
与其他领域相比,机器学习/人工智能现在似乎有更高频率的超级有趣的发展。
Author Archive
关于文本预处理(英文),看这一篇就够了
文本预处理是一个被严重忽视的话题。本文将介绍文本预处理的真正含义,文本预处理的不同方法,以及估计可能需要多少预处理的方法。
自然语言生成 – Natural-language generation | NLG

自然语言生成 – NLG 是 NLP 的重要组成部分,他的主要目的是降低人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式。
本文除了介绍 NLG 的基本概念,还会介绍 NLG 的3个 Level、6个步骤和3个典型的应用。
想要了解更多 NLP 相关的内容,请访问 NLP专题 ,免费提供59页的NLP文档下载。
访问 NLP 专题,下载 59 页免费 PDF
什么是 NLG?
NLG 是 NLP 的一部分
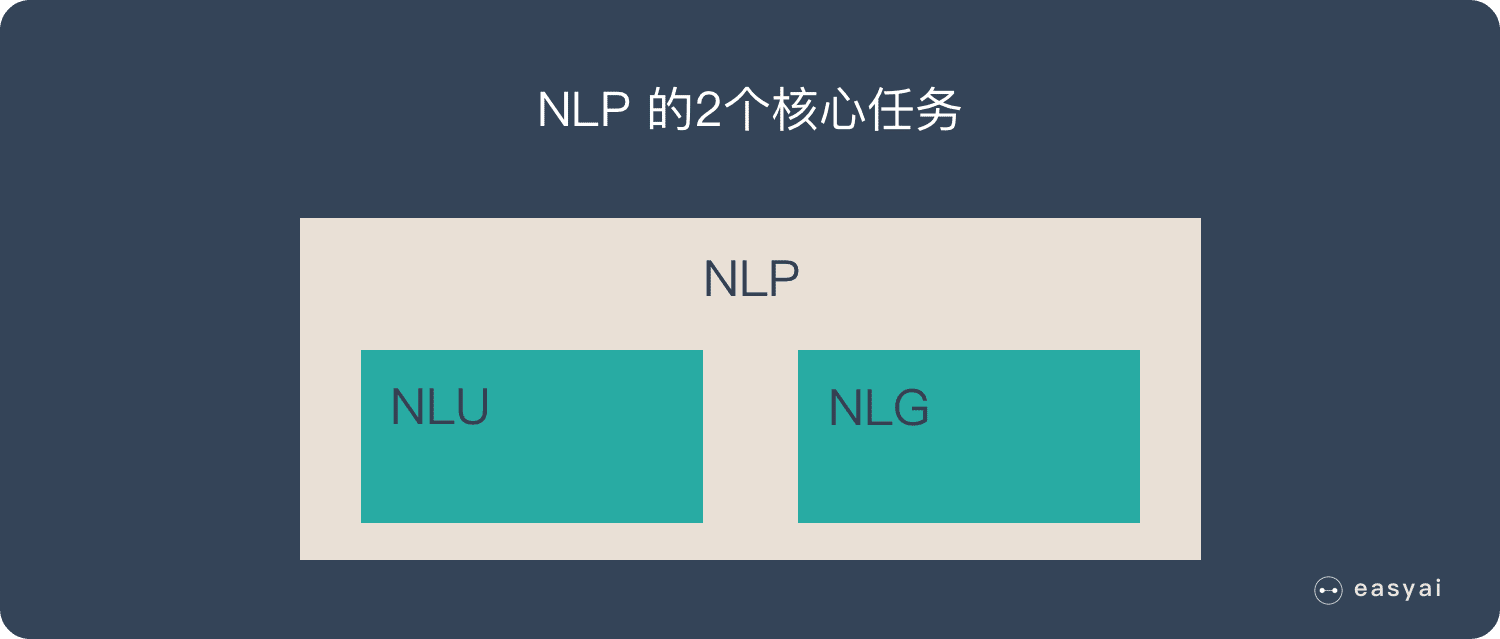
NLP = NLU + NLG
自然语言生成 – NLG 是 NLP 的重要组成部分。NLU 负责理解内容,NLG 负责生成内容。
以智能音箱为例,当用户说“几点了?”,首先需要利用 NLU 技术判断用户意图,理解用户想要什么,然后利用 NLG 技术说出“现在是6点50分”。
自然语言生成 – NLG 是什么?

