


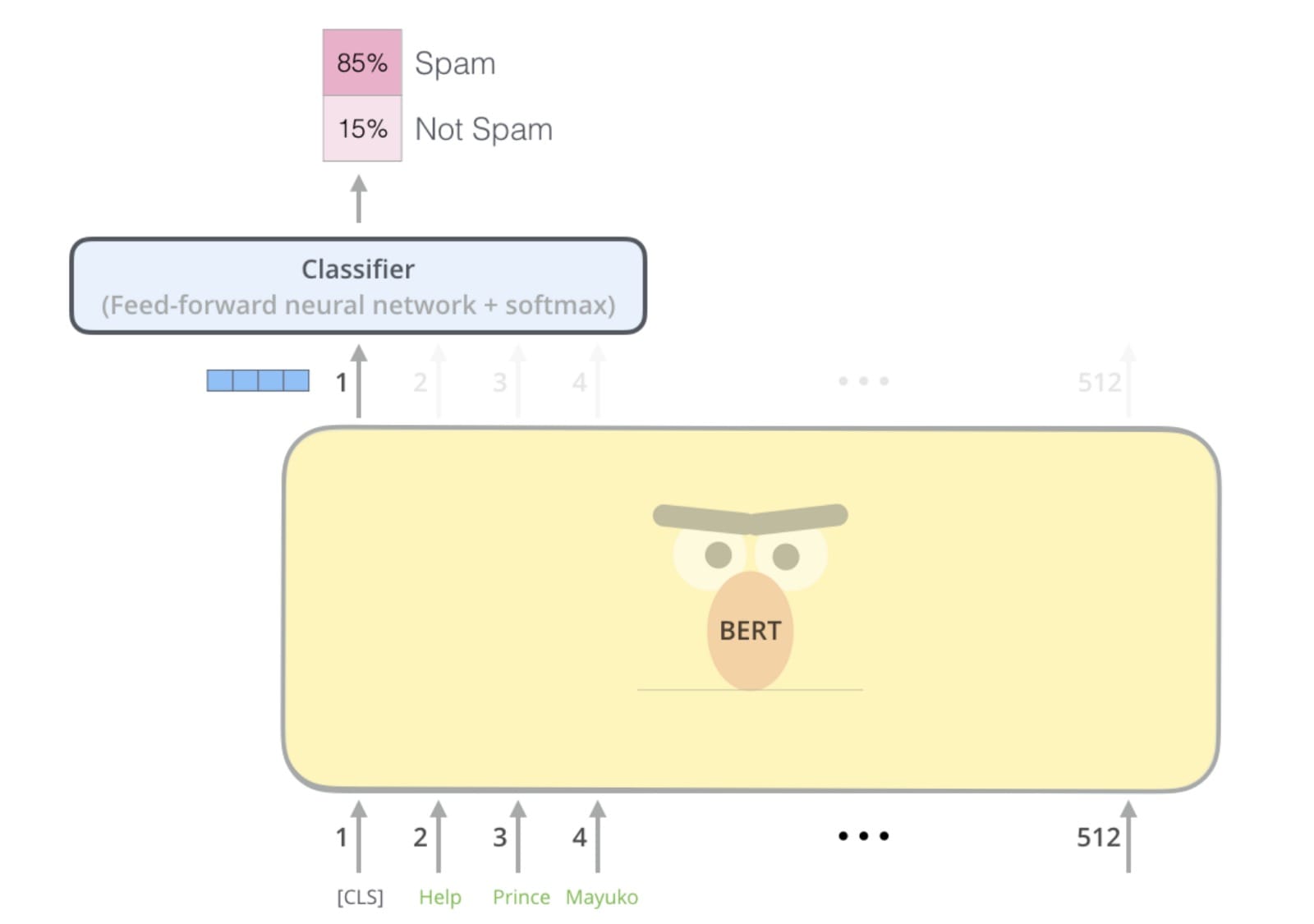
在大多数NLP研究人员看来,2018年是技术进步的一年,新的预训练 NLP模型打破了从情绪分析到问答的任务记录。
但对于其他人来说,2018年是NLP永远毁掉芝麻街的一年。
首先来到ELMo,然后BERT,现在BigBird坐在顶上GLUE排行榜。我自己的想法已被这种命名惯例所破坏,当我听到“ 我一直在玩Bert”时,例如,我脑海中浮现的图像不是我童年时期模糊不均的鸟头,而是某种东西。像这样:
我无法看到那个,插图BERT!
我问你 – 如果芝麻街对NLP模特品牌不安全,那是什么?
但有一种模式让我的童年记忆完好无损,这种算法仍然无名无名,被其作者简称为“语言模型”或“我们的方法”。只有当某篇论文的作者需要比较他们的时候这个无名创作的异想天开的模特被认为值得一个绰号。而且它不是摇奖或格罗弗或饼干怪兽; 这个名字确切地描述了算法是什么,而不是更多:OpenAI GPT,来自OpenAI的生成预训练的Transformer。
但与其命名相同,OpenAI GPT被BERT毫不客气地从GLUE排行榜中淘汰出局。GPT垮台的一个原因是它是使用传统语言建模预先训练的,即预测句子中的下一个单词。相比之下,BERT是预先训练使用蒙面语言建模,这更是一个填充式的毛坯运动:猜测失踪(“掩盖”)字样因为来之前的话后。这种双向架构使BERT能够学习更丰富的表示,并最终在NLP基准测试中表现更好。
因此,在2018年末,似乎OpenAI GPT将永远为历史所知,因为它是BERT的通用名称,古怪单向的前身。
但是2019年却讲了一个不同的故事。事实证明,导致GPT在2018年垮台的单向架构赋予它做BERT从未做过的事情的能力(或者至少不是为此而设计的):写关于谈论独角兽的故事:

