其中一些语言,研究兴趣符合商业吸引力:英语,中文和西班牙语等语言汇集了大量可用数据,庞大的母语人口和相应地理区域的巨大经济潜力。然而,丰富的“较小”语言也表明NLP领域通常朝着多语言和跨语言概括的理论上合理的方式发展。
总结
在全球人工智能炒作的刺激下,NLP领域正在爆发新方法和颠覆性改进。模型意义和背景依赖性正在转变,可能是人类语言中最普遍和最具挑战性的事实。现代算法的泛化能力允许跨不同任务,语言和数据集进行有效扩展,从而显着加快NLP开发的ROI周期,并允许将NLP灵活有效地集成到各个业务场景中。
本文转自towardsdatascience,原文地址


Comments