NLG 是为了跨越人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式,如文章、报告等。
自然语言生成 – NLG 有2种方式:
- text – to – text:文本到语言的生成
- data – to – text :数据到语言的生成
NLG 的3个 Level

简单的数据合并:自然语言处理的简化形式,这将允许将数据转换为文本(通过类似Excel的函数)。为了关联,以邮件合并(MS Word mailmerge)为例,其中间隙填充了一些数据,这些数据是从另一个源(例如MS Excel中的表格)中检索的。
模板化的 NLG :这种形式的NLG使用模板驱动模式来显示输出。以足球比赛得分板为例。数据动态地保持更改,并由预定义的业务规则集(如if / else循环语句)生成。

高级 NLG :这种形式的自然语言生成就像人类一样。它理解意图,添加智能,考虑上下文,并将结果呈现在用户可以轻松阅读和理解的富有洞察力的叙述中。
NLG 的6个步骤

第一步:内容确定 – Content Determination
作为第一步,NLG 系统需要决定哪些信息应该包含在正在构建的文本中,哪些不应该包含。通常数据中包含的信息比最终传达的信息要多。
第二步:文本结构 – Text Structuring
确定需要传达哪些信息后,NLG 系统需要合理的组织文本的顺序。例如在报道一场篮球比赛时,会优先表达「什么时间」「什么地点」「哪2支球队」,然后再表达「比赛的概况」,最后表达「比赛的结局」。
第三步:句子聚合 – Sentence Aggregation
不是每一条信息都需要一个独立的句子来表达,将多个信息合并到一个句子里表达可能会更加流畅,也更易于阅读。
第四步:语法化 – Lexicalisation
当每一句的内容确定下来后,就可以将这些信息组织成自然语言了。这个步骤会在各种信息之间加一些连接词,看起来更像是一个完整的句子。
第五步:参考表达式生成 – Referring Expression Generation|REG
这个步骤跟语法化很相似,都是选择一些单词和短语来构成一个完整的句子。不过他跟语法化的本质区别在于“REG需要识别出内容的领域,然后使用该领域(而不是其他领域)的词汇”。
第六步:语言实现 – Linguistic Realisation
最后,当所有相关的单词和短语都已经确定时,需要将它们组合起来形成一个结构良好的完整句子。
NLG 的3种典型应用
NLG 的不管如何应用,大部分都是下面的3种目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
下面给大家列一些比较典型的应用:

自动写新闻
某些领域的新闻是有比较明显的规则的,比如体育新闻。目前很多新闻已经借助 NLG 来完成了。
聊天机器人