你看,从左到右的语言建模不仅仅是一次预训练; 它还可以完成一项非常实际的任务:语言生成。如果你可以预测一个句子中的下一个单词,那么你可以在那之后预测单词,然后是下一个单词,很快就会有很多单词。如果你的语言建模足够好,这些单词将形成有意义的句子,句子将形成连贯的段落,这些段落将形成你想要的任何东西。
而在2019年2月14日,OpenAI的语言模型确实足够好 – 足以写出谈论独角兽,生成假新闻和撰写反回收宣言的故事。它甚至被赋予了一个新名称:OpenAI GPT-2。
那么GPT-2的人类写作能力的秘诀是什么?没有基本的算法突破; 这是扩大规模的壮举。GPT-2拥有惊人的15亿个参数(比原来的GPT多15倍),并接受了来自800万个网站的文本培训。
如何理解具有15亿个参数的模型?让我们看看可视化是否有帮助。
可视化GPT-2
由于担心恶意使用,OpenAI没有发布完整的GPT-2模型,但他们确实发布了与原始GPT(117 M参数)相当的较小版本,并在新的更大的数据集上进行了培训。虽然没有大型模型那么强大,但较小的版本仍然有一些语言生成排序。让我们看看可视化是否可以帮助我们更好地理解这个模型。
一个说明性的例子
让我们看看GPT-2小型模型如何完成这句话:船上的狗跑了

这是模型生成的内容:船上的狗跑了,船上
发现了狗。
看起来很合理,对吧?现在让我们通过将狗更改为电机来略微调整示例,并查看模型生成的内容:船上的马达跑了
现在完成的句子:船上的电动机
以每小时约100英里的速度运转。
通过在句子开头改变那个单词,我们得到了完全不同的结果。该模型似乎明白,跑狗的类型与电机的类型完全不同。
如何GPT-2知道要这样的密切关注做 g与电动机,特别是因为这句话早在句子中出现?好吧,GPT-2基于变形金刚,它是一个注意模型 – 它学会将注意力集中在与手头任务最相关的前几个词上:预测句子中的下一个单词。
让我们看看GPT-2关注的焦点是“ 船上的狗跑 ”:

从左到右阅读的线条在猜测句子中的下一个单词时显示模型注意的位置(颜色强度代表注意力)。因此,当在跑完后猜测下一个单词时,模型会密切关注这种情况下的狗。这是有道理的,因为知道谁在做什么或正在做什么对于猜测接下来会发生什么是至关重要的。
在语言学术语中,该模型侧重于船上名词短语“狗”的头部。有迹象表明,GPT-2捕获为好,因为上述关注图案仅仅是许多其他的语言属性一个所述的144个关注图案在模型中。GPT-2有12层变压器,每层都有12个独立的注意机制,称为“头部”; 结果是12 x 12 = 144个不同的注意模式。在这里,我们可视化所有144个,突出显示我们刚刚看到的那个:
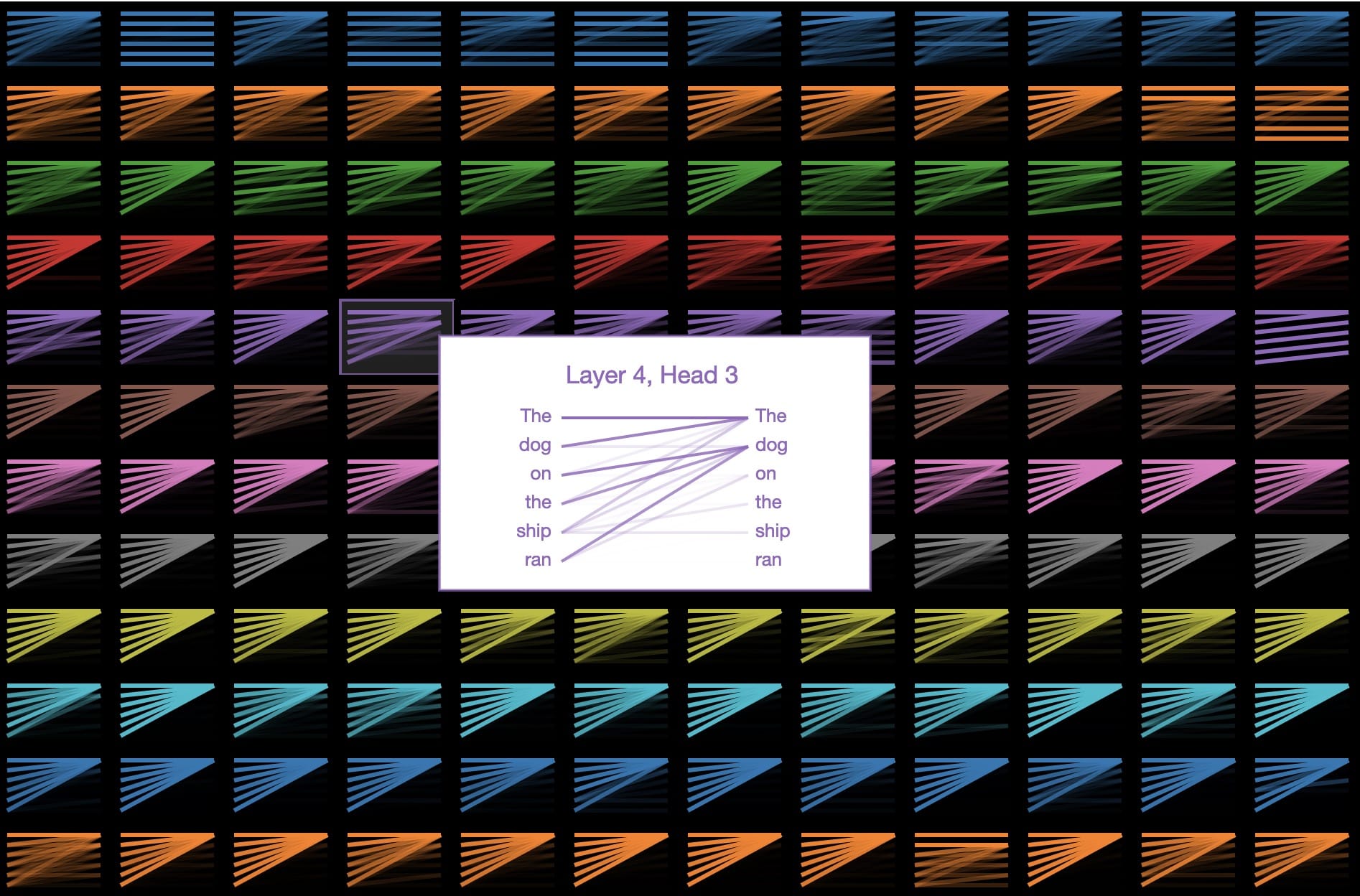
我们可以看到这些模式有许多不同的形式。这是另一个有趣的:

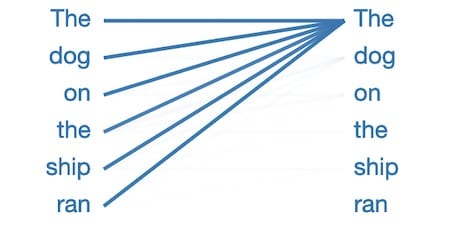
该层/头将所有注意力集中在句子中的前一个单词上。这是有道理的,因为相邻单词通常与预测下一个单词最相关。传统的n -gram语言模型基于同样的直觉。
但为什么这么多注意力模式看起来像这样呢?
在这种模式中,几乎所有注意力都集中在句子中的第一个单词上,而其他单词则被忽略。这似乎是空模式,表明注意头没有找到它正在寻找的任何语言现象。该模型似乎已经将第一个单词重新定位为当它没有更好的关注点时可以看的地方。
_____中的猫