大家了解聊天机器人都是从 Siri 开始的,最近几年又出现了智能音箱的热潮。
除了大家日常生活中很熟悉的领域,客服工作也正在被机器人替代,甚至一些电话客服也是机器人。

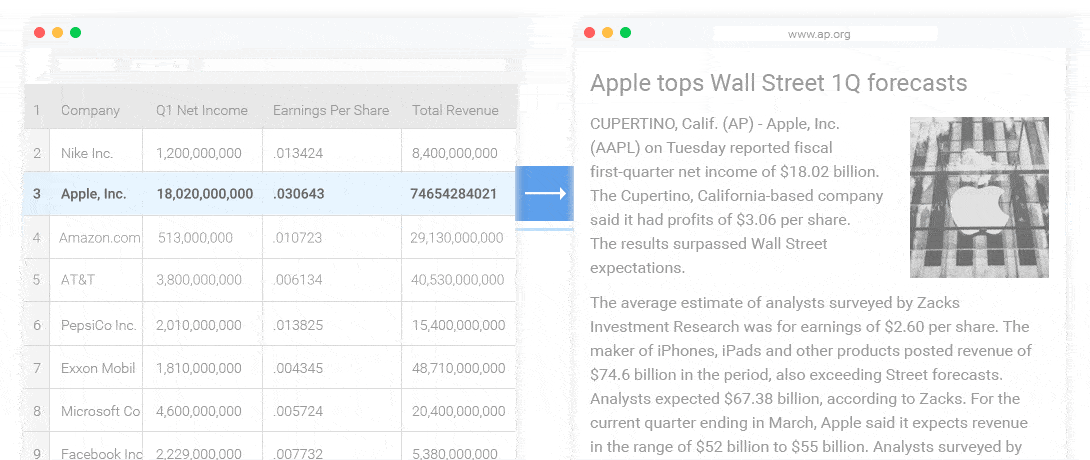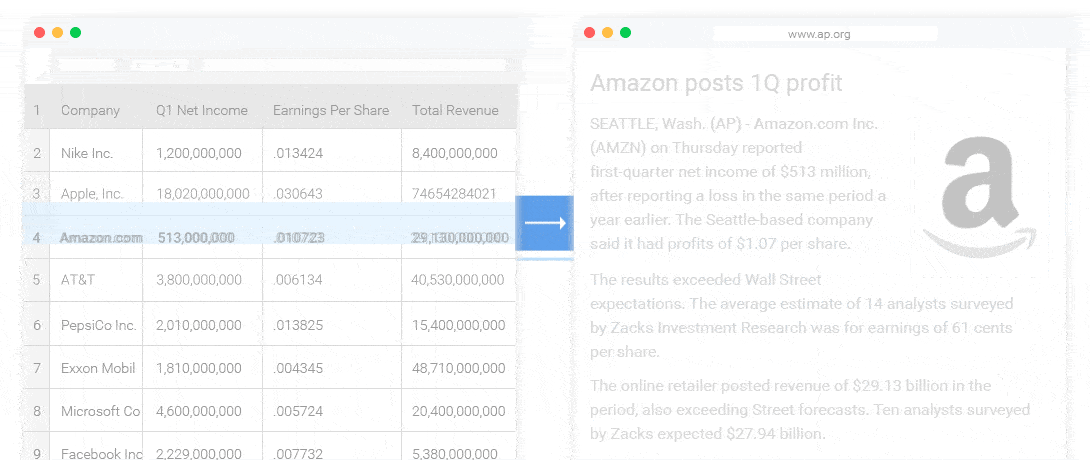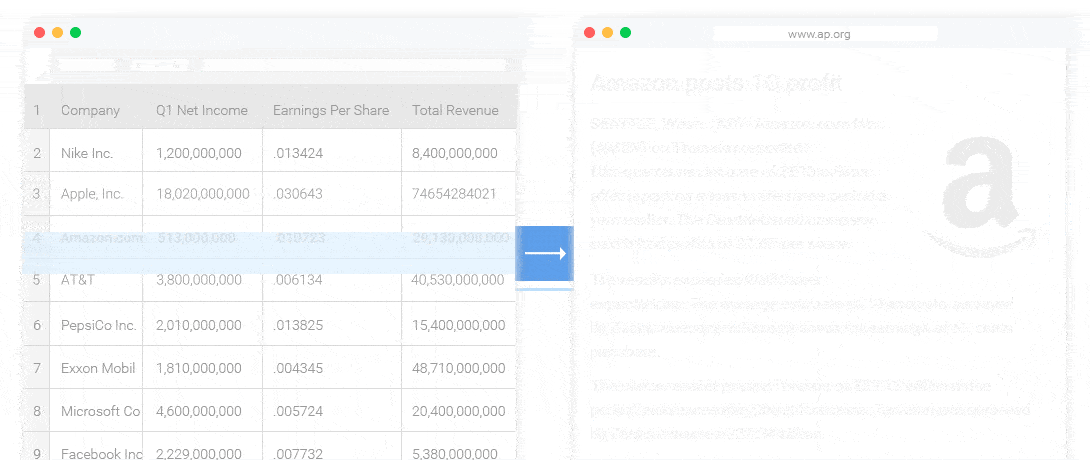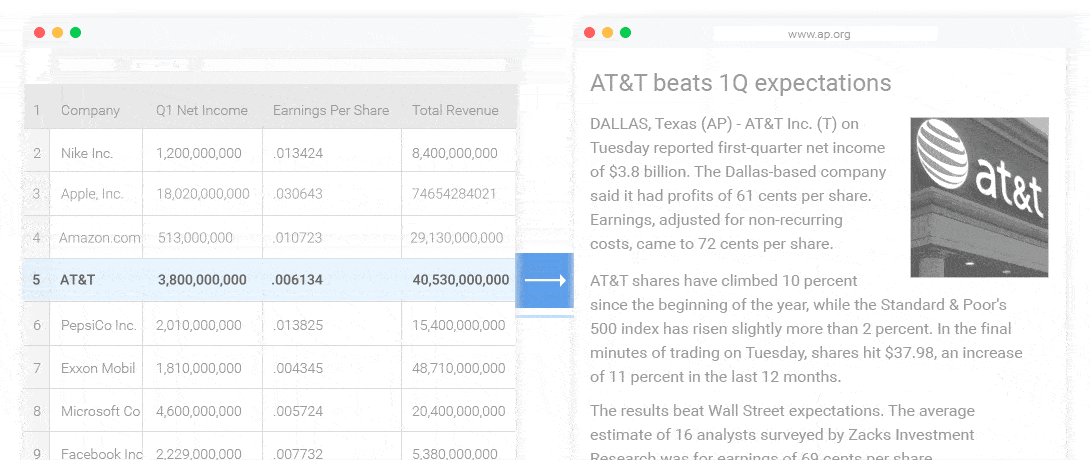
BI 的解读和报告生成
几乎各行各业都有自己的数据统计和分析工具。这些工具可以产生各式各样的图表,但是输出结论和观点还是需要依赖人。NLG 的一个很重要的应用就是解读这些数据,自动的输出结论和观点。(如下图所示)

总结
自然语言生成 – NLG 是 NLP 的重要组成部分,他的主要目的是降低人类和机器之间的沟通鸿沟,将非语言格式的数据转换成人类可以理解的语言格式。
NLG 的3个level:
- 简单的数据合并
- 模块化的 NLG
- 高级 NLG
NLG 的6个步骤:
- 内容确定 – Content Determination
- 文本结构 – Text Structuring
- 句子聚合 – Sentence Aggregation
- 语法化 – Lexicalisation
- 参考表达式生成 – Referring Expression Generation|REG
- 语言实现 – Linguistic Realisation
NLG 应用的3个目的:
- 能够大规模的产生个性化内容
- 帮助人类洞察数据,让数据更容易理解
- 加速内容生产
NLG 的3个典型应用:
- 自动写新闻
- 聊天机器人
- BI 的解读和报告生成
百度百科版本+维基百科
百度百科版本
自然语言生成是研究使计算机具有人一样的表达和写作的功能。即能够根据一些关键信息及其在机器内部的表达形式,经过一个规划过程,来自动生成一段高质量的自然语言文本。
自然语言处理包括自然语言理解和自然语言生成。自然语言生成是人工智能和计算语言学的分支,相应的语言生成系统是基于语言信息处理的计算机模型,其工作过程与自然语言分析相反,是从抽象的概念层次开始,通过选择并执行一定的语义和语法规则来生成文本。
维基百科版本
自然语言生成(NLG)是语言技术的一个方面,侧重于从结构化数据或结构化表示(如知识库或逻辑形式)生成自然语言。当这种形式表征被解释为心理表征的模型时,心理语言学家更喜欢语言生成这个术语。
可以说一个NLG系统就像一个翻译器将数据转换成自然语言表示。然而,由于自然语言的固有表现力,产生最终语言的方法与编译器的方法不同。NLG已经存在了很长时间,但商业NLG技术最近才被广泛使用。
扩展阅读
从基于规则到深度学习,NLP 技术进阶三部曲
我们将快速介绍NLP中的3种主要技术方法,以及我们如何使用它们来构建出色的机器!