好吧,如果我们要让NLP玷污我们对芝麻街的记忆,那么我猜Seuss博士也是公平的游戏。让我们来看看GPT-2如何从经典的经典帽子Cat中完成这些系列:在一根风筝线上,我们看到了母亲的新礼服!她的礼服有粉红色,白色和……
以下是GPT-2完成最后一句话的方式:她的礼服有粉红色,白色和
蓝色的点。
还不错!原文有红色,所以至少我们知道这不仅仅是记忆。
那么GPT-2如何知道选择颜色?也许是由于以下注意模式似乎识别逗号分隔列表:
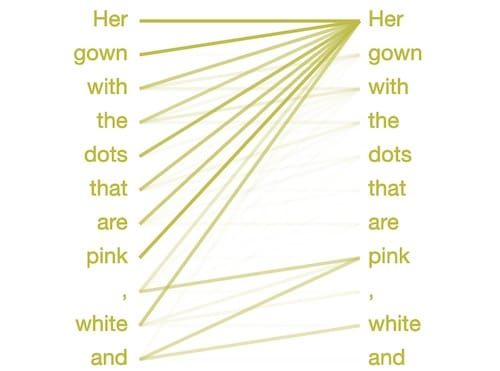
为了决定单词之后和,模型将注意力集中在列表中的前面的项目 - 粉红色和白色。它知道选择一个与之前项目类型匹配的单词,在这种情况下是一种颜色。
什么名字?
GPT-2似乎特别擅长仅根据名字撰写简短的传记。

作为一个有趣的练习,尝试让GPT-2从提示“谁是<你的名字>?”生成文本。这个特殊的提示通常会触发模型写一个简短的传记,可能因为它是作者生物的一个共同前言网络。
这里有一些为提示“Who is Jesse Vig?”而生成的bios:
“Jesse Vig是一位社交媒体营销专家和前社交媒体营销经理。他是VigMedia.com的联合创始人兼首席执行官,最近是VigMedia.com的创始人兼首席执行官。“
不错!有点重复,但是以一种意想不到的方式很好地个性化故事。这是另一个:
“杰西维格是福音派传教士詹姆斯维格的儿子。他于1964年移居美国,并成为密歇根大学的传教士,在那里他教了18年,直到2007年10月去世。“
在最后一个例子中,GPT-2非常聪明,知道我的另一个自我的父亲有相同的姓氏。让我们看看GPT-2在选择这个姓氏时的注意力集中在哪里:

当决定在詹姆斯之后预测这个词时,这种模式将注意力集中在我之前提到的姓氏上。(注意,在模型内部,Vig已被分成单词“ V”和“ ig”,因为它是一个不常见的单词。)似乎这种注意模式专门用于识别家族名称之间的关系。为了测试这个,让我们稍微改变一下文字:
“杰西维格是一位名叫詹姆斯的福音派传教士的同事 ……”

既然詹姆斯只是一个同事,这种注意模式几乎完全忽略了我的姓氏。
注意: GPT-2似乎根据与名称相关的感知种族和性别生成传记。需要进一步研究以了解模型可能编码的偏差; 你可以阅读更多关于这个话题在这里。
未来是生成性的
就在去年,生成各种图像,视频,音频和文本内容的能力已经提高到我们无法再相信自己的感官和对真实或虚假的判断的程度。
而这仅仅是个开始; 这些技术将继续发展并相互融合。很快,当我们盯着thispersondoesnotexist.com上生成的面孔时,他们会满足我们的目光,他们将与我们谈论他们的生活,揭示他们产生的个性的怪癖。
最直接的危险可能是真实与生成的混合。我们已经看过奥巴马作为AI傀儡和Steve Buscemi-Jennifer Lawrence chimera的视频。很快,这些深水将成为个人。因此,当你的妈妈打电话说她需要500美元连线到开曼群岛时,问问自己:这真的是我的妈妈,还是一个语言生成的AI,从她5年前发布的Facebook视频中获得了母亲的声音皮肤?
但就目前而言,让我们尽情享受谈论独角兽的故事。
资源:
用于创建上述可视化的Colab笔记本
用于可视化工具的GitHub repo,使用这些令人敬畏的工具/框架构建:
本文转自《Towards Data Science》。原文地址(需要科学上网)

Comments