AI 将如何改写我们的生活
关于机器人会如何改变我们的生活耳朵一直都在科幻小说中的主食了几十年。在20世纪40年代,人类和人工智能之间的广泛互动似乎仍然遥遥无期,艾萨克·阿西莫夫(Isaac Asimov)提出了他着名的“机器人三法则”(Three Laws of Robotics),旨在防止机器人伤害我们。
MirrorGAN出世!浙大等提出文本-图像新框架,刷新COCO纪录
浙大、悉尼大学等高校研究员提出MirrorGAN,作为全局-局部注意和语义保持的文本-图像-文本框架,解决文本描述和视觉内容之间的语义一致性问题,并在COCO数据集上刷新了记录。
Google手写字符识别的新进展
15年时Google曾经推出了支持82种语言的手写输入,并在去年升级为100种语言。但随着机器学习的迅速发展,研究人员也在不断重构着以往的方法为用户带来更快更准的体验。
对比复现34个预训练模型,PyTorch和Keras你选谁?
初学者该用什么样的 DL 架构?当然是越简单越好、训练速度越快越好、测试准确率越高越好!那么我们到底该选择 PyTorch 还是 Keras 呢?
Q-Learning
什么是 Q-Learning ?
Q学习是强化学习中基于价值的学习算法。
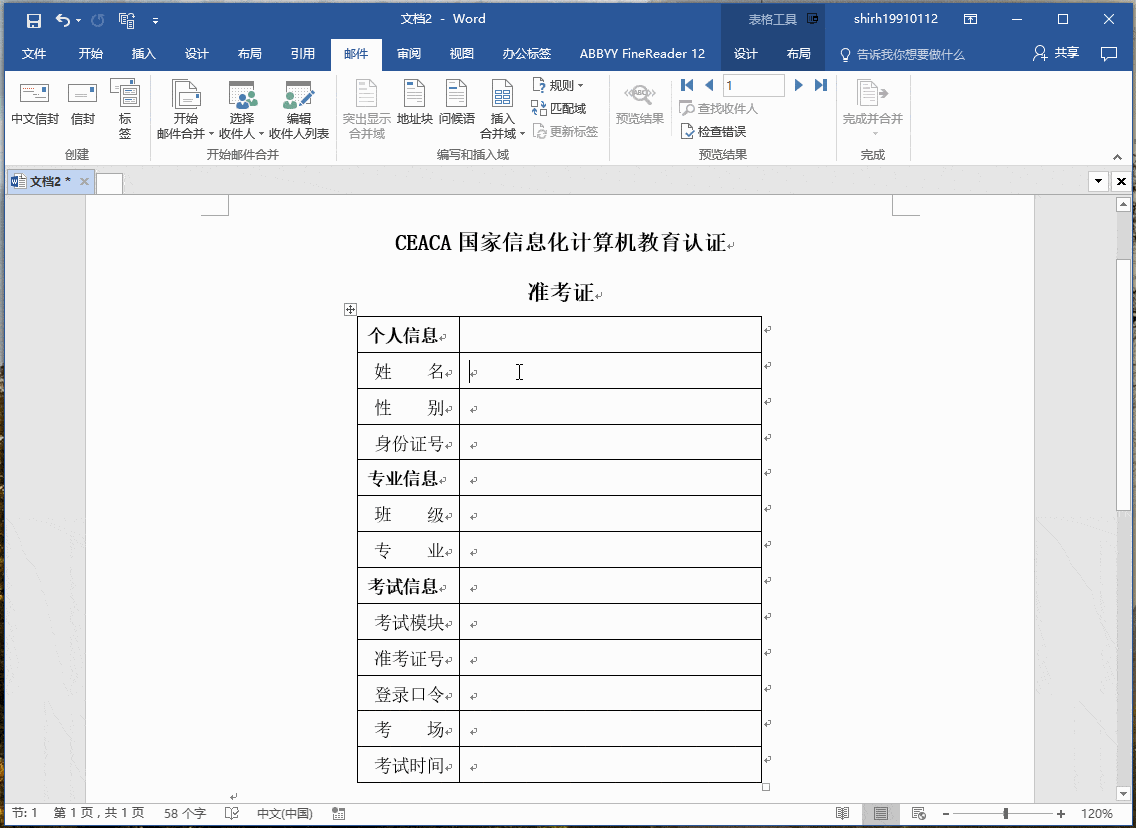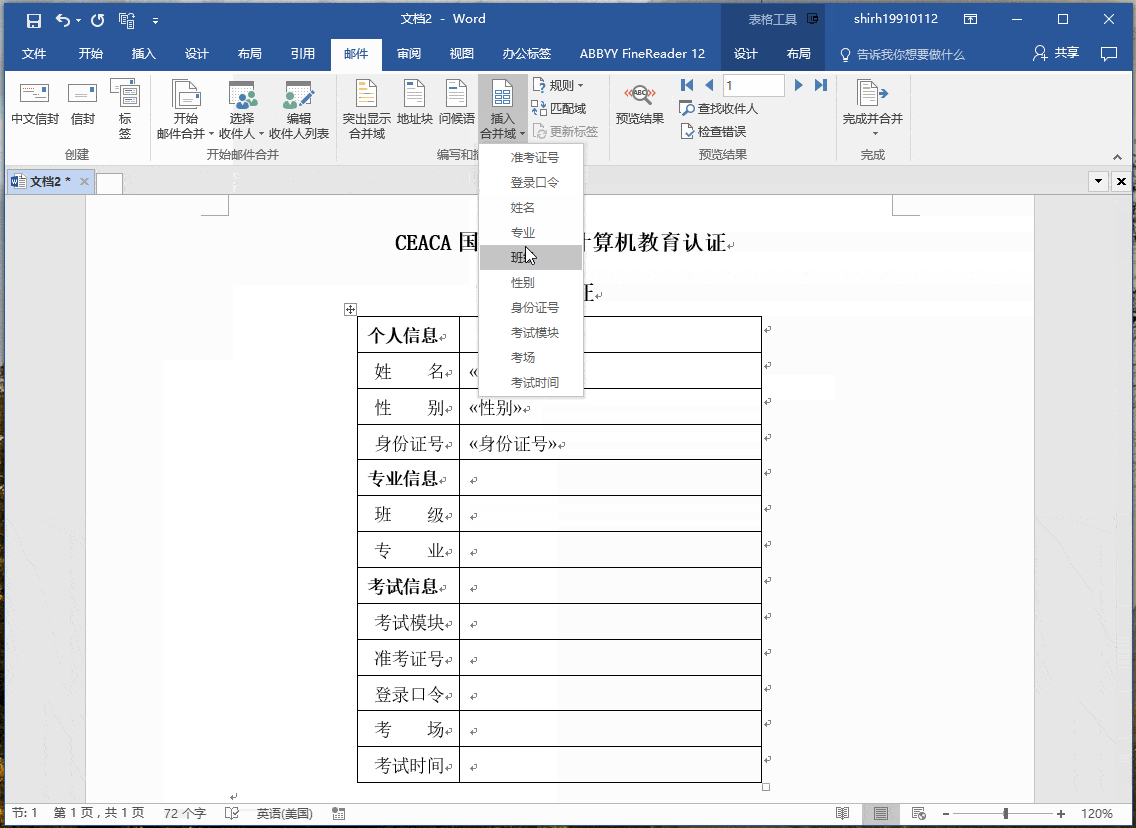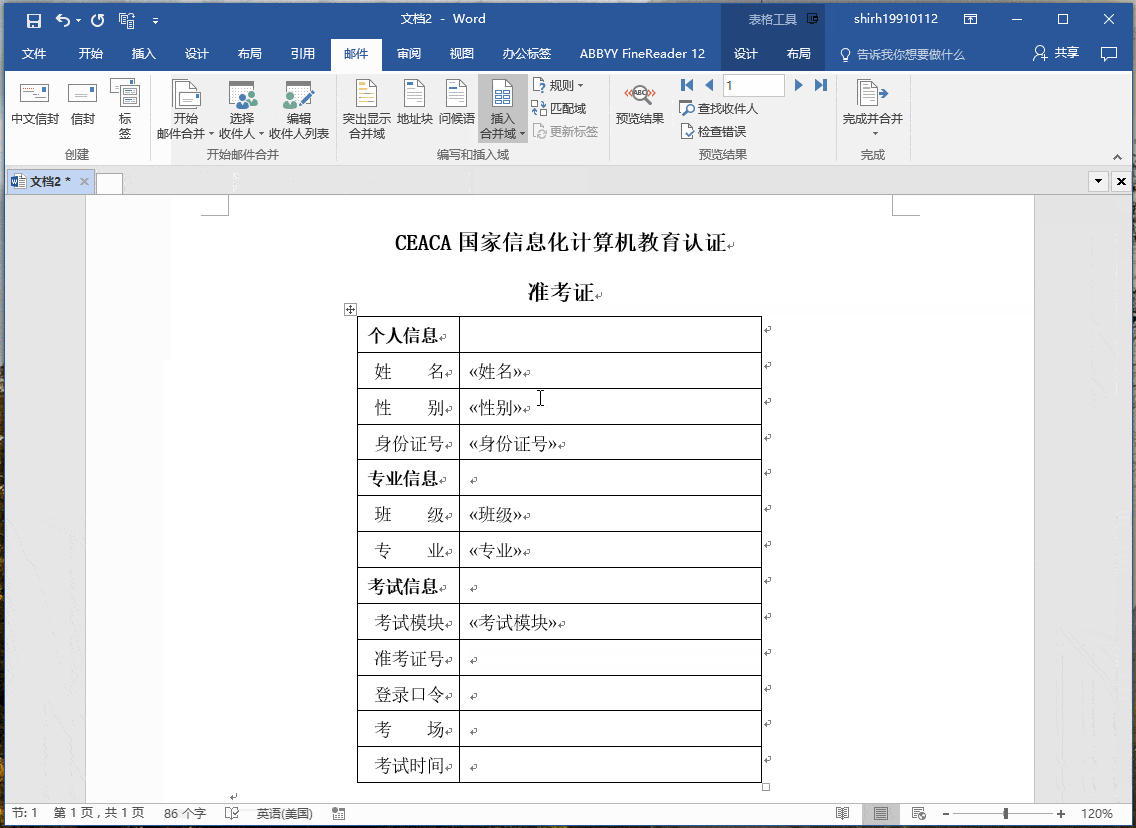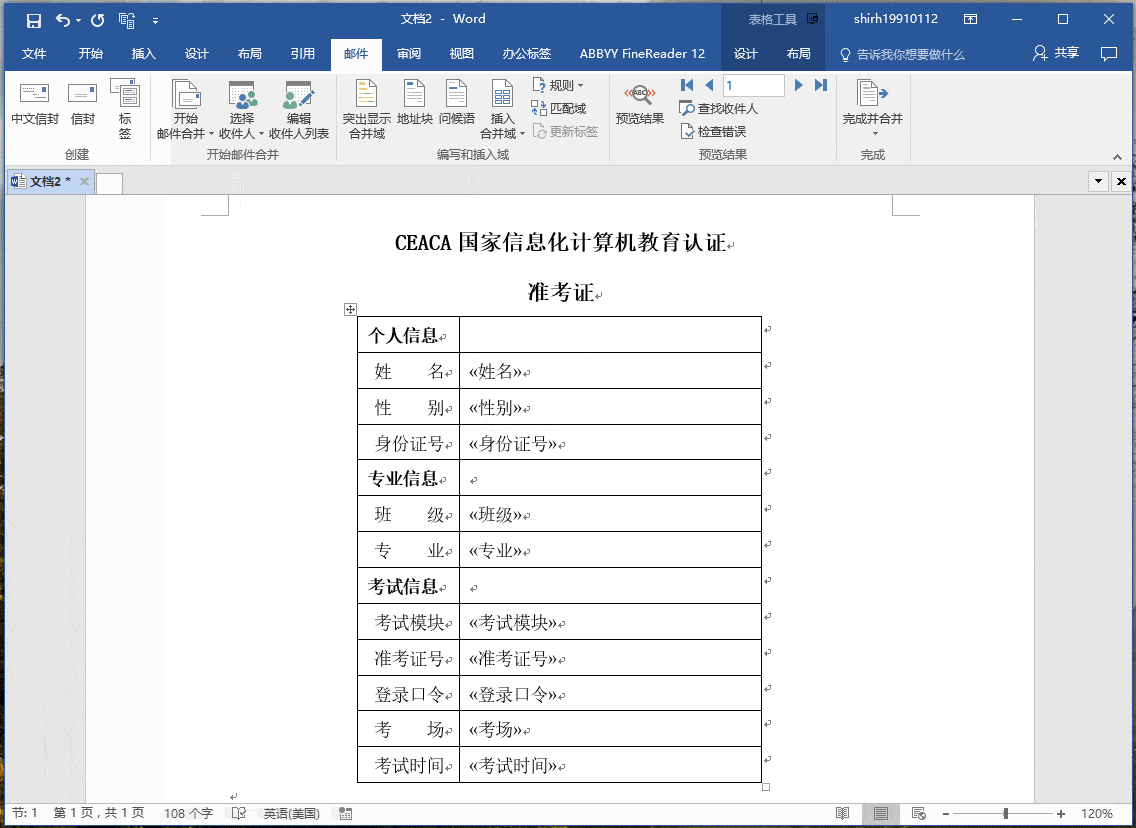
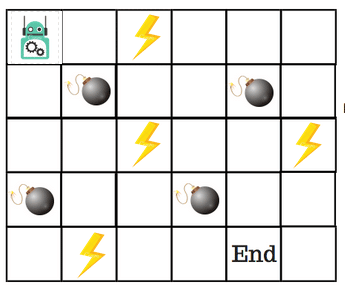
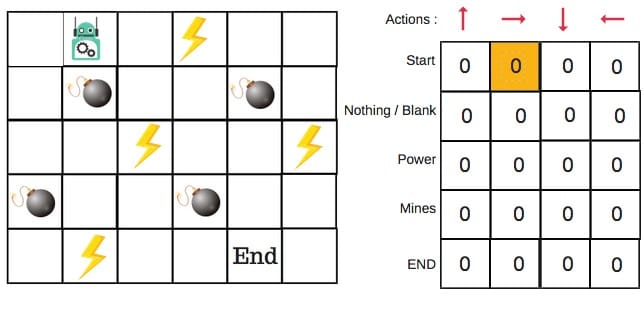
假设机器人必须越过迷宫并到达终点。有地雷,机器人一次只能移动一个地砖。如果机器人踏上矿井,机器人就死了。机器人必须在尽可能短的时间内到达终点。
得分/奖励系统如下:
- 机器人在每一步都失去1点。这样做是为了使机器人采用最短路径并尽可能快地到达目标。
- 如果机器人踩到地雷,则点损失为100并且游戏结束。
- 如果机器人获得动力⚡️,它会获得1点。
- 如果机器人达到最终目标,则机器人获得100分。
现在,显而易见的问题是:我们如何训练机器人以最短的路径到达最终目标而不踩矿井?
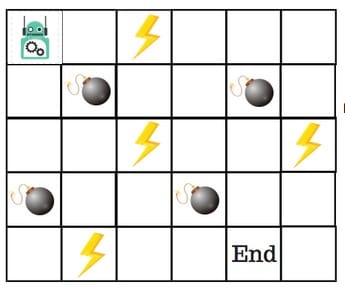
那么,我们该如何解决这个问题呢?
什么是 Q-Table ?
Q-Table只是一个简单查找表的奇特名称,我们计算每个州的最大预期未来奖励。基本上,这张表将指导我们在每个州采取最佳行动。
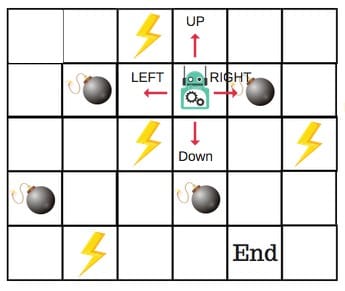
每个非边缘区块将有四个动作数。当机器人处于某种状态时,它可以向上或向下或向右或向左移动。
所以,让我们在Q-Table中对这个环境进行建模。
在Q表中,列是动作,行是状态。
每个Q表得分将是机器人在该状态下采取该行动时将获得的最大预期未来奖励。这是一个迭代过程,因为我们需要在每次迭代时改进Q-Table。
但问题是:
- 我们如何计算Q表的值?
- 值是可用的还是预定义的?
为了学习Q表的每个值,我们使用Q-Learning算法。
Q-Learning 的数学依据
Q-Fuction
所述 Q-Fuction 使用Bellman方程和采用两个输入:状态(小号)和动作(一个)。
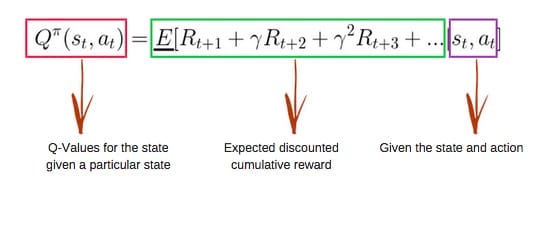
使用上面的函数,我们得到表中单元格的Q值。
当我们开始时,Q表中的所有值都是零。
有一个更新值的迭代过程。当我们开始探索环境时,通过不断更新表中的Q值, Q函数为我们提供了更好和更好的近似。
现在,让我们了解更新是如何进行的。
Q-Learning 算法的过程详解
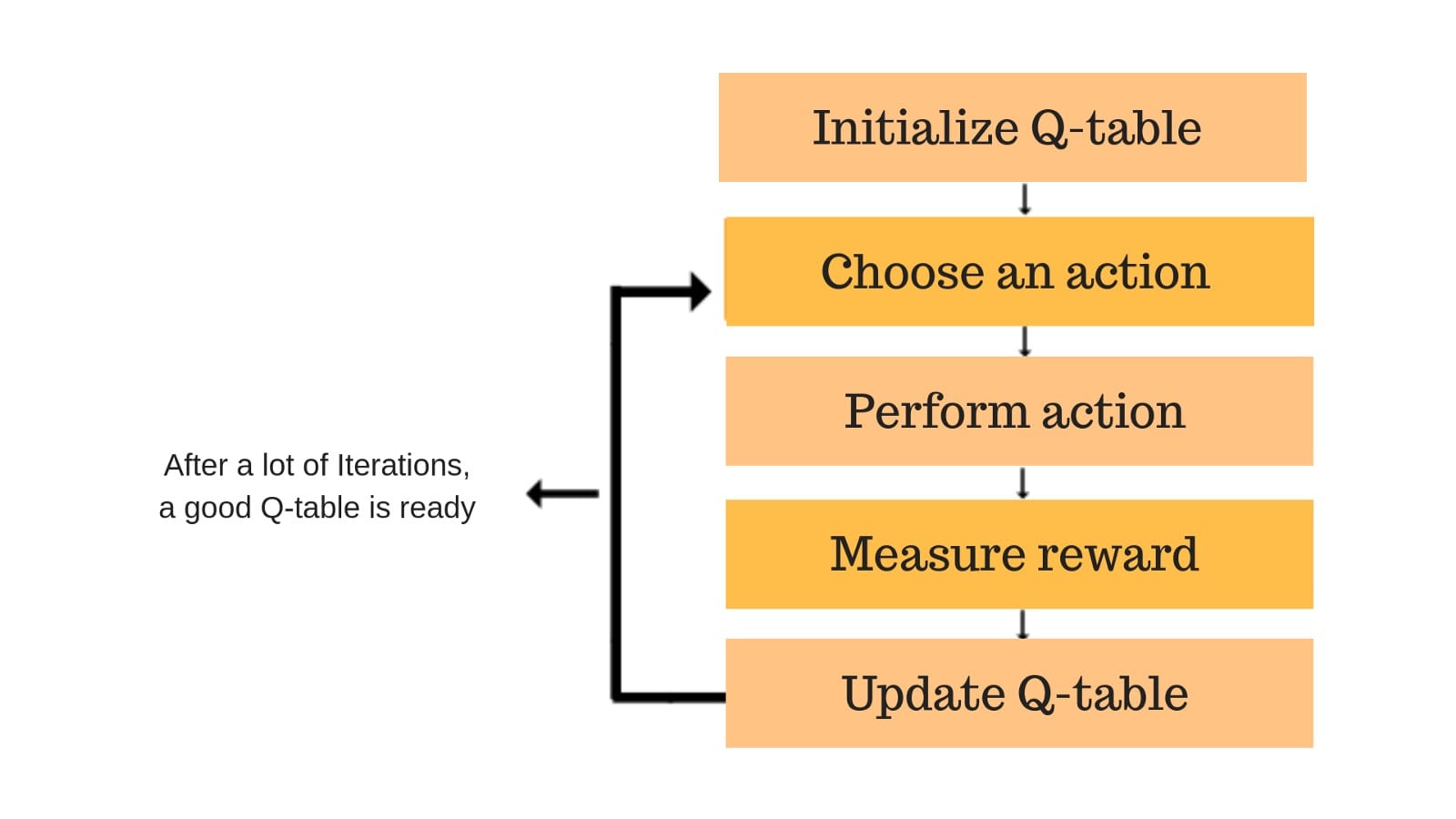
每个彩色框都是一步。让我们详细了解每个步骤。
第1步:初始化Q表
我们将首先构建一个Q表。有n列,其中n =操作数。有m行,其中m =状态数。我们将值初始化为0。
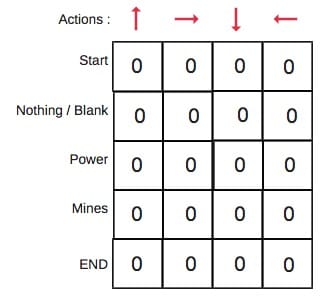
在我们的机器人示例中,我们有四个动作(a = 4)和五个状态(s = 5)。所以我们将构建一个包含四列五行的表。
步骤2和3:选择并执行操作
这些步骤的组合在不确定的时间内完成。这意味着此步骤一直运行,直到我们停止训练,或者训练循环停止,如代码中所定义。
我们将根据Q-Table选择状态中的动作(a)。但是,如前所述,当剧集最初开始时,每个Q值都为0。
因此,现在探索和开发权衡的概念发挥作用。
我们将使用一种叫做epsilon贪婪策略的东西。
一开始,ε利率会更高。机器人将探索环境并随机选择动作。这背后的逻辑是机器人对环境一无所知。
随着机器人探索环境,epsilon率降低,机器人开始利用环境。
在探索过程中,机器人逐渐变得更有信心估计Q值。
对于机器人示例,有四种操作可供选择:向上,向下,向左和向右。 我们现在开始训练 – 我们的机器人对环境一无所知。所以机器人选择随机动作,说对了。
我们现在可以使用Bellman方程更新Q值,使其处于开始和向右移动。
步骤4和5:评估
现在我们采取了行动并观察了结果和奖励。我们需要更新功能Q(s,a)。

在机器人游戏的情况下,重申得分/奖励结构是:
- 功率 = +1
- 我的 = -100
- 结束 = +100


我们将一次又一次地重复这一过程,直到学习停止。通过这种方式,Q表将会更新。
本文翻译自《An introduction to Q-Learning: reinforcement learning》
维基百科版本
维基百科版本
Q -learning是一种无模型 强化学习算法。Q-learning的目标是学习一种策略,告诉代理在什么情况下要采取什么行动。它不需要环境的模型(因此内涵“无模型”),并且它可以处理随机转换和奖励的问题,而不需要调整。
对于任何有限马尔可夫决策过程(FMDP),Q -learning在从当前状态开始的任何和所有后续步骤中最大化总奖励的预期值的意义上找到最优的策略。[1] 在给定无限探索时间和部分随机策略的情况下,Q- learning可以为任何给定的FMDP确定最佳动作选择策略。“Q”命名返回用于提供强化的奖励的函数,并且可以说代表在给定状态下采取的动作的“质量”。
使用word2vec分析新闻标题并预测文章成功
文章标题的嵌入可以预测受欢迎程度吗?我们可以从中了解情绪与股票之间的关系?word2vec可以帮助我们回答这些问题,等等。